Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Applies to:![]() SQL Server en Linux
SQL Server en Linux
Este artículo presenta las configuraciones de implementación admitidas para los grupos de disponibilidad Always On de SQL Server en servidores Linux. Un grupo de disponibilidad admite una alta disponibilidad y protección de datos. La detección automática de fallos, la conmutación automática por falla y la reconexión transparente después de la conmutación por falla proporcionan alta disponibilidad. Las réplicas sincronizadas proporcionan la protección de datos.
En un clúster de conmutación por error (WSFC) de Windows Server, una configuración común para alta disponibilidad usa dos réplicas síncronas y un tercer servidor o uso compartido de archivos para proporcionar quórum. El testigo de recurso compartido de archivos valida la configuración del grupo de disponibilidad: estado de sincronización y el rol de la réplica, por ejemplo. Esta configuración garantiza que la réplica secundaria elegida como destino de la conmutación por error tenga los datos más recientes y los cambios de configuración del grupo de disponibilidad más actualizados.
El WSFC sincroniza los metadatos de configuración para el arbitraje de conmutación por error entre las réplicas del grupo de disponibilidad y el testigo del recurso compartido de archivos. Cuando un grupo de disponibilidad no está en un WSFC, las instancias de SQL Server almacenan los metadatos de configuración en la base de datos master.
Por ejemplo, un grupo de disponibilidad en un clúster de Linux tiene CLUSTER_TYPE = EXTERNAL. No hay ningún WSFC para gestionar el failover. En este caso, las instancias de SQL Server administran y mantienen los metadatos de configuración. Dado que no hay ningún servidor testigo en este clúster, se requiere una tercera instancia de SQL Server para almacenar los metadatos de estado de configuración. Las tres instancias de SQL Server juntas proporcionan almacenamiento de metadatos distribuidos para el clúster.
El administrador de clústeres puede consultar las instancias de SQL Server en el grupo de disponibilidad y orquestar la conmutación por error para mantener la alta disponibilidad. En un clúster de Linux, Pacemaker es el administrador de clústeres.
A partir de SQL Server 2017 (14.x) CU 1, la alta disponibilidad para un grupo de disponibilidad con CLUSTER_TYPE = EXTERNAL está habilitada para dos réplicas síncronas más una réplica de solo configuración. La única réplica de configuración se puede hospedar en cualquier edición de SQL Server 2017 (14.x) CU 1 o versiones posteriores (incluida SQL Server Express Edition). La réplica de solo configuración mantiene información de configuración sobre el grupo de disponibilidad en la base de datos master, pero no contiene las bases de datos de usuario del grupo de disponibilidad.
Cómo afecta la configuración a la configuración de recursos predeterminada
La REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT configuración del recurso de clúster garantiza que el número especificado de réplicas secundarias escriba datos de transacción en el registro antes de que la réplica principal confirme cada transacción. Cuando se usa un administrador de clústeres externo, esta configuración afecta a la alta disponibilidad y a la protección de datos. El valor predeterminado de la configuración depende de la arquitectura en el momento en que se crea el recurso de clúster. Al instalar el agente de recursos de SQL Server - mssql-server-ha - y crear un recurso de clúster para el grupo de disponibilidad, el administrador de clústeres detecta la configuración del grupo de disponibilidad y establece REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT en consecuencia.
Si es compatible con la configuración, el parámetro de agente de recurso REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT se establece en el valor que proporciona alta disponibilidad y protección de datos. Para obtener más información, consulte Comprender el agente de recursos de SQL Server para Pacemaker.
En las siguientes secciones se explica el comportamiento predeterminado para el recurso de clúster.
Elija un diseño de grupo de disponibilidad para satisfacer los requisitos empresariales específicos de alta disponibilidad, protección de datos y escalado de lectura.
Las siguientes configuraciones describen los patrones de diseño del grupo de disponibilidad y las capacidades de cada patrón. Estos patrones de diseño se aplican a los grupos de disponibilidad con CLUSTER_TYPE = EXTERNAL para soluciones de alta disponibilidad.
- Tres réplicas sincrónicas
- Dos réplicas sincrónicas
- Dos réplicas síncronas y una réplica de solo configuración
Tres réplicas sincrónicas
Esta configuración consta de tres réplicas sincrónicas. De forma predeterminada, proporciona alta disponibilidad y protección de datos. También puede proporcionar escalado de lectura.
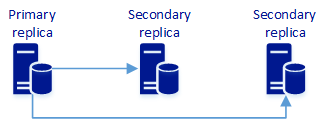
Un grupo de disponibilidad con tres réplicas sincrónicas puede proporcionar escalado de lectura, alta disponibilidad y protección de datos. En la tabla siguiente se describe el comportamiento de disponibilidad.
| Comportamiento de la disponibilidad | Escalado de lectura | Alta disponibilidad y protección de datos |
Protección de los datos |
|---|---|---|---|
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT= |
0 | 1 1 | 2 |
| Interrupción principal | Conmutación por error automática. Es posible que haya pérdida de datos. La nueva réplica principal es de L/E. | Conmutación por error automática. La nueva réplica principal es de L/E. | Conmutación por error automática. La nueva principal no estará disponible para las transacciones de lectura o escritura hasta que la principal anterior se recupere y se una al grupo de disponibilidad como secundaria. |
| Una interrupción de réplica secundaria | La réplica primaria es de L/E. La secundaria disponible está disponible para Lecturas. | La réplica primaria es de L/E. La secundaria disponible está disponible para Lecturas. | La principal no estará disponible para las transacciones de lectura o escritura hasta que la secundaria con errores se recupere y se una al grupo de disponibilidad. |
| Interrupción de dos réplicas secundarias | La principal solo está disponible para lecturas y no para escrituras hasta que una de las réplicas secundarias se recupere y vuelva a unirse al grupo de disponibilidad. | La principal solo está disponible para lecturas y no para escrituras hasta que una de las réplicas secundarias se recupere y vuelva a unirse al grupo de disponibilidad. | La principal no estará disponible para las transacciones de lectura o escritura hasta que todas las réplicas secundarias con errores se recuperen y se unan al grupo de disponibilidad. |
| Interrupción de réplica principal y una secundaria | Conmutación por error automática. Es posible que haya pérdida de datos. La nueva primaria solo está disponible para lecturas y no para escrituras hasta que una de las réplicas secundarias se recupere y se reincorpore al grupo de disponibilidad. | Conmutación por error automática. La nueva primaria solo está disponible para lecturas y escrituras hasta que una de las réplicas secundarias se recupere y se reincorpore al grupo de disponibilidad. | Conmutación por error automática. La nueva réplica primaria sigue sin estar disponible para las transacciones de lectura o escritura hasta que la réplica principal anterior y la réplica secundaria se recuperan y vuelven a unirse al grupo de disponibilidad. |
1 valor predeterminado
Dos réplicas sincrónicas
Esta configuración habilita la protección de datos. Al igual que las demás configuraciones de grupos de disponibilidad, puede habilitar el escalado de lectura. La configuración de dos réplicas sincrónicas no proporciona alta disponibilidad automática. Una configuración de dos réplicas solo es aplicable a SQL Server 2017 (14.x) RTM y ya no se admite con versiones posteriores (CU1 y posteriores) de SQL Server 2017 (14.x).
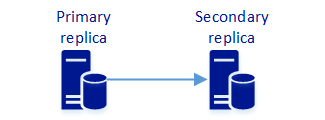
Un grupo de disponibilidad con dos réplicas sincrónicas proporciona protección de datos y capacidad de lectura. En la tabla siguiente se describe el comportamiento de disponibilidad.
| Comportamiento de la disponibilidad | Escalado de lectura | Protección de los datos |
|---|---|---|
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT= |
0 1 | 1 |
| Interrupción principal | Conmutación por error automática. Es posible que haya pérdida de datos. La nueva réplica principal es de L/E. | Conmutación por error automática. La nueva principal no estará disponible para las transacciones de lectura o escritura hasta que la principal anterior se recupere y se una al grupo de disponibilidad como una secundaria. |
| Una interrupción de réplica secundaria | La réplica principal es de lectura/escritura, se ejecuta con riesgo de pérdida de datos. | La principal no estará disponible para las transacciones de lectura o escritura hasta que la secundaria con errores se recupere y se una al grupo de disponibilidad. |
1 valor predeterminado
Dos réplicas síncronas y una réplica de solo configuración
Un grupo de disponibilidad con dos (o más) réplicas sincronizadas, y una réplica de solo configuración, proporciona protección de datos y podría proporcionar alta disponibilidad. El diagrama siguiente representa esta arquitectura:
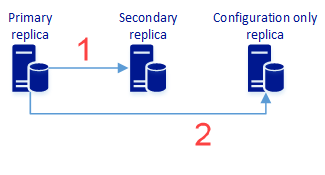
- Replicación sincrónica de datos de usuario en la réplica secundaria. También incluye los metadatos de configuración del grupo de disponibilidad.
- Replicación sincrónica de los metadatos de configuración del grupo de disponibilidad. No incluye datos de usuario.
En el diagrama de grupo de disponibilidad, una réplica principal envía los datos de configuración tanto a la réplica secundaria como a la réplica de solo configuración. La réplica secundaria también recibe datos de usuario. La réplica de solo configuración no recibe datos de usuario. La réplica secundaria está en modo de disponibilidad sincrónica. La réplica de solo configuración no contiene las bases de datos en el grupo de disponibilidad, solo metadatos sobre el grupo de disponibilidad. Los datos de configuración de la réplica de solo configuración se confirman de forma sincrónica.
Nota:
Un grupo de disponibilidad con solo réplica de configuración es nuevo para SQL Server 2017 (14.x) CU 1. Todas las instancias de SQL Server del grupo de disponibilidad deben ser SQL Server 2017 (14.x) CU 1 o versiones posteriores.
El valor predeterminado para REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT es 0. En la tabla siguiente se describe el comportamiento de disponibilidad.
| Comportamiento de la disponibilidad | Alta disponibilidad y protección de datos |
Protección de los datos |
|---|---|---|
REQUIRED_SYNCHRONIZED_SECONDARIES_TO_COMMIT= |
0 1 | 1 |
| Interrupción principal | Conmutación por error automática. La nueva réplica principal es de L/E. Es posible que haya pérdida de datos. | Conmutación por error automática. La nueva principal no estará disponible para las transacciones de lectura o escritura hasta que la principal anterior se recupere y se una al grupo de disponibilidad como una secundaria. |
| Interrupción de la réplica secundaria | La réplica principal es de L/E, la ejecución se expone a pérdida de datos (si se produce un error en la réplica principal y no se puede recuperar). No se produce una conmutación automática por error si el primario también falla. | La principal no estará disponible para las transacciones de lectura o escritura hasta que la secundaria con errores se recupere y se una al grupo de disponibilidad. No hay ninguna réplica a la que realizar la conmutación por error si también se produce un error en la réplica principal. |
| Interrupción de la réplica exclusiva de configuración | La réplica primaria es de L/E. No se produce una conmutación automática por error si el primario también falla. | La réplica primaria es de L/E. No se produce una conmutación automática por error si el primario también falla. |
| Interrupción de réplicas sincrónicas secundarias y solo de configuración | El servidor primario no está disponible para las transacciones de lectura y escritura. Sin conmutación automática. | El servidor primario no está disponible para las transacciones de lectura y escritura. No hay ninguna réplica a la que realizar la conmutación por error si también se produce un error en la réplica principal. |
1 valor predeterminado
Nota:
La instancia de SQL Server que aloja la réplica de solo configuración también puede alojar otras bases de datos. También puede participar como una base de datos utilizada únicamente para la configuración en más de un grupo de disponibilidad.
Requisitos
- Todas las réplicas de un grupo de disponibilidad con una réplica solo de configuración deben ser SQL Server 2017 (14.x) CU 1 o versiones posteriores.
- Cualquier edición de SQL Server puede hospedar una réplica solo de configuración, incluida SQL Server Express.
- El grupo de disponibilidad necesita al menos una réplica secundaria, además de la réplica principal.
- Solo las réplicas de configuración no cuentan para el número máximo de réplicas por instancia de SQL Server. SQL Server edición estándar permite hasta tres réplicas, SQL Server Enterprise Edition permite hasta 9.
Consideraciones
- No más de una réplica solo de configuración por grupo de disponibilidad.
- Una réplica de solo configuración no puede ser una réplica principal.
- No se puede modificar el modo de disponibilidad de una réplica de solo configuración. Para cambiar de una réplica de solo configuración a una réplica secundaria sincrónica o asincrónica, quite la réplica de solo configuración y agregue una réplica secundaria con el modo de disponibilidad requerido.
- Una réplica solo de configuración es sincrónica con los metadatos del grupo de disponibilidad. No existen datos de usuario.
- Un grupo de disponibilidad con una réplica principal y una réplica solo de configuración, pero sin réplica secundaria no es válido.
- No se puede crear un grupo de disponibilidad en una instancia de SQL Server Express Edition.
Comprender el agente de recursos de SQL Server para Pacemaker
SQL Server 2017 (14.x) introdujo sequence_number en sys.availability_groups para mostrar si una réplica marcada como SYNCHRONOUS_COMMIT está actualizada.
sequence_number es un bigint que aumenta de forma monotónica y representa cuán actualizada está la réplica del grupo de disponibilidad local en comparación con el resto de las réplicas del grupo de disponibilidad.
Este número se actualiza al realizar conmutaciones por error, agregar o quitar réplicas y otras operaciones de grupo de disponibilidad.
La réplica principal actualiza el número y, a continuación, lo inserta en las réplicas secundarias. Una réplica secundaria que está actualizada tiene la misma sequence_number que la principal.
Cuando Pacemaker decide ascender una réplica a primario, primero envía una notificación a todas las réplicas para obtener el número de secuencia y almacenarlo. Esta notificación se denomina notificación previa a la promoción. A continuación, cuando Pacemaker intenta promover una réplica a principal, la réplica solo se promueve si su número de secuencia es el más alto de todos los números de secuencia de todas las réplicas. De lo contrario, rechaza la operación de promoción. Con este proceso, solo la réplica con el número de secuencia más alto se puede promover a principal, lo que garantiza que no se pierdan datos.
La promoción funciona siempre que al menos una réplica promocionable tenga el mismo número de secuencia que el primario anterior. El comportamiento predeterminado es que el agente de recursos de Pacemaker configure REQUIRED_COPIES_TO_COMMIT automáticamente para que al menos una réplica secundaria de confirmación sincrónica esté actualizada y disponible como destino de una conmutación por error automática. Con cada acción de supervisión, el valor de REQUIRED_COPIES_TO_COMMIT se calcula (y actualiza, si es necesario) como ("número de réplicas de confirmación sincrónica" / 2). Después, en tiempo de conmutación por error, el agente de recursos requiere que (total number of replicas - required_copies_to_commit réplicas) respondan a la notificación previa a la promoción para poder promover una de ellas a principal. La réplica con el valor de sequence_number más alto se promueve a principal.
Por ejemplo, considere el caso de un grupo de disponibilidad con tres réplicas sincrónicas: una réplica principal y dos réplicas secundarias de confirmación sincrónica.
REQUIRED_COPIES_TO_COMMITes 3 / 2 = 1El número necesario de réplicas para responder a la acción de pre-promoción es 3 - 1 = 2. Por lo tanto, dos réplicas tienen que estar activas para que se desencadene la conmutación por error. Cuando se produce una interrupción principal, si una de las réplicas secundarias no responde y solo una de las secundarias responde a la acción previa a la promoción, el agente de recursos no puede garantizar que la secundaria que ha respondido tenga el
sequence_numbermás alto, y no se desencadena una conmutación por error.
Puede invalidar el comportamiento predeterminado y configurar el recurso del grupo de disponibilidad para que no se establezca REQUIRED_COPIES_TO_COMMIT automáticamente.
Importante
Cuando REQUIRED_COPIES_TO_COMMIT es 0, corre el riesgo de pérdida de datos. Si hay una interrupción del sistema principal, el agente de recursos no desencadena automáticamente un failover. Debe optar por esperar a que el primario se recupere o realizar una conmutación por error manual.
Para establecer REQUIRED_COPIES_TO_COMMIT en 0, ejecute:
sudo pcs resource update <ag_cluster> required_copies_to_commit=0
El comando equivalente que usa crm (en SUSE Linux Enterprise Server) es:
sudo crm resource param <ag_cluster> set required_synchronized_secondaries_to_commit 0
Para revertir al valor calculado predeterminado, ejecute:
sudo pcs resource update <ag_cluster> required_copies_to_commit=
Nota:
Actualizar las propiedades de recursos hace que todas las réplicas se detengan y reinicien. Este cambio degrada temporalmente el primario a secundario y lo promueve de nuevo, lo que provoca una falta de disponibilidad temporal de escritura. El nuevo valor de REQUIRED_COPIES_TO_COMMIT se establece solo después de reiniciar las réplicas, por lo que no es instantáneo al ejecutar el comando pcs .
Equilibrio de la alta disponibilidad y la protección de datos
El comportamiento predeterminado descrito anteriormente también se aplica al caso de dos réplicas sincrónicas (principal y secundaria). Pacemaker establece REQUIRED_COPIES_TO_COMMIT en 1 para asegurar que la réplica secundaria siempre esté actualizada para la máxima protección de datos.
Advertencia
Esta configuración conlleva un mayor riesgo de no disponibilidad de la réplica principal debido a interrupciones planeadas o no planeadas en la base de datos secundaria. Puede elegir cambiar el comportamiento predeterminado del agente de recursos y anular el REQUIRED_COPIES_TO_COMMIT valor por 0:
sudo pcs resource update <ag1> required_copies_to_commit=0
Al invalidar este valor, el agente de recursos usa la nueva configuración para REQUIRED_COPIES_TO_COMMIT y deja de calcularlo. Debe actualizarlo manualmente si es necesario (por ejemplo, si aumenta el número de réplicas).
Las tablas siguientes describen el resultado de una interrupción para las réplicas principal o secundaria en configuraciones de recursos de grupo de disponibilidad diferentes:
Grupo de disponibilidad: dos réplicas sincrónicas
| Configuración | Interrupción principal | Una interrupción de réplica secundaria |
|---|---|---|
REQUIRED_COPIES_TO_COMMIT = 0 |
Debe emitir manualmente un FAILOVER.Puede provocar la pérdida de datos. La nueva réplica principal es de L/E. |
La réplica principal es de lectura/escritura, se ejecuta con riesgo de pérdida de datos. |
REQUIRED_COPIES_TO_COMMIT = 1
1 |
El clúster emite automáticamente FAILOVERNo se produce pérdida de datos. La nueva réplica principal rechaza todas las conexiones hasta que la réplica principal anterior termine de recuperarse y se una al grupo de disponibilidad como réplica secundaria. |
El servidor principal rechaza todas las conexiones hasta que se recupere el servidor secundario. |
1 SQL Server agente de recursos para el comportamiento predeterminado de Pacemaker.
Grupo de disponibilidad: tres réplicas sincronizadas
| Configuración | Interrupción principal | Una interrupción de réplica secundaria |
|---|---|---|
REQUIRED_COPIES_TO_COMMIT = 0 |
Debe emitir manualmente un FAILOVER.Puede provocar la pérdida de datos. La nueva réplica principal es de L/E. |
La réplica primaria es de L/E. |
REQUIRED_COPIES_TO_COMMIT = 1
1 |
El clúster emite automáticamente FAILOVER.No se produce pérdida de datos. La nueva réplica principal es de L/E. |
La réplica primaria es de L/E. |
1 SQL Server agente de recursos para el comportamiento predeterminado de Pacemaker.