Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server
SQL Server![]() Azure SQL Database
Azure SQL Database![]() Instancia
Instancia ![]() administrada de Azure SQLBase de datos SQL en Microsoft Fabric
administrada de Azure SQLBase de datos SQL en Microsoft Fabric
El motor de base de datos de SQL Server procesa consultas en diversas arquitecturas de almacenamiento de datos como tablas locales, tablas con particiones y tablas distribuidas entre varios servidores. En las secciones siguientes se trata el modo en que SQL Server procesa las consultas y optimiza la reutilización de consultas a través del almacenamiento en caché de los planes de ejecución.
Modos de ejecución
El motor de base de datos de SQL Server puede procesar las instrucciones Transact-SQL mediante dos modos de procesamiento distintos:
- Ejecución del modo de fila
- Ejecución del modo por lotes
Ejecución del modo de fila
La ejecución del modo de fila es un método de procesamiento de consultas que se usa con tablas RDBMS tradicionales, donde los datos se almacenan en formato de fila. Cuando se ejecuta una consulta y accede a los datos de tablas de almacén de filas, los operadores del árbol de ejecución y los operadores secundarios leen todas las filas necesarias, en todas las columnas especificadas en el esquema de tabla. De cada fila que se lee, SQL Server recupera las columnas que son necesarias para el conjunto de resultados, como se hace referencia mediante una instrucción SELECT, un predicado JOIN o un predicado de filtro.
Nota:
La ejecución del modo de fila es muy eficaz para escenarios OLTP, pero puede serlo menos cuando se analizan grandes cantidades de datos, por ejemplo en escenarios de almacenamiento de datos.
Ejecución del modo por lotes
La ejecución por lotes es un método de procesamiento de consultas utilizado para procesar múltiples filas juntas (de ahí el término "por lotes"). Cada columna dentro de un lote se almacena como un vector en un área de memoria independiente, por lo que el procesamiento del modo por lotes se basa en vectores. En el procesamiento del modo por lotes también se utilizan algoritmos optimizados para CPU multinúcleo y mayor ancho de banda de memoria que se encuentran en el hardware moderno.
Cuando se introdujo por primera vez, la ejecución del modo por lotes estaba estrechamente integrada con el formato de almacenamiento de almacén de columnas y optimizada para este. Sin embargo, a partir de SQL Server 2019 (15.x) y en Azure SQL Database, la ejecución del modo por lotes ya no requiere índices de almacenes de columnas. Para obtener más información, consulte Modo por lotes en el almacén de filas.
El procesamiento del modo por lotes funciona en los datos comprimidos siempre que sea posible y elimina el operador de intercambio que usa el procesamiento del modo de fila. El resultado es un mayor paralelismo y un rendimiento más rápido.
Cuando una consulta se ejecuta en el modo por lotes y tiene acceso a los datos de índices de almacén de columnas, los operadores del árbol de ejecución y los operadores secundarios leen varias filas en segmentos de columna. SQL Server solo lee las columnas necesarias para el resultado, tal y como se indica en una instrucción SELECT, un predicado JOIN o un predicado de filtro. Para más información sobre los índices de almacén de columnas, vea Arquitectura de los índices de almacén de columnas.
Nota:
La ejecución del modo por lotes es muy eficaz en escenarios de almacenamiento de datos, donde se leen y se agregan grandes cantidades de datos.
Procesamiento de instrucciones SQL
La forma más básica de ejecutar instrucciones Transact-SQL en SQL Server consiste en procesar una única instrucción Transact-SQL. Los pasos que se usan para procesar una única instrucción SELECT que solo hace referencia a tablas base locales (no a vistas ni a tablas remotas) ilustran el proceso básico.
Precedencia de los operadores lógicos
Cuando en una instrucción se usa más de un operador lógico, primero se evalúa NOT, luego AND y, finalmente, OR. Los operadores aritméticos y bit a bit se tratan antes que los operadores lógicos. Para más información, vea Prioridad de operador.
En el siguiente ejemplo, la condición de color pertenece al modelo de producto 21 y no al modelo de producto 20, ya que porque AND tiene prioridad sobre OR.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
Puede cambiar el significado de la consulta si agrega paréntesis para provocar que OR se evalúe primero. La siguiente consulta busca solamente los productos en los modelos 20 y 21 que sean rojos.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
El uso de paréntesis, incluso cuando no se necesitan, puede mejorar la comprensión de las consultas y reducir las posibilidades de cometer un error debido a la prioridad de los operadores. No hay ninguna reducción significativa del rendimiento que sea achacable al uso de paréntesis. El siguiente ejemplo se lee mejor que el ejemplo original, aunque ambos son sintácticamente iguales.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
Optimización de las instrucciones SELECT
Una instrucción SELECT no es de procedimiento, ya que no expone los pasos exactos que el servidor de bases de datos debe usar para recuperar los datos solicitados. Esto significa que el servidor de la base de datos debe analizar la instrucción para determinar la manera más eficaz de extraer los datos solicitados. Este proceso se denomina optimizar la instrucción SELECT . El componente que lleva a cabo este proceso se denomina Optimizador de consultas. La entrada al Optimizador de consultas consta de la consulta, el esquema de la base de datos (definiciones de tabla e índice) y las estadísticas de base de datos. La salida del Optimizador de consultas es un plan de ejecución de consultas, en ocasiones denominado plan de consulta o simplemente plan de ejecución. El contenido de un plan de ejecución se describe con más detalle posteriormente en este artículo.
En el siguiente diagrama se muestran las entradas y salidas del optimizador de consultas durante la optimización de una única instrucción SELECT:
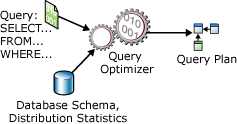
Una instrucción SELECT define únicamente los siguientes elementos:
- El formato del conjunto de resultados. Este elemento se especifica principalmente en la lista de selección. Sin embargo, también afectan a la forma final del conjunto de resultados otras cláusulas como
ORDER BYyGROUP BY. - Las tablas que contienen los datos de origen. Se especifica en la cláusula
FROM. - Cómo se relacionan las tablas de forma lógica para la instrucción
SELECT. Esto se define en las especificaciones de combinación, que pueden aparecer en la cláusulaWHEREo en una cláusulaONque sigue aFROM. - Las condiciones que deben cumplir las filas de las tablas de origen para satisfacer los requisitos de la instrucción
SELECT. Se especifican en las cláusulasWHEREyHAVING.
Un plan de ejecución de consulta es una definición de los siguientes elementos:
La secuencia en la que se tiene acceso a las tablas de origen.
Normalmente, hay muchas secuencias diferentes en las que el servidor de la base de datos puede tener acceso a las tablas base para generar el conjunto de resultados. Por ejemplo, si la instrucciónSELECThace referencia a tres tablas, el servidor de la base de datos podría tener acceso primero aTableA, utilizar los datos deTableApara extraer las filas que coincidan con las deTableBy, finalmente, utilizar los datos deTableBpara extraer datos deTableC. Las demás secuencias en las que el servidor de base de datos podría tener acceso a las tablas son:
TableC,TableB,TableAo
TableB,TableA,TableCo
TableB,TableC,TableAo
TableC, ,TableA,TableBLos métodos que se usan para extraer los datos de cada tabla.
Por lo general, hay métodos diferentes para tener acceso a los datos de cada tabla. Si solo se necesitan unas cuantas filas con valores de clave específicos, el servidor de la base de datos puede utilizar un índice. Si se necesitan todas las filas de una tabla, el servidor de la base de datos puede omitir los índices y realizar un recorrido de la tabla. Si se necesitan todas las filas de la tabla, pero hay un índice cuyas columnas de clave están ordenadas conORDER BY, realizar un recorrido del índice en lugar de un recorrido de la tabla puede evitar otra ordenación del conjunto de resultados. Si una tabla es muy pequeña, los escaneos de la tabla podrían ser el método más eficiente para casi todos los accesos a la tabla.Los métodos que se usan para realizar cálculos, y cómo filtrar, agregar y ordenar los datos de cada tabla.
A medida que se tiene acceso a los datos desde las tablas, existen distintos métodos para realizar cálculos sobre ellos (por ejemplo, calcular valores escalares), para agregarlos y ordenarlos tal como se define en el texto de la consulta, por ejemplo, cuando se usa una cláusulaGROUP BYoORDER BY, y cómo filtrarlos, por ejemplo, cuando se usa una cláusulaWHEREoHAVING.
El proceso de selección de un plan de ejecución entre varios planes posibles se conoce como optimización. El Optimizador de consultas es uno de los componentes más importantes del Motor de base de datos. Mientras que parte de la carga de trabajo se debe al análisis de la consulta y selección de un plan por parte del optimizador de consultas, esta carga suele reducirse cuando dicho optimizador elige un plan de ejecución eficaz. Por ejemplo, se pueden dar a dos constructoras planos idénticos para una casa. Si una de las constructoras tarda unos días más en planear cómo construirá la casa y la otra comienza a construir inmediatamente sin planear, la que ha planeado su proyecto probablemente terminará antes.
El Optimizador de consultas de SQL Server es un optimizador basado en el coste. Cada plan de ejecución posible tiene asociado un costo en términos de la cantidad de recursos del equipo que se utilizan. El optimizador de consultas debe analizar los planes posibles y elegir el de menor costo estimado. Algunas instrucciones SELECT complejas tienen miles de planes de ejecución posibles. En estos casos, el Optimizador de consultas no analiza todas las combinaciones posibles. En lugar de esto, utiliza algoritmos complejos para encontrar un plan de ejecución que tenga un costo razonablemente cercano al mínimo posible.
El Optimizador de consultas de SQL Server elige, además del plan de ejecución con el coste de recursos mínimo, el plan que devuelve resultados al usuario con un coste razonable de recursos y con la mayor brevedad posible. Por ejemplo, el procesamiento de una consulta en paralelo suele utilizar más recursos que el procesamiento en serie, pero completa la consulta más rápidamente. El Optimizador de consultas de SQL Server utilizará un plan de ejecución en paralelo para devolver resultados si esto no afecta negativamente a la carga del servidor.
El Optimizador de consultas de SQL Server se basa en las estadísticas de distribución cuando estima los costes de recursos de métodos diferentes para extraer información de una tabla o un índice. Se mantienen estadísticas de distribución para las columnas y los índices, y se conserva información sobre la densidad1 de los datos subyacentes. Esto se usa para indicar la selectividad de los valores de una columna o un índice determinado. Por ejemplo, en una tabla que representa automóviles, muchos automóviles tienen el mismo fabricante, pero cada uno dispone de un único número de identificación de vehículo (NIV). Un índice del NIV es más selectivo que un índice del fabricante, porque NIV tiene una densidad inferior a la del fabricante. Si las estadísticas de los índices no están actualizadas, puede que el optimizador de consultas no realice la mejor elección para el estado actual de la tabla. Para obtener más información sobre las densidades, vea Estadísticas.
1 La densidad define la distribución de valores únicos que existen en los datos, o bien el promedio de valores duplicados para una columna determinada. A medida que disminuye la densidad, aumenta la selectividad de un valor.
El Optimizador de consultas de SQL Server es importante porque permite que el servidor de bases de datos se ajuste dinámicamente a las condiciones cambiantes de la base de datos, sin necesitar la entrada de un programador o un administrador de base de datos. Esto permite a los programadores centrarse en la descripción del resultado final de la consulta. Pueden estar seguros de que el Optimizador de consultas de SQL Server creará un plan de ejecución eficaz para el estado de la base de datos cada vez que se ejecuta la instrucción.
Nota:
SQL Server Management Studio tiene tres opciones para mostrar los planes de ejecución:
- El plan de ejecución estimado, que es el plan compilado, generado por el optimizador de consultas.
- El plan de ejecución real, que es lo mismo que el plan compilado más su contexto de ejecución. Esto incluye la información de runtime disponible una vez completada la ejecución, como advertencias de ejecución o, en versiones más recientes del Motor de base de datos, el tiempo transcurrido y el tiempo de CPU usado durante la ejecución.
- Las estadísticas de consulta activa, que es lo mismo que el plan compilado más su contexto de ejecución. Esto incluye información en tiempo de ejecución durante el progreso de la ejecución y se actualiza cada segundo. La información en tiempo de ejecución incluye, por ejemplo, el número real de filas que fluyen a través de los operadores.
Procesamiento de una instrucción SELECT
Los pasos básicos que utiliza SQL Server para procesar una única instrucción SELECT incluyen lo siguiente:
- El analizador examina la instrucción
SELECTy la divide en unidades lógicas como palabras clave, expresiones, operadores e identificadores. - Se genera un árbol de la consulta, a veces denominado árbol de secuencia, que describe los pasos lógicos que se requieren para transformar los datos de origen en el formato que necesita el conjunto de resultados.
- El optimizador de consultas analiza diferentes formas de acceso a las tablas de origen. Después, selecciona la serie de pasos que devuelven los resultados de la forma más rápida con el menor número de recursos posible. El árbol de la consulta se actualiza para registrar esta serie exacta de pasos. La versión final y optimizada del árbol de la consulta se denomina plan de ejecución.
- El motor relacional comienza a ejecutar el plan de ejecución. A medida que se procesan los pasos que necesitan datos de las tablas base, el motor relacional solicita al motor de almacenamiento que pase los datos de los conjuntos de filas solicitados desde el motor relacional.
- El motor relacional procesa los datos que devuelve el motor de almacenamiento en el formato definido para el conjunto de resultados y devuelve el conjunto de resultados al cliente.
Doblado de constantes y evaluación de expresiones
SQL Server evalúa algunas expresiones constantes con antelación para mejorar el rendimiento de las consultas. Esta técnica de optimización utilizada por el optimizador de consultas tiene como objetivo simplificar las expresiones en tiempo de compilación en lugar de en tiempo de ejecución. Implica evaluar expresiones constantes durante la compilación de consultas para que el plan de ejecución resultante sea más eficaz. Es lo que se conoce como doblado de constantes. Una constante es un literal de Transact-SQL, como 3, 'ABC', '2005-12-31', 1.0e3 o 0x12345678. Por ejemplo, tome esta consulta:
SELECT * FROM Orders WHERE OrderDate < DATEADD(day, 30 * 12, '2020-01-01');
Aquí, 30 * 12 es una expresión constante. SQL Server puede evaluarlo durante la compilación y volver a escribir la consulta internamente como:
SELECT * FROM Orders WHERE OrderDate < DATEADD(day, 360, '2020-01-01');
Expresiones que pueden plegarse
SQL Server usa el plegado de constantes con los siguientes tipos de expresiones:
- Expresiones aritméticas, como
1 + 1y5 / 3 * 2, que solo incluyen constantes. - Expresiones lógicas, como
1 = 1y1 > 2 AND 3 > 4, que solo incluyen constantes. - Funciones integradas que SQL Server considera que pueden plegarse, tales como
CASTyCONVERT. Por lo general, una función intrínseca se puede plegar si es una función de sus entradas solo y no otra información contextual, como SET opciones, configuración de idioma, opciones de base de datos y claves de cifrado. Las funciones no deterministas no pueden plegarse. Excepto algunas excepciones, las funciones deterministas integradas pueden doblarse. - Métodos deterministas de tipos definidos por el usuario CLR y funciones deterministas definidas por el usuario CLR con valores escalares (a partir de SQL Server 2012 [11.x]). Para obtener más información, vea Doblado constante para las funciones y métodos definidos por el usuario CLR.
Nota:
Los tipos de objetos grandes constituyen una excepción. Si el tipo de salida del proceso de plegado es un tipo de objeto grande, como text, ntext, image, nvarchar(max), varchar(max), varbinary(max) o XML, SQL Server no pliega la expresión.
Expresiones no plegables
El resto de tipos de expresiones no pueden plegarse. En concreto, los siguientes tipos de expresiones no pueden plegarse:
- Expresiones no constantes como una expresión cuyo resultado dependa del valor de una columna.
- Expresiones cuyos resultados dependan de una variable o parámetro locales, como @x.
- Funciones no deterministas.
- Funciones de Transact-SQL definidas por el usuario1.
- Expresiones cuyos resultados dependan de la configuración de idioma.
- Expresiones cuyos resultados dependen de SET las opciones.
- Expresiones cuyos resultados dependan de las opciones de configuración del servidor.
1 Antes de SQL Server 2012 (11.x), las funciones deterministas definidas por el usuario CLR con valores escalares y los métodos de tipos definidos por el usuario CLR no se podían plegar.
Ejemplos de expresiones constantes que pueden plegarse y que no pueden plegarse
Considere la siguiente consulta:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
Si la opción de base de datos PARAMETERIZATION no se establece en FORCED para esta consulta, la expresión 117.00 + 1000.00 se evalúa y sustituye por su resultado, 1117.00, antes de que se compile la consulta. Entre las ventajas de este doblado de constantes figuran las siguientes:
- La expresión no tiene que evaluarse repetidas veces durante el tiempo de ejecución.
- El valor de la expresión después de su evaluación lo utiliza el optimizador de consultas para estimar el tamaño del conjunto de resultados del fragmento de la consulta
TotalDue > 117.00 + 1000.00.
Por otra parte, si la función dbo.f es una función escalar definida por el usuario, la expresión dbo.f(100) no se pliega, puesto que SQL Server no pliega las expresiones que impliquen a funciones definidas por el usuario, incluso si son deterministas. Para obtener más información sobre la parametrización, consulte Parametrización forzada más adelante en este artículo.
Evaluación de expresiones
Además, algunas expresiones cuyas constantes no se pliegan, pero cuyos argumentos se conocen en tiempo de compilación tanto si se trata de parámetros como de constantes, se evalúan mediante el estimador (de cardinalidad) del tamaño del conjunto de resultados que forma parte del optimizador durante la optimización.
Se evalúan las funciones integradas siguientes y los operadores especiales en tiempo de compilación específicamente, si se conocen todas sus entradas: UPPER, LOWER, RTRIM, DATEPART( YY only ), GETDATE, CAST y CONVERT. Los siguientes operadores también se evalúan en tiempo de compilación si se conocen todas sus entradas:
- Operadores aritméticos: +, -, *, /, unarios -
- Operadores lógicos:
AND,OR,NOT - Operadores de comparación:<, >, <=, >=, <>,
LIKE,IS NULL,IS NOT NULL
El optimizador de consultas no evalúa ninguna otra función ni operador durante la estimación de la cardinalidad.
Ejemplos de evaluación de expresiones en tiempo de compilación
Observe este procedimiento almacenado:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
Durante la optimización de la instrucción SELECT del procedimiento, el optimizador de consultas intenta evaluar la cardinalidad esperada del conjunto de resultados para la condición OrderDate > @d+1. La expresión @d+1 no admite el plegado de constantes porque @d es un parámetro. Sin embargo, el valor del parámetro ya se conoce durante la optimización. Esto permite que el optimizador de consultas estime con exactitud el tamaño del conjunto de resultados, lo que ayuda a seleccionar un buen plan de consulta.
Ahora considere un ejemplo similar al anterior, excepto que una variable @d2 local reemplaza @d+1 en la consulta y la expresión se evalúa en una SET instrucción en lugar de en la consulta.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
Cuando la instrucción SELECT en MyProc2 se optimiza en SQL Server, el valor de @d2 no se conoce. Por lo tanto, el optimizador de consultas utiliza una estimación predeterminada para la selectividad de OrderDate > @d2, (en este caso, un 30 por ciento).
Procesar otras instrucciones
Los pasos básicos descritos para procesar una instrucción SELECT se aplican a otras instrucciones Transact-SQL, como INSERT, UPDATE y DELETE. Las instruccionesUPDATE y DELETE deben identificar el conjunto de filas que se van a modificar o eliminar. El proceso de identificación de estas filas es el mismo que se utiliza para identificar las filas de origen que contribuyen al conjunto de resultados de una instrucción SELECT . Las instrucciones UPDATE e INSERT pueden contener instrucciones SELECT incrustadas que proporcionan los valores de los datos que se van a actualizar o insertar.
Incluso las instrucciones del lenguaje de definición de datos (DDL), como CREATE PROCEDURE o ALTER TABLE, se resuelven en última instancia en un conjunto de operaciones relacionales en las tablas de catálogo del sistema y, a veces (como ALTER TABLE ADD COLUMN) en las tablas de datos.
Tablas de trabajo
Es posible que el motor relacional tenga que generar una tabla de trabajo para realizar una operación lógica que se especifica en una instrucción Transact-SQL. Las tablas de trabajo son tablas internas que se utilizan para almacenar resultados intermedios. Se generan tablas de trabajo para determinadas consultas GROUP BY, ORDER BY, o UNION. Por ejemplo, si una cláusula ORDER BY hace referencia a columnas que no están cubiertas por índices, es posible que el motor relacional tenga que generar una tabla de trabajo para ordenar el conjunto de resultados en el orden solicitado. Las tablas de trabajo también se utilizan en ocasiones a modo de colas que contienen temporalmente el resultado de ejecutar parte de un plan de consulta. Las tablas de trabajo se generan en tempdb y se eliminan automáticamente cuando ya no se necesitan.
Resolución de vistas
El procesador de consultas de SQL Server trata las vistas indexadas y no indexadas de manera diferente.
- Las filas de una vista indizada se almacenan en la base de datos con el mismo formato que una tabla. Si el optimizador de consultas decide utilizar una vista indizada en un plan de consulta, ésta recibe el mismo tratamiento que la tabla base.
- Solo se almacena la definición de una vista no indizada, y no las filas de la vista. El optimizador de consultas incorpora la lógica de la definición de la vista en el plan de ejecución que genera para la instrucción Transact-SQL que hace referencia a la vista no indexada.
La lógica utilizada por el Optimizador de consultas de SQL Server para decidir cuándo se tiene que usar una vista indexada es muy similar a la lógica que se usa para decidir cuándo se tiene que usar un índice en una tabla. Si los datos de la vista indexada cubren toda o parte de la instrucción SQL y el optimizador de consultas determina que un índice de la vista es la ruta de acceso menos costosa, el optimizador de consultas elegirá el índice independientemente de si se hace referencia a la vista por su nombre en la consulta.
Si una instrucción Transact-SQL hace referencia a una vista no indizada, el analizador y el optimizador de consultas analizarán el origen de la instrucción Transact-SQL y de la vista, y las resolverán en un plan de ejecución único. No hay un plan para la instrucción Transact-SQL y otro distinto para la vista.
Por ejemplo, considere la vista siguiente:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
En función de esta vista, ambas instrucciones Transact-SQL realizan las mismas operaciones en las tablas base y producen el mismo resultado:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
La característica del plan de presentación de SQL Server Management Studio muestra que el motor relacional genera el mismo plan de ejecución para estas dos instrucciones SELECT .
Uso de sugerencias con vistas
Las sugerencias que se colocan en las vistas de una consulta pueden entrar en conflicto con otras sugerencias que se descubren al expandir la vista para obtener acceso a sus tablas base. En ese caso, la consulta devuelve un error. Por ejemplo, considere la siguiente vista que contiene una sugerencia de tabla en su definición:
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
Ahora supongamos que usted ingresa la siguiente consulta:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
La consulta genera un error porque la sugerencia SERIALIZABLE que se aplica a la vista Person.AddrState de la consulta se propaga a las tablas Person.Address y Person.StateProvince de la vista cuando ésta se expande. No obstante, la expansión de la vista también mostrará la sugerencia NOLOCK en Person.Address. Dado que las indicaciones SERIALIZABLE y NOLOCK entran en conflicto, la consulta resultante es incorrecta.
Las sugerencias de tabla PAGLOCK, NOLOCK, ROWLOCK, TABLOCKo TABLOCKX entran en conflicto las unas con las otras, lo mismo que las sugerencias de tabla HOLDLOCK, NOLOCK, READCOMMITTED, REPEATABLEREADy SERIALIZABLE .
Las sugerencias pueden propagarse por los niveles de las vistas anidadas. Por ejemplo, supongamos que una consulta aplica la sugerencia HOLDLOCK a una vista v1. Cuando se expande v1 , observamos que la vista v2 forma parte de su definición. La definición dev2incluye una sugerencia NOLOCK en una de sus tablas base. Sin embargo, esta tabla también hereda la sugerencia HOLDLOCK de la consulta de la vista v1. Dado que las sugerencias NOLOCK y HOLDLOCK entran en conflicto, se produce un error en la consulta.
Si se utiliza la sugerencia FORCE ORDER en una consulta que contiene una vista, el orden de combinación de las tablas que se encuentran dentro de la vista se determina mediante la posición de la vista en la construcción ordenada. Por ejemplo, la siguiente consulta realiza una selección entre tres tablas y una vista:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
Y View1 se define tal como se muestra a continuación:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
El orden de combinación en el plan de consulta es Table1, Table2, TableA, TableB, Table3.
Resolución de índices en vistas
Al igual que cualquier índice, SQL Server decide utilizar una vista indexada en el plan de consulta solo si el Optimizador de consultas considera que es útil.
Las vistas indexadas se pueden crear en cualquier edición de SQL Server. En algunas ediciones de algunas versiones anteriores de SQL Server, el Optimizador de consultas tiene en cuenta automáticamente la vista indexada. En algunas ediciones de algunas versiones anteriores de SQL Server, para utilizar una vista indexada, se debe usar la sugerencia de tabla NOEXPAND . El uso automático de una vista indizada por el optimizador de consultas solo se admite en ediciones específicas de SQL Server. La base de datos de Azure SQL y Azure SQL Managed Instance también admiten el uso automático de vistas indexadas sin especificar la sugerencia NOEXPAND.
El Optimizador de consultas de SQL Server utiliza una vista indexada cuando se cumplen las siguientes condiciones:
- Las siguientes opciones de sesión están establecidas en
ON:ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
- La opción de sesión
NUMERIC_ROUNDABORTestá establecida en OFF. - El Optimizador de consultas encuentra una coincidencia entre las columnas de índice de la vista y los elementos de la consulta, como:
- Predicados de condiciones de búsqueda de la cláusula WHERE
- Operaciones de combinación
- Funciones de agregado
- Cláusulas
GROUP BY - Referencias de tablas
- El costo estimado de utilización del índice es el más bajo de todos los mecanismos de acceso que tiene en cuenta el optimizador de consultas.
- Todas las tablas a las que se hace referencia en la consulta (directamente o con la expansión de una vista para acceder a sus tablas subyacentes) que se correspondan con una referencia a tabla de la vista indexada deben tener el mismo conjunto de indicaciones aplicado a ellas.
Nota:
Las indicaciones READCOMMITTED y READCOMMITTEDLOCK siempre se consideran como indicaciones diferentes en este contexto, independientemente del nivel de aislamiento de la transacción actual.
Además de los requisitos de las sugerencias de tabla y opciones SET, estas reglas son las mismas que usa el Optimizador de consultas para determinar si un índice de la tabla satisface una consulta. No ha de especificarse ningún otro elemento para que la consulta utilice una vista indizada.
Una consulta no tiene que hacer referencia explícita a una vista indexada en la cláusula FROM del Optimizador de consultas para usar dicha vista. Si la consulta contiene referencias a columnas de las tablas base que también se encuentran en la vista indizada y el optimizador de consultas considera que la vista indizada constituye el mecanismo de acceso de menor costo, el optimizador elige la vista indizada, de forma similar a como elige los índices de la tabla base cuando no se hace referencia directa a los mismos en una consulta. El optimizador de consultas puede elegir la vista cuando contiene columnas a las que no se hace referencia en la consulta, siempre y cuando la vista ofrezca la opción de costo más bajo para incluir una o varias de las columnas especificadas en la consulta.
El optimizador de consultas trata una vista indexada referenciada en la cláusula FROM como una vista estándar. Expande la definición de la vista en la consulta al inicio del proceso de optimización. A continuación se realiza la coincidencia de vista indizada. Puede que se use la vista indexada en el plan de ejecución final seleccionado por el Optimizador de consultas o que, en su lugar, el plan materialice los datos necesarios de la vista mediante el acceso a las tablas base a las que hace referencia la vista. El Optimizador de consultas elige la alternativa de menor costo.
Uso de sugerencias con vistas indizadas
Puede evitar que los índices de la vista se utilicen en una consulta mediante el uso de la sugerencia de consulta EXPAND VIEWS o utilizar la sugerencia de tabla NOEXPAND para exigir el uso de un índice de una vista indexada especificada en la cláusula FROM de una consulta. Sin embargo, debe dejar que sea el optimizador de consultas el que determine dinámicamente los mejores métodos de acceso para cada consulta. Limite la utilización de EXPAND y NOEXPAND a casos específicos en los que se haya comprobado que el rendimiento mejora significativamente.
La opción
EXPAND VIEWSdetermina que el Optimizador de consultas no use ninguno de los índices de la vista en toda la consulta.Cuando se especifica
NOEXPANDen una vista, el Optimizador de consultas considera la posibilidad de usar cualquiera de los índices definidos en la vista. Cuando se especificaNOEXPANDcon la cláusulaINDEX()opcional, el Optimizador de consultas está obligado a usar los índices especificados.NOEXPANDsolo se puede especificar en una vista indexada, nunca en una vista no indexada. El uso automático de una vista indizada por el optimizador de consultas solo se admite en ediciones específicas de SQL Server. La base de datos de Azure SQL y Azure SQL Managed Instance también admiten el uso automático de vistas indexadas sin especificar la sugerenciaNOEXPAND.
Cuando no se especifica NOEXPAND ni EXPAND VIEWS en una consulta que contiene una vista, ésta se expande para tener acceso a las tablas subyacentes. Si la consulta que compone la vista contiene sugerencias de tabla, éstas se propagan a las tablas subyacentes. (Este proceso se explica con más detalle en Resolución de vistas). Siempre que los conjuntos de sugerencias que existen en las tablas subyacentes sean idénticos entre sí, la consulta es elegible para coincidir con una vista indexada. La mayoría de las veces, estas sugerencias coinciden entre sí, ya que se heredan directamente de la vista. Sin embargo, si la consulta hace referencia a tablas en lugar de vistas y las sugerencias aplicadas directamente en estas tablas no son idénticas, no se puede seleccionar dicha consulta para que coincida con una vista indexada. Si las sugerencias INDEX, PAGLOCK, ROWLOCK, TABLOCKX, UPDLOCK o XLOCK se aplican a las tablas a las que se hace referencia en la consulta después de la expansión de la vista, la consulta no se puede seleccionar para la coincidencia de vistas indexadas.
Si una sugerencia de tabla en forma de INDEX (index_val[ ,...n] ) hace referencia a una vista de una consulta y no se especifica también la sugerencia NOEXPAND, se pasa por alto la sugerencia de índice. Para especificar el uso de un determinado índice, use NOEXPAND.
Por lo general, cuando el Optimizador de consultas hace coincidir una vista indexada con una consulta, las sugerencias especificadas en las tablas o vistas de la consulta se aplican directamente a la vista indexada. Si el optimizador de consultas elige no utilizar una vista indizada, las sugerencias se propagan directamente a las tablas a las que se hace referencia en la vista. Para más información, consulte Resolución de vistas. Esta propagación no se aplica a las sugerencias de combinación. Solo se aplican en su posición original en la consulta. El optimizador de consultas no tiene en cuenta las sugerencias de combinación al hacer coincidir consultas con vistas indizadas. Si un plan de consulta utiliza una vista indexada que coincide con parte de una consulta que contiene una sugerencia de combinación, no se utiliza la sugerencia de combinación en el plan.
No se permiten sugerencias en las definiciones de vistas indexadas. En los modos de compatibilidad 80 y superiores, SQL Server pasa por alto las sugerencias incluidas en definiciones de vistas indexadas al mantenerlas o al ejecutar consultas que utilizan dichas vistas. Aunque utilizar sugerencias en definiciones de vistas indexadas no genera un error de sintaxis en el modo de compatibilidad 80, las sugerencias se pasan por alto.
Para obtener más información, vea Sugerencias de tabla (Transact-SQL).
Resolución de vistas con particiones distribuidas
El procesador de consultas de SQL Server optimiza el rendimiento de las vistas con particiones distribuidas. El aspecto más importante del rendimiento de las vistas con particiones distribuidas es la minimización de la cantidad de datos transferidos entre los servidores miembro.
SQL Server crea planes dinámicos e inteligentes que hacen un uso eficaz de las consultas distribuidas para tener acceso a los datos de las tablas miembro remotas:
- El Procesador de consultas usa en primer lugar OLE DB para recuperar las definiciones de la restricción CHECK de cada tabla miembro. Esto permite al procesador de consultas mapear la distribución de valores de clave entre las tablas miembro.
- El procesador de consultas compara los intervalos de clave especificados en la cláusula
WHEREde una instrucción Transact-SQL con el mapa que muestra cómo se distribuyen las filas en las tablas miembro. El procesador de consultas crea entonces un plan de ejecución de consultas que utiliza consultas distribuidas para recuperar únicamente las filas remotas necesarias para completar la instrucción Transact-SQL. El plan de ejecución también se construye de tal manera que cualquier acceso a las tablas miembro remotas, ya sea para datos o metadatos, se demora hasta que se requiere la información.
Por ejemplo, imagine un sistema en el que una tabla Customers está particionada en Server1 (CustomerID de 1 a 3 299 999), Server2 (CustomerID de 3 300 000 a 6 599 999) y Server3 (CustomerID de 6 600 000 a 9 999 999).
Tome como ejemplo el plan de ejecución que se crea para esta consulta ejecutada en Server1:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
El plan de ejecución para esta consulta extrae las filas con los valores clave de CustomerID de 3200000 a 3299999 de la tabla miembro local, y emite una consulta distribuida para recuperar las filas con los valores de clave de 3300000 a 3400000 de Server2.
El procesador de consultas SQL Server también puede crear lógica dinámica en planes de ejecución de consultas para instrucciones Transact-SQL cuyos valores clave no se conocen cuando se tiene que crear el plan. Tome como ejemplo este procedimiento almacenado:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server no puede predecir el valor de clave que proporcionará el parámetro @CustomerIDParameter cada vez que se ejecute el procedimiento. Puesto que el valor de clave no se puede predecir, el procesador de consultas no puede predecir tampoco a qué tabla miembro deberá tenerse acceso. Para tratar este caso, SQL Server crea un plan de ejecución con lógica condicional, lo que se conoce como filtros dinámicos, y que sirve para controlar la tabla miembro a la que se tendrá acceso en función del valor del parámetro de entrada. Suponiendo que el procedimiento almacenado GetCustomer se ejecutó en Server1, la lógica del plan de ejecución puede representarse como se muestra en el siguiente ejemplo:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
A veces SQL Server genera ese tipo de planes dinámicos de ejecución, incluso para consultas sin parámetros. El Optimizador puede parametrizar una consulta de modo que el plan de ejecución pueda volver a usarse. Si el Optimizador de consultas parametriza una consulta que hace referencia a una vista con particiones, el optimizador ya no puede dar por supuesto que las filas necesarias vendrán de una tabla base de datos especificada, y tendrá que utilizar los filtros dinámicos en el plan de ejecución.
Ejecutar un procedimiento almacenado y un desencadenador
SQL Server almacena únicamente el origen de procedimientos almacenados y desencadenadores. La primera vez que se ejecuta un procedimiento almacenado o un desencadenador, el origen se compila en un plan de ejecución. Si el procedimiento almacenado o el desencadenador se ejecutan de nuevo antes de que el plan de ejecución quede anticuado en la memoria, el motor relacional detecta el plan existente y vuelve a utilizarlo. Si el plan ha quedado anticuado en la memoria, se genera uno nuevo. Este proceso es similar al que sigue SQL Server para procesar todas las instrucciones Transact-SQL. La principal ventaja de rendimiento que tienen los procedimientos almacenados y los desencadenadores en SQL Server en comparación con lotes de Transact-SQL dinámico, es que las instrucciones Transact-SQL siempre son las mismas. Por lo tanto, el motor relacional los hace coincidir fácilmente con los planes de ejecución existentes. El procedimiento almacenado y los planes del desencadenador se reutilizan fácilmente.
El plan de ejecución para los procedimientos almacenados y los desencadenadores se ejecuta aparte del plan de ejecución del lote que llama al procedimiento almacenado o que activa el desencadenador. Esto proporciona mayor flexibilidad para volver a utilizar los planes de ejecución de los procedimientos almacenados y desencadenadores.
Almacenamiento en caché y reutilización de planes de ejecución
SQL Server tiene un bloque de memoria que se utiliza para almacenar planes de ejecución y búferes de datos. El porcentaje del conjunto que se asigna a los planes de ejecución o a los búferes de datos varía dinámicamente según el estado del sistema. La parte del bloque de memoria que se usa para almacenar los planes de ejecución se denomina caché de planes.
La caché de planes tiene dos almacenes para todos los planes compilados:
- El almacén de caché Planes de objeto (OBJCP) se usa para los planes relacionados con objetos persistentes (procedimientos almacenados, funciones y desencadenadores).
- El almacén de caché Planes SQL (SQLCP) se usa para los planes relacionados con consultas con parámetros automáticos, dinámicas o preparadas.
En la consulta siguiente se proporciona información sobre el uso de memoria de estos dos almacenes de caché:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Nota:
El almacén de planes tiene dos repositorios adicionales que no se utilizan para almacenar planes.
- El almacén de caché Árboles enlazados (PHDR) se usa para las estructuras de datos utilizadas durante la compilación del plan para vistas, restricciones y valores predeterminados. Estas estructuras se conocen como Árboles enlazados o Árboles algebraicos.
- El almacén de caché Procedimientos almacenados extendidos (XPROC) se usa para los procedimientos predefinidos del sistema, como
sp_executeSqloxp_cmdshell, que se definen mediante un archivo DLL, no mediante instrucciones Transact-SQL. La estructura en caché solo contiene el nombre de la función y el del archivo DLL en el que se implementa el procedimiento.
Los planes de ejecución de SQL Server tienen los siguientes componentes principales:
Plan compilado (o plan de consulta)
El plan de consulta generado por el proceso de compilación es principalmente una estructura de datos reentrante de solo lectura usada por cualquier número de usuarios. Almacena información sobre:Operadores físicos que implementan la operación descrita por los operadores lógicos.
El orden de estos operadores, que determina el orden en el que se accede a los datos, se filtran y se agregan.
El número de filas estimadas que fluyen a través de los operadores.
Nota:
En las versiones más recientes del Motor de base de datos, también se almacena información sobre los objetos de estadísticas que se han usado para la estimación de cardinalidad.
Qué objetos complementarios se deben crear, como tablas de trabajo o archivos de trabajo en
tempdb. En el plan de consulta no se almacena ningún contexto de usuario ni información en tiempo de ejecución. Nunca hay más de una o dos copias del plan de consulta en la memoria: una copia para todas las ejecuciones en serie y otra para todas las ejecuciones en paralelo. La copia en paralelo cubre todas las ejecuciones en paralelo, sin tener en cuenta el grado de paralelismo.
Contexto de ejecución
Cada usuario que ejecuta la consulta tiene una estructura de datos que alberga los datos específicos de su ejecución, como los valores de los parámetros. Esta estructura de datos se conoce como contexto de ejecución. Las estructuras de datos del contexto de ejecución se vuelven a utilizar, pero su contenido no. Si otro usuario ejecuta la misma consulta, las estructuras de datos se reinicializan con el contexto del nuevo usuario.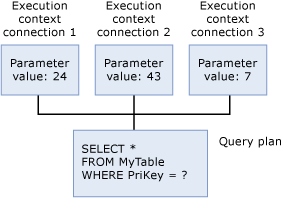
Al ejecutar una instrucción Transact-SQL en SQL Server, el motor de base de datos busca primero en la caché de planes para comprobar la existencia de un plan de ejecución para la misma instrucción Transact-SQL. La instrucción Transact-SQL se considera existente si coincide literalmente con una instrucción Transact-SQL ejecutada anteriormente con un plan en caché, carácter por carácter. SQL Server vuelve a usar cualquier plan existente que encuentra para ahorrar la sobrecarga de volver a compilar la instrucción Transact-SQL. Si no existe ningún plan de ejecución, SQL Server genera uno nuevo para la consulta.
Nota:
Los planes de ejecución de algunas instrucciones Transact-SQL no se almacenan en la caché de planes, como, por ejemplo, instrucciones de operaciones masivas que se ejecutan en almacén de filas, o instrucciones que contienen literales de cadena de más de 8 KB. Estos planes solo existen mientras se ejecuta la consulta.
SQL Server tiene un algoritmo eficiente que permite encontrar cualquier plan de ejecución existente para una determinada instrucción Transact-SQL. En la mayoría de los sistemas, los recursos mínimos utilizados para este escaneo son inferiores a los recursos que se ahorran al poder reutilizar los planes existentes en lugar de compilar cada instrucción de Transact-SQL.
Los algoritmos que hacen coincidir las instrucciones Transact-SQL nuevas con los planes de ejecución no utilizados existentes de la caché de planes requieren que todas las referencias a objetos sean totalmente cualificadas. Por ejemplo, supongamos que Person es el esquema predeterminado para el usuario que ejecuta las instrucciones SELECT siguientes. Aunque en este ejemplo no es necesario que la tabla Person esté completamente calificada para su ejecución, esto significa que la segunda instrucción no se corresponde con un plan existente, pero la tercera sí lo hace.
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
Cambiar cualquiera de las siguientes SET opciones para una ejecución determinada afectará a la capacidad de reutilizar planes, ya que el Motor de base de datos realiza el plegado constante y estas opciones afectan a los resultados de estas expresiones:
ANSI_NULL_DFLT_OFF
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
NUMERIC_ROUNDABORT
ANSI_NULL_DFLT_ON
LANGUAGE
CONCAT_NULL_YIELDS_NULL
DATEFORMAT
ANSI_WARNINGS
QUOTED_IDENTIFIER
ANSI_NULLS
NO_BROWSETABLE
ANSI_DEFAULTS
Almacenamiento en caché de varios planes para la misma consulta
Las consultas y los planes de ejecución se identifican de forma única en el Motor de base de datos, como una huella digital:
- El hash del plan de consulta es un valor hash binario calculado sobre el plan de ejecución de una consulta dada, y se utiliza para identificar de forma única planes de ejecución similares.
- El hash de consulta es un valor hash binario calculado en el texto Transact-SQL de una consulta y se usa para identificar las consultas de forma única.
Un plan compilado se puede recuperar de la caché de planes mediante un identificador de plan, que es un identificador transitorio que permanece constante solo mientras el plan permanece en la caché. El identificador del plan es un valor hash derivado del plan compilado del lote completo. El identificador del plan de un plan compilado permanece sin cambios incluso si se vuelven a compilar una o varias instrucciones del lote.
Nota:
Si se ha compilado un plan para un lote en lugar de una sola instrucción, el plan para instrucciones individuales del lote se puede recuperar mediante el identificador del plan y los desplazamientos de la instrucción.
La DMV sys.dm_exec_requests contiene las columnas statement_start_offset y statement_end_offset de cada registro, que hacen referencia a la instrucción que se está ejecutando actualmente de un lote en ejecución o de un objeto persistente. Para obtener más información, consulte sys.dm_exec_requests (Transact-SQL).
La DMV sys.dm_exec_query_stats también contiene estas columnas para cada registro, que hacen referencia a la posición de una instrucción dentro de un lote o un objeto almacenado. Para más información, vea sys.dm_exec_query_stats (Transact-SQL).
El texto Transact-SQL real de un lote se almacena en un espacio de memoria independiente de la caché de planes denominado caché de SQL Manager (SQLMGR). El texto de Transact-SQL de un plan compilado se puede recuperar de la caché del administrador SQL mediante un SQL Handle, que es un identificador transitorio que permanece constante solo mientras al menos un plan que lo refiera permanezca en la caché de planes. El identificador SQL es un valor hash derivado del texto del lote completo y se garantiza que es único para cada lote.
Nota:
Al igual que un plan compilado, el texto de Transact-SQL se almacena por lote, incluidos los comentarios. El identificador SQL contiene el hash MD5 del texto del lote completo y se garantiza que es único para cada lote.
En la consulta siguiente se proporciona información sobre el uso de memoria de la caché de SQL Manager:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
Hay una relación 1:N entre un identificador SQL y los identificadores de plan. Esa condición se produce cuando la clave de caché para los planes compilados es diferente. Esto puede producirse debido a un cambio en SET las opciones entre dos ejecuciones del mismo lote.
Considere el siguiente procedimiento almacenado:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
Compruebe lo que se puede encontrar en la caché de planes mediante la consulta siguiente:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
Este es el conjunto de resultados.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Ahora ejecute el procedimiento almacenado con otro parámetro, pero sin otros cambios en el contexto de ejecución:
EXEC usp_SalesByCustomer 8
GO
Vuelva a comprobar lo que se puede encontrar en la caché de planes. Este es el conjunto de resultados.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Observe que usecounts ha aumentado a 2, lo que significa que el mismo plan en caché se ha reutilizado tal cual, ya que se han vuelto a usar las estructuras de datos del contexto de ejecución. Ahora cambie la opción SET ANSI_DEFAULTS y ejecute el procedimiento almacenado con el mismo parámetro.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
Vuelva a comprobar lo que se puede encontrar en la caché de planes. Este es el conjunto de resultados.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Observe que ahora hay dos entradas en la salida de la DMV sys.dm_exec_cached_plans:
- En la columna
usecountsse muestra el valor1en el primer registro, que es el plan ejecutado una vez conSET ANSI_DEFAULTS OFF. - En la columna
usecountsse muestra el valor2en el segundo registro, que es el plan ejecutado conSET ANSI_DEFAULTS ON, porque se ha ejecutado dos veces. - El otro valor
memory_object_addresshace referencia a una entrada diferente del plan de ejecución en la caché de planes. Pero el valorsql_handlees el mismo para ambas entradas porque hacen referencia al mismo lote.- La ejecución con
ANSI_DEFAULTSestablecido en OFF tiene un nuevo valorplan_handley está disponible para su reutilización en las llamadas que tengan el mismo conjunto de opciones SET. El nuevo identificador del plan es necesario porque el contexto de ejecución se reinicializó debido a los cambios en las opciones SET. Pero esto no desencadena una recompilación: las dos entradas hacen referencia al mismo plan y a la misma consulta, como se demuestra en los mismos valores dequery_plan_hashyquery_hash.
- La ejecución con
Lo que esto significa en la práctica es que tenemos dos entradas de plan en la caché correspondientes al mismo lote, y subraya la importancia de asegurarse de que las opciones que afectan a la caché de planes SET sean las mismas cuando las mismas consultas se ejecutan repetidamente, para favorecer la reutilización del plan y mantener el tamaño de la caché de planes en el mínimo necesario.
Sugerencia
Un problema común es que los distintos clientes pueden tener valores predeterminados diferentes para las SET opciones. Por ejemplo, una conexión realizada a través de SQL Server Management Studio establece QUOTED_IDENTIFIER de forma automática en ON, mientras que SQLCMD establece QUOTED_IDENTIFIER en OFF. La ejecución de las mismas consultas desde estos dos clientes dará como resultado varios planes (como se ha descrito en el ejemplo anterior).
Eliminar planes de ejecución del caché de planes
Los planes de ejecución permanecen en la caché de planes mientras haya suficiente memoria para almacenarlos. Cuando existe presión de memoria, el Motor de base de datos de SQL Server usa un enfoque basado en costes para determinar qué planes de ejecución hay que eliminar de la caché de planes. Para tomar una decisión basada en costes, el Motor de base de datos de SQL Server incrementa y reduce una variable de coste actual por cada plan de ejecución de acuerdo con los factores siguientes.
Cuando un proceso de usuario inserta un plan de ejecución en la caché, el proceso de usuario establece el coste actual igual al coste de compilación de la consulta original; para los planes de ejecución ad hoc, el proceso de usuario establece el coste actual en cero. Después, cada vez que un proceso de usuario hace referencia a un plan de ejecución, restablece el coste actual en el coste de compilación original; en el caso de los planes de ejecución ad hoc, el proceso de usuario aumenta el coste actual. Para todos los planes, el valor máximo del costo actual es el costo de compilación original.
Cuando existe presión de memoria, el Motor de Base de Datos de SQL Server responde eliminando los planes de ejecución de la caché de planes. Para determinar qué planes eliminar, el Motor de base de datos de SQL Server examina repetidamente el estado de cada plan de ejecución y elimina los planes cuando su coste actual es cero. Un plan de ejecución con un coste actual de cero no se elimina automáticamente cuando existe presión de memoria; solamente se elimina cuando el Motor de base de datos de SQL Server examina el plan y el coste actual es cero. Al examinar un plan de ejecución, el Motor de base de datos de SQL Server impulsa el coste actual hacia cero reduciendo el coste actual si una consulta no está usando actualmente el plan.
El Motor de base de datos de SQL Server examina repetidamente los planes de ejecución hasta que se han eliminado los suficientes para satisfacer los requisitos de memoria. Mientras existe presión de memoria, un plan de ejecución puede ver su costo incrementado y reducido más de una vez. Cuando ya no existe presión de memoria, el Motor de base de datos de SQL Server deja de reducir el coste actual de los planes de ejecución no usados y todos los planes de ejecución permanecen en la caché de planes, incluso aunque su coste sea cero.
El motor de base de datos de SQL Server usa el monitor de recursos y los subprocesos de trabajo de usuario para liberar memoria de la memoria caché del plan en respuesta a la presión de memoria. El monitor de recursos y los subprocesos de trabajo de usuario pueden examinar los planes que se ejecutan simultáneamente y reducir el costo actual de los planes de ejecución no usados. El monitor de recursos quita los planes de ejecución de la caché de planes cuando hay presión de memoria global. Libera memoria para aplicar las directivas correspondientes a la memoria del sistema, memoria de procesos, memoria del grupo de recursos y tamaño máximo de todas las memorias de caché.
El tamaño máximo de todas las memorias de caché es una función del tamaño del grupo de búferes y no puede exceder la memoria máxima del servidor. Para más información sobre la configuración de la memoria máxima del servidor, consulte la configuración de max server memory en sp_configure.
Los subprocesos de trabajo de usuario quitan los planes de ejecución de la caché de planes cuando existe presión de memoria caché única. Aplican las directivas del tamaño máximo de la memoria caché única y de las entradas máximas de la memoria caché única.
En los ejemplos siguientes se muestra qué planes de ejecución se quitan de la caché de planes:
- Se suele hacer referencia a un plan de ejecución como si su costo nunca llegara a ser cero. El plan permanece en la caché de planes y no se elimina a menos que haya presión de memoria y el coste actual sea cero.
- Se insertó un plan de ejecución ad hoc y no se vuelve a hacer referencia a él antes de que exista presión de memoria. Dado que los planes ad hoc se inicializan con un coste actual de cero, cuando el Motor de base de datos de SQL Server examina el plan de ejecución, verá el coste actual de cero y eliminará el plan de la caché de planes. El plan de ejecución ad hoc permanece en la caché de planes con un coste actual de cero cuando no hay presión de memoria.
Para quitar manualmente un único plan o todos los planes de la memoria caché, utilice DBCC FREEPROCCACHE. También se puede usar DBCC FREESYSTEMCACHE para borrar cualquier memoria caché, incluida la caché de planes. Desde SQL Server 2016 (13.x), ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE borra la memoria caché (de plan) de procedimientos de la base de datos en ámbito.
Los cambios en algunos parámetros de configuración mediante sp_configure y reconfigure también harán que se eliminen los planes de la caché de planes. Puede encontrar la lista de estos parámetros de configuración en la sección Comentarios del artículo DBCC FREEPROCCACHE. Este tipo de cambios de configuración registrarán el siguiente mensaje informativo en el registro de errores:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Recompilación de planes de ejecución
Algunos cambios en una base de datos puede hacer que un plan de ejecución resulte ineficaz o no válido, según el nuevo estado de la base de datos. SQL Server detecta los cambios que invalidan un plan de ejecución y marcan el plan como no válido. Después, debe volver a compilarse un nuevo plan para la próxima conexión que ejecute la consulta. Las condiciones que hacen que un plan no sea válido son:
- Los cambios realizados en una tabla o vista a las que hace referencia la consulta (
ALTER TABLEyALTER VIEW). - Los cambios realizados en un único procedimiento eliminan todos los planes de dicho procedimiento de la memoria caché (
ALTER PROCEDURE). - Cambios en los índices utilizados por el plan de ejecución.
- Actualizaciones de estadísticas que utiliza el plan de ejecución y que se generan explícitamente desde instrucciones, como
UPDATE STATISTICS, o automáticamente. - Eliminar un índice utilizado por el plan de ejecución.
- Una llamada explícita a
sp_recompile. - Numerosos cambios en las claves (generados por las instrucciones
INSERToDELETEde otros usuarios que modifican una tabla a la que hace referencia la consulta). - Para tablas con desencadenadores, si el número de filas de las tablas insertadas o eliminadas crece significativamente.
- Ejecutar un procedimiento almacenado mediante la opción
WITH RECOMPILE.
La mayoría de las recompilaciones se necesitan para comprobar si las instrucciones son correctas o para obtener planes de ejecución de consultas potencialmente más rápidos.
En las versiones de SQL Server anteriores a la 2005, siempre que una instrucción de un lote provocaba una recompilación, se volvía a compilar todo el lote, independientemente de si se había enviado por medio de un procedimiento almacenado, un desencadenador, un lote ad hoc o una instrucción preparada. A partir de SQL Server 2005 (9.x), solo se vuelve a compilar la instrucción del lote que desencadena la recompilación. Además, existen otros tipos de recompilaciones en SQL Server 2005 (9.x) y versiones posteriores, gracias al conjunto de características ampliado.
La recompilación de instrucciones beneficia al rendimiento ya que, en la mayoría de los casos, un pequeño número de instrucciones provocan recompilaciones con sus penalizaciones asociadas, en lo que respecta a los bloqueos y el tiempo de la CPU. Estas penalizaciones se evitan para otras instrucciones del lote que no es necesario volver a compilar.
El evento extendido sql_statement_recompile (XEvent) envía informes de recompilaciones de nivel de instrucción. Este XEvent se produce cuando un lote de cualquier tipo requiere una recompilación de nivel de instrucción. Esto incluye procedimientos almacenados, desencadenadores, lotes ad hoc y consultas. Los lotes pueden enviarse mediante diversas interfaces, tales como sp_executesql, SQL dinámico, métodos Prepare o métodos Execute.
La recompile_cause columna de sql_statement_recompile XEvent contiene un código entero que indica el motivo de la recompilación. La tabla siguiente contiene las posibles razones:
Esquema modificado
Estadísticas modificadas
Compilación diferida
SET opción modificada
Tabla temporal modificada
Conjunto de filas remoto modificado
Permiso FOR BROWSE modificado
Entorno de notificación de consultas modificado
Vista particionada modificada
Opciones de cursor modificadas
OPTION (RECOMPILE) solicitado
El plan parametrizado ha sido descartado
Plan que afecta a la versión de la base de datos modificado
Directiva que fuerza el plan del almacén de consultas modificada
Error al forzar el plan de Almacén de consultas
Falta el plan en el almacén de consultas
Nota:
En versiones de SQL Server en las que XEvents no están disponibles, se puede usar el evento de seguimiento de SQL Server Profiler SP:Recompile para el mismo propósito de informar recompilaciones a nivel de instrucción.
El evento de seguimiento SQL:StmtRecompile también informa de recompilaciones de instrucciones, y se puede usar para realizar el seguimiento de las recompilaciones y depurarlas.
Aunque SP:Recompile solo se genera para procedimientos almacenados y desencadenadores, SQL:StmtRecompile se genera para procedimientos almacenados, desencadenadores, lotes ad hoc, lotes que se ejecutan mediante sp_executesql, consultas preparadas y SQL dinámico.
La columna EventSubClass de SP:Recompile y SQL:StmtRecompile contiene un código de número entero que indica la razón de la recompilación. Los códigos se describen en la clase de eventos SQL:StmtRecompile.
Nota:
Si la opción de base de datos AUTO_UPDATE_STATISTICS se establece en ON, las consultas se vuelven a compilar cuando su destino son tablas o vistas indexadas cuyas estadísticas se han actualizado o cuyas cardinalidades han cambiado mucho desde la última ejecución.
Este comportamiento se aplica a tablas estándar definidas por el usuario, a tablas temporales y a tablas insertadas y eliminadas creadas por desencadenadores DML. Si el rendimiento de la consulta se ve afectado por un número excesivo de recompilaciones, considere la posibilidad de cambiar esta opción a OFF. Cuando la opción de base de datos AUTO_UPDATE_STATISTICS está establecida en OFF, no se producen recompilaciones basadas en estadísticas o cambios en la cardinalidad, a excepción de las tablas insertadas y eliminadas que se crean mediante los desencadenadores DML INSTEAD OF. Como estas tablas se crean en tempdb, la recompilación de las consultas a las que tienen acceso depende de la configuración de AUTO_UPDATE_STATISTICS en tempdb.
En las versiones de SQL Server anteriores a la 2005, las consultas se siguen recompilando en función de los cambios de cardinalidad de las tablas insertadas y eliminadas del desencadenador DML, incluso aunque esta opción esté establecida en OFF.
Parámetros y reutilización de un plan de ejecución
El uso de parámetros, incluidos los marcadores de parámetros de las aplicaciones ADO, OLE DB y ODBC, puede incrementar las posibilidades de volver a utilizar los planes de ejecución.
Advertencia
La utilización de parámetros o marcadores de parámetros para contener valores que especifican los usuarios finales es más segura que la concatenación de valores en una cadena que después se ejecuta mediante un método de API de acceso de datos, la instrucción EXECUTE o el procedimiento almacenado sp_executesql .
La única diferencia entre las dos instrucciones SELECT siguientes son los valores que se comparan en la cláusula WHERE :
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
La única diferencia entre los planes de ejecución para estas consultas es el valor que se almacena para la comparación con la columna ProductSubcategoryID . Aunque el objetivo de SQL Server es reconocer siempre que las instrucciones generan básicamente el mismo plan y volver a utilizar los planes, SQL Server no siempre detecta esto en las instrucciones Transact-SQL complejas.
Separar las constantes de la instrucción Transact-SQL mediante parámetros ayuda al motor relacional a reconocer los planes duplicados. Puede utilizar los parámetros de varias maneras:
En Transact-SQL, utilice
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmEste método se recomienda para las scripts de Transact-SQL, procedimientos almacenados o desencadenadores que generan dinámicamente instrucciones SQL.
Con ADO, OLE DB y ODBC, utilice marcadores de parámetros. Los marcadores de parámetro son signos de interrogación (?) que reemplazan una constante en una instrucción SQL y están enlazados a una variable de programa. Por ejemplo, podría hacer lo siguiente en una aplicación ODBC:
Use
SQLBindParameterpara enlazar una variable de entero al primer marcador de parámetro de una instrucción SQL.Coloque el valor entero en la variable.
Ejecute la instrucción y especifique el marcador de parámetros (?):
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
El proveedor de SQL Server Native Client OLE DB y el controlador de SQL Server Native Client ODBC incluidos en SQL Server usan
sp_executesqlpara enviar instrucciones a SQL Server cuando se utilizan marcadores de parámetros en las aplicaciones.Para diseñar procedimientos almacenados, que utilizan parámetros de forma intencionada.
Si no crea explícitamente parámetros en el diseño de las aplicaciones, puede utilizar el Optimizador de consultas de SQL Server para parametrizar automáticamente determinadas consultas mediante el comportamiento predeterminado de parametrización simple. O bien, puede forzar que el Optimizador de consultas tenga en cuenta la parametrización de todas las consultas de la base de datos si establece la opción PARAMETERIZATION de la instrucción ALTER DATABASE en FORCED.
Cuando se habilite la parametrización forzada, la parametrización simple aún puede ocurrir. Por ejemplo, la siguiente consulta no se puede parametrizar según las reglas de parametrización forzada:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
Sin embargo, se puede parametrizar según las reglas de parametrización simple. Cuando la parametrización forzada se intenta pero falla, después se sigue intentando la parametrización simple.
Parametrización simple
En SQL Server, el uso de parámetros o marcadores de parámetros en instrucciones Transact-SQL aumenta la posibilidad de que el motor relacional encuentre planes de ejecución existentes compilados previamente que coincidan con nuevas instrucciones Transact-SQL.
Advertencia
La utilización de parámetros o marcadores de parámetros para contener valores que especifican los usuarios finales es más segura que la concatenación de valores en una cadena que después se ejecuta mediante un método de la API de acceso de datos, la instrucción EXECUTE o el procedimiento almacenado sp_executesql .
Si una instrucción Transact-SQL se ejecuta sin parámetros, SQL Server parametriza la instrucción internamente para aumentar las posibilidades de hacerla coincidir con un plan de ejecución existente. Este proceso se denomina parametrización simple. En las versiones de SQL Server anteriores a la 2005, el proceso se denominaba parametrización automática.
Considere esta declaración:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
El valor 1 del final de la instrucción puede especificarse como un parámetro. El motor relacional genera el plan de ejecución para este lote como si se hubiera especificado un parámetro en lugar del valor 1. Debido a esta parametrización simple, SQL Server reconoce que las dos instrucciones siguientes generan esencialmente el mismo plan de ejecución y reutiliza el primer plan para la segunda instrucción:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Al procesar instrucciones Transact-SQL complejas, el motor relacional puede tener dificultades para determinar qué expresiones pueden parametrizarse. Para aumentar las posibilidades de que el motor relacional encuentre planes de ejecución existentes no utilizados que coincidan con instrucciones Transact-SQL complejas, especifique explícitamente los parámetros con sp_executesql o con marcadores de parámetros.
Nota:
Cuando los operadores aritméticos +, -, *, / o % se usan para realizar la conversión explícita o implícita de los valores de constante int, smallint, tinyint o bigint en los tipos de datos flotantes, reales, decimales o numéricos, SQL Server aplica reglas específicas para calcular el tipo y la precisión de los resultados de la expresión. Sin embargo, estas reglas varían en función de si la consulta se parametriza o no. Por lo tanto, expresiones similares utilizadas en consultas pueden, en ciertos casos, producir resultados diferentes.
En el comportamiento predeterminado de parametrización simple, SQL Server parametriza una clase relativamente pequeña de consultas. No obstante, se puede especificar que, con algunas limitaciones, todas las consultas de una base de datos se parametricen al establecer la opción PARAMETERIZATION del comando ALTER DATABASE en FORCED. De este modo, puede que mejore el rendimiento de bases de datos que reciben grandes volúmenes de consultas simultáneas si se reduce la frecuencia de las compilaciones de consultas.
O bien, puede especificar que una sola consulta, y cualquier otra que sea sintácticamente equivalente pero solo se diferencie en los valores de parámetros, sea parametrizada.
Sugerencia
Cuando se usa una solución de asignación relacional de objetos (ORM), como Entity Framework (EF), es posible que las consultas de aplicación como árboles de consulta LINQ manuales o determinadas consultas SQL sin procesar no se parametricen, lo que afecta a la nueva utilización del plan y a la capacidad de realizar un seguimiento de las consultas en el Almacén de consultas. Para más información, consulte Almacenamiento en caché y parametrización de consultas de EF y Consultas SQL sin formato de EF.
Parametrización forzada
Puede reemplazar el comportamiento predeterminado de parametrización simple de SQL Server si especifica que, con algunas limitaciones, todas las instrucciones SELECT, INSERT, UPDATEy DELETE de una base de datos incluyan parámetros. La parametrización forzada se habilita al establecer la opción PARAMETERIZATION en FORCED en la instrucción ALTER DATABASE . Puede que la parametrización forzada mejore el rendimiento de determinadas bases de datos al reducir la frecuencia de las compilaciones y recopilaciones de consultas. Las bases de datos que pueden beneficiarse de la parametrización forzada suelen ser las que experimentan grandes volúmenes de consultas simultáneas de orígenes como las aplicaciones de punto de venta.
Cuando la opción PARAMETERIZATION está establecida en FORCED, cualquier valor literal que aparezca en una instrucción SELECT, INSERT, UPDATEo DELETE , enviado de cualquier forma, se convierte en un parámetro durante la compilación de consultas. Las excepciones son los literales que aparecen en las siguientes construcciones de consulta:
- Instrucciones
INSERT...EXECUTE. - Instrucciones incluidas en los cuerpos de procedimientos almacenados, desencadenadores o funciones definidas por el usuario. SQL Server ya reutiliza planes de consulta para estas rutinas.
- Instrucciones preparadas que ya han sido parametrizadas en la aplicación del lado del cliente.
- Instrucciones que contienen llamadas a métodos XQuery, en las que el método aparece en un contexto en el que los argumentos suelen incluir parámetros, como una cláusula
WHERE. Si el método aparece en un contexto en el que los argumentos no se parametrizarán, el resto de la instrucción se parametriza. - Instrucciones dentro de un cursor de Transact-SQL. (Las instrucciones
SELECTcontenidas en cursores de la API incluyen parámetros). - Construcciones de consulta obsoletas.
- Cualquier instrucción que se ejecuta en el contexto de
ANSI_PADDINGoANSI_NULLSestablecido enOFF. - Instrucciones que contienen más de 2.097 literales aptos para parametrización.
- Declaraciones que hacen referencia a variables, como
WHERE T.col2 >= @bb. - Instrucciones que contienen la sugerencia de consulta
RECOMPILE. - Declaraciones que contienen una cláusula
COMPUTE. - Declaraciones que contienen una cláusula
WHERE CURRENT OF.
Además, las siguientes cláusulas de consulta no incluyen parámetros. En estos casos, las cláusulas son las únicas que no se parametrizan. Otras cláusulas de la misma consulta podrían ser candidatas para la parametrización forzada.
- El <select_list> de cualquier instrucción
SELECT. Esto incluye listasSELECTde subconsultas ySELECTlistas dentro de instruccionesINSERT. - Instrucciones
SELECTde subconsulta que aparezcan dentro de una instrucciónIF. - Las cláusulas
TOP,TABLESAMPLE,HAVING,GROUP BY,ORDER BY,OUTPUT...INTOoFOR XMLde una consulta. - Argumentos, directos o como subexpresiones, a
OPENROWSET,OPENQUERY,OPENDATASOURCE,OPENXML, o a cualquier operadorFULLTEXT. - Los argumentos pattern y escape_character de una cláusula
LIKE. - El argumento de estilo de una cláusula
CONVERT. - Constantes de tipo entero dentro de una cláusula
IDENTITY. - Constantes especificadas mediante la sintaxis de extensiones ODBC.
- Expresiones que admiten el doblado de constantes y son argumentos de los operadores
+,-,*,/y%. Al considerar la posibilidad de que se pueda elegir la parametrización forzada, SQL Server tiene en cuenta que una expresión admite el plegado de constantes cuando se cumple alguna de las siguientes condiciones:- No aparecen columnas, variables ni subconsultas en la expresión.
- La expresión contiene una cláusula
CASE.
- Argumentos para cláusulas de sugerencias de consulta. Estos incluyen el argumento number_of_rows de la sugerencia de consulta
FAST, el argumento number_of_processors de la sugerencia de consultaMAXDOPy el argumento number de la sugerencia de consultaMAXRECURSION.
La parametrización se produce a nivel de instrucciones Transact-SQL individuales. En otras palabras, las instrucciones individuales de un lote están parametrizadas. Tras la compilación, una consulta con parámetros se ejecuta en el contexto del lote en el que se envió originalmente. Si un plan de ejecución de una consulta se almacena en caché, puede determinar si la consulta se parametrizó mediante una referencia a la columna sql de la vista de administración dinámica sys.syscacheobjects. Si una consulta incluye parámetros, los nombres y tipos de datos de parámetros se anteponen al texto del lote enviado en esta columna, como (@1 tinyint).
Nota:
Los nombres de parámetros son arbitrarios. Los usuarios o las aplicaciones no deben basarse en un determinado orden de nombres. Además, lo siguiente puede cambiar entre versiones de SQL Server y actualizaciones acumulativas (CU): nombres de parámetro, elección de literales parametrizados y espaciado en el texto con parámetros.
Tipos de datos de parámetros
Cuando SQL Server parametriza literales, los parámetros se convierten a los siguientes tipos de datos:
- Los literales de tipo entero cuyo tamaño cabría de otro modo dentro del tipo de datos int se parametrizan a int. Los literales de tipo entero de mayor tamaño que forman parte de predicados que incluyen algún operador de comparación (incluidos
<,<=,=,!=,>,>=,!<,!>,<>,ALL,ANY,SOME,BETWEENeIN) se parametrizan a numeric(38,0). Los literales de mayor tamaño que no forman parte de predicados que incluyen operadores de comparación se parametrizan a numéricos cuya precisión sea lo suficientemente grande como para admitir su tamaño y cuya escala sea 0. - Los literales numéricos de punto fijo que forman parte de predicados que incluyen operadores de comparación se parametrizan a numéricos, con una precisión de 38 y una escala lo suficientemente grande como para admitir su tamaño. Los literales numéricos de punto fijo que no forman parte de predicados que incluyen operadores de comparación se parametrizan a numéricos cuyas precisión y escala son lo suficientemente grandes como para admitir su tamaño.
- Los literales numéricos de punto flotante se parametrizan a float(53).
- Los literales de cadena no Unicode se parametrizan a varchar(8000) si el literal se ajusta a 8000 caracteres y a varchar(max) si tiene un número superior a este.
- Los literales de cadena Unicode se parametrizan a nvarchar(4000) si el literal se ajusta a 4000 caracteres Unicode y a nvarchar(max) si tiene un número superior a este.
- Los literales de tipo binario se parametrizan a varbinary(8000) si el literal se ajusta a 8000 bytes. Si tiene más de 8000 bytes, se convierte a varbinary(max).
- Los literales de tipo money se parametrizan a money.
Instrucciones para utilizar la parametrización forzada
Tenga en cuenta lo siguiente al establecer la opción PARAMETERIZATION en FORCED:
- La parametrización forzada, en efecto, cambia las constantes literales de una consulta a parámetros al compilar una consulta. Por tanto, puede que el optimizador de consultas elija planes menos adecuados para las consultas. En concreto, es menos probable que el optimizador de consultas haga coincidir la consulta con una vista indizada o un índice de una columna calculada. Puede que también elija planes menos adecuados para consultas formuladas en tablas con particiones y vistas con particiones distribuidas. No se debe utilizar la parametrización forzada en entornos que se basan en su mayor parte en vistas indexadas e índices en columnas calculadas. Por lo general, los profesionales de bases de datos experimentados solo deben usar la
PARAMETERIZATION FORCEDopción después de determinar que hacerlo no afecta negativamente al rendimiento. - Las consultas distribuidas que hacen referencia a más de una base de datos se pueden elegir para la parametrización forzada siempre que la opción
PARAMETERIZATIONse establezca enFORCEDen la base de datos en cuyo contexto se ejecuta la consulta. - Al establecer la opción
PARAMETERIZATIONenFORCEDse vacían todos los planes de consulta de la caché de planes de una base de datos, excepto aquéllos que se estén compilando, recompilando o ejecutando en ese momento. Los planes de consulta que se estén compilando o ejecutando durante el cambio de configuración se parametrizan la próxima vez que se ejecute la consulta. - Configurar la opción
PARAMETERIZATIONes una operación en línea que no requiere bloqueos exclusivos a nivel de base de datos. - El valor actual de la opción
PARAMETERIZATIONse mantiene al volver a adjuntar o restaurar una base de datos.
Puede reemplazar el comportamiento de parametrización forzada si especifica que se trate de realizar la parametrización simple en una sola consulta, y en cualquier otra que sea sintácticamente equivalente pero solo se diferencie en los valores de parámetro. Por el contrario, puede especificar que se trate de forzar la parametrización solo en un conjunto de consultas sintácticamente equivalentes, aunque la parametrización forzada esté deshabilitada en la base de datos. Se utilizanguías de planes con este fin.
Nota:
Cuando la opción PARAMETERIZATION está establecida en FORCED, la notificación de mensajes de error podría ser distinta a cuando la opción PARAMETERIZATION se establece en SIMPLE: podrían notificarse varios mensajes de error con una parametrización forzada, en la que se notificarían menos mensajes con la parametrización simple, y los números de línea en los que ocurren los errores podrían indicarse incorrectamente.
Preparación de instrucciones SQL
El motor relacional de SQL Server proporciona compatibilidad completa para preparar las instrucciones Transact-SQL antes de que se ejecuten. Si una aplicación necesita ejecutar una instrucción Transact-SQL varias veces, puede utilizar la API de bases de datos para lo siguiente:
- Prepara la declaración una vez. Esto compila la instrucción Transact-SQL en un plan de ejecución.
- Ejecutar el plan de ejecución precompilado cada vez que sea necesario ejecutar la declaración. Esto evita tener que volver a compilar la instrucción Transact-SQL después de la primera ejecución. Las funciones y los métodos de la API controlan la preparación y la ejecución de las instrucciones. No es parte del lenguaje Transact-SQL. El modelo de preparación y ejecución para ejecutar instrucciones Transact-SQL es compatible con el proveedor OLE DB del cliente nativo de SQL Server y con el controlador ODBC del cliente nativo de SQL Server. En una solicitud de preparación, el proveedor o el controlador envían la instrucción a SQL Server con una solicitud para preparar la instrucción. SQL Server compila un plan de ejecución y devuelve un identificador para ese plan al proveedor o al controlador. En una solicitud de ejecución, el proveedor o el controlador envían al servidor una solicitud para ejecutar el plan asociado al identificador.
Las instrucciones preparadas no se pueden utilizar para crear objetos temporales en SQL Server. Las instrucciones preparadas no pueden hacer referencia a procedimientos almacenados del sistema que creen objetos temporales, como tablas temporales. Estos procedimientos deben ejecutarse directamente.
El uso excesivo del modelo de preparación y ejecución puede reducir el rendimiento. Si una instrucción solo se ejecuta una vez, una ejecución directa solo requiere un recorrido de ida y vuelta por la red al servidor. El hecho de preparar y ejecutar una instrucción Transact-SQL que solo se ejecuta una vez requiere un recorrido de ida y vuelta adicional en la red: uno para preparar la instrucción y otro para ejecutarla.
Preparar una instrucción es más eficaz si se utilizan marcadores de parámetros. Por ejemplo, suponga que se solicita ocasionalmente a una aplicación que recupere información de productos de la base de datos de ejemplo AdventureWorks . Hay dos maneras en que la aplicación puede llevarlo cabo.
En la primera, la aplicación puede ejecutar una consulta independiente para cada producto que se solicita:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
En la segunda, la aplicación hace lo siguiente:
Prepara una instrucción que contiene un marcador de parámetros (?):
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;Enlaza una variable de programa al marcador de parámetros.
Cada vez que se necesite información de productos, llena la variable enlazada con el valor de clave y ejecuta la instrucción.
La segunda forma es más eficaz cuando la instrucción se ejecuta más de tres veces.
En SQL Server, el modelo de preparación y ejecución no tiene ninguna ventaja significativa sobre el rendimiento de la ejecución directa, debido a la manera en que SQL Server reutiliza los planes de ejecución. SQL Server dispone de algoritmos eficientes para hacer corresponder las instrucciones Transact-SQL actuales con los planes de ejecución generados para ejecuciones anteriores de la misma instrucción Transact-SQL. Si una aplicación ejecuta varias veces una instrucción Transact-SQL con marcadores de parámetros, SQL Server volverá a usar el plan de ejecución de la primera ejecución para la segunda ejecución, así como para las siguientes (a menos que el plan quede anticuado en la caché de planes). El modelo de preparación y ejecución sigue teniendo estas ventajas:
- Buscar un plan de ejecución mediante un identificador es más eficaz que los algoritmos que se utilizan para encontrar planes de ejecución existentes que coincidan con una instrucción Transact-SQL.
- La aplicación puede controlar cuándo se crea el plan de ejecución y cuándo se vuelve a utilizar.
- El modelo de preparación y ejecución se puede transportar a otras bases de datos, incluidas las versiones anteriores de SQL Server.
Sensibilidad de los parámetros
Con la expresión sensibilidad de los parámetros, también conocida como "examen de parámetros", se hace referencia a un proceso mediante el cual SQL Server "examina" los valores de parámetros actuales durante la compilación o la recompilación y los pasa al Optimizador de consultas para que se puedan usar para generar planes de ejecución de consultas potencialmente más eficaces.
Los valores de parámetros se examinan durante la compilación o la recompilación de los siguientes tipos de lotes:
- procedimientos almacenados
- Consultas enviadas mediante
sp_executesql - Consultas preparadas
Para obtener más información sobre cómo solucionar problemas de detección de parámetros, consulte:
- Investigación y resolución de problemas de sensibilidad de parámetros
- Parámetros y reutilización de un plan de ejecución
- Optimización de planes sensibles a parámetros
- Solución de problemas de las consultas en el plan de ejecución de consultas que distingue entre parámetros en Azure SQL Database
- Solución de problemas de consultas con problemas del plan de ejecución de consultas confidenciales de parámetros en Azure SQL Managed Instance
Cuando una consulta en SQL Server usa la sugerencia OPTION (RECOMPILE), el optimizador de consultas convierte los parámetros y las variables locales en constantes en tiempo de compilación que pueden plegarse como constantes y reducirse a literales. Esto significa que, durante la compilación, el optimizador sabe y puede usar los valores actuales en tiempo de ejecución de parámetros y variables locales, ya que existen inmediatamente antes de esa instrucción. Option (RECOMPILE) permite al optimizador generar un plan de consulta más óptimo adaptado a los valores específicos y aprovechar los mejores índices subyacentes en tiempo de ejecución. En el caso de los parámetros, este proceso hace referencia no a los valores pasados originalmente al procedimiento almacenado o por lotes, sino a sus valores en el momento de la recompilación. Es posible que estos valores se hayan modificado dentro del procedimiento antes de llegar a la instrucción que incluye RECOMPILE. Este comportamiento puede mejorar el rendimiento de las consultas con datos de entrada altamente variables o sesgados.
Variables locales
Cuando una consulta usa variables locales, SQL Server no puede examinar sus valores en tiempo de compilación, por lo que calcula la cardinalidad mediante estadísticas disponibles o heurística. Si existen estadísticas, normalmente usa el valor All Density (también conocido como densidad media) del histograma estadístico para calcular cuántas filas coinciden con el predicado. Sin embargo, si no hay estadísticas disponibles para la columna, SQL Server recurre a estimaciones heurísticas, como suponiendo 10% selectividad para predicados de igualdad y 30% para desigualdades y intervalos, lo que podría dar lugar a planes de ejecución menos precisos. Este es un ejemplo de una consulta que usa una variable local.
DECLARE @ProductId INT = 100;
SELECT * FROM Products WHERE ProductId = @ProductId;
En este caso, SQL Server no usa el valor 100 para optimizar la consulta. Usa una estimación general.
Procesamiento en paralelo de consultas
SQL Server proporciona consultas en paralelo para optimizar la ejecución de consultas y las operaciones con índices en equipos que disponen de más de un microprocesador (CPU). Debido a que SQL Server puede realizar una operación de índice o consulta en paralelo mediante varios subprocesos de trabajo del sistema operativo, la operación se puede completar de forma rápida y eficaz.
Durante la optimización de una consulta, SQL Server busca operaciones de consulta o índice que podrían beneficiarse de la ejecución en paralelo. Para estas consultas, SQL Server inserta operadores de intercambio en el plan de ejecución de consultas para preparar su ejecución en paralelo. Un operador de intercambio es un operador de un plan de ejecución de consultas que proporciona administración de procesos, redistribución de datos y control del flujo. El operador de intercambio incluye los operadores lógicos Distribute Streams, Repartition Streams y Gather Streams como subtipos; uno o más de estos pueden aparecer en la salida de Showplan de un plan de consulta en una consulta paralela.
Importante
Determinadas construcciones impiden la capacidad de SQL Server de usar el paralelismo en el plan de ejecución completo o en partes de este.
Entre las construcciones que impiden el paralelismo se incluyen las siguientes:
UDF escalares
Para obtener más información sobre las funciones escalares definidas por el usuario, vea Crear funciones definidas por el usuario. A partir de SQL Server 2019 (15.x), el Motor de base de datos de SQL Server tiene la capacidad de insertar estas funciones y desbloquear el uso del paralelismo durante el procesamiento de consultas. Para obtener más información sobre la inserción de UDF escalares, vea Procesamiento de consultas inteligente en bases de datos SQL.Consulta remota
Para obtener más información sobre Remote Query, vea Referencia de operadores lógicos y físicos del plan de presentación.Cursores dinámicos
Para obtener más información sobre los cursores, vea DECLARE CURSOR.Consultas recursivas
Para obtener más información sobre la recursión, vea Instrucciones para definir y usar expresiones de tabla comunes recursivas y Recursion in T-SQL (La recursión en T-SQL).Funciones con valores de tabla de múltiples instrucciones (MSTVF)
Para obtener más información sobre las MSTVF, vea Creación de funciones definidas por el usuario (motor de base de datos).Palabra clave TOP
Para obtener más información, vea TOP (Transact-SQL).
Un plan de ejecución de consultas puede contener el atributo NonParallelPlanReason en el elemento QueryPlan, que describe por qué no se usó el paralelismo. Los valores de este atributo incluyen:
| Valor NonParallelPlanReason | Descripción |
|---|---|
| MaxDOPSetToOne | El grado máximo de paralelismo está establecido en 1. |
| EstimatedDOPIsOne | El grado estimado de paralelismo es 1. |
| NoParallelWithRemoteQuery | El paralelismo no se admite para las consultas remotas. |
| NoParallelDynamicCursor | Los planes paralelos no se admiten para los cursores dinámicos. |
| NoParallelFastForwardCursor | Los planes paralelos no se admiten para los cursores de avance rápido. |
| NoParallelCursorFetchByBookmark | Los planes paralelos no se admiten para los cursores que capturan por marcador. |
| NoParallelCreateIndexInNonEnterpriseEdition | La creación de índices en paralelo no se admite para ediciones que no sean Enterprise. |
| NoParallelPlansInDesktopOrExpressEdition | Los planes paralelos no se admiten para Desktop y Express Edition. |
| NonParallelizableIntrinsicFunction | La consulta hace referencia a una función intrínseca que no se puede paralelizar. |
| FunciónDefinidaPorElUsuarioCLRRequiereAccesoADatos | El paralelismo no se admite para una UDF de CLR que requiere acceso a datos. |
| TSQLUserDefinedFunctionsNotParallelizable | La consulta hace referencia a una función definida por el usuario de T-SQL que no se podía paralelizar. |
| TableVariableTransactionsDoNotSupportParallelNestedTransaction | Las variables de tabla no admiten transacciones anidadas paralelas. |
| La consulta DML devuelve resultados al cliente | La consulta DML devuelve el resultado al cliente y no se puede paralelizar. |
| MixedSerialAndParallelOnlineIndexBuildNotSupported | La combinación de planes de serie y paralelos no se admite para una sola compilación de índice en línea. |
| CouldNotGenerateValidParallelPlan | Error al comprobar el plan paralelo; se realizará una conmutación por recuperación a la opción de serie. |
| NoParallelForMemoryOptimizedTables | El paralelismo no se admite para las tablas OLTP en memoria a las que se hace referencia. |
| NoParallelForDmlOnMemoryOptimizedTable | El paralelismo no se admite para DML en una tabla OLTP en memoria. |
| NoParallelForNativelyCompiledModule | El paralelismo no se admite para los módulos compilados de forma nativa a los que se hace referencia. |
| NoRangesResumableCreate | Error al generar intervalos para una operación de creación reanudable. |
Tras la inserción de operadores de intercambio, el resultado es un plan de ejecución de consultas en paralelo. Un plan de ejecución de consultas en paralelo puede usar más de un subproceso de trabajo. Un plan de ejecución en serie, usado por una consulta no paralela (en serie), solo usa un subproceso de trabajo para su ejecución. El número real de subprocesos de trabajo utilizados por una consulta en paralelo se determina durante la inicialización de la ejecución del plan de consulta y depende de la complejidad del plan y el grado de paralelismo.
El grado de paralelismo (DOP) determina el número máximo de CPU que se están usando; no significa el número de subprocesos de trabajo que se están usando. El límite de DOP se establece por tarea. No es un límite por solicitud ni por consulta. Esto significa que durante una ejecución de consultas en paralelo, una sola solicitud puede generar varias tareas que se asignan a un programador. Se pueden usar más procesadores que los especificados por MAXDOP de manera simultánea en un momento dado de la ejecución de la consulta, cuando se ejecutan varias tareas de forma simultánea. Para más información, consulte la guía de arquitectura de subprocesos y tareas.
El Optimizador de consultas de SQL Server no utiliza un plan de ejecución en paralelo para una consulta si se cumple alguna de las siguientes condiciones:
- El plan de ejecución en serie es trivial o no supera el umbral de coste para la configuración del paralelismo.
- El plan de ejecución en serie tiene un coste total estimado de subárbol menor al de cualquier plan de ejecución en paralelo explorado por el optimizador.
- La consulta contiene operadores escalares o relacionales que no se pueden ejecutar en paralelo. Es posible que algunos operadores hagan que una sección del plan de consulta se ejecute en modo de serie, o que todo el plan se ejecute en modo de serie.
Nota:
El coste total estimado de subárbol de un plan en paralelo puede ser menor que el umbral de coste de la configuración del paralelismo. Esto indica que el coste total estimado de subárbol del plan en serie lo superó y se eligió el plan de consulta con el menor coste total estimado de subárbol.
Grado de paralelismo (DOP)
SQL Server detecta de forma automática el mejor grado de paralelismo para cada instancia de una ejecución de consulta en paralelo o de una operación de índice del lenguaje de definición de datos (DDL). Para ello utiliza los siguientes criterios:
Si SQL Server se ejecuta en un equipo que dispone de más de un microprocesador o CPU, por ejemplo, un equipo de multiproceso simétrico (SMP). Solo los equipos con más de una CPU pueden utilizar consultas en paralelo.
Si hay suficientes subprocesos de trabajo disponibles. Cada operación de consulta o índice requiere que se ejecute un determinado número de subprocesos de trabajo. La ejecución de un plan en paralelo requiere más subprocesos de trabajo que un plan en serie, y el número de subprocesos de trabajo aumenta con el grado de paralelismo. Si no es posible cumplir el requisito de subprocesos de trabajo del plan en paralelo para un grado de paralelismo específico, el Motor de base de datos de SQL Server reduce automáticamente el grado de paralelismo o abandona por completo el plan en paralelo en el contexto de carga de trabajo especificado. Es entonces cuando ejecuta un plan en serie (un subproceso de trabajo).
El tipo de operación de consulta o índice ejecutado. Las operaciones de índice que crean o reconstruyen un índice, o que eliminan un índice agrupado y las consultas que utilizan intensamente los ciclos de la CPU son los candidatos idóneos para un plan de paralelismo. Por ejemplo, las combinaciones de tablas grandes, agregaciones importantes y la ordenación de grandes conjuntos de resultados son buenos candidatos. En las consultas simples, que suelen encontrarse en aplicaciones de procesamiento de transacciones, la coordinación adicional necesaria para ejecutar una consulta en paralelo es más importante que el aumento potencial del rendimiento. Para distinguir entre las consultas que se benefician del paralelismo y las que no, el Motor de base de datos de SQL Server compara el coste estimado de ejecutar la operación de índice o la consulta con el valor de umbral de coste para el paralelismo . Los usuarios pueden cambiar el valor predeterminado de 5 mediante sp_configure si unas pruebas correctas han detectado que otro valor es más adecuado para la carga de trabajo en ejecución.
Si hay un número suficiente de filas que se van a procesar. Si el Optimizador de consultas determina que el número de filas es demasiado bajo, no proporciona operadores de intercambio para distribuir las filas. Por lo tanto, los operadores se ejecutan en serie. Ejecutar los operadores en un plan en serie evita los escenarios en que los costos de arranque, distribución y coordinación exceden las ganancias logradas mediante la ejecución de operadores en paralelo.
Si las estadísticas de distribución actuales están disponibles. Si no es posible establecer el grado de paralelismo más alto, se tienen en cuenta los grados inferiores antes de abandonar el plan en paralelo. Por ejemplo, cuando sea crea un índice agrupado en una vista, las estadísticas de distribución no se pueden evaluar porque el índice agrupado aún no existe. En este caso, el Motor de base de datos de SQL Server no puede proporcionar el grado de paralelismo más alto para la operación de índice. Sin embargo, algunos operadores, como el ordenamiento y el escaneo, se siguen beneficiando de la ejecución en paralelo.
Nota:
Las operaciones de índices en paralelo están únicamente disponibles en las ediciones Enterprise, Developer y Evaluation de SQL Server.
En tiempo de ejecución, el Motor de base de datos de SQL Server determina si la carga de trabajo actual del sistema y la información de configuración descrita previamente permiten la ejecución en paralelo. Si se garantiza la ejecución en paralelo, el Motor de base de datos de SQL Server determina el número óptimo de subprocesos de trabajo y propaga la ejecución del plan en paralelo a dichos subprocesos. Cuando una operación de consulta o índice empieza a ejecutarse en varios subprocesos de trabajo para la ejecución en paralelo, se usa el mismo número de subprocesos hasta que la operación se completa. El Motor de base de datos de SQL Server vuelve a examinar el número óptimo de decisiones de subprocesos de trabajo cada vez que se recupera un plan de ejecución de la caché de planes. Por ejemplo, la ejecución de una consulta puede conllevar el uso de un plan en serie, una ejecución posterior de la misma consulta puede conllevar que un plan en paralelo use tres subprocesos de trabajo y una tercera ejecución puede conllevar que un plan en paralelo use cuatro subprocesos de trabajo.
Los operadores de actualización y eliminación de un plan de ejecución de consultas en paralelo se ejecutan en serie, pero la cláusula WHERE de una instrucción UPDATE o DELETE se puede ejecutar en paralelo. Los cambios reales de los datos se aplican en serie a la base de datos.
Hasta SQL Server 2012 (11.x), el operador Insert también se ejecuta en serie. Sin embargo, la parte SELECT de una instrucción INSERT se puede ejecutar en paralelo. Los cambios reales de los datos se aplican en serie a la base de datos.
A partir de SQL Server 2014 (12.x) y del nivel de compatibilidad de la base de datos 110, la instrucción SELECT ... INTO se puede ejecutar en paralelo. Otras formas de operadores de inserción funcionan de la misma manera que se ha descrito para SQL Server 2012 (11.x).
A partir de SQL Server 2016 (13.x) y del nivel de compatibilidad de la base de datos 130, la instrucción INSERT ... SELECT se puede ejecutar en paralelo al realizar la inserción en montones o en índices de almacén de columnas (CCI) agrupados y mediante la sugerencia TABLOCK. Las inserciones en las tablas temporales locales (identificadas por el prefijo #) y las tablas temporales globales (identificadas por prefijos ##) también se habilitan para el paralelismo mediante la sugerencia TABLOCK. Para obtener más información, vea INSERT (Transact-SQL).
Los cursores estáticos y los cursores impulsados por conjuntos clave pueden ser poblados mediante planes de ejecución en paralelo. Sin embargo, el comportamiento de los cursores dinámicos solo puede proporcionarse mediante la ejecución en serie. El optimizador de consultas siempre genera un plan de ejecución en serie para una consulta que es parte de un cursor dinámico.
Anulación de grados de paralelismo
El grado de paralelismo establece el número de procesadores que se van a utilizar en la ejecución de planes paralelos. Esta configuración se puede establecer en varios niveles:
En el nivel de servidor, mediante la opción de configuración de servidormáximo grado de paralelismo (MAXDOP).
Se aplica a: SQL ServerNota:
SQL Server 2019 (15.x) presenta recomendaciones automáticas para establecer la opción de configuración de servidor MAXDOP durante el proceso de instalación. La interfaz de usuario del programa de instalación permite aceptar la configuración recomendada o introducir su propio valor. Para obtener más información, vea la página Configuración del Motor de base de datos: MaxDOP.
Nivel de carga de trabajo, mediante la opción de configuración del grupo de cargas de trabajo MAX_DOPResource Governor.
Se aplica a: SQL ServerEn el nivel de base de datos, mediante la MAXDOPconfiguración de ámbito de base de datos.
Se aplica a: SQL Server y Azure SQL Database.Nivel de instrucción de consulta o índice, utilizando el indicador de consultaMAXDOP o la opción de índice MAXDOP. Por ejemplo, puede usar la opción MAXDOP para controlar, mediante el aumento o la reducción, el número de procesadores dedicados en una operación de índices en línea. De este modo es posible equilibrar los recursos utilizados por una operación de índice con los de usuarios simultáneos.
Se aplica a: SQL Server and Azure SQL Database
Al establecer la opción de grado máximo de paralelismo en 0 (valor predeterminado), SQL Server puede usar todos los procesadores disponibles, hasta un máximo de 64, en una ejecución de planes en paralelo. Aunque SQL Server establece un objetivo en runtime de 64 procesadores lógicos cuando la opción MAXDOP se establece en 0, si es necesario se puede configurar manualmente un valor diferente. Si se establece MAXDOP en 0 para consultas o índices, SQL Server puede utilizar todos los procesadores disponibles, hasta un máximo de 64, para las consultas o los índices especificados en una ejecución de planes en paralelo. MAXDOP no es un valor forzado para todas las consultas en paralelo, sino un objetivo provisional para todas las consultas aptas para el paralelismo. Esto significa que, si no hay suficientes subprocesos de trabajo disponibles en tiempo de ejecución, se puede ejecutar una consulta con un grado de paralelismo inferior al de la opción MAXDOP de configuración del servidor.
Sugerencia
Consulte las recomendaciones de MAXDOP para obtener instrucciones sobre cómo configurar MAXDOP en el nivel de servidor, base de datos, consulta o sugerencia.
Ejemplo de consulta en paralelo
La consulta siguiente cuenta el número de pedidos realizados en un determinado trimestre, a partir del 1 de abril de 2000, y en los cuales el cliente recibió al menos un elemento de la línea del pedido después de la fecha de confirmación. Esta consulta muestra el número de dichos pedidos agrupados por orden de prioridad y de manera ascendente.
Este ejemplo utiliza nombres teóricos de tabla y columna.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
Se supone que los índices siguientes están definidos en las tablas lineitem y orders:
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
Éste es un posible plan en paralelo generado para la consulta mostrada anteriormente:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
En la ilustración siguiente se muestra un plan de consultas ejecutado con un grado de paralelismo igual a 4 y que implica una combinación de dos tablas.
El plan paralelo contiene tres operadores de paralelismo. Tanto el operador Index Seek del índice o_datkey_ptr como el operador Index Scan del índice l_order_dates_idx se realizan en paralelo. Esto produce varios flujos exclusivos. Esto puede determinarse a partir de los operadores Parallelism más cercanos que están encima de los operadores Index Scan e Index Seek, respectivamente. Ambos están redistribuyendo el tipo de intercambio. Es decir, solo están reorganizando los datos entre los flujos y producen el mismo número de flujos a la salida que a la entrada. Este número de flujos equivale al grado de paralelismo.
El operador Parallelism situado encima del operador Index Scan l_order_dates_idx reparte sus flujos de entrada con el valor de L_ORDERKEY como clave. De este modo, los mismos valores de L_ORDERKEY finalizan en el mismo flujo de salida. Al mismo tiempo, los flujos de salida conservan el orden de la columna L_ORDERKEY para cumplir los requisitos de entrada del operador Merge Join.
El operador Parallelism situado encima del operador Index Seek reparte sus flujos de entrada con el valor de O_ORDERKEY. Como su entrada no está ordenada en los valores de la columna O_ORDERKEY y esta es la columna de combinación del operador Merge Join, el operador Sort que está entre los operadores Parallelism y Merge Join asegura que la entrada esté ordenada para el operador Merge Join en las columnas de combinación. El operador Sort, al igual que el operador Merge Join, se ejecuta en paralelo.
El operador de paralelismo más alto recopila los resultados de varios flujos en un solo flujo. Las agregaciones parciales que realiza el operador Stream Aggregate que está situado debajo del operador Parallelism se acumulan en un solo valor SUM para cada valor diferente de O_ORDERPRIORITY en el operador Stream Aggregate situado encima del operador Parallelism. Como este plan tiene dos segmentos de intercambio y un grado de paralelismo igual a 4, usa ocho subprocesos de trabajo.
Para más información sobre los operadores usados en este ejemplo, consulte Referencia de operadores lógicos y físicos del plan de presentación.
Operaciones de índice en paralelo
Los planes de consulta generados para las operaciones de índice que crean o regeneran un índice o quitan un índice agrupado permiten las operaciones en paralelo de varios subprocesos de trabajo en equipos con varios microprocesadores.
Nota:
Las operaciones de índice en paralelo solo están disponibles en Enterprise Edition a partir de SQL Server 2008 (10.0.x).
SQL Server utiliza los mismos algoritmos para determinar el grado de paralelismo (el número total de subprocesos de trabajo diferentes que se ejecutan) en las operaciones de índice que en otras consultas. El grado máximo de paralelismo en una operación de índice está sujeto a la opción de configuración del servidor grado máximo de paralelismo . Puede anular el valor del grado máximo de paralelismo para operaciones de índice individuales estableciendo la opción de índice MAXDOP en las instrucciones CREATE INDEX, ALTER INDEX, DROP INDEX y ALTER TABLE.
Cuando el Motor de base de datos de SQL Server crea un plan de ejecución de índice, el número de operaciones en paralelo se establece en el valor más bajo de los valores siguientes:
- El número de microprocesadores o CPU en el equipo.
- El número especificado en la opción de configuración del servidor "grado máximo de paralelismo".
- Número de CPU que aún no superan un umbral de trabajo realizado para subprocesos de trabajo de SQL Server.
Por ejemplo, en un equipo con ocho CPU, donde el grado máximo de paralelismo se ha definido en 6, no se generan más de seis subprocesos de trabajo en paralelo para una operación de índice. Si cinco de las CPU del equipo han excedido ya el umbral de trabajo de SQL Server cuando se crea un plan de ejecución de índice, el plan de ejecución especificará únicamente tres subprocesos de trabajo en paralelo.
Entre las fases principales de una operación de índice en paralelo se incluyen lo siguiente:
- Un subproceso de trabajo de coordinación recorre la tabla rápida y aleatoriamente para calcular la distribución de las claves de índice. El hilo de trabajo coordinador establece los límites de clave que crearán un número de rangos de clave que sean iguales al grado de operaciones en paralelo, donde se estima que cada rango de clave cubre un número similar de filas. Por ejemplo, si hay cuatro millones de filas en la tabla y el grado de paralelismo es 4, el subproceso de trabajo de coordinación determinará los valores de clave que delimitan cuatro conjuntos de filas con un millón de filas en cada uno. Si no se pueden establecer suficientes intervalos de clave para utilizar todas las CPU, el grado de paralelismo se reduce en consecuencia.
- El subproceso de trabajo de coordinación genera un número de subprocesos de trabajo igual al grado de operaciones en paralelo y espera hasta que estos subprocesos de trabajo finalicen su trabajo. Cada subproceso de trabajo recorre la tabla base mediante un filtro que recupera solo filas con valores de clave en el rango asignado al subproceso de trabajo. Cada subproceso de trabajo crea una estructura de índice para las filas en su rango con clave. En el caso de un índice con particiones, cada subproceso de trabajo genera un número especificado de particiones. Las particiones no se comparten entre los subprocesos de trabajo.
- Una vez que han terminado los hilos de trabajo en paralelo, el hilo de trabajo coordinador conecta las subunidades del índice en un único índice. Esta fase solo se aplica a operaciones de índice sin conexión.
Las instrucciones individuales CREATE TABLE o ALTER TABLE pueden tener varias restricciones que requieren la creación de un índice. Estas operaciones de creación de índice se llevan a cabo en serie, aunque cada operación de creación de índice puede ser una operación en paralelo en un equipo con varias CPU.
Arquitectura de consultas distribuidas
Microsoft SQL Server admite dos métodos para hacer referencia a orígenes de datos OLE DB heterogéneos en instrucciones Transact-SQL:
Nombres de servidores vinculados
Los procedimientos almacenados del sistemasp_addlinkedserverysp_addlinkedsrvloginse utilizan para dar un nombre de servidor a un origen de datos OLE DB. Se puede hacer referencia a los objetos de estos servidores vinculados en instrucciones Transact-SQL mediante nombres que consten de cuatro partes. Por ejemplo, si un nombre de servidor vinculado deDeptSQLSrvrse define en otra instancia de SQL Server, la instrucción siguiente hace referencia a una tabla de ese servidor:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;El nombre del servidor vinculado también puede especificarse en una instrucción
OPENQUERYpara abrir un conjunto de filas desde un origen de datos OLE DB. Se puede hacer referencia a este conjunto de filas del mismo modo que a una tabla en las instrucciones Transact-SQL.Nombres de conectores ad hoc
Para las referencias poco frecuentes a un origen de datos, las funcionesOPENROWSEToOPENDATASOURCEse especifican con la información necesaria para conectarse a un servidor vinculado. A continuación, se puede hacer referencia al conjunto de filas del mismo modo que se hace referencia a una tabla en instrucciones Transact-SQL:SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
SQL Server utiliza OLE DB para la comunicación entre el motor relacional y el motor de almacenamiento. El motor relacional divide cada instrucción Transact-SQL en un grupo de operaciones sobre conjuntos de filas OLE DB simples abiertos por el motor de almacenamiento desde las tablas base. Esto significa que el motor relacional también puede abrir conjuntos de filas OLE DB simples en cualquier origen de datos OLE DB.
El motor relacional utiliza la interfaz de programación de aplicaciones (API) OLE DB para abrir los conjuntos de filas en servidores vinculados, capturar las filas y administrar las transacciones.
Es necesario que haya un proveedor OLE DB en el servidor que ejecute SQL Server por cada origen de datos OLE DB al que se tenga acceso como servidor vinculado. El conjunto de operaciones Transact-SQL que puede utilizarse con un origen de datos OLE DB específico depende de las funcionalidades del proveedor OLE DB.
Para cada instancia de SQL Server, los miembros del rol fijo de servidor sysadmin pueden habilitar o deshabilitar el uso de nombres de conectores ad hoc para un proveedor OLE DB mediante la propiedad DisallowAdhocAccess de SQL Server. Al habilitar el acceso ad hoc, cualquier usuario que haya iniciado sesión en esa instancia puede ejecutar instrucciones Transact-SQL que contengan nombres de conectores ad hoc, haciendo referencia a cualquier origen de datos de la red al que se pueda obtener acceso mediante ese proveedor OLE DB. Para controlar el acceso a orígenes de datos, los miembros del rol sysadmin pueden deshabilitar el acceso ad hoc para ese proveedor OLE DB y, de esta forma, limitar a los usuarios solo a los orígenes de datos a los que se hace referencia mediante nombres de servidores vinculados definidos por los administradores. De forma predeterminada, el acceso ad hoc está habilitado para el proveedor OLE DB de SQL Server y deshabilitado para los demás proveedores OLE DB.
Las consultas distribuidas pueden permitir que los usuarios tengan acceso a otro origen de datos (por ejemplo, archivos, orígenes de datos no relacionales como Active Directory, etc.) mediante el contexto de seguridad de la cuenta de Microsoft Windows con la que se ejecuta el servicio SQL Server. SQL Server suplanta el inicio de sesión de forma apropiada para inicios de sesión de Windows; sin embargo, eso no es posible para inicios de sesión de SQL Server. Como consecuencia, puede ocurrir que un usuario de consultas distribuidas acceda a otro origen de datos para el que no tiene permisos, pero para el que la cuenta con la que el servicio SQL Server se está ejecutando sí los tiene. Utilice sp_addlinkedsrvlogin para definir los inicios de sesión específicos con acceso autorizado al servidor vinculado correspondiente. Este control no está disponible para nombres ad hoc; por tanto, tenga precaución a la hora de habilitar el proveedor OLE DB para el acceso ad hoc.
Cuando es posible, SQL Server inserta operaciones relacionales como combinaciones, restricciones, proyecciones, ordenaciones y operaciones "group by" al origen de datos OLE DB. SQL Server no analiza de forma predeterminada la tabla básica en SQL Server ni realiza las operaciones relacionales por sí mismo. SQL Server consulta el proveedor de OLE DB para determinar el nivel de gramática SQL que admite y, en función de esa información, inserta tantas operaciones relacionales como es posible en el proveedor.
SQL Server especifica un mecanismo para que un proveedor OLE DB devuelva estadísticas que indiquen cómo se distribuyen los valores de clave en el origen de datos OLE DB. Esto permite que el optimizador de consultas de SQL Server analice mejor el patrón de datos del origen de datos según los requisitos de cada instrucción Transact-SQL, lo que mejora su capacidad a la hora de generar planes de ejecución óptimos.
Mejoras de procesamiento de consultas en índices y tablas con particiones
En SQL Server 2008 (10.0.x), se mejoró el rendimiento del procesamiento de las consultas en tablas con particiones para muchos planes paralelos, se modificó la forma de representación de los planes en paralelo y en serie y se mejoró la información sobre la creación de particiones que los planes de ejecución en tiempo de compilación y en tiempo de ejecución proporcionan. En este artículo se describen estas mejoras y se proporcionan instrucciones sobre la interpretación de los planes de ejecución de consultas de índices y tablas con particiones, así como las prácticas recomendadas para mejorar el rendimiento de las consultas en objetos con particiones.
Nota:
Hasta SQL Server 2014 (12.x), los índices y tablas con particiones solo se admiten en las ediciones Enterprise, Developer y Evaluation de SQL Server. A partir de SQL Server 2016 (13.x) SP1, también se admiten los índices y tablas con particiones en SQL Server Standard Edition.
Nueva operación de búsqueda orientada a particiones
En SQL Server, se cambia la representación interna de una tabla con particiones para que la tabla parezca que es para el procesador de consultas un índice de varias columnas, siendo PartitionID la columna inicial.
PartitionID es una columna calculada oculta usada internamente para representar el valor de ID de la partición que contiene una fila específica. Por ejemplo, suponga que la tabla T, definida como T(a, b, c), tiene una partición en la columna a y un índice clúster en la columna b. En SQL Server, esta tabla con particiones se trata internamente como una tabla sin particiones con el esquema T(PartitionID, a, b, c) y un índice agrupado en la clave compuesta (PartitionID, b). De esta manera, el Optimizador de consultas puede realizar operaciones de búsqueda basadas en PartitionID sobre cualquier tabla o índice con particiones.
Ahora, la eliminación de particiones se lleva a cabo durante esta operación de búsqueda.
Además, el Optimizador de Consultas se amplía de modo que una operación de búsqueda o exploración con una condición pueda realizarse en PartitionID (como la columna inicial lógica) y posiblemente en otras columnas clave de índice, y luego realizar una búsqueda de segundo nivel con una condición diferente sobre una o más columnas adicionales, para cada valor distinto que cumpla con la condición de la operación de búsqueda de primer nivel. De esta manera, esta operación, denominada búsqueda selectiva, permite al optimizador de consultas realizar una operación de búsqueda o examen en función de una condición con el fin de determinar las particiones a las cuales se va a obtener acceso junto con una operación Index Seek de segundo nivel en el seno de ese operador, que devolverá las filas de las particiones que cumplan con una condición diferente. Por ejemplo, considere la siguiente consulta.
SELECT * FROM T WHERE a < 10 and b = 2;
En este ejemplo, suponga que la tabla T, definida como T(a, b, c), tiene una partición en la columna a y un índice clúster en la columna b. La siguiente función define los límites de la partición para la tabla T:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
Para llevar a cabo la consulta, el procesador de consultas realiza una operación de búsqueda de primer nivel para localizar todas las particiones que cumplan con la condición T.a < 10. Se identifican así las particiones a las cuales se va a tener acceso. A continuación, el procesador lleva a cabo en cada partición identificada una búsqueda de segundo nivel sobre el índice agrupado de la columna b con el fin de localizar las filas que cumplan con la condición T.b = 2 y T.a < 10.
La siguiente ilustración es una representación lógica de la operación de búsqueda selectiva. En ella se muestra la tabla T con datos en las columnas a y b. Las particiones están numeradas del 1 al 4; las líneas discontinuas representan los límites de las particiones. Una operación de búsqueda de primer nivel en el particionamiento (no representado en la ilustración) ha determinado que las particiones 1, 2 y 3 cumplen con la condición de búsqueda impuesta por el particionamiento definido para la tabla y con el predicado de la columna a. Es decir, T.a < 10. La línea curva representa el camino recorrido por la fase de búsqueda de segundo nivel de la operación de búsqueda selectiva. Básicamente, la operación de skip scan busca en cada una de estas particiones las filas que cumplan con la condición b = 2. El costo total de la operación de búsqueda selectiva es el mismo que el de tres búsquedas por índices independientes.
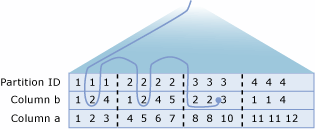
Visualización de la información de creación de particiones en los planes de ejecución de consultas
Los planes de ejecución de consultas en tablas e índices con particiones pueden examinarse utilizando las instrucciones SET de Transact-SQL SET SHOWPLAN_XML o SET STATISTICS XML, o mediante la salida gráfica del plan de ejecución en SQL Server Management Studio. Por ejemplo, para ver el plan de ejecución en tiempo de compilación, puede seleccionar Mostrar plan de ejecución estimado en la barra de herramientas del editor de consultas; para ver el plan en tiempo de ejecución, debe seleccionar Incluir plan de ejecución real.
Estas herramientas le proporcionarán la siguiente información:
- Las operaciones como
scans,seeks,inserts,updates,mergesydeletesque acceden a tablas o índices con particiones. - Las particiones a las que tiene acceso la consulta. Por ejemplo, el número total de particiones a las que se ha tenido acceso y los intervalos de particiones contiguas a los que se ha tenido acceso están disponibles en los planes de ejecución en tiempo de ejecución.
- Cuándo se utiliza la operación de búsqueda selectiva en una operación de búsqueda o de recorrido para recuperar datos de una o más particiones.
Mejoras de la información sobre particiones
SQL Server proporciona una mejor información acerca del particionamiento tanto para los planes de ejecución en tiempo de compilación como para los planes de ejecución en tiempo de ejecución. Los planes de ejecución proporcionan ahora la siguiente información:
- Un atributo
Partitionedopcional que indica que un operador, comoseek,scan,insert,update,mergeodelete, se ejecuta en una tabla con particiones. - Un nuevo elemento
SeekPredicateNewcon un subelementoSeekKeysque incluyePartitionIDcomo columna principal de clave de índice y condiciones de filtro que especifican búsquedas de rango enPartitionID. La presencia de dos subelementosSeekKeysindica que se utiliza una operación de escaneo por omisión enPartitionID. - Información de resumen que proporciona el número total de particiones a las que se ha tenido acceso. Esta información está disponible únicamente en planes de ejecución en tiempo real.
Para mostrar cómo aparece esta información tanto en la salida gráfica del plan de ejecución como en la salida XML de Showplan, considere la siguiente consulta sobre la tabla con particiones fact_sales. Esta consulta actualiza datos en dos particiones.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
En la siguiente ilustración, se muestran las propiedades del operador Clustered Index Seek en el plan de ejecución del entorno de ejecución para esta consulta. Para ver la definición de la tabla fact_sales y la definición de la partición, consulte "Ejemplo" en este artículo.

Atributo particionado
Cuando un operador como Index Seek se ejecuta en un índice o tabla con particiones, el atributo Partitioned aparece en los planes de tiempo de compilación y de ejecución y se establece en True (1). El atributo no se muestra cuando su valor es False (0).
El atributo Partitioned puede aparecer en los siguientes operadores físicos y lógicos:
- Examen de tablas
- Examen de índice
- Index Seek
- Insertar
- Actualizar
- Eliminar
- Fusionar
Como puede apreciarse en la ilustración previa, este atributo se muestra en las propiedades del operador en el que está definido. En la salida del Plan de presentación XML, este atributo aparece como Partitioned="1" en el nodo RelOp del operador en el que está definido.
Predicado de búsqueda nuevo
En la salida del Plan de presentación XML, el elemento SeekPredicateNew aparece en el operador en el que está definido. Puede contener hasta un máximo de dos apariciones del subelemento SeekKeys . El primer elemento SeekKeys especifica la operación de búsqueda de primer nivel a nivel de identificador de partición del índice lógico. Es decir, esta búsqueda determina las particiones a las que se debe tener acceso para satisfacer las condiciones de la consulta. El segundo elemento SeekKeys especifica la parte correspondiente a la búsqueda de segundo nivel de la operación de "skip scan" que tiene lugar en cada partición identificada en la búsqueda de primer nivel.
Información resumida de particiones
En los planes de ejecución en tiempo de ejecución, la información del resumen de particiones proporciona un recuento de las particiones a las que se ha accedido y la identidad de las particiones reales accedidas. Esta información puede utilizarse para comprobar que la consulta tiene acceso a las particiones correctas y que todas las demás particiones no se consideran.
Se proporciona la siguiente información: Actual Partition County Partitions Accessed.
Actual Partition Count es el número total de particiones a las que la consulta ha tenido acceso.
Partitions Accessed, en la salida del Plan de presentación XML, es la información de resumen de partición que aparece en el nuevo elemento RuntimePartitionSummary en el nodo RelOp del operador en el que está definido. El siguiente ejemplo muestra los contenidos del elemento RuntimePartitionSummary , que indica que se ha tenido acceso a un total de dos particiones (particiones 2 y 3).
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
Mostrar la información de particiones utilizando otros métodos de Showplan
Los métodos del plan de presentación SHOWPLAN_ALL, SHOWPLAN_TEXT y STATISTICS PROFILE no notifican la información de particiones que se describe en este artículo, con la siguiente excepción. Como parte del predicado SEEK , las particiones a las que se va a tener acceso están identificadas por un predicado de intervalo definido sobre la columna calculada que representa el identificador de la partición. En el ejemplo siguiente se muestra el predicado SEEK para un operador Clustered Index Seek . Se obtiene acceso a las particiones 2 y 3, y el operador de búsqueda filtra las filas que cumplen con la condición date_id BETWEEN 20080802 AND 20080902.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
Interpretación de planes de ejecución para montones con particiones
Un montón con particiones se trata como un índice lógico sobre el identificador de partición. La eliminación de una partición en un montón con particiones se representa en un plan de ejecución como un operador Table Scan con un predicado SEEK sobre el identificador de partición. El siguiente ejemplo muestra la información de Showplan proporcionada:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
Interpretación de planes de ejecución para combinaciones por colocación
La combinación colocada puede darse cuando dos tablas presentan particiones que usan funciones de partición iguales o equivalentes y las columnas de partición de ambos lados de la combinación se especifican en la condición de combinación de la consulta. El optimizador de consultas puede generar un plan en el que las particiones de cada tabla que tengan los mismos identificadores de partición se combinen de forma independiente. Las uniones colocadas pueden ser más rápidas que las uniones no colocadas, puesto que pueden requerir menos memoria y tiempo de procesamiento. El Optimizador de consultas elige un plan no colocado o colocado en función de las estimaciones de costos.
En un plan colocado, la combinación Nested Loops lee una o varias particiones de índice o tabla combinada de la parte interna. Los números en el interior de los operadores Constant Scan representan los números de partición.
Cuando se generan planes paralelos para combinaciones por colocación para índices o tablas con particiones, aparece un operador Parallelism entre los operadores de combinación Constant Scan y Nested Loops . En este caso, los distintos subprocesos de trabajo de la parte exterior de la combinación leen y trabajan en una partición diferente.
La siguiente ilustración muestra un plan de consulta paralela para una combinación por colocación.
Estrategia de ejecución de consultas en paralelo para objetos con particiones
El procesador de consultas utiliza una estrategia de ejecución paralela para consultas que seleccionan en objetos con particiones. Como parte de la estrategia de ejecución, el procesador de consultas determina las particiones de tabla requeridas para la consulta y la proporción de subprocesos de trabajo que se han de asignar a cada partición. En la mayoría de los casos, el procesador de consultas asigna a cada partición un número igual, o casi igual, de subprocesos de trabajo y, después, ejecuta la consulta en paralelo en las particiones. En los párrafos siguientes se explica la asignación de subprocesos de trabajo con más detalle.
Si el número de subprocesos de trabajo es menor que el número de particiones, el procesador de consultas asigna cada subproceso de trabajo a una partición diferente, pero deja inicialmente una o más particiones sin un subproceso de trabajo asignado. Cuando un subproceso de trabajo termina de ejecutarse en una partición, el procesador de consultas lo asigna a la partición siguiente hasta que cada partición tenga asignado un solo subproceso de trabajo. Este es el único caso en el que el procesador de consultas reasigna subprocesos de trabajo a otras particiones.
Muestra el subproceso de trabajo reasignado después de finalizar. Si el número de subprocesos de trabajo es igual al número de particiones, el procesador de consultas asigna un subproceso de trabajo a cada partición. Cuando un subproceso de trabajo finaliza, no se reasigna a otra partición.

Si el número de subprocesos de trabajo es mayor que el número de particiones, el procesador de consultas asigna un número igual de subprocesos de trabajo a cada partición. Si el número de subprocesos de trabajo no es un múltiplo exacto del número de particiones, el procesador de consultas asigna un subproceso de trabajo adicional a algunas particiones para que se usen todos los subprocesos de trabajo disponibles. Si solo hay una partición, todos los subprocesos de trabajo se asignarán a esa partición. En el diagrama siguiente hay cuatro particiones y 14 subprocesos de trabajo. Cada partición tiene asignados tres subprocesos de trabajo, y dos particiones tienen un subproceso de trabajo adicional, para un total de 14 asignaciones de subprocesos de trabajo. Cuando un subproceso de trabajo finaliza, no se reasigna a otra partición.

Aunque los ejemplos anteriores sugieren una manera sencilla de asignar subprocesos de trabajo, la estrategia real es más compleja y considera otras variables que se producen durante la ejecución de la consulta. Por ejemplo, si la tabla tiene particiones y un índice agrupado en la columna A, y una consulta tiene la cláusula de predicado WHERE A IN (13, 17, 25), el procesador de consultas asignará uno o más subprocesos de trabajo a cada uno de estos tres valores de búsqueda (A=13, A=17 y A=25) en lugar de a cada partición de tabla. Solo es necesario ejecutar la consulta en las particiones que contienen estos valores, y si se da la circunstancia de que todos estos predicados de búsqueda están en la misma partición de tabla, todos los subprocesos de trabajo se asignarán a la misma partición de tabla.
He aquí otro ejemplo: supongamos que la tabla tiene cuatro particiones en la columna A con puntos de límite (10, 20, 30), un índice en la columna B y la consulta tiene una cláusula de predicado WHERE B IN (50, 100, 150). Dado que las particiones de tabla se basan en los valores de A, los valores de B pueden producirse en cualquiera de las particiones de tabla. Por lo tanto, el procesador de consultas buscará cada uno de los tres valores de B (50, 100, 150) en cada una de las cuatro particiones de tabla. El procesador de consultas asignará subprocesos de trabajo proporcionalmente para poder ejecutar cada uno de estos 12 exámenes de consulta en paralelo.
| Particiones de tabla basadas en la columna A | Busca la columna B en cada partición de tabla |
|---|---|
| Partición de tabla 1: A < 10 | B=50, B=100, B=150 |
| Partición de tabla 2: A >= 10 Y A < 20 | B=50, B=100, B=150 |
| Partición de tabla 3: A >= 20 AND A < 30 | B=50, B=100, B=150 |
| Partición de tabla 4: A >= 30 | B=50, B=100, B=150 |
procedimientos recomendados
Para mejorar el rendimiento de las consultas que tienen acceso a una cantidad grande de datos de tablas e índices grandes con particiones, recomendamos las siguientes prácticas:
- Distribuya cada partición entre varios discos. Ello resulta especialmente importante al utilizar discos giratorios.
- Cuando sea posible, utilice un servidor con memoria principal suficiente para alojar en ella las particiones con una mayor frecuencia de acceso, o todas las particiones, con el fin de reducir el coste de la E/S.
- Si no es posible alojar en memoria los datos que está consultando, comprima las tablas e índices. De esta manera se reducirá el costo de la E/S.
- Utilice un servidor con procesadores rápidos y tantos núcleos de procesador como pueda permitirse, con el fin de sacar partido de la capacidad de procesamiento de las consultas en paralelo.
- Asegúrese de que el servidor dispone de un ancho banda de controlador de E/S suficiente.
- Cree un índice agrupado en cada tabla grande con particiones para aprovechar las optimizaciones de escaneo de B-tree.
- Siga las recomendaciones de mejores prácticas en el documento técnico, The Data Loading Performance Guide, cuando cargue grandes volúmenes de datos en tablas con particiones.
Ejemplo
El ejemplo siguiente crea una base de datos de prueba que contiene una única tabla con siete particiones. Utilice las herramientas descritas previamente al ejecutar las consultas de este ejemplo para ver la información del particionamiento para los planes de tiempo de compilación y los de tiempo de ejecución.
Nota:
Este ejemplo inserta más de 1 millón de filas en la tabla. En función de su hardware, la ejecución de este ejemplo puede tomar varios minutos. Antes de ejecutar este ejemplo, compruebe que tiene más de 1,5 GB de espacio en disco disponible.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
Contenido relacionado
- Referencia de operador de plan de presentación lógico y físico
- Información general sobre Extended Events
- Procedimientos recomendados para supervisar cargas de trabajo con Almacén de consultas
- Estimación de cardinalidad (SQL Server)
- Procesamiento de consultas inteligente en bases de datos SQL
- Prioridad de operador (Transact-SQL)
- Información general sobre el plan de ejecución
- Centro de rendimiento para el motor de base de datos SQL Server y Azure SQL Database