Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server 2017 (14.x) y versiones posteriores
SQL Server 2017 (14.x) y versiones posteriores
En este artículo se describe la extensión de Python para ejecutar scripts de Python externos con SQL Server Machine Learning Services. La extensión agrega:
- Un entorno de ejecución de Python
- La distribución de Anaconda con el intérprete y el runtime de Python 3.5
- Herramientas y bibliotecas estándar
- Paquetes de Python en Microsoft:
- revoscalepy para el análisis a escala.
- microsoftml para algoritmos de aprendizaje automático.
La instalación del intérprete y del runtime de Python 3.5 garantiza una compatibilidad casi completa con las soluciones de Python estándar. Python se ejecuta en un proceso aparte de SQL Server para garantizar que las operaciones de base de datos no se ponen en riesgo.
Componentes de Python
SQL Server incluye paquetes tanto de código abierto como de propietario. El runtime de Python que se instala con el programa de instalación es Anaconda 4.2 con Python 3.5. El runtime de Python se instala independientemente de las herramientas de SQL, y se ejecuta fuera de los procesos principales del motor, en el marco de extensibilidad. Como parte de la instalación de Machine Learning Services con Python, debe aceptar las condiciones de la licencia pública de GNU.
SQL Server no modifica los ejecutables de Python, pero se debe usar la versión de Python que instale el programa de instalación, ya que es en esa versión donde se compilan y prueban los paquetes de propietario. Para ver una lista de los paquetes admitidos por la distribución de Anaconda, vaya al sitio de Continuum Analytics: Lista de paquetes de Anaconda.
La distribución de Anaconda asociada a una determinada instancia de motor de base de datos está en la carpeta relativa a esa instancia. Por ejemplo, si instaló el motor de base de datos de SQL Server 2017 con Machine Learning Services y Python en la instancia predeterminada, mire en C:\Program Files\Microsoft SQL Server\MSSQL14.MSSQLSERVER\PYTHON_SERVICES.
Los paquetes de Python que Microsoft agrega para cargas de trabajo paralelas y distribuidas incluyen las siguientes bibliotecas.
| Biblioteca | Descripción |
|---|---|
| revoscalepy | Admite objetos de origen de datos y la exploración, manipulación, transformación y visualización de datos. Admite la creación de contextos de proceso remotos, así como varios modelos de aprendizaje automático escalables, como rxLinMod. Para más información, vea Módulo revoscalepy en SQL Server. |
| microsoftml | Contiene algoritmos de Machine Learning que se han optimizado para ser más rápidos y precisos, así como transformaciones en línea para trabajar con texto e imágenes. Para más información, vea Módulo microsoftml en SQL Server. |
Microsoftml y revoscalepy están estrechamente ligados; así, los orígenes de datos usados en microsoftml se definen como objetos de revoscalepy. Las limitaciones de contexto de cálculo en revoscalepy se trasladan a microsoftml. es decir, todas las funciones están disponibles para las operaciones locales, pero cambiar a un contexto de proceso remoto requiere RxInSqlServer.
Uso de Python en SQL Server
Hay que importar el módulo revoscalepy al código de Python y, después, llamar a las funciones desde ese módulo, como cualquier otra función de Python.
Entre los orígenes de datos admitidos se incluyen las bases de datos ODBC, SQL Server y el formato de archivo XDF para intercambiar datos con otros orígenes o con soluciones de R. Los datos de entrada de Python deben ser tabulares. Todos los resultados de Python se deben devolver en forma de un dataframe pandas.
Entre los contextos de proceso admitidos se incluyen el contexto de proceso local o remoto de SQL Server. Un contexto de proceso remoto hace referencia a la ejecución de código que se inicia en un equipo como, por ejemplo, una estación de trabajo, pero que luego cambia la ejecución del script a un equipo remoto. Cambiar el contexto de proceso requiere que ambos sistemas tengan la misma biblioteca revoscalepy.
El contexto de proceso local, como cabría esperar, incluye la ejecución de código de Python en el mismo servidor que la instancia del motor de base de datos, con código dentro de T-SQL o insertado en un procedimiento almacenado. También se puede ejecutar el código desde un IDE de Python local y hacer que el script se ejecute en el equipo de SQL Server, mediante la definición de un contexto de proceso remoto.
Arquitectura de la ejecución
En los siguientes diagramas se describe la interacción de los componentes de SQL Server con el runtime de Python en cada uno de los escenarios admitidos: la ejecución de un script en la base de datos y la ejecución de forma remota desde un terminal de Python, usando un contexto de proceso de SQL Server.
Scripts de Python ejecutados en base de datos
Cuando Python se ejecuta "dentro de" SQL Server, el script de Python se debe encapsular dentro de un procedimiento almacenado especial, sp_execute_external_script.
Una vez que el script esté insertado en el procedimiento almacenado, cualquier aplicación que pueda realizar una llamada a un procedimiento almacenado podrá iniciar la ejecución del código de Python. A partir de entonces, SQL Server administra la ejecución del código, como se resume en el siguiente diagrama.
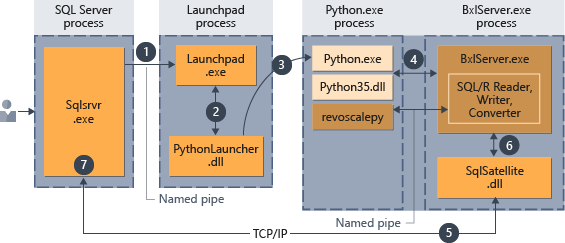
- Una solicitud para el entorno de ejecución de Python se indica mediante el parámetro
@language='Python'pasado al procedimiento almacenado. SQL Server envía esta solicitud al servicio Launchpad. En Linux, SQL usa un servicio Launchpad a fin de comunicarse con un proceso de Launchpad independiente para cada usuario. Vea el Diagrama de la arquitectura de extensibilidad para más información. - El servicio Launchpad inicia el selector adecuado, en este caso, PythonLauncher.
- PythonLauncher inicia el proceso Python35 externo.
- BxlServer coordina con el runtime de Python la administración de intercambios de datos y el almacenamiento de los resultados del trabajo.
- SQL Satellite administra las comunicaciones sobre las tareas y los procesos relacionados con SQL Server.
- BxlServer usa SQL Satellite para comunicar el estado y los resultados a SQL Server.
- SQL Server obtiene los resultados y cierra las tareas y los procesos relacionados.
Scripts de Python ejecutados desde un cliente remoto
Puede ejecutar scripts de Python desde un equipo remoto (como un equipo portátil) y hacer que se ejecuten en el contexto del equipo de SQL Server si se cumplen estas condiciones:
- Tú diseñas los scripts adecuadamente.
- El equipo remoto tiene instaladas las bibliotecas de extensibilidad que se usan en Machine Learning Services. El paquete revoscalepy es necesario para usar contextos de proceso remotos.
En el siguiente diagrama se resume el flujo de trabajo general cuando se envían scripts desde un equipo remoto.
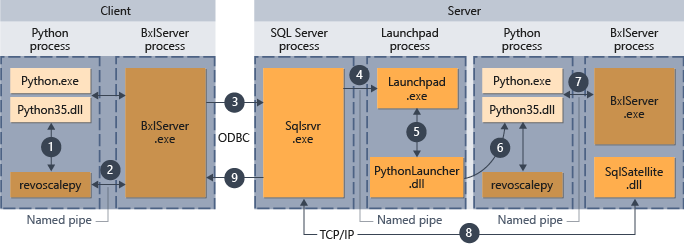
- En el caso de las funciones que se admiten en revoscalepy, el runtime de Python llama a una función de enlace, que a su vez llama a BxlServer.
- BxlServer se incluye en Machine Learning Services (en base de datos) y se ejecuta en un proceso independiente del runtime de Python.
- BxlServer determina el destino de la conexión e inicia una conexión mediante ODBC. Para ello, pasa las credenciales proporcionadas como parte de la cadena de conexión en el script de Python.
- BxlServer abre una conexión con la instancia de SQL Server.
- Cuando se llama a un runtime de script externo, se invoca el servicio Launchpad, que a su vez abre el iniciador adecuado; en este caso, PythonLauncher.dll. A partir de ese momento, el procesamiento de código de Python se controla en un flujo de trabajo similar al de un procedimiento almacenado en T-SQL.
- PythonLauncher realiza una llamada a la instancia del runtime de Python que hay instalada en el equipo de SQL Server.
- Los resultados se devuelven a BxlServer.
- SQL Satellite administra la comunicación con SQL Server y la limpieza de los objetos de trabajo relacionados.
- SQL Server devuelve los resultados al cliente.