Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server 2017 (14.x) y versiones posteriores
SQL Server 2017 (14.x) y versiones posteriores
En este artículo se explican los pasos para crear un grupo de disponibilidad (AG) Always On con una réplica en un servidor de Windows y la otra réplica en un servidor Linux.
Importante
Los grupos de disponibilidad multiplataforma de SQL Server, que incluyen réplicas heterogéneas con compatibilidad completa con alta disponibilidad y recuperación ante desastres, están disponibles con DH2i DxEnterprise. Para obtener más información, consulte Grupos de disponibilidad de SQL Server con sistemas operativos mixtos.
Vea el vídeo siguiente para obtener información sobre los grupos de disponibilidad multiplataforma con DH2i.
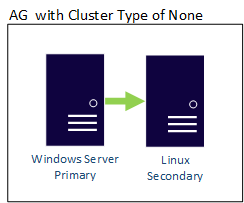
Esta configuración es multiplataforma porque las réplicas están en sistemas operativos diferentes. Use esta configuración para la migración de una plataforma a la otra o para la recuperación ante desastres (DR). Esta configuración no admite alta disponibilidad.
Antes de continuar, debe estar familiarizado con la instalación y configuración de instancias de SQL Server en Windows y Linux.
Escenario
En este escenario, hay dos servidores en sistemas operativos diferentes. Una instancia de Windows Server 2022 denominada WinSQLInstance hospeda la réplica principal. Un servidor Linux denominado LinuxSQLInstance hospeda la réplica secundaria.
Configuración del AG
Los pasos para crear el AG son los mismos que los pasos para crear un AG para cargas de trabajo de escalado de lectura. El tipo de clúster del grupo de disponibilidad es NONE, porque no hay ningún administrador de clústeres.
En el caso de los scripts de este artículo, los corchetes angulares < y > identifican los valores que debe reemplazar para su entorno. Los corchetes angulares en sí no son necesarios para los scripts.
Instale SQL Server 2022 (16.x) en Windows Server 2022, habilite los grupos de disponibilidad Always On desde el administrador de configuración de SQL Server y establezca la autenticación de modo mixto.
Sugerencia
Si va a validar esta solución en Azure, coloque ambos servidores en el mismo conjunto de disponibilidad para asegurarse de que se separan en el centro de datos.
Habilitación de grupos de disponibilidad
Para obtener instrucciones, consulte Habilitación o deshabilitación de la característica de grupo de disponibilidad AlwaysOn.
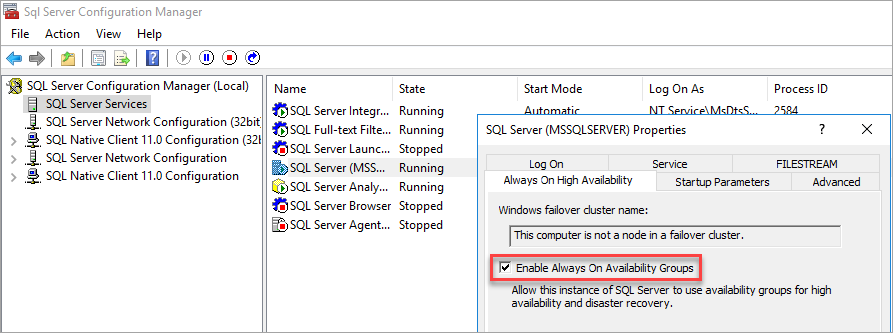
El administrador de configuración de SQL Server se da cuenta de que el equipo no es un nodo en un clúster de conmutación por error.
Después de habilitar los grupos de disponibilidad, reinicie SQL Server.
Configuración de la autenticación de modo mixto
Para obtener instrucciones, consulte Cambiar el modo de autenticación del servidor.
Instale SQL Server 2022 (16.x) en Linux. Para obtener instrucciones, consulte Guía de instalación de SQL Server en Linux. Habilite
hadrconmssql-conf.Para habilitar
hadrdesdemssql-confel símbolo del sistema, ejecute el siguiente comando:sudo /opt/mssql/bin/mssql-conf set hadr.hadrenabled 1Después de habilitar
hadr, reinicie la instancia de SQL Server:sudo systemctl restart mssql-server.serviceConfigure el archivo de
hostsen ambos servidores o registre los nombres de servidor con DNS.Abra los puertos de firewall para TCP 1433 y 5022 en Windows y Linux.
En la réplica principal, cree un inicio de sesión y una contraseña de base de datos.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GOPrecaución
La contraseña debe seguir la directiva de contraseña predeterminada de SQL Server. De forma predeterminada, la contraseña debe tener al menos ocho caracteres y contener caracteres de tres de los siguientes cuatro conjuntos: mayúsculas, minúsculas, dígitos en base 10 y símbolos. Las contraseñas pueden tener hasta 128 caracteres. Use contraseñas lo más largas y complejas posible.
En la réplica principal, cree una clave y un certificado maestros y, después, haga una copia de seguridad del certificado con una clave privada.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; CREATE CERTIFICATE dbm_certificate WITH SUBJECT = 'dbm'; BACKUP CERTIFICATE dbm_certificate TO FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.cer' WITH PRIVATE KEY ( FILE = 'C:\Program Files\Microsoft SQL Server\MSSQL16.MSSQLSERVER\MSSQL\DATA\dbm_certificate.pvk', ENCRYPTION BY PASSWORD = '<private-key-password>' ); GOPrecaución
La contraseña debe seguir la directiva de contraseña predeterminada de SQL Server. De forma predeterminada, la contraseña debe tener al menos ocho caracteres y contener caracteres de tres de los siguientes cuatro conjuntos: mayúsculas, minúsculas, dígitos en base 10 y símbolos. Las contraseñas pueden tener hasta 128 caracteres. Use contraseñas lo más largas y complejas posible.
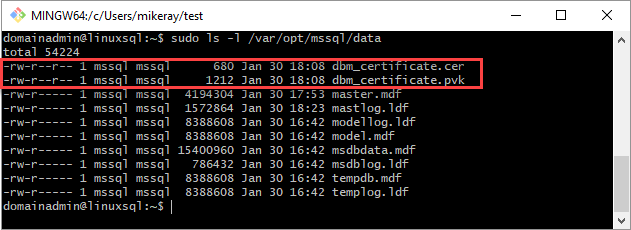
Copie el certificado y la clave privada en el servidor Linux (réplica secundaria) en
/var/opt/mssql/data. Puede usarpscppara copiar los archivos en el servidor Linux.Establezca el grupo y la propiedad de la clave privada y el certificado en
mssql:mssql.El siguiente script establece el grupo y la propiedad de los archivos.
sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.pvk sudo chown mssql:mssql /var/opt/mssql/data/dbm_certificate.cerEn el diagrama siguiente, la propiedad y el grupo están configurados correctamente para el certificado y la clave.
En la réplica secundaria, cree un inicio de sesión y una contraseña de base de datos y cree una clave maestra.
CREATE LOGIN dbm_login WITH PASSWORD = '<password>'; CREATE USER dbm_user FOR LOGIN dbm_login; GO CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<master-key-password>'; GOPrecaución
La contraseña debe seguir la directiva de contraseña predeterminada de SQL Server. De forma predeterminada, la contraseña debe tener al menos ocho caracteres y contener caracteres de tres de los siguientes cuatro conjuntos: mayúsculas, minúsculas, dígitos en base 10 y símbolos. Las contraseñas pueden tener hasta 128 caracteres. Use contraseñas lo más largas y complejas posible.
En la réplica secundaria, restaure el certificado que copió en
/var/opt/mssql/data.CREATE CERTIFICATE dbm_certificate AUTHORIZATION dbm_user FROM FILE = '/var/opt/mssql/data/dbm_certificate.cer' WITH PRIVATE KEY ( FILE = '/var/opt/mssql/data/dbm_certificate.pvk', DECRYPTION BY PASSWORD = '<private-key-password>' ); GOEn el ejemplo anterior, reemplace por
<private-key-password>la misma contraseña que usó al crear el certificado en la réplica principal.Cree un punto de conexión en la réplica principal.
CREATE ENDPOINT [Hadr_endpoint] AS TCP ( LISTENER_IP = (0.0.0.0), LISTENER_PORT = 5022 ) FOR DATABASE_MIRRORING ( ROLE = ALL, AUTHENTICATION = CERTIFICATE dbm_certificate, ENCRYPTION = REQUIRED ALGORITHM AES ); ALTER ENDPOINT [Hadr_endpoint] STATE = STARTED; GRANT CONNECT ON ENDPOINT::[Hadr_endpoint] TO [dbm_login]; GOImportante
El firewall debe estar abierto para el puerto TCP de escucha. En el script anterior, el puerto es 5022. Use cualquier puerto TCP disponible.
En la réplica secundaria, configure el punto de conexión. Repita el script anterior en la réplica secundaria para crear el endpoint.
En la réplica principal, cree el AG con
CLUSTER_TYPE = NONE. El script de ejemplo usaSEEDING_MODE = AUTOMATICpara crear el AG.Nota:
Cuando la instancia de Windows de SQL Server usa diferentes rutas de acceso para los archivos de datos y de registro, la propagación automática no se realiza correctamente en la instancia de Linux de SQL Server porque estas rutas de acceso no existen en la réplica secundaria. Para usar el siguiente script para un AG multiplataforma, la base de datos requiere la misma ruta de acceso para los archivos de datos y de registro en el servidor de Windows. También puede actualizar el script para establecer
SEEDING_MODE = MANUALy, después, realizar una copia de seguridad y restaurar la base de datos conNORECOVERYpara inicializar la base de datos.Este comportamiento se aplica a las imágenes de Azure Marketplace.
Para obtener más información sobre la propagación automática, vea Propagación automática - Diseño de disco.
Antes de ejecutar el script, actualice los valores de los AG.
Reemplace
<WinSQLInstance>por el nombre del servidor de la instancia de SQL Server de la réplica principal.Reemplace
<LinuxSQLInstance>por el nombre del servidor de la instancia de SQL Server de la réplica secundaria.
Para crear el AG, actualice los valores y ejecute el script en la réplica principal.
CREATE AVAILABILITY GROUP [ag1] WITH (CLUSTER_TYPE = NONE) FOR REPLICA ON N'<WinSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<WinSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL) ), N'<LinuxSQLInstance>' WITH ( ENDPOINT_URL = N'tcp://<LinuxSQLInstance>:5022', AVAILABILITY_MODE = ASYNCHRONOUS_COMMIT, SEEDING_MODE = AUTOMATIC, FAILOVER_MODE = MANUAL, SECONDARY_ROLE(ALLOW_CONNECTIONS = ALL); );Para obtener más información, vea CREAR GRUPO DE DISPONIBILIDAD.
En la réplica secundaria, únase al AG.
ALTER AVAILABILITY GROUP [ag1] JOIN WITH (CLUSTER_TYPE = NONE); ALTER AVAILABILITY GROUP [ag1] GRANT CREATE ANY DATABASE; GOCree una base de datos para el AG. En los pasos de ejemplo se utiliza una base de datos denominada
TestDB. Si utiliza el sembrado automático, establezca la misma ruta de acceso para los archivos de datos y de registro.Antes de ejecutar el script, actualice los valores de la base de datos.
Reemplace
TestDBpor el nombre de la base de datos.Sustituya
<F:\Path>por la ruta de acceso de los archivos de base de datos y de registro. Use la misma ruta de acceso para los archivos de base de datos y de registro.
También se puede utilizar las rutas de acceso predeterminadas.
Para crear la base de datos, ejecute el script.
CREATE DATABASE [TestDB] CONTAINMENT = NONE ON PRIMARY (NAME = N'TestDB', FILENAME = N'<F:\Path>\TestDB.mdf') LOG ON (NAME = N'TestDB_log', FILENAME = N'<F:\Path>\TestDB_log.ldf'); GORealice una copia de seguridad completa de la base de datos.
Si no utiliza la propagación automática, restaure la base de datos en el servidor de réplica secundaria (Linux). Migración de una base de datos SQL Server de Windows a Linux mediante Copia de seguridad y restauración. Restaure la base de datos
WITH NORECOVERYen la réplica secundaria.Agregue la base de datos al AG. Actualice el script de ejemplo. Reemplace
TestDBpor el nombre de la base de datos. En la réplica principal, ejecute la consulta T-SQL para agregar la base de datos al AG.ALTER AG [ag1] ADD DATABASE TestDB; GOCompruebe que la base de datos se está rellenando en la réplica secundaria.

Conmutación por error de la réplica principal
Cada grupo de disponibilidad tiene solo una réplica principal. La réplica principal permite lecturas y escrituras. Para cambiar cuál réplica es la principal, puede efectuar una conmutación por error. En un grupo de disponibilidad típico, el administrador de clústeres automatiza el proceso de conmutación por error. En un grupo de disponibilidad con el tipo de clúster "NONE", el proceso de conmutación por error es manual.
Hay dos maneras de efectuar una conmutación por error de la réplica principal en un grupo de disponibilidad de tipo de clúster NONE:
- Conmutación por error manual sin pérdida de datos
- Conmutación manual forzada con pérdida de datos
Conmutación por error manual sin pérdida de datos
Use este método si la réplica principal está disponible, pero necesita modificar temporal o permanentemente la instancia que hospeda dicha réplica principal. Antes de emitir la conmutación por error manual, asegúrese de que la réplica secundaria de destino está actualizada para evitar una posible pérdida de datos.
Para realizar la conmutación por error manual sin perder datos:
Establezca las réplicas de destino principal y secundaria actuales en
SYNCHRONOUS_COMMIT.ALTER AVAILABILITY GROUP [AGRScale] MODIFY REPLICA ON N'<node2>' WITH (AVAILABILITY_MODE = SYNCHRONOUS_COMMIT);Ejecute la consulta siguiente para identificar que las transacciones activas se confirman en la réplica principal y en al menos una réplica secundaria sincrónica:
SELECT ag.name, drs.database_id, drs.group_id, drs.replica_id, drs.synchronization_state_desc, ag.sequence_number FROM sys.dm_hadr_database_replica_states drs, sys.availability_groups ag WHERE drs.group_id = ag.group_id;La réplica secundaria se sincroniza si
synchronization_state_descesSYNCHRONIZED.Actualice
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITa 1.El siguiente script establece
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMITen 1 en un grupo de disponibilidad denominadoag1. Antes de ejecutar el siguiente script, reemplaceag1por el nombre del grupo de disponibilidad:ALTER AVAILABILITY GROUP [AGRScale] SET (REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT = 1);Esta configuración garantiza que todas las transacciones activas se confirman en la réplica principal y en, al menos, una réplica secundaria sincrónica.
Nota:
Este ajuste no es específico a la conmutación por error y se debe establecer en función de los requisitos del entorno.
Desconecte la réplica principal y las réplicas secundarias que no participan en la conmutación para preparar el cambio de rol.
ALTER AVAILABILITY GROUP [AGRScale] OFFLINEAscienda la réplica secundaria de destino a principal.
ALTER AVAILABILITY GROUP AGRScale FORCE_FAILOVER_ALLOW_DATA_LOSS;Actualice el rol de la réplica principal antigua y otras réplicas secundarias a
SECONDARY, ejecute el comando siguiente en la instancia de SQL Server en la que se hospeda la réplica principal anterior:ALTER AVAILABILITY GROUP [AGRScale] SET (ROLE = SECONDARY);Nota:
Para eliminar un grupo de disponibilidad, use DROP AVAILABILITY GROUP. Para un grupo de disponibilidad creado con el tipo de clúster NONE o EXTERNAL, ejecute el comando en todas las réplicas que forman parte del grupo de disponibilidad.
Reanude el movimiento de datos, ejecute el siguiente comando para cada base de datos del grupo de disponibilidad en la instancia de SQL Server que hospeda la réplica principal:
ALTER DATABASE [db1] SET HADR RESUMEVuelva a crear cualquier cliente de escucha que haya creado para fines de escalado de lectura y que no esté administrado por un administrador de clústeres. Si el oyente original apunta al nodo principal anterior, elimínelo y vuelva a crearlo para que apunte al nuevo nodo principal.
Conmutación por error manual forzada con pérdida de datos
Si la réplica primaria no está disponible y no se puede recuperar de inmediato, deberá forzar una conmutación por error a la réplica secundaria con pérdida de datos. Sin embargo, si la réplica principal original se recupera tras la conmutación por error, pasará a ostentar el rol principal. Para evitar que cada réplica esté en un estado diferente, quite la principal original del grupo de disponibilidad después de forzar la conmutación por error con pérdida de datos. Una vez que la primaria original vuelva a estar en línea, elimine el grupo de disponibilidad por completo.
Para forzar una conmutación por error manual con pérdida de datos de la réplica principal N1 a la secundaria N2, siga estos pasos:
En la réplica secundaria (N2), inicie una conmutación por error forzada:
ALTER AVAILABILITY GROUP [AGRScale] FORCE_FAILOVER_ALLOW_DATA_LOSS;En la nueva réplica principal (N2), retire la réplica principal original (N1):
ALTER AVAILABILITY GROUP [AGRScale] REMOVE REPLICA ON N'N1';Valide que todo el tráfico de las aplicaciones apunte al escucha y/o a la nueva réplica principal.
Si la principal original (N1) está en línea, desconecte el grupo de disponibilidad AGRScale de la principal original (N1) de inmediato:
ALTER AVAILABILITY GROUP [AGRScale] OFFLINESi hay datos o cambios sin sincronizar, conserve dichos datos por medio de copias de seguridad u otras opciones de replicación de datos, en consonancia con los requisitos de su empresa.
Luego, quite el grupo de disponibilidad de la principal original (N1):
DROP AVAILABILITY GROUP [AGRScale];Anule la base de datos del grupo de disponibilidad de la réplica principal original (N1):
USE [master] GO DROP DATABASE [AGDBRScale] GO(Opcional) Si quiere, ahora puede volver a agregar N1 como nueva réplica secundaria al grupo de disponibilidad AGRScale.
En este artículo se revisan los pasos para crear un AG multiplataforma para admitir las cargas de trabajo de migración o de escalado de lectura. Se puede utilizar para la recuperación ante desastres manual. También se explica cómo conmutar por error el AG. Un grupo de disponibilidad multidispositivo (AG) utiliza el tipo de clúster NONE y no admite alta disponibilidad.