Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Instancia
Instancia ![]() administrada de Azure SQLBase de datos SQL en Microsoft Fabric
administrada de Azure SQLBase de datos SQL en Microsoft Fabric
En este artículo se describe cómo trazar datos mediante el paquete de Python pandas'.hist (). Una base de datos de SQL Server es el origen que se usa para visualizar los intervalos de datos del histograma que tienen valores consecutivos y no superpuestos.
Prerequisites
SQL Server Management Studio para restaurar la base de datos de ejemplo en Azure SQL Managed Instance.
Azure Data Studio. Para realizar la instalación, vea Azure Data Studio.
Restaure la base de datos DW de ejemplo para obtener los datos de ejemplo que se usan en este artículo.
Comprobación de la base de datos restaurada
Para comprobar que la base de datos restaurada existe, consulte la tabla Person.CountryRegion:
USE AdventureWorksDW;
SELECT * FROM Person.CountryRegion;
Instalación de paquetes de Python
Descarga e instalación de Azure Data Studio.
Instale los siguientes paquetes de Python:
pyodbcpandassqlalchemymatplotlib
Para instalar estos paquetes:
- En el cuaderno de Azure Data Studio, seleccione Administrar paquetes.
- En el panel Administrar paquetes, seleccione la pestaña Agregar nuevo.
- Para cada uno de los paquetes siguientes, escriba el nombre del paquete, seleccione Buscar y, a continuación, seleccione Instalar.
Trazado del histograma
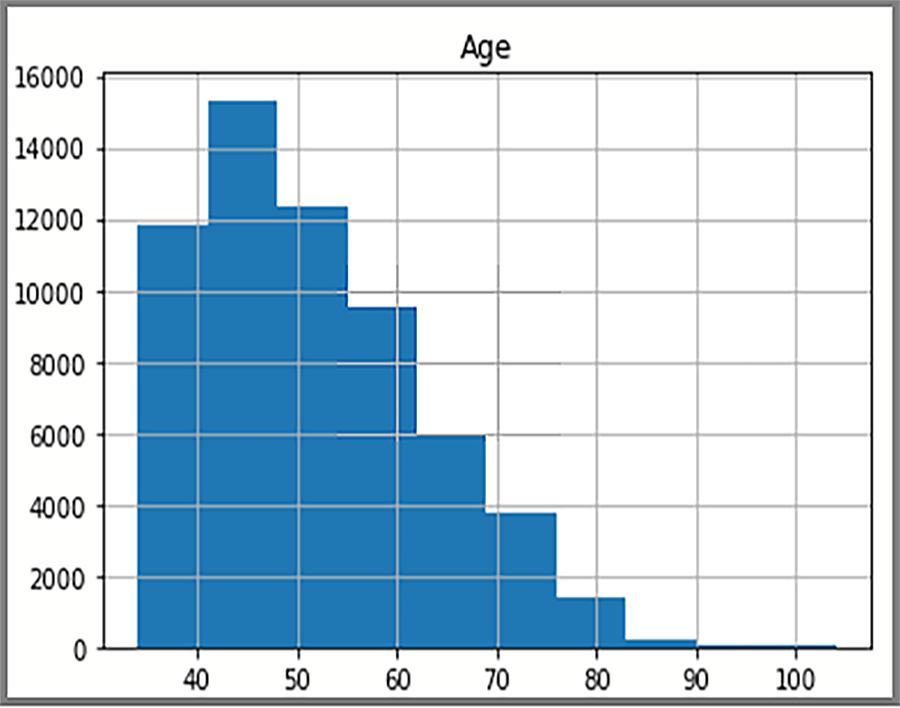
Los datos distribuidos que se muestran en el histograma están basados en una consulta SQL de AdventureWorksDW2025. El histograma visualiza los datos y la frecuencia de los valores de los mismos.
Edite las variables de cadena de conexión: server, database, usernamey password para conectarse a la base de datos de SQL Server.
Para crear un nuevo cuaderno:
En Azure Data Studio, seleccione Archivo y luego Nuevo cuaderno.
En el bloc de notas, seleccione el kernel Python3 y luego el comando +Código.
Pegue el código en el cuaderno. Seleccione Run all (Ejecutar todas).
import pyodbc import pandas as pd import matplotlib import sqlalchemy from sqlalchemy import create_engine matplotlib.use('TkAgg', force=True) from matplotlib import pyplot as plt # Some other example server values are # server = 'localhost\sqlexpress' # for a named instance # server = 'myserver,port' # to specify an alternate port server = 'servername' database = 'AdventureWorksDW2022' username = 'yourusername' password = 'databasename' url = 'mssql+pyodbc://{user}:{passwd}@{host}:{port}/{db}?driver=SQL+Server'.format(user=username, passwd=password, host=server, port=port, db=database) engine = create_engine(url) sql = "SELECT DATEDIFF(year, c.BirthDate, GETDATE()) AS Age FROM [dbo].[FactInternetSales] s INNER JOIN dbo.DimCustomer c ON s.CustomerKey = c.CustomerKey" df = pd.read_sql(sql, engine) df.hist(bins=50) plt.show()
La pantalla muestra la distribución de edad de los clientes en la tabla FactInternetSales.