Tutorial de Python: Creación de un modelo para clasificar clientes con aprendizaje automático de SQL
Se aplica a:![]() SQL Server 2017 (14.x) y versiones posteriores
SQL Server 2017 (14.x) y versiones posteriores ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
En la parte tres de esta serie de tutoriales de cuatro partes, creará un modelo de k-means en Python para realizar la agrupación en clústeres. En la siguiente parte de esta serie, implementará este modelo en una base de datos con SQL Server Machine Learning Services o en clústeres de macrodatos.
En la parte tres de esta serie de tutoriales de cuatro partes, creará un modelo de k-means en Python para realizar la agrupación en clústeres. En la siguiente parte de esta serie, implementará este modelo en una base de datos con SQL Server Machine Learning Services.
En la parte tres de esta serie de tutoriales de cuatro partes, creará un modelo de k-means en Python para realizar la agrupación en clústeres. En la siguiente parte de esta serie, implementará este modelo en una base de datos con Machine Learning Services en Azure SQL Managed Instance.
En este artículo, aprenderá a:
- Definición del número de clústeres para un algoritmo de k-means
- Agrupación en clústeres
- Análisis de los resultados
En la parte uno, ha instalado los requisitos previos y ha restaurado la base de datos de ejemplo.
En la parte dos, ha aprendido a preparar los datos de una base de datos para realizar la agrupación en clústeres.
En la parte cuatro, aprenderá a crear un procedimiento almacenado en una base de datos que pueda realizar la agrupación en clústeres en Python basándose en datos nuevos.
Prerrequisitos
- En la parte tres de este tutorial, se da por hecho que ha completado los requisitos previos de la parte uno y que ha realizado los pasos de la parte dos.
Definición del número de clústeres
Para agrupar en clústeres los datos de clientes, usará el algoritmo de agrupación en clústeres k-means, una de las formas más sencillas y conocidas de agrupar datos. Para más información sobre k-means, vea Guía completa sobre el algoritmo de agrupación en clústeres k-means.
El algoritmo acepta dos entradas: los datos en sí y un número predefinido "k", que representa el número de clústeres que se generarán. El resultado es k clústeres con los datos de entrada repartidos entre los clústeres.
El objetivo de k-means es agrupar los elementos en k clústeres, de forma que todos los elementos del mismo clúster sean similares entre sí y, en la medida de lo posible, que sean distintos de los elementos de otros clústeres.
Para determinar el número de clústeres que usará el algoritmo, use una representación de la suma de cuadrados dentro de los grupos por el número de clústeres extraídos. El número adecuado de clústeres que se usará se encuentra en la curva o "codo" de la representación.
################################################################################################
## Determine number of clusters using the Elbow method
################################################################################################
cdata = customer_data
K = range(1, 20)
KM = (sk_cluster.KMeans(n_clusters=k).fit(cdata) for k in K)
centroids = (k.cluster_centers_ for k in KM)
D_k = (sci_distance.cdist(cdata, cent, 'euclidean') for cent in centroids)
dist = (np.min(D, axis=1) for D in D_k)
avgWithinSS = [sum(d) / cdata.shape[0] for d in dist]
plt.plot(K, avgWithinSS, 'b*-')
plt.grid(True)
plt.xlabel('Number of clusters')
plt.ylabel('Average within-cluster sum of squares')
plt.title('Elbow for KMeans clustering')
plt.show()
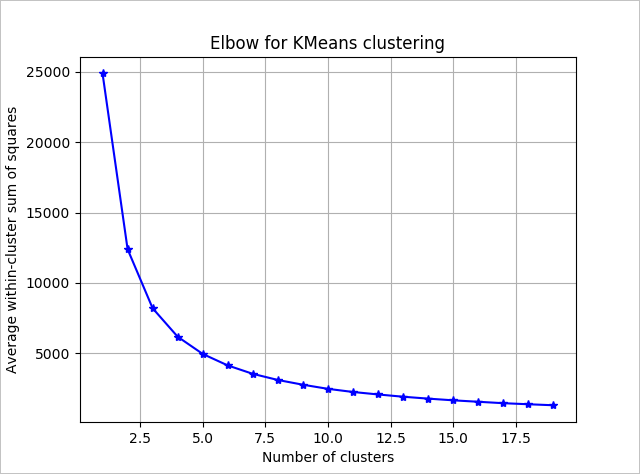
Según el gráfico, parece que k = 4 sería un buen valor para probar. El valor k agrupará los clientes en cuatro clústeres.
Agrupación en clústeres
En el siguiente script de Python, usará la función KMeans del paquete sklearn.
################################################################################################
## Perform clustering using Kmeans
################################################################################################
# It looks like k=4 is a good number to use based on the elbow graph.
n_clusters = 4
means_cluster = sk_cluster.KMeans(n_clusters=n_clusters, random_state=111)
columns = ["orderRatio", "itemsRatio", "monetaryRatio", "frequency"]
est = means_cluster.fit(customer_data[columns])
clusters = est.labels_
customer_data['cluster'] = clusters
# Print some data about the clusters:
# For each cluster, count the members.
for c in range(n_clusters):
cluster_members=customer_data[customer_data['cluster'] == c][:]
print('Cluster{}(n={}):'.format(c, len(cluster_members)))
print('-'* 17)
print(customer_data.groupby(['cluster']).mean())
Análisis de los resultados
Ahora que ha realizado la agrupación en clústeres mediante k-means, el paso siguiente es analizar el resultado y ver si puede identificar información procesable.
Analice los valores medios de agrupación en clústeres y los tamaños de los clústeres obtenidos en el script anterior.
Cluster0(n=31675):
-------------------
Cluster1(n=4989):
-------------------
Cluster2(n=1):
-------------------
Cluster3(n=671):
-------------------
customer orderRatio itemsRatio monetaryRatio frequency
cluster
0 50854.809882 0.000000 0.000000 0.000000 0.000000
1 51332.535779 0.721604 0.453365 0.307721 1.097815
2 57044.000000 1.000000 2.000000 108.719154 1.000000
3 48516.023845 0.136277 0.078346 0.044497 4.271237
Las cuatro medias de clústeres se proporcionan mediante las variables definidas en la parte uno:
- orderRatio = índice de devolución de pedidos (número total de pedidos con una devolución total o parcial comparado con el número total de pedidos)
- itemsRatio = índice de artículos devueltos (número total de artículos devueltos comparado con el número de artículos comprados)
- monetaryRatio = índice de importes de devoluciones (total de importes monetarios de los artículos devueltos comparado con el importe de las compras)
- frequency = frecuencia de devolución
Con frecuencia, la minería de datos que usa k-means necesita un análisis más detallado de los resultados y pasos adicionales para comprender mejor cada clúster, pero puede proporcionar pistas adecuadas. Estas son dos formas en que se podrían interpretar estos resultados:
- Parece que el clúster 0 es un grupo de clientes inactivos (todos los valores son de cero).
- Parece que el clúster 3 es un grupo que destaca en términos de comportamiento de devoluciones.
El clúster 0 es claramente un conjunto de clientes inactivos. Puede que quiera dirigir sus actividades de marketing hacia este grupo para generar interés por las compras. En el paso siguiente, consultará en la base de datos las direcciones de correo electrónico de los clientes del clúster 0 para enviarles un correo electrónico promocional.
Limpieza de recursos
Si no quiere continuar con este tutorial, elimine la base de datos tpcxbb_1gb.
Pasos siguientes
En la parte tres de esta serie de tutoriales, ha completado estos pasos:
- Definición del número de clústeres para un algoritmo de k-means
- Agrupación en clústeres
- Análisis de los resultados
Para implementar el modelo de aprendizaje automático que ha creado, siga la parte cuatro de esta serie de tutoriales:
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de