Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a![]() : SQL Server 2016 (13.x) y versiones posteriores
: SQL Server 2016 (13.x) y versiones posteriores
En este artículo, se ofrece una visión global de las soluciones de continuidad empresarial para alta disponibilidad y recuperación ante desastres en SQL Server, en Windows y Linux.
Todos los usuarios que implementan SQL Server deben asegurarse de que todas las instancias críticas de SQL Server y las bases de datos dentro de ellas estén disponibles cuando los usuarios empresariales y finales los necesiten, tanto si esa disponibilidad está durante las horas laborables normales como al día. El objetivo es mantener la empresa en funcionamiento con una interrupción mínima o inexistente. Este concepto se conoce también como continuidad empresarial.
SQL Server 2017 (14.x) y versiones posteriores introdujeron características y mejoras para la disponibilidad. La mayor adición es la compatibilidad con SQL Server en distribuciones de Linux. Para obtener una lista completa de las nuevas características de SQL Server, vea los temas siguientes:
| Versión | Sistema operativo |
|---|---|
| Novedades de SQL Server 2025 (17.x) | Windows | Linux |
| Novedades de SQL Server 2022 (16.x) | Windows | Linux |
| Novedades de SQL Server 2019 (15.x) | Windows | Linux |
| Novedades de SQL Server 2017 (14.x) | Windows | Linux |
Este artículo se centra en los escenarios de disponibilidad en SQL Server 2017 (14.x) y versiones posteriores, así como en las características de disponibilidad nuevas y mejoradas. Entre los escenarios se incluyen los híbridos que pueden abarcar implementaciones de SQL Server en Windows Server y Linux, y otros que pueden aumentar el número de copias legibles de una base de datos.
Aunque en este artículo no se tratan las opciones de disponibilidad externas a SQL Server (como la virtualización), todo lo que se describe aquí se aplica a las instalaciones de SQL Server dentro de una máquina virtual invitada, ya sea en la nube pública o hospedada por un servidor de hipervisor local.
Escenarios de SQL Server que usan características de disponibilidad
Puede usar grupos de disponibilidad Always On, instancias de clúster de conmutación por error y trasvase de registros de diferentes maneras, no solo para la disponibilidad. Hay cuatro maneras principales de usar las características de disponibilidad:
- Alta disponibilidad
- Recuperación ante desastres
- Migraciones y actualizaciones
- Escalado horizontal de copias legibles de una o varias bases de datos
En las secciones siguientes se describen las características pertinentes para cada escenario. Una característica no cubierta es la replicación de SQL Server. Aunque la replicación de SQL Server no se designa oficialmente como una característica de disponibilidad en el paraguas AlwaysOn, a menudo se usa para hacer que los datos sean redundantes en determinados escenarios. La replicación de mezcla no se admite para SQL Server en Linux. Para obtener más información, consulte Replicación de SQL Server en Linux.
Importante
Las características de disponibilidad de SQL Server no reemplazan el requisito de tener una estrategia de copia de seguridad y restauración sólida y bien probada. Una estrategia de copia de seguridad y restauración es el bloque de creación más fundamental de cualquier solución de disponibilidad.
Alta disponibilidad
Es importante asegurarse de que las instancias o bases de datos de SQL Server estén disponibles si se produce un problema local en un centro de datos o en una sola región en la nube. En esta sección se explica cómo pueden ayudar las características de disponibilidad de SQL Server. Todas las características descritas están disponibles en Windows Server y en Linux.
Grupos de disponibilidad
Los grupos de disponibilidad (AG) proporcionan protección a nivel de base de datos enviando cada transacción de una base de datos a otra instancia o réplica, que contiene una copia de esa base de datos en un estado especial. Puede implementar un AG en las ediciones Standard o Enterprise. Las instancias que participan en un grupo de disponibilidad pueden ser instancias independientes o instancias de clúster de conmutación por error (FCI, se describen en la siguiente sección). Puesto que las transacciones se envían a una réplica en el momento en que se producen, los grupos de disponibilidad están recomendados en aquellos casos en que se requiere un punto de recuperación y objetivos de tiempo de recuperación inferiores. El movimiento de datos entre las réplicas puede ser sincrónico o asincrónico; en el caso de la edición Enterprise, se permiten hasta tres réplicas (incluida la principal) como sincrónicas. Un grupo de disponibilidad tiene una copia de lectura y escritura completa de la base de datos que se encuentra en la réplica principal, mientras que todas las réplicas secundarias no pueden recibir transacciones directamente de los usuarios finales o las aplicaciones.
Nota
AlwaysOn es un término genérico para las características de disponibilidad de SQL Server y abarca tanto los grupos de disponibilidad como los FCI. AlwaysOn no es el nombre de la característica del grupo de disponibilidad.
Antes de SQL Server 2022 (16.x), los grupos de disponibilidad solo proporcionan protección de nivel de base de datos y no de nivel de instancia. Todo lo que no se capture en el registro de transacciones o configurado en la base de datos se debe sincronizar manualmente para cada réplica secundaria. Algunos ejemplos de objetos que se deben sincronizar manualmente son los inicios de sesión a nivel de instancia, los servidores vinculados y los trabajos del Agente SQL Server.
En SQL Server 2022 (16.x) y versiones posteriores, puede administrar objetos de metadatos, incluidos usuarios, inicios de sesión, permisos y trabajos del Agente SQL Server en el nivel de grupo de disponibilidad, además del nivel de instancia. Para obtener más información, consulte ¿Qué es un grupo de disponibilidad independiente?
Un grupo de disponibilidad también tiene otro componente denominado el cliente de escucha, que permite a las aplicaciones y los usuarios finales conectarse sin necesidad de conocer qué instancia de SQL Server hospeda la réplica principal. Cada GA tiene su propia escucha. Aunque las implementaciones del agente de escucha son ligeramente diferentes en Windows Server frente a Linux, proporcionan la misma funcionalidad y facilidad de uso. En el diagrama siguiente se muestra un Grupo de Disponibilidad basado en Windows Server que usa un Clúster de Conmutación por Error de Windows Server (WSFC). Se requiere un clúster subyacente en la capa del sistema operativo para la disponibilidad tanto si está en Linux como en Windows Server. En el ejemplo, se muestra una sencilla configuración de dos servidores, o nodos, en la que el WSCF es el clúster subyacente.
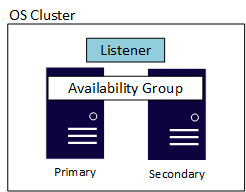
Las ediciones Estándar y Enterprise tienen valores máximos diferentes en lo relativo a las réplicas. Un grupo de disponibilidad en la edición Estándar, conocido como grupo de disponibilidad básica, admite dos réplicas (una principal y otra secundaria) con una sola base de datos en el grupo de disponibilidad. La edición Enterprise no solo permite que se configuren varias bases de datos en un solo grupo de disponibilidad, sino que también puede tener hasta nueve réplicas totales (una principal y ocho secundarias). Enterprise Edition también proporciona otras ventajas opcionales, como las réplicas secundarias legibles o la posibilidad de realizar copias de seguridad a partir de una réplica secundaria, entre otras.
Nota
Reflejo de base de datos, que fue obsoleto en SQL Server 2012 (11.x), no está disponible en la versión Linux de SQL Server ni se agrega. Los usuarios que aún utilizan la creación de reflejo de la base de datos deben planear la migración a grupos de disponibilidad, que son lo que sustituye a la creación de reflejo de la base de datos.
En cuanto a la disponibilidad, los grupos de disponibilidad pueden proporcionar conmutación por error automática o manual. La conmutación automática por error puede producirse si se configura el movimiento de datos sincrónico y la base de datos en la réplica principal y secundaria se encuentra en un estado sincronizado. Siempre que se use el agente de escucha y la aplicación use una versión compatible de .NET Framework (3.5 con Service Pack 1 o 4.6.2 y versiones posteriores), la conmutación por error debe controlarse con un efecto mínimo en los usuarios finales si se usa un agente de escucha. La conmutación por error a una réplica secundaria para convertirla en la nueva réplica principal se puede configurar para que sea automática o manual, y generalmente se mide en segundos.
En la lista siguiente se resaltan algunas diferencias entre los grupos de disponibilidad (AGs) en Windows Server y Linux.
Debido a la forma en que el clúster subyacente funciona en Linux y Windows Server, todas las conmutaciones por error del grupo de disponibilidad (manuales o automáticas) se realizan a través del clúster en Linux. En implementaciones de grupos de disponibilidad basadas en Windows Server, las conmutaciones por error manuales deben hacerse a través de SQL Server. Las conmutaciones automáticas por error se controlan mediante el clúster subyacente en Windows Server y Linux.
Para SQL Server en Linux, se recomienda configurar un grupo de disponibilidad con un mínimo de tres réplicas, debido a la forma en que funciona el clúster subyacente.
En Linux, el nombre común usado por cada agente de escucha se define en DNS y no en el clúster como en Windows Server.
SQL Server 2017 (14.x) introdujo las siguientes características y mejoras en los AG (Grupos de Disponibilidad):
- Tipos de clúster
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT- Compatibilidad mejorada del Coordinador de transacciones distribuidas (DTC) para las configuraciones basadas en Windows Server
- Escenarios adicionales de escalado horizontal para bases de datos de solo lectura (se describen más adelante en este artículo)
Tipos de clúster de grupo de disponibilidad
La forma de disponibilidad integrada de agrupación en clústeres de Windows Server se habilita a través de una característica denominada Clústeres de conmutación por error. Permite crear un WSFC para su uso con un grupo de disponibilidad o FCI. SQL Server incluye archivos DLL de recursos compatibles con clústeres que proporcionan integración para grupos de disponibilidad y FCI.
SQL Server en Linux admite varias tecnologías de agrupación en clústeres. Microsoft admite los componentes de SQL Server, mientras que nuestros asociados admiten la tecnología de agrupación en clústeres pertinente. Por ejemplo, además de Pacemaker, SQL Server en Linux admite HPE Serviceguard y DH2i DxEnterprise como solución de clúster.
Un clúster de conmutación por error basado en Windows y una solución de clúster de Linux son más similares que diferentes. Ambos proporcionan una manera de aprovechar los servidores individuales y combinarlos en una configuración para proporcionar disponibilidad, y tienen conceptos de elementos como recursos, restricciones (incluso si se implementan de manera diferente), conmutación por error, etc.
Por ejemplo, a fin de que Pacemaker se admita tanto en configuraciones de grupo de disponibilidad como de FCI, incluidos aspectos como la conmutación automática por error, Microsoft proporciona el paquete mssql-server-ha para Pacemaker que, aunque es parecido, no es exactamente igual a los DLL del recurso en un clúster WSFC. Una de las diferencias entre un clúster WSFC y Pacemaker es que no hay ningún recurso de nombre de red en Pacemaker, que es el componente que ayuda a tomar el nombre del agente de escucha (o el nombre de la FCI) en un clúster WSFC. Use DNS para la resolución de nombres en Linux.
Debido a la diferencia en la pila de clústeres, los grupos de disponibilidad de SQL Server 2017 (14.x) y versiones posteriores deben controlar algunos de los metadatos que administra de forma nativa un WSFC. Por ejemplo, hay tres tipos de clúster para un grupo de disponibilidad, que se almacenan en sys.availability_groups en las columnas cluster_type y cluster_type_desc.
- WSFC
- Externo
- Ninguno
Todos los grupos de disponibilidad que necesitan una alta disponibilidad deben usar un clúster subyacente, lo que en el caso de SQL Server 2017 (14.x) y versiones posteriores significa un agente de clúster WSFC o Linux. En el caso de los grupos de disponibilidad basados en Windows Server que utilizan un WSFC como estructura subyacente, el tipo de clúster predeterminado es WSFC y no es necesario configurarlo. En el caso de los grupos de disponibilidad basados en Linux, debe establecer el tipo de clúster en Externo al crear el grupo de disponibilidad. La integración con una solución de clúster externa en Linux se configura después de crear el grupo de disponibilidad, mientras que en un clúster de WSFC esto se hace en el momento de la creación.
El tipo de clúster Ninguno puede utilizarse con grupos de disponibilidad de Windows Server y Linux. La configuración del tipo de clúster en Ninguno implica que el grupo de disponibilidad no requiere un clúster subyacente. Esto significa que SQL Server 2017 (14.x) es la primera versión de SQL Server que admite grupos de disponibilidad sin un clúster, pero el inconveniente es que esta configuración no se admite como solución de alta disponibilidad.
Importante
En SQL Server 2017 (14.x) y versiones posteriores, no se puede cambiar un tipo de clúster para un grupo de disponibilidad después de crearlo. Esta restricción significa que un grupo de disponibilidad no se puede cambiar de Ninguno a Externo o WSFC, y viceversa.
Si solo desea agregar copias adicionales de solo lectura de una base de datos, o si quiere lo que ofrece un grupo de disponibilidad para la migración y las actualizaciones, pero no desea enfrentarse a la complejidad de un clúster subyacente o incluso la replicación, considere configurar un grupo de disponibilidad con un tipo de clúster Ninguno. Para obtener más información, consulte las secciones Migraciones y actualizaciones yescalado de lectura.
En la captura de pantalla siguiente se muestra la compatibilidad con los distintos tipos de tipos de clúster en SQL Server Management Studio (SSMS). Debe ejecutar la versión 17.1 o una posterior. La captura de pantalla siguiente procede de la versión 17.2:

REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT
SQL Server 2016 (13.x) aumentó la compatibilidad para el número de réplicas sincrónicas de dos a tres en la edición Enterprise. Sin embargo, si se sincroniza una réplica secundaria, pero la otra réplica tiene un problema, no hay forma de controlar el comportamiento para indicar al principal que espere a la réplica problemática o que le permita continuar. En este escenario, la réplica principal podría seguir recibiendo tráfico de escritura aunque la réplica secundaria no esté en un estado sincronizado, lo que da lugar a una pérdida de datos en la réplica secundaria.
En SQL Server 2017 (14.x) y versiones posteriores, puede controlar el comportamiento de lo que sucede cuando hay réplicas sincrónicas con REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT. Esta opción funciona como se describe a continuación:
- Hay tres valores posibles:
0,1y2. - El valor es el número de réplicas secundarias que se deben sincronizar, lo que tiene implicaciones para la pérdida de datos, la disponibilidad de los Grupos de Disponibilidad y la conmutación por error.
- Para WSFCs y un tipo de clúster de None, el valor predeterminado es
0y puede establecerlo manualmente en1o2. - Para un tipo de clúster externo, el mecanismo del clúster establece este valor de forma predeterminada y puede invalidarlo manualmente. Para tres réplicas sincrónicas, el valor predeterminado es
1.
En Linux, configuras el valor de REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT en el recurso AG del clúster. En Windows, se establece a través de Transact-SQL.
Un valor mayor que 0 garantiza una mayor protección de datos, ya que si el número necesario de réplicas secundarias no está disponible, la principal no está disponible hasta que se resuelva esa condición.
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT también afecta al comportamiento de la conmutación por error, ya que la conmutación automática por error no se puede producir si el número correcto de réplicas secundarias no está en el estado adecuado. En Linux, un valor de 0 no permite la conmutación automática por fallo. Por lo tanto, al usar modo síncrono con conmutación automática por fallo en Linux, debe establecer el valor por encima de 0 para lograr la conmutación automática por fallo.
0 en Windows Server es el comportamiento de SQL Server 2016 (13.x) y versiones anteriores.
Compatibilidad mejorada con el Coordinador de transacciones distribuidas de Microsoft
Antes de SQL Server 2016 (13.x), la única manera de obtener disponibilidad en SQL Server para las aplicaciones que requieren transacciones distribuidas, que usan DTC debajo de las cubiertas, era implementar FCI. Una transacción distribuida puede hacerse de dos maneras:
- Transacción que abarca más de una base de datos en la misma instancia de SQL Server.
- Una transacción que abarca más de una instancia de SQL Server o posiblemente implica un origen de datos que no sea de SQL Server.
SQL Server 2016 (13.x) introdujo la compatibilidad parcial para DTC con los grupos de disponibilidad incluidos en el segundo escenario. SQL Server 2017 (14.x) lo completa al hacer que ambos escenarios sean compatibles con DTC.
En SQL Server 2017 (14.x) y versiones posteriores, puede agregar compatibilidad con DTC a un grupo de disponibilidad después de crearlo. En SQL Server 2016 (13.x), solo puede habilitar el soporte para DTC al crear el AG.
Instancias de clúster de conmutación por error
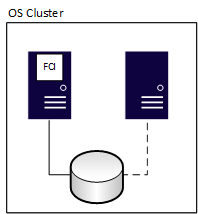
Las instancias de clúster de conmutación por error (FCI) proporcionan disponibilidad para toda la instalación de SQL Server, conocida como instancia. Con las FCI, si el servidor subyacente encuentra un problema, todo lo que hay dentro de la instancia se mueve a otro servidor, incluidas las bases de datos, los trabajos del Agente SQL Server, los servidores vinculados, etc. Todos los fci requieren algún almacenamiento compartido, incluso si está definido en red. Un nodo puede ejecutar y poseer los recursos de la FCI en cualquier momento dado. En el diagrama siguiente, el primer nodo del clúster posee la FCI. También posee los recursos de almacenamiento compartido asociados, que indica la línea sólida al almacenamiento.
Después de un "failover", cambia la propiedad del recurso, como se muestra en el siguiente diagrama:
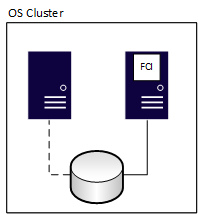
Una FCI tiene cero pérdida de datos, pero el almacenamiento compartido subyacente es un único punto de error, ya que hay una copia de los datos. Para tener copias redundantes de bases de datos, combine FCIs con otro método de disponibilidad, como un grupo de disponibilidad o un envío de registros. El otro método debe usar almacenamiento físicamente independiente de la FCI. Cuando la FCI realiza un failover a otro nodo, se detiene en uno y se inicia en otro. Este proceso es similar a apagar un servidor y encenderlo.
Una FCI pasa por el proceso de recuperación normal. Reenvía las transacciones que deben implementarse y revierte las transacciones incompletas. Por lo tanto, la base de datos es coherente desde un determinado punto de datos hasta el momento del fallo o de la conmutación por error manual, por lo que no hay pérdida de datos. Las bases de datos solo están disponibles una vez completada la recuperación. El tiempo de recuperación depende de muchos factores y, por lo general, es más largo que conmutar un grupo de disponibilidad. La compensación es que, al conmutar por error un grupo de disponibilidad, puede haber tareas adicionales necesarias para que una base de datos se pueda usar, como habilitar un trabajo del Agente SQL Server.
Nota
La recuperación acelerada de bases de datos (ADR) puede mitigar el tiempo de recuperación. Para más información, consulte Recuperación acelerada de bases de datos.
Al igual que un grupo de disponibilidad, las FCI abstraen cuál es el nodo del clúster subyacente que las está hospedando. Una FCI siempre conserva el mismo nombre. Las aplicaciones y los usuarios finales nunca se conectan a los nodos. En su lugar, usan el nombre único asignado a la FCI. Una FCI puede participar en un grupo de disponibilidad como una de las instancias que hospeda una réplica principal o secundaria.
En la lista siguiente se resaltan algunas diferencias con las FCI en Windows Server frente a Linux:
- En Windows Server, una FCI es parte del proceso de instalación. Configure una FCI en Linux después de instalar SQL Server.
- Linux solo admite una instalación única de SQL Server por host, por lo que todas las FCI son una instancia predeterminada. Windows Server admite hasta 25 FCI por WSFC.
- El nombre común usado por las FCI en Linux se define en DNS, y debe ser el mismo que el recurso creado para la FCI.
Trasvase de registros
Si los objetivos de tiempo de recuperación y punto de recuperación son más flexibles, o las bases de datos no son muy críticas, el trasvase de registros es otra característica de disponibilidad probada en SQL Server. En función de las copias de seguridad nativas de SQL Server, el proceso para el trasvase de registros genera de forma automática copias de seguridad del registro de transacciones, las copia en una o varias instancias conocidas como estado de espera semiactiva y aplica automáticamente las copias de seguridad del registro de transacciones a dicho estado de espera. El trasvase de registros usa trabajos del Agente SQL Server para automatizar el proceso de copia de seguridad, copia y aplicación de las copias de seguridad del registro de transacciones.
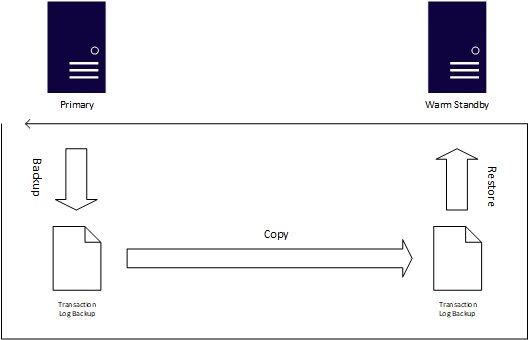
La mayor ventaja de usar el envío de registros es que tiene en cuenta el error humano, ya que permite retrasar la aplicación de los registros de transacciones. Por ejemplo, si alguien emite una UPDATE sin una cláusula WHERE, es posible que el modo de espera no tenga el cambio, por lo que puede pasar a esa opción mientras se realiza la reparación del sistema principal. Aunque el trasvase de registros es fácil de configurar, el cambio de la principal a una espera activa, conocida como cambio de rol, siempre es manual. Inicia un cambio de rol a través de Transact-SQL y, al igual que un Grupo de Disponibilidad, debes sincronizar manualmente todos los objetos que no se registraron en el registro de transacciones. Debe configurar el trasvase de registros por base de datos, mientras que un único grupo de disponibilidad puede contener varias bases de datos.
A diferencia de un grupo de disponibilidad o FCI, el trasvase de registros no tiene abstracción para un cambio de rol, que las aplicaciones deben ser capaces de controlar. Se podrían emplear técnicas como un alias de DNS (CNAME), pero esto tiene ventajas y desventajas, como el tiempo necesario para que DNS se actualice después del cambio.
Recuperación ante desastres
Cuando la ubicación de disponibilidad principal experimenta un evento catastrófico, como un terremoto o una inundación, la empresa debe estar preparada para que sus sistemas se pongan a funcionar en cualquier otro lugar. En esta sección se explica cómo las características de disponibilidad de SQL Server pueden ayudar con la continuidad empresarial.
Grupos de disponibilidad
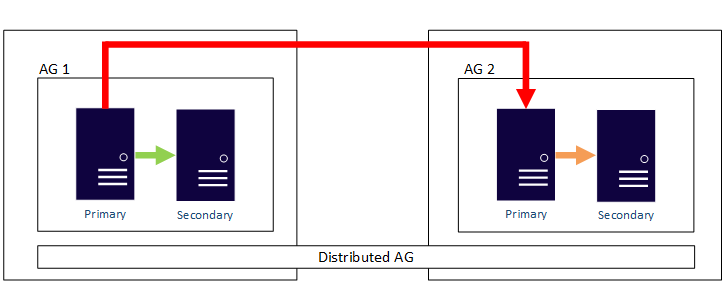
Una de las ventajas de los grupos de disponibilidad es que puede configurar tanto la alta disponibilidad como la recuperación ante desastres mediante una sola función. Sin necesidad de garantizar que el almacenamiento compartido tenga también una alta disponibilidad, es mucho más fácil tener réplicas que sean locales en un centro de datos para la alta disponibilidad y remotas en otros centros de datos para la recuperación ante desastres, cada una con almacenamiento independiente. El hecho de tener copias adicionales de la base de datos es la compensación para asegurar la redundancia. En el diagrama siguiente se muestra un ejemplo de un grupo de disponibilidad (AG) que abarca varios centros de datos. Una réplica principal es responsable de mantener todas las réplicas secundarias sincronizadas.

Fuera de un grupo de disponibilidad con un tipo de clúster None, un grupo de disponibilidad requiere que todas las réplicas formen parte del mismo clúster subyacente, ya sea un WSFC o una solución de clúster externo. En el diagrama anterior, el WSFC se extiende para funcionar en dos centros de datos diferentes, lo que agrega complejidad independientemente de la plataforma (Windows Server o Linux). El ajuste de clústeres a distancia aumenta la complejidad.
Introducido en SQL Server 2016 (13.x), un grupo de disponibilidad distribuido permite que un grupo de disponibilidad abarque grupos de disponibilidad configurados en clústeres diferentes. Esto elimina la necesidad de que todos los nodos participen en el mismo clúster, lo que facilita en gran medida la configuración de la recuperación ante desastres. Para obtener más información sobre los grupos de disponibilidad distribuidos, vea Grupos de disponibilidad distribuidos.
Instancias de clúster de conmutación por error
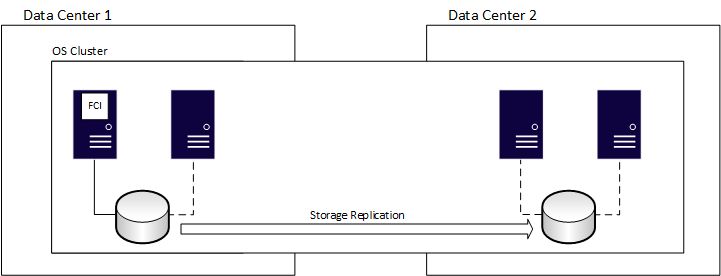
Puede utilizar FCIs para la recuperación ante desastres. Al igual que con un grupo de disponibilidad (AG) normal, debe extender el mecanismo del clúster subyacente a todas las ubicaciones, lo que agrega complejidad. Para las CFIs, también se debe tener en cuenta el almacenamiento compartido. Los sitios primarios y secundarios necesitan acceder a los mismos discos. Para asegurarse de que el almacenamiento usado por la FCI existe en ambos sitios, use un método externo, como la funcionalidad proporcionada por el proveedor de almacenamiento en la capa de hardware. Como alternativa, use réplica de almacenamiento en Windows Server.
Trasvase de registros
El trasvase de registros es uno de los métodos más antiguos para proporcionar recuperación ante desastres para las bases de datos de SQL Server. El trasvase de registros se suele usar con grupos de disponibilidad y FCI para proporcionar una recuperación ante desastres rentable y más sencilla, donde otras opciones podrían ser difíciles debido al entorno, las aptitudes administrativas o el presupuesto. De forma similar al caso de alta disponibilidad para el envío de registros, muchos entornos retrasan la carga del registro de transacciones para considerar errores humanos.
Migraciones y actualizaciones
Cuando una organización implementa nuevas instancias o actualiza las antiguas, no puede tolerar interrupciones prolongadas. En esta sección se describe cómo se pueden usar las características de disponibilidad de SQL Server para minimizar el tiempo de inactividad en un cambio de arquitectura planeado, cambio de servidor, cambio de plataforma (como Windows Server a Linux o viceversa) o durante la aplicación de revisiones.
Nota
También puede usar otros métodos, como copias de seguridad y restauraciones, para migraciones y actualizaciones. En este artículo no se describen esos métodos.
Grupos de disponibilidad
Puede actualizar una instancia existente que contenga uno o varios grupos de disponibilidad (AG) implementados a versiones posteriores de SQL Server. Aunque esta actualización requiere cierta cantidad de tiempo de inactividad, se puede minimizar con la cantidad correcta de planeamiento.
Si desea migrar a nuevos servidores sin cambiar la configuración (incluido el sistema operativo o la versión de SQL Server), agregue esos servidores como nodos al clúster subyacente existente y, a continuación, agréguelos al grupo de disponibilidad. Una vez que la réplica o las réplicas estén en el estado adecuado, realice una conmutación manual a un nuevo servidor. A continuación, quite los servidores antiguos del AG y desactívelos.
Los grupos de disponibilidad distribuidos son también otro método para migrar a una configuración nueva o actualizar SQL Server. Dado que un grupo de disponibilidad distribuido admite diferentes grupos de disponibilidad subyacentes en distintas arquitecturas, puede cambiar de SQL Server 2019 (15.x) que se ejecuta en Windows Server 2019 a SQL Server 2025 (17.x) que se ejecuta en Windows Server 2025.
Por último, los grupos de disponibilidad (AG) con un tipo de clúster de None son útiles para la migración o actualización. No se pueden mezclar tipos de clúster en una configuración típica de AG (grupo de disponibilidad), por lo que todas las réplicas deben ser de tipo Ninguno. Un grupo de disponibilidad distribuido se puede usar para abarcar grupos de disponibilidad configurados con diferentes tipos de clúster. Este método también se admite en todas las plataformas de sistema operativo diferentes.
Todas las variantes de AGs para migraciones y actualizaciones permiten la sincronización de datos, la parte más lenta del trabajo, a distribuirse a lo largo del tiempo. Cuando llegue el momento de iniciar el cambio a la nueva configuración, la migración es una breve interrupción, frente a un largo período de tiempo de inactividad en el que todo el trabajo, incluida la sincronización de datos, debe completarse.
Los grupos de disponibilidad (AG) pueden proporcionar un tiempo de inactividad mínimo durante la aplicación de parches al sistema operativo subyacente al realizar un traspaso manual de la réplica principal a una réplica secundaria mientras la actualización está en curso. Desde una perspectiva del sistema operativo, esto es más común en Windows Server, ya que el mantenimiento del sistema operativo subyacente puede requerir un reinicio. La aplicación de revisiones a Linux a veces necesita un reinicio, pero es menos común.
Otra manera de minimizar el tiempo de inactividad es aplicar revisiones a las instancias de SQL Server que participan en un grupo de disponibilidad, en función de la complejidad de la arquitectura del grupo de disponibilidad. Primero se actualiza una réplica secundaria. Una vez aplicados los parches al número correcto de réplicas, realice una conmutación manual de la réplica principal a otro nodo para realizar la actualización. Actualice las réplicas secundarias restantes en ese punto.
Instancias de clúster de conmutación por error
Las FCI por sí solas no pueden ayudar con una migración o actualización tradicional. Debe configurar un grupo de disponibilidad (AG) o envío de registros para las bases de datos de la FCI y tener en cuenta todos los demás objetos. Sin embargo, los FCI en Windows Server siguen siendo una opción popular cuando necesitas aplicar actualizaciones a los servidores de Windows subyacentes. Cuando se inicia una conmutación por error manual, la breve interrupción minimiza el tiempo en que la instancia estaría no disponible mientras se actualiza Windows Server.
Puede actualizar una FCI en su lugar a versiones posteriores de SQL Server. Para más información, consulte Actualización de una instancia de clúster de conmutación por error.
Trasvase de registros
El trasvase de registros sigue siendo una opción popular para migrar y actualizar bases de datos. De forma similar a los grupos de disponibilidad, pero esta vez utilizando el registro de transacciones como método de sincronización, la propagación de datos se puede iniciar antes del cambio de servidor. En el momento del cambio, una vez que se detiene todo el tráfico en el origen, será necesario tomar, copiar y aplicar un registro de transacciones final a la nueva configuración. En ese momento, la base de datos se puede poner en línea.
El envío de registros suele ser más tolerante a redes más lentas y, aunque el cambio puede tardar ligeramente más que uno hecho con un grupo de disponibilidad o un grupo de disponibilidad distribuido, normalmente se mide en minutos, no en horas, ni días ni semanas.
De forma similar a los grupos de disponibilidad, el trasvase de registros puede proporcionar una manera de cambiar a otro servidor durante una ventana de mantenimiento.
Otros métodos de implementación de SQL Server y disponibilidad
Hay otros dos métodos de implementación para SQL Server en Linux: contenedores y uso de Azure (u otro proveedor de nube pública). La necesidad general de disponibilidad existe independientemente de cómo se implemente SQL Server. Estos dos métodos tienen algunas consideraciones especiales al hacer que SQL Server tenga alta disponibilidad.
Contenedores y opciones de alta disponibilidad y recuperación ante desastres de SQL Server
La implementación de contenedores de SQL Server es una manera de simplificar el aprovisionamiento, el escalado y la administración del ciclo de vida de SQL Server entre entornos. Un contenedor es una imagen completa lista para ejecutar de SQL Server.
Dependiendo de la plataforma de contenedor, por ejemplo, al usar un orquestador de contenedores como Kubernetes, si se pierde el contenedor, se puede implementar de nuevo y asociar al almacenamiento compartido que se usó. Aunque esto proporciona cierta resistencia, hay cierto tiempo de inactividad asociado a la recuperación de la base de datos y no es realmente de alta disponibilidad, como lo sería al usar un grupo de disponibilidad o una FCI.
Si desea configurar la alta disponibilidad para contenedores de SQL Server implementados en Kubernetes o plataformas que no son de Kubernetes, puede usar DH2i DxEnterprise como una de las soluciones de agrupación en clústeres, sobre la que puede configurar un grupo de disponibilidad en modo de alta disponibilidad. Esta opción proporciona el objetivo de punto de recuperación (RPO) y el objetivo de tiempo de recuperación (RTO) esperados de una solución de alta disponibilidad.
Implementación de máquinas virtuales basadas en Linux
Linux se puede implementar con SQL Server en Azure Virtual Machines linux. Al igual que con las instalaciones basadas en el entorno local, una instalación admitida requiere el uso de aislamiento de un nodo que ha fallado, externo al agente de clúster. La barrera de nodos se proporciona a través de agentes de disponibilidad de barreras. Algunas distribuciones los incluyen como parte de la plataforma, mientras que otras dependen de los proveedores externos de hardware y software. Consulte la distribución de Linux preferida para ver qué formas de barrera de nodo se proporcionan para que se pueda implementar una solución compatible en la nube pública.
Hay disponibles guías para instalar SQL Server en Linux para las siguientes distribuciones:
- Inicio rápido: instalar SQL Server y crear una base de datos en Red Hat
- Inicio rápido: Instalación de SQL Server y creación de una base de datos en Ubuntu
- Inicio rápido: Instalación de SQL Server y creación de una base de datos en SUSE Linux Enterprise Server
Escalabilidad de lectura
Las réplicas secundarias tienen la capacidad de usarse para las consultas de solo lectura. Existen dos maneras en las que eso puede lograrse por medio de un AG.
- Permitir el acceso directo al secundario
- Configurar el enrutamiento de solo lectura, que requiere el uso del listener. SQL Server 2016 (13.x) introdujo la posibilidad de equilibrar la carga de las conexiones de solo lectura a través del cliente de escucha mediante un algoritmo round robin, lo que permite a las solicitudes de solo lectura su expansión por todas las réplicas legibles.
Nota
Las réplicas secundarias legibles solo están disponibles en Enterprise Edition. Cada instancia que hospeda una réplica legible necesita una licencia de SQL Server.
El escalado de copias legibles de una base de datos mediante grupos de disponibilidad se introdujo por primera vez con grupos de disponibilidad distribuidos en SQL Server 2016 (13.x). Esta característica ofrece copias de solo lectura de la base de datos no solo localmente, sino también regional y globalmente, con una configuración mínima. Esta configuración reduce el tráfico de red y la latencia al hacer que las consultas se ejecuten localmente. Cada réplica principal de un grupo de disponibilidad puede inicializar otros dos grupos de disponibilidad, incluso si no es la copia de lectura y escritura completa, y cada grupo de disponibilidad distribuido puede admitir hasta 27 copias legibles de los datos.

En SQL Server 2017 (14.x) y versiones posteriores, puede crear una solución casi en tiempo real con grupos de disponibilidad configurados con un tipo de clúster None. Si su objetivo es usar grupos de disponibilidad principalmente para réplicas secundarias legibles y no para disponibilidad, este enfoque elimina la complejidad de usar un WSFC o una solución de clúster externo en Linux. Ofrece las ventajas comprensibles de un grupo de disponibilidad mediante un método de implementación más sencillo.
La única advertencia principal es que, debido a que no hay ningún clúster subyacente con un tipo de clúster None, la configuración del enrutamiento de solo lectura es un poco diferente. Desde una perspectiva de SQL Server, un cliente de escucha sigue siendo necesario para enrutar las solicitudes, incluso si no hay ningún clúster. En lugar de configurar un agente de escucha tradicional, use la dirección IP o el nombre de la réplica principal. A continuación, la réplica principal enruta las solicitudes de solo lectura.
Un modo de espera activa de trasvase de registros se puede configurar técnicamente para un uso legible restaurando la base de datos WITH STANDBY. Sin embargo, dado que los registros de transacciones requieren el uso exclusivo de la base de datos para la restauración, los usuarios no podrán acceder a la base de datos mientras esto ocurre. Por ello, el trasvase de registros es una solución menos idónea, especialmente si se necesitan datos casi en tiempo real.
A diferencia de la replicación transaccional en la que todos los datos están activos, cada réplica secundaria en un escenario de lectura a escala es una copia exacta de la réplica principal. La réplica no está en un estado en el que se pueden aplicar índices únicos. Si se requieren índices para la generación de informes o si es necesario manipular datos, debe crear esos índices en las bases de datos de la réplica principal. Si necesita esa flexibilidad, la replicación es una mejor solución para datos legibles.
Interoperabilidad de distribución multiplataforma y Linux
Con la compatibilidad con SQL Server en Windows Server y Linux, en esta sección se explica cómo pueden trabajar conjuntamente con fines de disponibilidad, además de otros fines. También trata la historia de las soluciones que incorporan más de una distribución de Linux.
Nota
No hay escenarios en los que una instancia de clúster de conmutación por error (FCI) basada en WSFC o un grupo de alta disponibilidad (AG) funcione directamente con un grupo de alta disponibilidad o una FCI basada en Linux. Un clúster de conmutación por error de Windows Server (WSFC) no se puede ampliar con un nodo Pacemaker ni viceversa.
Grupos de disponibilidad distribuidos
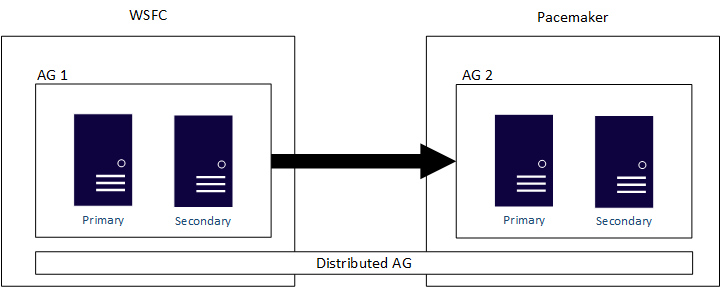
Los grupos de disponibilidad distribuidos están diseñados para abarcar las configuraciones de grupo de disponibilidad, con independencia de que los dos clústeres subyacentes debajo de los grupos de disponibilidad sean dos clústeres WSFC diferentes, distribuciones de Linux, o uno esté en un clúster WSFC y otro en Linux. Un grupo de disponibilidad distribuido es el principal método para lograr una solución multiplataforma. Un grupo de disponibilidad distribuido es también la solución principal para las migraciones del tipo de una conversión desde una infraestructura de SQL Server basada en Windows Server a otra basada en Linux, en caso de que sea esto lo que quiere hacer su empresa. Como se indicó anteriormente, los grupos de disponibilidad y, especialmente los grupos de disponibilidad distribuidos, minimizarían el tiempo que una aplicación no estaría disponible para su uso. En el diagrama siguiente se muestra un ejemplo de un grupo de recursos distribuido que abarca un WSFC y Pacemaker.
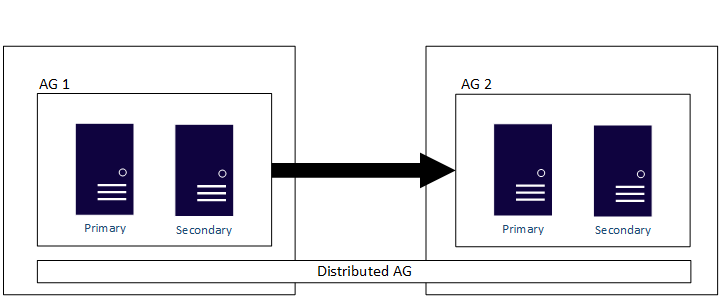
Si configura un grupo de disponibilidad con un tipo de clúster 'Ninguno', este puede abarcar Windows Server, Linux y varias distribuciones de Linux. Puesto que esta configuración no es verdadera de alta disponibilidad, no la use para implementaciones críticas. En su lugar, úselo para escenarios de escalado de lectura o de migración y actualización.
Trasvase de registros
El trasvase de registros se basa en la copia de seguridad y restauración, por lo que no hay diferencias en las bases de datos, las estructuras de archivos y otros elementos de SQL Server en Windows Server frente a SQL Server en Linux. Puede configurar el trasvase de registros entre una instalación de SQL Server basada en Windows Server y una linux, y entre distribuciones de Linux. Todo lo demás permanece igual.
Al igual que con un AG, el trasvase de registros no funciona cuando el servidor de origen está en una versión principal de SQL Server superior, mientras que el servidor de destino se encuentra en una versión principal inferior.
Resumen
Puede hacer que las instancias y las bases de datos de SQL Server 2017 (14.x) y versiones posteriores tengan una alta disponibilidad con las mismas características en Windows Server y Linux. Además de los escenarios de disponibilidad estándar de alta disponibilidad local y recuperación ante desastres, puede minimizar el tiempo de inactividad asociado a las actualizaciones y migraciones mediante las características de disponibilidad de SQL Server. Los grupos de disponibilidad (GD) también pueden proporcionar copias adicionales de una base de datos como parte de la misma arquitectura para escalar copias legibles. Tanto si va a implementar una nueva solución como si está considerando la posibilidad de aplicar una actualización, SQL Server tiene la disponibilidad y confiabilidad que necesita.