Carga de datos en un grupo de SQL dedicado en Azure Synapse Analytics con SQL Server Integration Services (SSIS)
Se aplica a:![]() Azure Synapse Analytics
Azure Synapse Analytics
Cree un paquete de SQL Server Integration Services (SSIS) para cargar datos en un grupo de SQL dedicado en Azure Synapse Analytics. Si quiere, puede reestructurar, transformar y limpiar los datos a medida que pasan a través del flujo de datos de SSIS.
En este artículo se explica cómo realizar las siguientes tareas:
- Crear un nuevo proyecto de Integration Services en Visual Studio.
- Diseñar un paquete de SSIS que cargue datos del origen en el destino.
- Ejecutar el paquete de SSIS para cargar los datos.
Conceptos básicos
El paquete es la unidad de trabajo básica en SSIS. Los paquetes relacionados se agrupan en proyectos. Los proyectos y los paquetes de diseño se crean en Visual Studio con SQL Server Data Tools. El proceso de diseño es un proceso visual en el que se arrastran componentes del cuadro de herramientas y se colocan en la superficie de diseño, se conectan y se establecen sus propiedades. Después de terminar el paquete, puede ejecutarlo y puede implementarlo opcionalmente en SQL Server o SQL Database para una administración, supervisión y seguridad globales.
Una introducción detallada a SSIS queda fuera del ámbito de este artículo. Para más información, vea los siguientes artículos:
Opciones para cargar datos en Azure Synapse Analytics con SSIS
SQL Server Integration Services (SSIS) es un conjunto de herramientas flexible que proporciona una serie de opciones para conectarse a Azure Synapse Analytics y cargar datos en él.
El método preferido, que proporciona el mejor rendimiento, consiste en crear un paquete que use la tarea de carga de Azure SQL DW para cargar los datos. Esta tarea encapsula la información de origen y destino. Se supone que los datos de origen se almacenan localmente en archivos de texto delimitado.
De forma alternativa, puede crear un paquete que use una tarea Flujo de datos que contenga un origen y un destino. Este enfoque es compatible con una amplia gama de orígenes de datos, incluidos SQL Server y Azure Synapse Analytics.
Prerequisites
Para realizar este tutorial, necesita lo siguiente:
- SQL Server Integration Services (SSIS) . SSIS es un componente de SQL Server y exige una versión con licencia, de desarrollador o de evaluación de SQL Server. Para obtener una versión de evaluación de SQL Server, vea Evaluaciones de SQL Server.
- Visual Studio (opcional). Para obtener la edición gratuita de Visual Studio Community, vea Visual Studio Community. Si no quiere instalar Visual Studio, puede instalar solo SQL Server Data Tools (SSDT). SSDT instala una versión de Visual Studio con funcionalidad limitada.
- SQL Server Data Tools para Visual Studio (SSDT) . Para obtener SQL Server Data Tools para Visual Studio, vea Descargar SQL Server Data Tools (SSDT).
- Permisos y una base de datos de Azure Synapse Analytics. En este tutorial se explica cómo conectar un grupo de SQL dedicado con una instancia de Azure Synapse Analytics y cargar datos en ella. Necesita permisos para conectarse, crear una tabla y cargar datos.
Crear un proyecto de Integration Services
- Inicie Visual Studio.
- En el menú Archivo, seleccione Nuevo | Proyecto.
- Vaya a los tipos de proyecto Instalados | Plantillas | Inteligencia empresarial | Integration Services.
- Seleccione Proyecto de Integration Services. Proporcione los valores de Nombre y Ubicación y luego seleccione Aceptar.
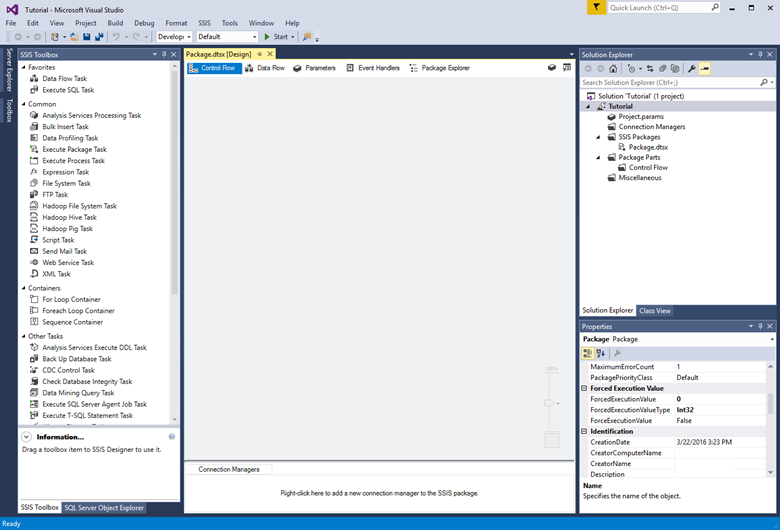
Se abre Visual Studio y crea un nuevo proyecto de Integration Services (SSIS). Luego Visual Studio abre el diseñador para el nuevo paquete único de SSIS (Package.dtsx) en el proyecto. Se ven las siguientes áreas de pantalla:
En el lado izquierdo, el cuadro de herramientas de componentes de SSIS.
En el centro, la superficie de diseño, con varias pestañas. Normalmente se usan al menos las pestañas Flujo de control y Flujo de datos.
En el lado derecho, los paneles Explorador de soluciones y Propiedades.
Opción 1: usar la tarea de carga de SQL DW
El primer enfoque es un paquete que usa la tarea de carga de SQL DW. Esta tarea encapsula la información de origen y destino. Se supone que los datos de origen se almacenan en archivos de texto delimitado, ya sea localmente o en Azure Blob Storage.
Requisitos previos de la opción 1
Para seguir el tutorial con esta opción, necesitará lo siguiente:
Feature Pack de Microsoft SQL Server Integration Services para Azure. La tarea de carga de SQL DW es un componente del Feature Pack.
Una cuenta de Azure Blob Storage. La tarea de carga de SQL DW carga datos desde Azure Blob Storage en Azure Synapse Analytics. Puede cargar los archivos que ya están en el Blob Storage, o bien puede cargar los archivos de su equipo. Si selecciona los archivos en el equipo, la tarea de carga de SQL DW los cargará en Blob Storage en primer lugar para el almacenamiento provisional y, después, los cargará en su grupo de SQL dedicado.
Agregar y configurar la tarea de carga de SQL DW
Arrastre una tarea de carga de SQL DW desde el cuadro de herramientas al centro de la superficie de diseño (en la pestaña Flujo de control).
Haga doble clic en la tarea para abrir el Editor de la tarea de carga de SQL DW.
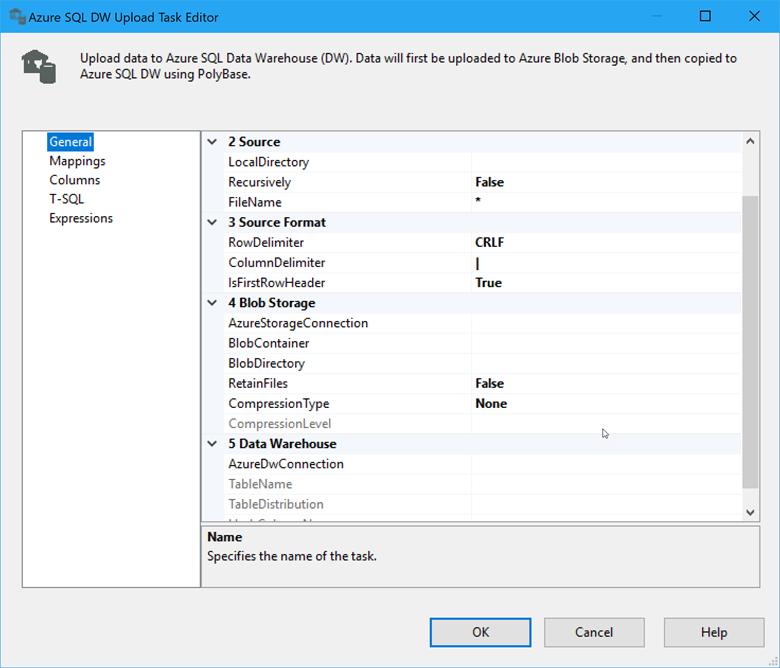
Configure la tarea con la ayuda de las instrucciones del artículo Tarea de carga de Azure SQL DW. Dado que esta tarea encapsula tanto la información de origen como de destino, así como las asignaciones entre las tablas de origen y destino, el editor de tareas tiene varias páginas de ajustes para configurar.
Crear una solución similar manualmente
Para obtener más control, puede crear manualmente un paquete que emule el trabajo realizado por la tarea de carga de SQL DW.
Use la tarea de carga en el blob de Azure para cargar los datos en Azure Blob Storage. Para obtener la tarea de carga en el blob de Azure, descargue Feature pack de Microsoft SQL Server Integration Services para Azure.
Después, use la tarea Ejecutar SQL de SSIS para iniciar un script de PolyBase que cargue los datos en su grupo de SQL dedicado. Para obtener un ejemplo que cargue datos desde Azure Blob Storage en un grupo de SQL dedicado (pero no con SSIS), vea Tutorial: Carga de datos en Azure Synapse Analytics.
Opción 2: usar un origen y un destino
El segundo enfoque es un paquete típico que usa una tarea Flujo de datos que contiene un origen y un destino. Este enfoque es compatible con una amplia gama de orígenes de datos, incluidos SQL Server y Azure Synapse Analytics.
En este tutorial se usa SQL Server como origen de datos. SQL Server se ejecuta en local o en una máquina virtual de Azure.
Para conectarse a SQL Server y a un grupo de SQL dedicado, puede usar un administrador de conexiones de ADO.NET y un origen y un destino, o bien un administrador de conexiones OLE DB y un origen y un destino. En este tutorial se usa ADO NET porque tiene las mínimas opciones de configuración. OLE DB puede proporcionar un rendimiento ligeramente mejor que ADO NET.
Como método abreviado, puede usar el Asistente para importación y exportación de SQL Server para crear el paquete básico. Después, guarde el paquete y ábralo en Visual Studio o SSDT para verlo y personalizarlo. Para más información, vea Importar y exportar datos con el Asistente para importación y exportación de SQL Server.
Requisitos previos de la opción 2
Para seguir el tutorial con esta opción, necesitará lo siguiente:
Datos de ejemplo. En este tutorial se usan datos de ejemplo almacenados en SQL Server en la base de datos de ejemplo AdventureWorks como datos de origen para cargar en un grupo de SQL dedicado. Para obtener la base de datos de ejemplo AdventureWorks, vea Bases de datos de ejemplo de AdventureWorks.
Una regla de firewall. Tiene que crear una regla de firewall en su grupo de SQL dedicado con la dirección IP del equipo local para poder cargar datos en dicho grupo.
Crear el flujo de datos básico
Arrastre una tarea Flujo de datos desde el cuadro de herramientas al centro de la superficie de diseño (en la pestaña Flujo de control).
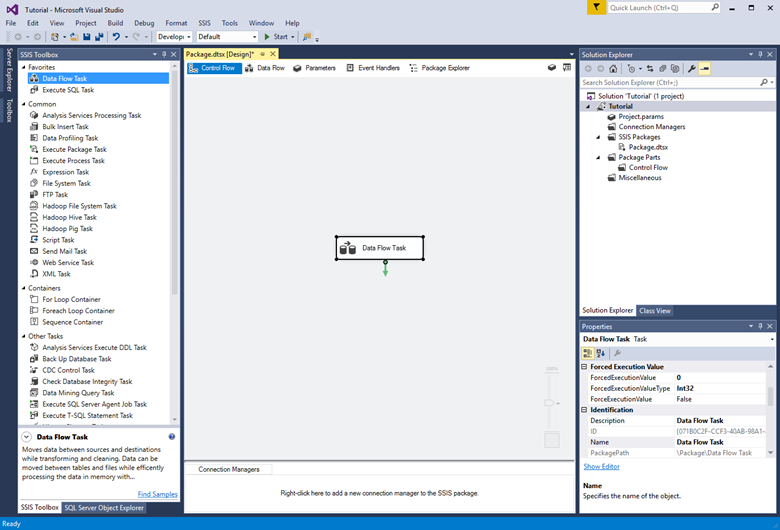
Haga doble clic en la tarea Flujo de datos para ir a la pestaña Flujo de datos.
En la lista Otros orígenes del cuadro de herramientas, arrastre un origen de ADO.NET a la superficie de diseño. Con el adaptador de origen aún seleccionado, cambie su nombre a Origen de SQL Server en el panel Propiedades.
Desde la lista Otros destinos del cuadro de herramientas, arrastre un destino de ADO.NET a la superficie de diseño bajo el origen de ADO.NET. Con el adaptador de destino aún seleccionado, cambie su nombre a Destino de SQL DW en el panel Propiedades.
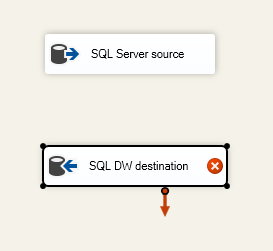
Configurar el adaptador de origen
Haga doble clic en el adaptador de origen para abrir el Editor de orígenes de ADO.NET.
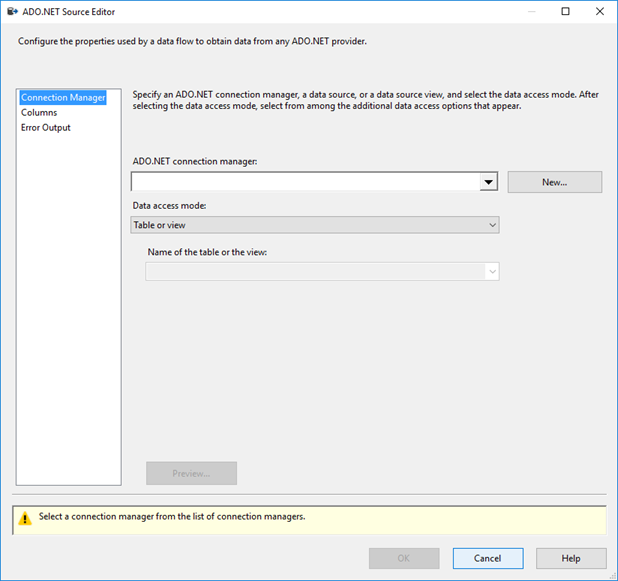
En la pestaña Administrador de conexiones del Editor de orígenes de ADO.NET, haga clic en el botón Nuevo situado junto a la lista Administrador de conexiones de ADO.NET para abrir el cuadro de diálogo Configurar el administrador de conexiones ADO.NET y crear la configuración de conexión para la base de datos de SQL Server desde la que carga datos este tutorial.
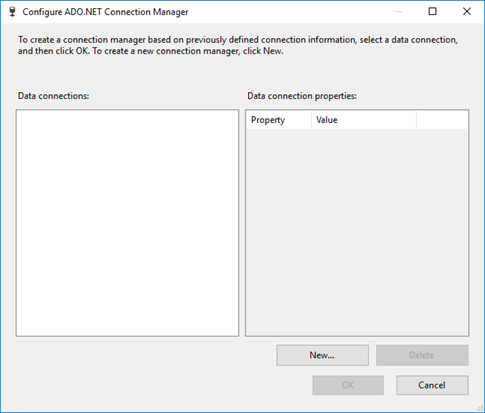
En el cuadro de diálogo Configurar el administrador de conexiones ADO.NET, haga clic en el botón Nuevo para abrir el cuadro de diálogo Administrador de conexiones y crear una nueva conexión de datos.
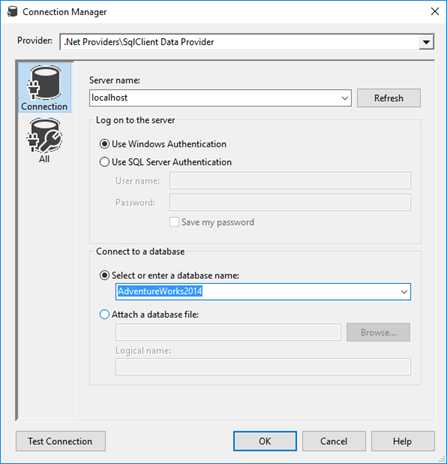
En el cuadro de diálogo Administrador de conexiones, haga lo siguiente.
En Proveedor, seleccione el proveedor de datos SqlClient.
En Nombre del servidor, escriba el nombre del servidor de SQL Server.
En la sección Iniciar sesión en el servidor, seleccione o escriba la información de autenticación.
En la sección Conectar con una base de datos, seleccione la base de datos de ejemplo AdventureWorks.
Haga clic en Probar conexión.

En el cuadro de diálogo que informa de los resultados de la prueba de conexión, haga clic en Aceptar para volver al cuadro de diálogo Administrador de conexiones.
En el cuadro de diálogo Administrador de conexiones, haga clic en Aceptar para volver al cuadro de diálogo Configurar el administrador de conexiones ADO.NET.
En el cuadro de diálogo Configurar el administrador de conexiones ADO.NET, haga clic en Aceptar para volver al Editor de orígenes de ADO.NET.
En el Editor de orígenes de ADO.NET, en la lista Nombre de la tabla o la vista, seleccione la tabla Sales.SalesOrderDetail.
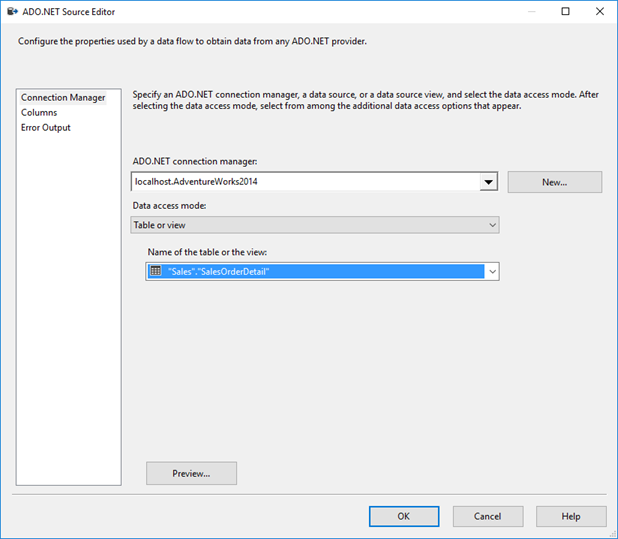
Haga clic en Vista previa para ver las 200 primeras filas de datos de la tabla de origen en el cuadro de diálogo Vista previa de los resultados de la consulta.
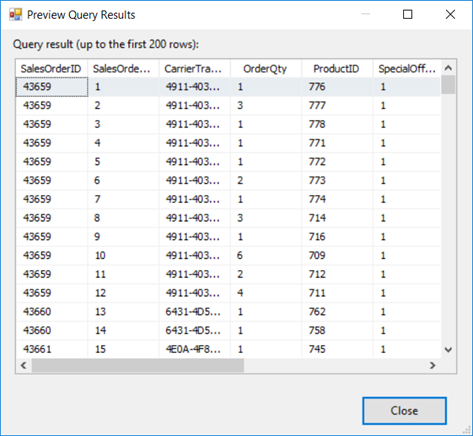
En el cuadro de diálogo Vista previa de los resultados de la consulta, haga clic en Cerrar para volver al Editor de orígenes de ADO.NET.
En el Editor de orígenes de ADO.NET, haga clic en Aceptar para acabar de configurar el origen de datos.
Conectar el adaptador de origen al adaptador de destino
Seleccione el adaptador de origen en la superficie de diseño.
Seleccione la flecha azul que va desde el adaptador de origen y arrástrela al editor de destino hasta que quede en su lugar.
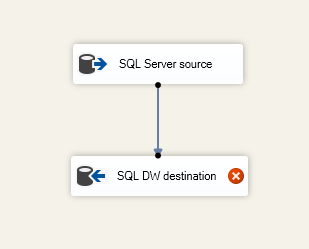
En un paquete de SSIS típico, se usa una serie de otros componentes del cuadro de herramientas de SSIS entre el origen y el destino para reestructurar, transformar y limpiar los datos a medida que pasan a través del flujo de datos de SSIS. Para que este ejemplo sea lo más sencillo posible, se conecta el origen directamente al destino.
Configurar el adaptador de destino
Haga doble clic en el adaptador de destino para abrir el Editor de destinos de ADO.NET.
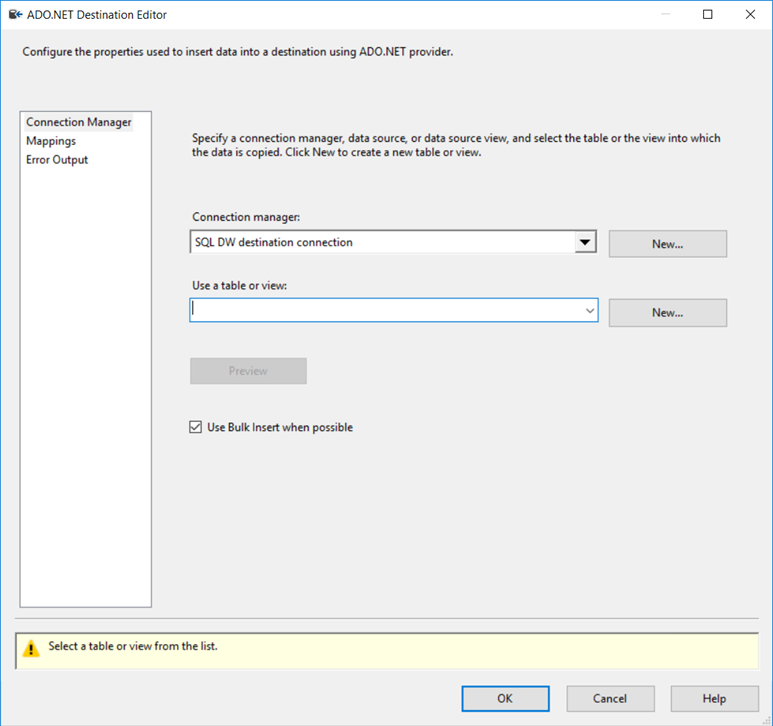
En la pestaña Administrador de conexiones del Editor de destinos de ADO.NET, haga clic en el botón Nuevo situado junto a la lista Administrador de conexiones para abrir el cuadro de diálogo Configurar el administrador de conexiones ADO.NET y crear la configuración de conexión para la base de datos de Azure Synapse Analytics en la que carga datos este tutorial.
En el cuadro de diálogo Configurar el administrador de conexiones ADO.NET, haga clic en el botón Nuevo para abrir el cuadro de diálogo Administrador de conexiones y crear una nueva conexión de datos.
En el cuadro de diálogo Administrador de conexiones, haga lo siguiente.
- En Proveedor, seleccione el proveedor de datos SqlClient.
- En Nombre del servidor, escriba el nombre del grupo de SQL dedicado.
- En la sección Iniciar sesión en el servidor, seleccione Usar la autenticación de SQL Server y escriba la información de autenticación.
- En la sección Conectar con una base de datos, seleccione una base de datos del grupo de SQL dedicado.
- Haga clic en Probar conexión.
- En el cuadro de diálogo que informa de los resultados de la prueba de conexión, haga clic en Aceptar para volver al cuadro de diálogo Administrador de conexiones.
- En el cuadro de diálogo Administrador de conexiones, haga clic en Aceptar para volver al cuadro de diálogo Configurar el administrador de conexiones ADO.NET.
En el cuadro de diálogo Configurar el administrador de conexiones ADO.NET, haga clic en Aceptar para volver al Editor de destinos de ADO.NET.
En el Editor de destinos de ADO.NET, haga clic en Nuevo junto a la lista Usar una tabla o una vista para abrir el cuadro de diálogo Crear tabla para crear una tabla de destino con una lista de columnas que coincida con la tabla de origen.
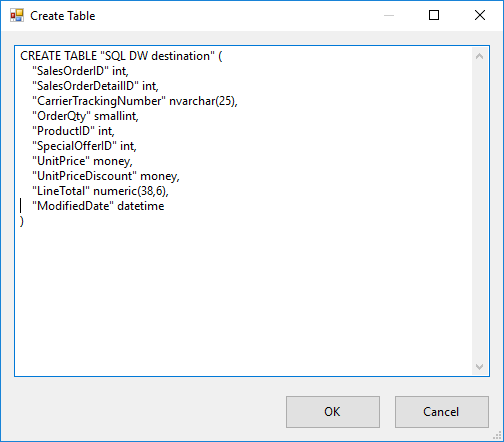
En el cuadro de diálogo Crear tabla, haga lo siguiente.
Cambie el nombre de la tabla de destino a SalesOrderDetail.
Quite la columna rowguid. El tipo de datos uniqueidentifier no se admite en grupos de SQL dedicados.
Cambie el tipo de datos de la columna LineTotal a money. El tipo de datos decimal no se admite en grupos de SQL dedicados. Para obtener información sobre los tipos de datos admitidos, vea CREATE TABLE (Azure Synapse Analytics, Almacenamiento de datos paralelos).
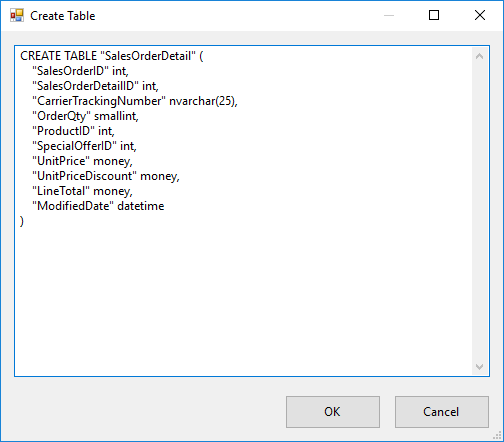
Haga clic en Aceptar para crear la tabla y volver al Editor de destinos de ADO.NET.
En el Editor de destinos de ADO.NET, seleccione la pestaña Asignaciones para ver cómo se asignan las columnas del origen a las del destino.
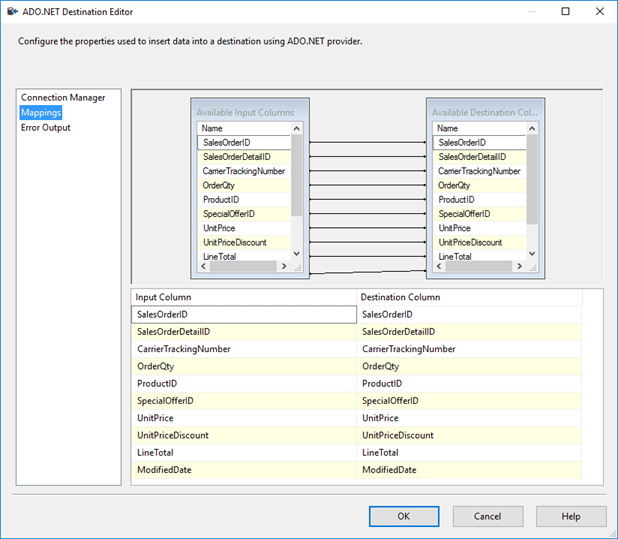
Haga clic en Aceptar para acabar de configurar el destino.
Ejecutar el paquete para cargar los datos
Para ejecutar el paquete, haga clic en el botón Iniciar de la barra de herramientas o seleccione una de las opciones Ejecutar del menú Depurar.
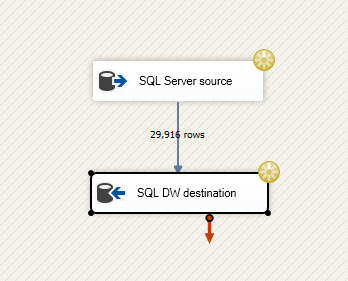
En los siguientes párrafos se describe lo que verá si ha creado el paquete con la segunda opción que se describe en este artículo, es decir, con un flujo de datos que contiene un origen y un destino.
A medida que el paquete comienza a ejecutarse, se ven ruedas amarillas que giran para indicar actividad, además del número de filas procesadas hasta el momento.
Cuando el paquete termina de ejecutarse, se ven marcas de verificación verdes para indicar el éxito, además del número total de filas de datos cargadas desde el origen en el destino.
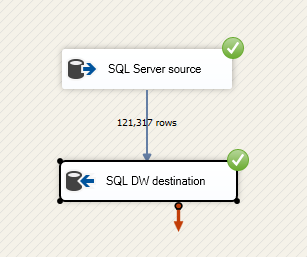
Felicidades. Ha usado correctamente SQL Server Integration Services para cargar datos en Azure Synapse Analytics.
Pasos siguientes
Obtenga más información sobre cómo depurar paquetes y solucionar los problemas que planteen en el entorno de diseño. Empiece aquí: Herramientas para solucionar problemas del desarrollo de paquetes.
Obtenga más información sobre cómo implementar los paquetes y los proyectos de SSIS en Integration Services Server u otra ubicación de almacenamiento. Empiece aquí: Implementación de proyectos y paquetes.
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de