Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server en Linux
SQL Server en Linux
En este artículo se explican los conceptos relacionados con las instancias de clúster de conmutación por error (FCI) de SQL Server en Linux.
Para crear una FCI de SQL Server en Linux, consulte Configuración de una instancia de clúster de conmutación por error: SQL Server en Linux (RHEL)
La capa de agrupación en clústeres
En Red Hat Enterprise Linux (RHEL), la capa de agrupación en clústeres se basa en el complemento HA de Red Hat Enterprise Linux (RHEL).
Nota:
El acceso al complemento de HA de Red Hat y a la documentación requiere una suscripción.
En SUSE Linux Enterprise Server (SLES), la capa de agrupación en clústeres se basa en High Availability Extension (HAE) de SUSE Linux Enterprise.
Para obtener más información sobre la configuración del clúster, las opciones del agente de recursos y la administración, así como para obtener recomendaciones y ver los procedimientos recomendados, vea SUSE Linux Enterprise High Availability Extension 15.
Tanto el complemento HA de RHEL como la extensión HAE de SUSE se basan en Pacemaker.
Como se muestra en el diagrama siguiente, el almacenamiento se presenta en dos servidores. Los componentes de agrupación en clústeres (Corosync y Pacemaker) coordinan las comunicaciones y la administración de recursos. Uno de los servidores tiene la conexión activa a los recursos de almacenamiento y SQL Server. Cuando Pacemaker detecta un error, los componentes de agrupación en clústeres son responsables del traslado de los recursos al otro nodo.
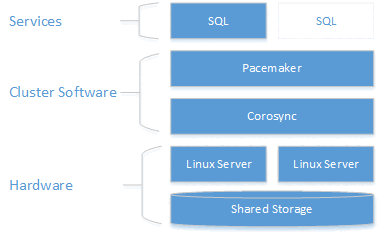
La integración de SQL Server con Pacemaker en Linux no es tan estrechamente integrada como con WSFC en Windows. SQL Server no tiene conocimiento sobre la presencia del clúster. Toda la orquestación se realiza desde el exterior y el servicio se controla como una instancia independiente por Pacemaker. Además, el nombre de red virtual es específico de WSFC, que no tiene ningún equivalente en Pacemaker. Se espera que @@SERVERNAME y sys.servers devuelvan el nombre del nodo, mientras que las DMV del clúster sys.dm_os_cluster_nodes y sys.dm_os_cluster_properties no devuelven ningún registro. Para usar una cadena de conexión que apunte al nombre de servidor de una cadena y no use la dirección IP, se tiene que registrar en su servidor DNS la dirección IP usada para crear el recurso de IP virtual (como se explica en las secciones siguientes) con el nombre de servidor elegido.
Número de instancias y nodos
Una diferencia clave con SQL Server en Linux es que solo puede haber una instalación de SQL Server por servidor de Linux. Esa instalación se denomina instancia. A diferencia de Windows Server, que admite hasta 25 FCI por clúster de conmutación por error de Windows Server (WSFC), una FCI basada en Linux solo tiene una instancia única. Esta instancia única también es una instancia predeterminada; no hay ningún concepto de instancia con nombre en Linux.
Un clúster de Pacemaker solo puede tener un máximo de 16 nodos cuando Corosync está implicado, por lo que una FCI única puede abarcar hasta 16 servidores. Una FCI implementada con la edición Standard de SQL Server admite hasta dos nodos de un clúster, aunque el clúster de Pacemaker tenga el máximo de 16 nodos.
En una FCI de SQL Server, la instancia de SQL Server está activa en un nodo o en el otro.
Dirección IP y nombre
En un clúster de Pacemaker de Linux, cada FCI de SQL Server necesita su propia dirección IP y nombre únicos. Si la configuración de FCI abarca varias subredes, se necesita una dirección IP por subred. El nombre único y la(s) direccion(es) IP se usan para acceder a la FCI, de modo que las aplicaciones y los usuarios finales no necesitan saber el servidor subyacente del clúster de Pacemaker.
El nombre de la FCI en DNS debe ser el mismo que el nombre del recurso de FCI que se crea en el clúster de Pacemaker. Tanto el nombre como la dirección IP deben estar registrados en DNS.
Almacenamiento compartido
Todas las FCI, tanto si están en Linux como en Windows Server, requieren algún tipo de almacenamiento compartido. Este almacenamiento se presenta a todos los servidores que pueden hospedar la FCI, pero solo un servidor puede usar el almacenamiento de la FCI en un momento dado. Las opciones disponibles para el almacenamiento compartido en Linux son:
- iSCSI
- Sistema de archivos de red (NFS)
- Bloque de mensajes del servidor (SMB)
En Windows Server, hay opciones ligeramente diferentes. Una opción que no se admite actualmente para FCI basadas en Linux es la posibilidad de usar un disco que sea local en el nodo de tempdb, que es el área de trabajo temporal de SQL Server.
En una configuración que abarca varias ubicaciones, lo que se almacena en un centro de datos se debe sincronizar con el otro. En el caso de una conmutación por error, la FCI puede conectarse y se ve que el almacenamiento es el mismo. Para lograrlo, se necesita algún método externo para la replicación de almacenamiento, ya sea a través del hardware de almacenamiento subyacente o de alguna utilidad basada en software.
Nota:
En el caso de SQL Server, las implementaciones basadas en Linux que usan discos presentados directamente en un servidor deben tener el formato XFS o ext4. Actualmente no se admiten otros sistemas de archivos. Los cambios se reflejan aquí.
El proceso para presentar el almacenamiento compartido es el mismo para los distintos métodos admitidos:
- Configurar el almacenamiento compartido
- Montar el almacenamiento como una carpeta en los servidores que actúan como nodos del clúster de Pacemaker para la FCI
- Si es necesario, mover las bases de datos del sistema de SQL Server al almacenamiento compartido
- Probar que SQL Server funciona desde cada servidor conectado al almacenamiento compartido
Una diferencia importante con SQL Server en Linux es que, aunque puede configurar la ubicación predeterminada del archivo de registro y datos de usuario, las bases de datos del sistema deben existir siempre en /var/opt/mssql/data. En Windows Server, existe la posibilidad de mover las bases de datos del sistema, incluida tempdb. Este hecho influye en el modo en que se configura el almacenamiento compartido de una FCI.
Las rutas de acceso predeterminadas de las bases de datos que no son del sistema se pueden cambiar mediante la utilidad mssql-conf. Para obtener información sobre cómo cambiar los valores predeterminados, cambie la ubicación predeterminada del directorio de datos o de registro. También puede almacenar datos y transacciones de SQL Server en otras ubicaciones siempre y cuando tengan la seguridad adecuada, aunque no sea una ubicación predeterminada; es necesario indicar la ubicación.