Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server
SQL Server![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Como mínimo, toda base de datos SQL Server tiene dos archivos de sistema operativo: un archivo de datos y un archivo de registro. Los archivos de datos contienen datos y otros objetos, como tablas, índices, procedimientos almacenados y vistas. Los archivos de registro contienen la información necesaria para recuperar todas las transacciones de la base de datos. Los archivos de datos se pueden agrupar en grupos de archivos para su asignación y administración.
Archivos de base de datos
Las bases de datos de SQL Server tienen tres tipos de archivos, como se muestra en la tabla siguiente.
| Archivo | Descripción |
|---|---|
| Principal | Incluye información de inicio de la base de datos y apunta a los demás archivos de la misma. Cada base de datos tiene un archivo de datos principal. La extensión recomendada para los nombres de archivos de datos principales es .mdf. |
| Secundario | Archivos de datos opcionales definidos por el usuario. Los datos se pueden distribuir en varios discos colocando cada archivo en una unidad de disco distinta. La extensión de nombre de archivo recomendada para los archivos de datos secundarios es .ndf. |
| Registro de transacciones | El registro contiene la información que se utiliza para recuperar la base de datos. Cada base de datos debe tener al menos un archivo de registro. La extensión recomendada para los nombres de archivos de registro es .ldf. |
Por ejemplo, una base de datos sencilla denominada Sales tiene un archivo principal que contenga todos los datos y objetos y un archivo de registro con la información del registro de transacciones. Puede crearse una base de datos más compleja, Orders, compuesta por un archivo principal y cinco archivos secundarios. Los datos y objetos de la base de datos se reparten entre los seis archivos, y cuatro archivos de registro adicionales contienen la información del registro de transacciones.
De forma predeterminada, los datos y los registros de transacciones se colocan en la misma unidad y ruta de acceso para manipular los sistemas de disco único, Puede que esta opción no resulte óptima para los entornos de producción. Se recomienda colocar los archivos de datos y de registro en distintos discos.
Nombres de archivo lógico y físico
Los archivos de SQL Server tienen dos tipos de nombre de archivo:
logical_file_name: el nombre usado para hacer referencia al archivo físico en todas las instrucciones Transact-SQL. El nombre de archivo lógico tiene que cumplir las reglas de los identificadores de SQL Server y tiene que ser único entre los nombres de archivos lógicos de la base de datos.os_file_name: el nombre del archivo físico, incluida la ruta de acceso del directorio. Debe seguir las reglas para nombres de archivos del sistema operativo.
Para obtener más información sobre los argumentos NAME y FILENAME, consulte ALTER DATABASE File and Filegroup Options.
Cuando se ejecutan varias instancias de SQL Server en un solo equipo, cada instancia recibe un directorio predeterminado diferente para contener los archivos de las bases de datos creadas en la instancia. Para obtener más información, vea Ubicaciones de archivos para instancias predeterminadas y con nombre de SQL Server.
Compatibilidad con el sistema de archivos
Los archivos de datos y de registro de SQL Server se pueden colocar en sistemas de archivos FAT o NTFS. En sistemas Windows, Microsoft recomienda usar el sistema de archivos NTFS por las características de seguridad que ofrece.
Los grupos de archivos de datos de lectura y escritura y los archivos de registro no se admiten en un sistema de archivos comprimido NTFS. Solo las bases de datos de solo lectura y los grupos de archivos secundarios de solo lectura se pueden colocar en un sistema de archivos NTFS comprimido. Para ahorrar espacio, use la compresión de datos en lugar de la compresión del sistema de archivos.
Páginas de archivo de datos
Las páginas de un archivo de datos de SQL Server están numeradas secuencialmente, comenzando por cero (0) para la primera página del archivo. Cada archivo de una base de datos tiene un número de identificador único. Para identificar de forma única una página de una base de datos, se requiere el identificador del archivo y el número de la página. El siguiente ejemplo muestra los números de página de una base de datos que tiene un archivo de datos principal de 4 MB y un archivo de datos secundario de 1 MB.
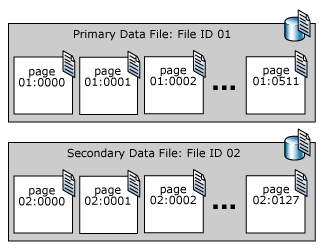
Una página de encabezado de archivo es la primera página que contiene información acerca de los atributos del archivo. Algunas de las otras páginas del comienzo del archivo también contienen información de sistema, como mapas de asignación. Una de las páginas de sistema almacenadas en el archivo de datos principal y en el archivo de registro principal es una página de arranque de la base de datos que contiene información acerca de los atributos de la base de datos.
Tamaño de archivo
Los archivos de SQL Server pueden crecer de forma automática a partir del tamaño especificado inicialmente. Cuando se define un archivo, se puede especificar un incremento de crecimiento. Cada vez que se llena el archivo, el tamaño aumenta en la cantidad especificada. Si hay varios archivos en un grupo de archivos, no crecerán automáticamente hasta que todos los archivos estén llenos.
Para obtener más información sobre las páginas y los tipos de página, consulte La guía de arquitectura de páginas y extensiones.
Cada archivo también puede tener un tamaño máximo especificado. Si no se especifica un tamaño máximo, el archivo puede crecer hasta utilizar todo el espacio disponible en el disco. Esta característica es especialmente útil cuando se utiliza SQL Server como base de datos incrustada en una solicitud en la que el usuario no tiene acceso conveniente a un administrador del sistema. El usuario puede dejar que los archivos crezcan automáticamente cuando sea necesario y evitar así las tareas administrativas de supervisar la cantidad de espacio disponible en la base de datos y asignar más espacio manualmente.
Para obtener más información sobre la administración del archivo de registro de transacciones, vea Administrar el tamaño del archivo de registro de transacciones.
Archivos de instantáneas de bases de datos
La forma de archivo que utiliza una instantánea de base de datos para almacenar sus datos de copia por escritura depende de si la instantánea la ha creado un usuario o se utiliza internamente:
Una instantánea de base de datos que crea un usuario almacena sus datos en uno o más archivos dispersos. La tecnología de archivos dispersos es una característica del sistema de archivos NTFS. Al principio, un archivo disperso no incluye datos de usuario y no se le asigna espacio en disco. Para obtener información general sobre el uso de los archivos dispersos en instantáneas de bases de datos y el crecimiento de estas, vea Ver el tamaño del archivo disperso de una instantánea de base de datos (Transact-SQL).
Las instantáneas de bases de datos las utilizan internamente algunos comandos DBCC. Estos comandos incluyen
DBCC CHECKDB,DBCC CHECKTABLE,DBCC CHECKALLOCyDBCC CHECKFILEGROUP. Una instantánea de base de datos interna utiliza flujos de datos alternativos dispersos de los archivos de base de datos originales. Como los archivos dispersos, los flujos de datos alternativos son una característica del sistema de archivos NTFS. El uso de los flujos de datos alternativos dispersos permite que varias asignaciones de datos se asocien a un único archivo o carpeta sin afectar a las estadísticas de tamaño o volumen.
Grupos de archivos
- El grupo de archivos principal contiene el archivo de datos principal y cualquier archivo secundario que no se encuentre en otros grupos de archivos.
- Se pueden crear grupos de archivos definidos por el usuario para agrupar archivos con fines administrativos y de asignación y ubicación de datos.
Por ejemplo, Data1.ndf, Data2.ndf y Data3.ndf pueden crearse en tres unidades de disco, respectivamente, y asignarse al grupo de archivos fgroup1. Se puede crear una tabla específicamente para el grupo de archivos fgroup1. Las consultas de datos de la tabla se distribuirán por los tres discos, con lo que mejorará el rendimiento. Puede obtenerse la misma mejora del rendimiento con un solo archivo creado en un conjunto de bandas RAID (matriz redundante de discos independientes). No obstante, los archivos y grupos de archivos permiten agregar fácilmente nuevos archivos a discos nuevos.
Todos los archivos de datos se almacenan en los grupos de archivos que se indican en la tabla siguiente.
| Grupo de archivos | Descripción |
|---|---|
| Principal | Grupo de archivos que contiene el archivo principal. Todas las tablas del sistema forman parte del grupo de archivos principal. |
| Datos optimizados para memoria | Un grupo de archivos optimizado para memoria se basa en el grupo de archivos FILESTREAM. |
| Filestream | Los datos no estructurados almacenados en directorios del sistema de archivos. |
| Definido por el usuario | Cualquier grupo de archivos creado por el usuario al crear la base de datos o al modificarla. |
Grupo de archivos predeterminado (principal)
Cuando se crean objetos en la base de datos sin especificar a qué grupo de archivos pertenecen, se asignan al grupo de archivos predeterminado. Siempre existe un grupo de archivos designado como predeterminado. Los archivos del grupo de archivos predeterminado deben ser lo suficientemente grandes como para dar cabida a todos los objetos nuevos no asignados a otros grupos de archivos.
El PRIMARY grupo de archivos es el grupo de archivos predeterminado a no ser que cambie mediante ALTER DATABASE instrucción. La asignación de los objetos y tablas del sistema permanece dentro del PRIMARY grupo de archivos, no el nuevo grupo de archivos predeterminado.
Grupo de archivos de datos optimizados para memoria
Para obtener más información sobre los grupos de archivos optimizados para memoria, consulte El grupo de archivos optimizados para memoria.
Grupo de archivos FILESTREAM
Para obtener más información sobre los grupos de archivos FILESTREAM, consulte FILESTREAM y Crear una base de datos habilitada para FILESTREAM.
Ejemplo de archivos y grupos de archivos
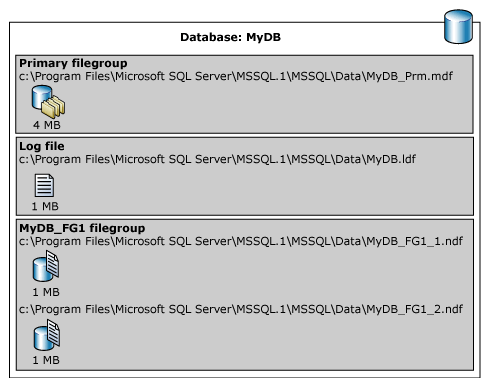
En el siguiente ejemplo se crea una base de datos en una instancia de SQL Server. La base de datos tiene un archivo de datos principal, un grupo de archivos definido por el usuario y el archivo de registro. El archivo de datos principal está en el grupo de archivos principal y el grupo de archivos definido por el usuario tiene dos archivos de datos secundarios. Una instrucción ALTER DATABASE hace que el grupo de archivos definido por el usuario sea el grupo predeterminado. A continuación, se crea una tabla que especifica el grupo de archivos definido por el usuario. (En este ejemplo se usa una ruta de acceso genérica C:\Program Files\Microsoft SQL Server\MSSQL.1 para evitar que se especifique una versión de SQL Server).
USE master;
GO
-- Create the database with the default data
-- filegroup, FILESTREAM filegroup and a log file. Specify the
-- growth increment and the max size for the
-- primary data file.
CREATE DATABASE MyDB
ON
PRIMARY (
NAME = 'MyDB_Primary',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_Prm.mdf',
SIZE = 4 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
),
FILEGROUP MyDB_FG1 (
NAME = 'MyDB_FG1_Dat1',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_1.ndf',
SIZE = 1 MB,
MAXSIZE = 10 MB, FILEGROWTH = 1 MB
), (
NAME = 'MyDB_FG1_Dat2',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB_FG1_2.ndf',
SIZE = 1 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
),
FILEGROUP FileStreamGroup1 CONTAINS FILESTREAM (
NAME = 'MyDB_FG_FS',
FILENAME = 'C:\Data\filestream1'
)
LOG ON (
NAME = 'MyDB_log',
FILENAME = 'C:\Program Files\Microsoft SQL Server\MSSQL.1\MSSQL\data\MyDB.ldf',
SIZE = 1 MB,
MAXSIZE = 10 MB,
FILEGROWTH = 1 MB
);
ALTER DATABASE MyDB
MODIFY FILEGROUP MyDB_FG1 DEFAULT;
-- Create a table in the user-defined filegroup.
USE MyDB;
GO
CREATE TABLE MyTable
(
cola INT PRIMARY KEY,
colb CHAR (8)
) ON MyDB_FG1;
GO
-- Create a table in the FILESTREAM filegroup
CREATE TABLE MyFSTable
(
cola INT PRIMARY KEY,
colb VARBINARY (MAX) FILESTREAM NULL
);
En la ilustración siguiente se resumen los resultados del ejemplo anterior (excepto los datos FILESTREAM).
Estrategia para el rellenado de archivos y grupos de archivos
Los grupos de archivos utilizan una estrategia de relleno proporcional entre todos los archivos de cada grupo de archivos. A medida que se escriben datos en el grupo de archivos, el motor de base de datos SQL Server escribe una cantidad proporcional al espacio libre del archivo en cada archivo del grupo de archivos, en lugar de escribir todos los datos en el primer archivo hasta que esté completo. A continuación, escribe en el siguiente archivo. Por ejemplo, si el archivo f1 tiene 100 MB de espacio disponible y el archivo f2 tiene 200 MB de espacio disponible, se dará una extensión del archivo f1, dos extensiones del archivo f2, etc. De ese modo, los dos archivos se llenarán aproximadamente al mismo tiempo y se conseguirá crear una banda simple.
Por ejemplo, un grupo de archivos consta de tres archivos configurados para crecer automáticamente. Cuando se agota el espacio de todos los archivos del grupo de archivos, solo se expande el primer archivo. Cuando se llena el primer archivo y no se pueden escribir más datos en el grupo de archivos, se expande el segundo archivo. Cuando se llena el segundo archivo y no pueden escribirse más datos en el grupo de archivos, se expande el tercer archivo. Si se llena el tercer archivo y no se pueden escribir más datos en el grupo de archivos, se vuelve a expandir el primer archivo, y así sucesivamente.
Reglas para el diseño de archivos y grupos de archivos
Las siguientes reglas afectan a los archivos y grupos de archivos:
Varios archivos o grupos de archivos no se pueden usar en más de una base de datos. Por ejemplo, los archivos
sales.mdfysales.ndf, que contienen datos y objetos de la base de datos sales, no pueden ser utilizados por otra base de datos.Un archivo puede pertenecer únicamente a un grupo de archivos.
Los archivos del registro de transacciones nunca pueden formar parte de un grupo de archivos.
Recomendaciones
Recomendaciones para trabajar con archivos y grupos de archivos:
La mayor parte de las bases de datos funcionarán correctamente con un solo archivo de datos y un solo archivo de registro de transacciones.
Si usa varios archivos de datos, cree un segundo grupo de archivos para el archivo adicional y conviértalo en el grupo de archivos predeterminado. De ese modo, el archivo principal solo contendrá objetos y tablas del sistema.
Para maximizar el rendimiento, cree archivos o grupos de archivos en tantos discos disponibles como sea posible y distribuya en grupos de archivos distintos los objetos que compitan de forma intensa por el espacio.
Utilice grupos de archivos para permitir la colocación de los objetos en determinados discos físicos.
Disponga en grupos de archivos distintos las diferentes tablas que se utilicen en las mismas consultas de combinación. Este paso mejorará el rendimiento debido a la búsqueda de datos combinados que realizan las operaciones de E/S en paralelo en los discos.
Distribuya en grupos de archivos distintos las tablas de acceso frecuente y los índices no clúster que pertenezcan a esas tablas. Utilizar grupos de archivos distintos mejorará el rendimiento debido a las operaciones de E/S en paralelo que se realizan si los archivos se encuentran en discos físicos distintos.
No coloque los archivos de registro de transacciones en el mismo disco físico que tenga los demás archivos y grupos de archivos.
Si necesita ampliar un volumen o partición en el que residen los archivos de base de datos mediante herramientas como diskpart, debe realizar copias de seguridad de todas las bases de datos de usuario y del sistema y detener primero los servicios de SQL Server. Además, una vez que los volúmenes de disco se extienden correctamente, debe considerar la posibilidad de ejecutar el comando DBCC CHECKDB para garantizar la integridad física de todas las bases de datos que residen en el volumen.
Para obtener más recomendaciones sobre la administración del archivo de registro de transacciones, vea Administrar el tamaño del archivo de registro de transacciones.
Contenido relacionado
- CREAR BASE DE DATOS
- ALTER DATABASE Opciones de archivo y grupo de archivos (Transact-SQL)
- Separar y adjuntar bases de datos (SQL Server)
- Guía de administración y arquitectura del registro de transacciones de SQL Server
- Guía de arquitectura de páginas y extensiones
- Administrar el tamaño del archivo de registro de transacciones