Comentarios de concesión de memoria
Se aplica a: SQL Server 2017 (14.x) y versiones posteriores, Azure SQL Managed Instance, base de datos de Azure SQL
A veces, una consulta se ejecuta con una concesión de memoria demasiado grande o demasiado pequeña. Si la concesión de memoria es demasiado grande, se impide el paralelismo en el servidor. Si es demasiado pequeño, puede que desbordemos al disco, que es una operación costosa. Los comentarios de concesión de memoria intentan recordar las necesidades de memoria de una ejecución anterior (con comentarios de percentil, varias ejecuciones anteriores). En función de esta información de consulta histórica, los comentarios de concesión de memoria ajustan la concesión dada a la consulta en consecuencia para las ejecuciones posteriores.
Esta característica se ha lanzado en tres oleadas. Comentarios de concesión de memoria en modo por lotes, seguidos de los comentarios de concesión de memoria en modo de fila y en SQL Server 2022 (16.x), hemos introducido comentarios de concesión de memoria en la persistencia del disco mediante el almacén de consultas y un algoritmo mejorado conocido como concesión de percentil.
Nota:
Para ver otras características de comentarios de consulta, consulte Comentarios de estimación de cardinalidad (CE) y Comentarios sobre grado de paralelismo (DOP).
Comentarios de concesión de memoria en modo por lotes
Se aplica a: SQL Server (a partir de SQL Server 2017 (14.x)), Azure SQL Database
El plan de ejecución de una consulta incluye la memoria mínima necesaria para la ejecución y el tamaño de concesión de memoria ideal para que todas las filas quepan en la memoria. El rendimiento se ve afectado si los tamaños de concesión de memoria son incorrectos. A su vez, unas concesiones excesivas se traducen en memoria desperdiciada y en simultaneidad reducida. Las concesiones de memoria insuficientes provocan un costoso desbordamiento en disco. Al ocuparse de las cargas de trabajo repetidas, los comentarios de concesión de memoria de modo de proceso por lotes vuelven a calcular la memoria real necesaria para una consulta y luego actualizan el valor de la concesión del plan almacenado en caché. Cuando se ejecuta una instrucción de consulta idéntica, la consulta usa el tamaño de concesión de memoria revisado, con lo que se reducen las concesiones de memoria excesivas que afectan a la simultaneidad y se solucionan las concesiones de memoria subestimadas que provocan costosos desbordamientos en disco.
El gráfico siguiente muestra un ejemplo de uso de los comentarios de concesión de memoria adaptable de modo de proceso por lotes. Para la primera ejecución de la consulta, la duración es de 88 segundos, debido a los grandes desbordamientos:
DECLARE @EndTime datetime = '2016-09-22 00:00:00.000';
DECLARE @StartTime datetime = '2016-09-15 00:00:00.000';
SELECT TOP 10 hash_unique_bigint_id
FROM dbo.TelemetryDS
WHERE Timestamp BETWEEN @StartTime AND @EndTime
GROUP BY hash_unique_bigint_id
ORDER BY MAX(max_elapsed_time_microsec) DESC;
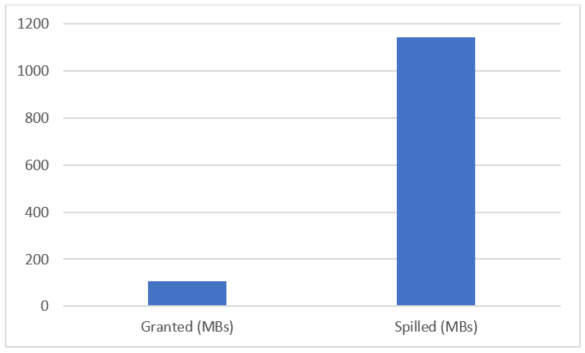
Con los comentarios de concesión de memoria habilitados para la segunda ejecución, la duración es de 1 segundo (partiendo de 88 segundos), los desbordamientos se eliminan por completo y la concesión es superior:
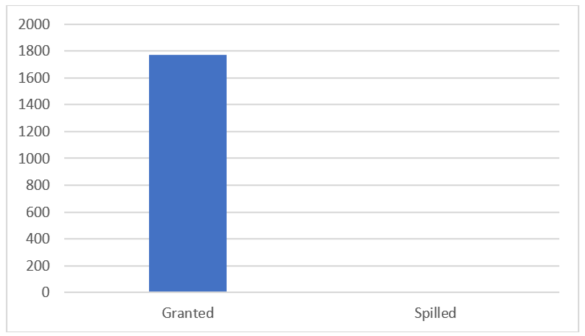
Tamaño de los comentarios de concesión de memoria
En el caso de una condición de concesión de memoria excesiva, si la memoria concedida es más de dos veces el tamaño de la memoria usada real, los comentarios de concesión de memoria volverán a calcular la concesión de memoria y actualizarán el plan almacenado en caché. Los planes con concesiones de memoria por debajo de 1 MB no se vuelven a calcular para usos por encima del límite.
Para una condición de concesión de memoria de tamaño insuficiente que da lugar a un desbordamiento en el disco para los operadores de modo por lotes, los comentarios de concesión de memoria desencadenarán un recálculo de la concesión de memoria. Los eventos de desbordamiento se notifican a los comentarios de concesión de memoria y se pueden exponer con el evento extendido spilling_report_to_memory_grant_feedback. Este evento devuelve el identificador de nodo del plan y el tamaño de los datos desbordados de ese nodo.
La concesión de memoria ajustada se muestra en el plan real (posterior a la ejecución) a través de la propiedad GrantedMemory.
Puede ver esta propiedad en el operador raíz del plan de presentación gráfico o en la salida XML del plan de presentación:
<MemoryGrantInfo SerialRequiredMemory="1024" SerialDesiredMemory="10336" RequiredMemory="1024" DesiredMemory="10336" RequestedMemory="10336" GrantWaitTime="0" GrantedMemory="10336" MaxUsedMemory="9920" MaxQueryMemory="725864" />
Para que se admitan automáticamente las cargas de trabajo para esta mejora, habilite el nivel de compatibilidad 140 para la base de datos.
Ejemplo:
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 140;
Comentarios de concesión de memoria y escenarios confidenciales de parámetros
Los distintos valores de parámetros también podrían necesitar diferentes planes de consulta para seguir siendo óptimos. Este tipo de consulta se define como "sensible a parámetros".
En el caso de los planes sensibles a parámetros, los comentarios de concesión de memoria se deshabilitarán en una consulta si esta tiene requisitos de memoria inestables. La característica de comentarios de concesión de memoria se deshabilita después de varias ejecuciones repetidas de la consulta y se puede observar mediante la supervisión del evento extendido memory_grant_feedback_loop_disabled. Esta condición se mitiga con el modo de persistencia y percentil para los comentarios de concesión de memoria introducido en SQL Server 2022 (16.x). La característica de persistencia de comentarios de concesión de memoria requiere que el almacén de consultas esté habilitado en la base de datos y se establezca en modo de "lectura y escritura".
Para obtener más información sobre el examen de parámetros y la sensibilidad de estos, consulte la Guía de arquitectura de procesamiento de consultas.
Almacenamiento en caché de los comentarios de concesión de memoria
Los comentarios pueden almacenarse en el plan almacenado en caché para una sola ejecución. Sin embargo, son las ejecuciones consecutivas de esa instrucción que se benefician de los ajustes de comentarios de concesión de memoria. Esta característica se aplica a la ejecución repetida de instrucciones. Los comentarios de concesión de memoria solo cambian el plan almacenado en caché. Antes de SQL Server 2022 (16.x), los cambios no se capturaban en el almacén de consultas.
Los comentarios no se conservan si el plan se expulsa de la memoria caché. Los comentarios también se perderán si hay una conmutación por error. Una instrucción que usa OPTION (RECOMPILE) crea un nuevo plan y no la almacena en caché. Puesto que no se almacena en caché, no se genera ningún comentario de concesión de memoria y no se almacena para esa compilación y ejecución. Sin embargo, si se almacena en caché una instrucción equivalente (es decir, con el mismo hash de consulta) que no usó OPTION (RECOMPILE) y, a continuación, se vuelve a ejecutar, las ejecuciones consecutivas segunda y posterior pueden beneficiarse de los comentarios de concesión de memoria.
Seguimiento de la actividad de comentarios de concesión de memoria
Puede realizar un seguimiento de los eventos de comentarios de concesión de memoria mediante el evento extendido memory_grant_updated_by_feedback. Este evento realiza un seguimiento del historial de recuentos de ejecución actual, del número de veces que los comentarios de concesión de memoria han provocado una actualización del plan, de la concesión de memoria adicional ideal antes de la modificación y de la concesión de memoria adicional ideal después de que los comentarios de concesión de memoria hayan modificado el plan almacenado en caché.
Comentarios de concesión de memoria, regulador de recursos y sugerencias de consulta
La memoria real concedida respeta el límite de memoria de consulta determinado por el regulador de recursos o la sugerencia de consulta.
Deshabilitación de los comentarios de concesión de memoria del modo por lotes sin cambiar el nivel de compatibilidad
Los comentarios de concesión de memoria se pueden deshabilitar en el ámbito de base de datos o de instrucción mientras se mantiene el nivel de compatibilidad de base de datos 140 o posterior. Para deshabilitar los comentarios de concesión de memoria del modo por lotes para todas las ejecuciones de consulta que se originan en la base de datos, ejecute las instrucciones SQL siguientes en el contexto de la base de datos aplicable:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_MEMORY_GRANT_FEEDBACK = ON;
-- Starting with SQL Server 2019, and in Azure SQL Database
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_MEMORY_GRANT_FEEDBACK = OFF;
Cuando se habilita, esta opción aparecerá como habilitada en sys.database_scoped_configurations.
Para volver a habilitar los comentarios de concesión de memoria del modo por lotes para todas las ejecuciones de consulta que se originan en la base de datos, ejecute las instrucciones SQL en el contexto de la base de datos aplicable:
-- SQL Server 2017
ALTER DATABASE SCOPED CONFIGURATION SET DISABLE_BATCH_MODE_MEMORY_GRANT_FEEDBACK = OFF;
-- Azure SQL Database, SQL Server 2019 and higher
ALTER DATABASE SCOPED CONFIGURATION SET BATCH_MODE_MEMORY_GRANT_FEEDBACK = ON;
También puede deshabilitar los comentarios de concesión de memoria en modo por lotes para una consulta específica si designa DISABLE_BATCH_MODE_MEMORY_GRANT_FEEDBACK como sugerencia de consulta USE HINT. Por ejemplo:
SELECT * FROM Person.Address
WHERE City = 'SEATTLE' AND PostalCode = 98104
OPTION (USE HINT ('DISABLE_BATCH_MODE_MEMORY_GRANT_FEEDBACK'));
Una sugerencia de consulta USE HINT tiene prioridad sobre una configuración con ámbito de base de datos o una configuración de marca de seguimiento.
Comentarios de concesión de memoria del modo de fila
Se aplica a: SQL Server (a partir de SQL Server 2019 (15.x)), Azure SQL Database
Los comentarios de concesión de memoria del modo de fila se expanden en la característica de comentarios de concesión de memoria de modo de proceso por lotes al ajustar los tamaños de concesión de memoria tanto para los operadores del modo de proceso por lotes como del modo de fila.
Para habilitar los comentarios de concesión de memoria en modo de fila en Azure SQL Database, habilite el nivel 150 o superior de compatibilidad de la base de datos para la base de datos a la que está conectado al ejecutar la consulta.
Ejemplo:
ALTER DATABASE [<database name>] SET COMPATIBILITY_LEVEL = 150;
Al igual que con los comentarios de concesión de memoria en modo por lotes, la actividad de comentarios de concesión de memoria del modo de fila es visible a través de XEvent memory_grant_updated_by_feedback. También se presentan dos nuevos atributos del plan de ejecución de consultas para mejorar la visibilidad del estado actual de una operación de comentarios de concesión de memoria para el modo de fila y por lotes.
Los comentarios de concesión de memoria no requieren el almacén de consultas; sin embargo, las mejoras de persistencia introducidas en SQL Server 2022 (16.x) requieren que el almacén de consultas esté habilitado para la base de datos y en un estado de "lectura y escritura". Para obtener más información sobre la persistencia, consulte Comentarios de concesión de memoria en modo percentil y persistencia más adelante en este artículo.
La actividad de comentarios de concesión de memoria del modo de fila es visible a través del evento extendido memory_grant_updated_by_feedback.
Con los comentarios de concesión de memoria en el modo por filas, se muestran dos nuevos atributos de plan de consulta para los planes reales posteriores a la ejecución: IsMemoryGrantFeedbackAdjusted y LastRequestedMemory, que se agregan al elemento XML MemoryGrantInfo del plan de consulta.
- El atributo
LastRequestedMemorymuestra la memoria concedida en kilobytes (KB) de la ejecución de la consulta anterior. - El atributo
IsMemoryGrantFeedbackAdjustedpermite comprobar el estado de los comentarios de concesión de memoria para la instrucción dentro de un plan de ejecución de consulta real.
Los valores que se exponen en este atributo son los siguientes:
Valor de IsMemoryGrantFeedbackAdjusted |
Descripción |
|---|---|
| No: First Execution | Los comentarios de concesión de memoria no ajustan la memoria para la primera compilación y ejecución asociada. |
| No: Accurate Grant | Si no hay ningún desbordamiento en el disco y la instrucción usa al menos el 50 % de la memoria concedida, no se desencadenan los comentarios de concesión de memoria. |
| No: Feedback disabled | Si los comentarios de concesión de memoria se desencadenan continuamente y fluctúan entre las operaciones de aumento y disminución de memoria, el motor de base de datos deshabilitará los comentarios de concesión de memoria para la instrucción. |
| Yes: Adjusting | Se aplicaron los comentarios de concesión de memoria y se podrían seguir ajustando para la próxima ejecución. |
| Sí: ajuste de percentil | Los comentarios de concesión de memoria se aplican mediante el algoritmo de concesión de percentil, que examina más historial que solo la ejecución más reciente. |
| Yes: Stable | Se aplicaron los comentarios de concesión de memoria y ahora la memoria concedida es estable, lo que significa que lo último que se concedió para la ejecución anterior es lo que se concedió para la ejecución actual. |
Comentarios de concesión de memoria en modo percentil y persistencia
Se aplica a: SQL Server (a partir de SQL Server 2022 (16.x)), Azure SQL Database
Esta característica se introdujo en SQL Server 2022 (16.x), pero esta mejora de rendimiento está disponible para las consultas que funcionan en el nivel 140 de compatibilidad de la base de datos (introducido en SQL Server 2017) o superior, o la sugerencia QUERY_OPTIMIZER_COMPATIBILITY_LEVEL_n de 140 y posteriores, y cuando el almacén de consultas está habilitado para la base de datos y está en un estado de "lectura de escritura".
- Los comentarios de concesión de memoria de percentil están habilitados de forma predeterminada en SQL Server 2022 (16.x), pero no tienen ningún efecto si el almacén de consultas no está habilitado o cuando este no está en un estado de "lectura de escritura".
- La persistencia de los comentarios de concesión de memoria, CE y DOP se activa de forma predeterminada en SQL Server 2022 (16.x), pero no tiene ningún efecto cuando el almacén de consultas no está habilitado o cuando este no está en un estado de "lectura de escritura".
- El percentil y la persistencia de los comentarios de concesión de memoria están disponibles en Azure SQL Database y se habilitan de forma predeterminada en todas las bases de datos, tanto existentes como nuevas.
- El percentil y la persistencia de los comentarios de concesión de memoria no están disponibles actualmente en Azure SQL Managed Instance.
Se recomienda tener una línea base de rendimiento para la carga de trabajo antes de habilitar la característica para la base de datos. Los números de línea base le ayudarán a determinar si obtiene la ventaja prevista de la característica.
Los comentarios de concesión de memoria (MGF) son una característica existente que ajusta el tamaño de la memoria asignada para una consulta en función del rendimiento pasado. Sin embargo, las fases iniciales de este proyecto solo almacenaron el ajuste de concesión de memoria con el plan en la memoria caché; si un plan se expulsa de la memoria caché, el proceso de comentarios debe iniciarse de nuevo, lo que da lugar a un rendimiento deficiente las primeras veces que se ejecuta una consulta después de la expulsión. La nueva solución consiste en conservar la información de concesión con la otra información de consulta en el almacén de consultas para que las ventajas persistan en las expulsiones de caché. La persistencia de los comentarios de concesión de memoria y el percentil abordan las limitaciones existentes de los comentarios de concesión de memoria de forma no intrusiva.
Además, los ajustes de tamaño de concesión solo se contabilizan para la concesión usada más recientemente. Por lo tanto, si una consulta o carga de trabajo con parámetros requiere tamaños de concesión de memoria considerablemente diferentes con cada ejecución, la información de concesión más reciente podría ser inexacta. Podría estar fuera del paso con las necesidades reales de la consulta que se ejecuta. Los comentarios de concesión de memoria en este escenario no son útiles para el rendimiento, ya que siempre estamos ajustando la memoria en función del último valor de concesión usado. En la imagen siguiente se muestra el comportamiento posible con los comentarios de concesión de memoria sin percentil y modo de persistencia.

Como puede ver, en este comportamiento de consulta inusual pero posible, la oscilación entre los importes de memoria necesarios reales y concedidos da como resultado una cantidad de memoria desperdiciada e insuficiente si la propia ejecución de la consulta se alterna en términos de la cantidad de memoria. Los comentarios de concesión de memoria se deshabilitan por sí mismos sin esta mejora, reconociendo que está haciendo más daño que bien.
Con un cálculo basado en percentil en el historial reciente de la consulta, en lugar de que solo sea la última ejecución, podemos suavizar los valores de tamaño de concesión en función del historial de uso de ejecución pasado e intentar optimizar para minimizar los desbordamientos. Por ejemplo, la misma carga de trabajo alternada vería el siguiente comportamiento de concesión de memoria:

El optimizador de consultas usa un percentil alto de los requisitos de tamaño de concesión de memoria anteriores para las ejecuciones del plan almacenado en caché a fin de calcular los tamaños de concesión de memoria utilizando los datos almacenados en el almacén de consultas. El ajuste de percentil, que realizará los ajustes de concesión de memoria se basa en el historial reciente de ejecuciones. Con el tiempo, la concesión de memoria dada reduce los desbordamientos y la memoria desperdiciada.
La persistencia también se aplica a los comentarios de DOP y a los comentarios de CE.
Habilitación y deshabilitación de las características de comentarios de concesión de memoria
Deshabilitación de los comentarios de concesión de memoria del modo de fila sin cambiar el nivel de compatibilidad
Los comentarios de concesión de memoria en modo de fila se pueden deshabilitar en el ámbito de base de datos o de instrucción mientras se mantiene el nivel de compatibilidad de base de datos 150 o posterior. Para deshabilitar los comentarios de concesión de memoria del modo de fila para todas las ejecuciones de consulta que se originan en la base de datos, ejecute las instrucciones SQL en el contexto de la base de datos aplicable:
ALTER DATABASE SCOPED CONFIGURATION SET ROW_MODE_MEMORY_GRANT_FEEDBACK = OFF;
Para volver a habilitar los comentarios de concesión de memoria en modo de fila para todas las ejecuciones de consultas que se originan en la base de datos, ejecute lo siguiente en el contexto de la base de datos aplicable:
ALTER DATABASE SCOPED CONFIGURATION SET ROW_MODE_MEMORY_GRANT_FEEDBACK = ON;
También puede deshabilitar los comentarios de concesión de memoria en modo de fila para una consulta específica si designa DISABLE_ROW_MODE_MEMORY_GRANT_FEEDBACK como sugerencia de consulta USE HINT. Por ejemplo:
SELECT * FROM Person.Address
WHERE City = 'SEATTLE' AND PostalCode = 98104
OPTION (USE HINT ('DISABLE_ROW_MODE_MEMORY_GRANT_FEEDBACK'));
Una sugerencia de consulta USE HINT tiene prioridad sobre una configuración con ámbito de base de datos o una configuración de marca de seguimiento.
Habilitación de los comentarios de concesión de memoria: persistencia y percentil
Los comentarios de persistencia y percentil están habilitados de forma predeterminada en Azure SQL Database y SQL Server 2022 (16.x).
Use el nivel 140 o superior de compatibilidad de base de datos para la base de datos a la que está conectado al ejecutar la consulta. Puede cambiarlo a través de ALTER DATABASE:
ALTER DATABASE <DATABASE NAME> SET COMPATIBILITY LEVEL = 140; -- OR HIGHER
El almacén de datos de consultas debe estar habilitado para cada base de datos en la que se use la parte de persistencia de esta característica.
Deshabilitación del percentil
Para deshabilitar el percentil de comentarios de concesión de memoria para todas las ejecuciones de consulta que se originan en la base de datos, ejecute lo siguiente en el contexto de la base de datos aplicable:
ALTER DATABASE SCOPED CONFIGURATION SET MEMORY_GRANT_FEEDBACK_PERCENTILE_GRANT = OFF;
El valor predeterminado de MEMORY_GRANT_FEEDBACK_PERCENTILE_GRANT es ON.
Deshabilitación de la persistencia
Permite deshabilitar la persistencia de los comentarios de concesión de memoria de todas las ejecuciones de consultas que se originan en la base de datos.
Ejecute lo siguiente en el contexto de la base de datos aplicable:
ALTER DATABASE SCOPED CONFIGURATION SET MEMORY_GRANT_FEEDBACK_PERSISTENCE = OFF;
Al deshabilitar la persistencia de comentarios de concesión de memoria, también se quitarán los comentarios recopilados existentes.
El valor predeterminado de MEMORY_GRANT_FEEDBACK_PERSISTENCE es ON.
Consideraciones sobre los comentarios de concesión de memoria
Puede ver la configuración actual consultando sys.database_scoped_configurations.
Nota:
Esta característica no funcionará si BATCH_MODE_MEMORY_GRANT_FEEDBACK y ROW_MODE_MEMORY_GRANT_FEEDBACK están establecidas en OFF.
Como los datos de comentarios proporcionados ahora se conservan en el almacén de consultas, hay cierto aumento en los requisitos de uso del almacén de consultas.
La concesión de memoria basada en el percentil peca de reducir los volcados. Dado que ya no se basa en la última ejecución, sino en una observación de las varias ejecuciones anteriores, esto podría aumentar el uso de memoria para las cargas de trabajo oscilantes con una gran varianza en los requisitos de concesión de memoria entre ejecuciones.
A partir de SQL Server 2022 (16.x), cuando se habilita el almacén de consultas para réplicas secundarias, los comentarios de concesión de memoria son compatibles con réplicas para réplicas secundarias en grupos de disponibilidad. Los comentarios de concesión de memoria pueden aplicar comentarios de forma diferente en una réplica principal y en una réplica secundaria. Sin embargo, los comentarios de concesión de memoria no se conservan en las réplicas secundarias y, en la conmutación por error, los comentarios de concesión de memoria de la réplica principal antigua se aplican a la nueva réplica principal. Los comentarios aplicados a la réplica secundaria cuando se convierten en la réplica principal se pierden. Para obtener más información, consulte Almacén de consultas para réplicas secundarias.
Contenido relacionado
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de