Guía de arquitectura y administración de registros de transacciones de SQL Server
Se aplica a: ![]() SQL Server
SQL Server ![]() Azure SQL Database
Azure SQL Database ![]() Azure SQL Managed Instance
Azure SQL Managed Instance ![]() Azure Synapse Analytics
Azure Synapse Analytics ![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)
Todas las bases de datos de SQL Server tienen un registro de transacciones que registra todas las transacciones y las modificaciones que hace cada transacción en la base de datos. El registro de transacciones es un componente esencial de la base de datos y, si se produce un error del sistema, podría ser necesario para volver a poner la base de datos en un estado coherente. Esta guía proporciona información acerca de la arquitectura física y lógica del registro de transacciones. Comprender la arquitectura puede mejorar la eficacia en la administración de registros de transacciones.
Arquitectura lógica del registro de transacciones
El registro de transacciones de SQL Server funciona desde el punto de vista lógico como si fuese una cadena de entradas de registro. Cada entrada del registro está identificada por un número de secuencia de registro (LSN, Log Sequence Number). Las nuevas entradas del registro se escriben al final lógico del registro con un LSN mayor que el de las entradas anteriores. Las entradas de registro se almacenan en una secuencia de serie a medida que se crean, de manera que si LSN2 es mayor que LSN1, el cambio descrito por la entrada de registro a la que hace referencia LSN2 se produce después del cambio descrito por la entrada de registro LSN1. Cada entrada del registro contiene el Id. de la transacción a la que pertenece. Por cada transacción, las entradas del registro asociadas a dicha transacción se vinculan individualmente en una cadena con punteros hacia atrás, para acelerar así la reversión de la transacción.
La estructura básica de un LSN es [VLF ID:Log Block ID:Log Record ID]. Para más información, consulte las secciones VLF y bloque de registro.
Este es un ejemplo de un LSN: 00000031:00000da0:0001, donde 0x31 es el identificador del VLF, 0xda0 es el identificador del bloque de registro y 0x1 es el primer registro de ese bloque de registro. Para ver ejemplos de LSN, examine la salida de DMV sys.dm_db_log_info y examine la columna vlf_create_lsn.
Los registros de modificaciones de datos registran la operación lógica llevada a cabo o las imágenes anterior y posterior de los datos modificados. La imagen anterior es una copia de los datos antes de llevar a cabo la operación; la imagen posterior es una copia de los datos después de haber realizado la operación.
Los pasos para recuperar una operación dependen del tipo de registro:
Registro de la operación lógica
- Para poner al día la operación lógica, se vuelve a ejecutar la operación.
- Para revertir la operación lógica, se ejecuta la operación lógica inversa.
Registro de las imágenes anterior y posterior
- Para poner al día la operación, se aplica la imagen posterior.
- Para revertir la operación, se aplica la imagen anterior.
En el registro de transacciones se registran muchos tipos de operaciones. Entre las operaciones se incluyen:
El inicio y el final de cada transacción.
Todas las modificaciones de los datos (inserción, actualización y eliminación). Las modificaciones de las tablas contienen, incluidas las tablas del sistema, hechas por procedimientos almacenados del sistema o por instrucciones del lenguaje de definición de datos (DDL).
Las asignaciones o cancelaciones de asignación de páginas y extensiones.
La creación o eliminación de una tabla o un índice.
También se registran las operaciones de reversión. Cada transacción reserva espacio en el registro de transacciones para asegurarse de que existe suficiente espacio de registro para admitir una reversión provocada por una instrucción de reversión explícita o cuando se produce un error. La cantidad de espacio reservado depende de las operaciones realizadas en la transacción, pero normalmente equivale a la cantidad de espacio empleado para registrar cada operación. Este espacio reservado se libera cuando se completa la transacción.
La sección del archivo de registro a partir de la primera entrada de registro que debe estar presente para una reversión correcta en toda la base de datos hasta la última entrada de registro escrita se denomina parte activa del registro, registro activo o final del registro. Esta es la sección del registro necesaria para una recuperación completa de la base de datos. No se puede truncar ninguna parte del registro activo. El número de secuencia de registro (LSN) de este primer registro se denomina el LSN de recuperación mínimo (MinLSN). Para más información sobre las operaciones admitidas por el registro de transacciones, vea El registro de transacciones.
Las copias de seguridad diferenciales y del registro posponen la base de datos restaurada a un momento posterior, correspondiente a un LSN superior.
Arquitectura física del registro de transacciones
El registro de transacciones de la base de datos está asignado a uno o varios archivos físicos. Conceptualmente, el archivo de registro es una cadena de entradas de registro. Físicamente, la secuencia de entradas del registro se almacena de forma eficaz en el conjunto de archivos físicos que implementa el registro de transacciones. Cada base de datos debe tener al menos un archivo de registro.
Archivos de registro virtuales (VLF)
El motor de base de datos de SQL Server segmenta cada archivo de registro físico internamente en varios archivos de registro virtuales (VLF). Los archivos de registro virtuales no tienen un tamaño fijo y no hay un número fijo de archivos de registro virtuales para un archivo de registro físico. El motor de base de datos elige dinámicamente el tamaño de los archivos de registro virtuales al crear o ampliar los archivos de registro. El motor de base de datos intenta mantener algunos archivos virtuales. El tamaño de los archivos virtuales después de ampliar un archivo de registro equivale a la suma del tamaño del registro existente y el tamaño del nuevo incremento del archivo. El tamaño o número de archivos de registro virtuales no lo pueden configurar ni establecer los administradores.
Creación de archivos de registro virtual
La creación de archivos de registro virtual (VLF) sigue este método:
- En SQL Server 2014 (12.x) y versiones posteriores, si el siguiente crecimiento es inferior a 1/8 del tamaño físico actual del registro, cree 1 VLF que cubra el tamaño del crecimiento.
- Si el siguiente crecimiento es superior a 1/8 del tamaño actual del registro, use el método para versiones anteriores a 2014, concretamente:
- Si el crecimiento es inferior a 64 MB, cree 4 VLF que cubran el tamaño del crecimiento (p. ej., en el caso de un crecimiento de 1 MB, cree 4 VLF de 256 KB).
- En Azure SQL Database y a partir de SQL Server 2022 (16.x) (todas las ediciones), la lógica es ligeramente diferente. Si el crecimiento es menor o igual que 64 MB, el motor de base de datos crea solo un VLF para cubrir el tamaño de crecimiento.
- Si el crecimiento está entre 64 MB y 1 GB, cree 8 VLF que cubran el tamaño del crecimiento (p. ej., en el caso de un crecimiento de 512 MB, cree 8 VLF de 64 KB).
- Si el crecimiento es superior a 1 GB, cree 16 VLF que cubran el tamaño del crecimiento (p. ej., en el caso de un crecimiento de 8 GB, cree 16 VLF de 512 MB).
- Si el crecimiento es inferior a 64 MB, cree 4 VLF que cubran el tamaño del crecimiento (p. ej., en el caso de un crecimiento de 1 MB, cree 4 VLF de 256 KB).
Si los archivos de registro crecen hasta un tamaño grande en muchos incrementos pequeños, acabará teniendo numerosos archivos de registro virtuales. Esto puede ralentizar el inicio de la base de datos, las operaciones de copia de seguridad y restauración de registros, y provocar la replicación transaccional/CDC y la latencia de la puesta al día siempre activa. Por el contrario, si los archivos de registro están establecidos en un tamaño grande con pocos o solo un incremento, contienen muy pocos archivos de registro virtuales muy grandes. Para obtener más información sobre la estimación correcta de la configuración de tamaño requerido y crecimiento automático de un registro de transacción, vea la sección Recomendaciones de Administrar el tamaño del archivo de registro de transacciones.
Se recomienda que cree sus archivos de registro con un tamaño parecido al tamaño final necesario, con los incrementos para conseguir la distribución de VLF óptima, y que tengan un valor de growth_increment relativamente alto.
Vea las recomendaciones siguientes para determinar la distribución de VLF óptima para el tamaño del registro de transacciones actual:
- El valor size, establecido por el argumento
SIZEdeALTER DATABASE, es el tamaño inicial del archivo de registro. - El valor growth_increment (también conocido como el valor de crecimiento automático), establecido por el argumento
FILEGROWTHdeALTER DATABASE, es la cantidad de espacio que se agrega al archivo cada vez que se necesita más espacio.
Para obtener más información sobre los argumentos FILEGROWTH y SIZE de ALTER DATABASE, vea Opciones File y Filegroup de ALTER DATABASE (Transact-SQL).
Sugerencia
Para determinar la distribución óptima de VLF para el tamaño de registro de transacciones actual de todas las bases de datos en una instancia determinada, así como los incrementos de tamaño necesarios para conseguir el tamaño requerido, consulte este script Fixing-VLF en GitHub.
¿Qué ocurre cuando tiene demasiados VLF?
Durante las fases iniciales de un proceso de recuperación de base de datos, SQL Server detecta todas las VFS en todos los archivos de registro de transacciones y crea una lista de estas VFS. Este proceso puede tardar mucho tiempo en función del número de VLF presentes en la base de datos específica. Cuantos más VLF, más tiempo será el proceso. Una base de datos puede acabar teniendo un gran número de VFS si se detecta un crecimiento automático frecuente del registro de transacciones o un crecimiento manual en pequeños incrementos. Cuando el número de VLF alcanza el intervalo de varios cientos de miles, puede encontrar algunos o la mayoría de los síntomas siguientes:
- Una o varias bases de datos tardan mucho tiempo en finalizar la recuperación durante el inicio de SQL Server.
- La restauración de una base de datos tarda mucho tiempo en completarse.
- Los intentos de adjuntar una base de datos tardan mucho tiempo en completarse.
- Al intentar configurar la creación de reflejo de la base de datos, se producen mensajes de error 1413, 1443 y 1479, que indican un tiempo de espera.
- Se producen errores relacionados con la memoria como el 701 al intentar restaurar una base de datos.
- Es posible que la replicación transaccional o la captura de datos modificados experimenten una latencia significativa.
Al examinar el registro de errores de SQL Server, es posible que vea que se dedica una cantidad significativa de tiempo antes de la fase de análisis del proceso de recuperación de la base de datos. Por ejemplo:
2022-05-08 14:42:38.65 spid22s Starting up database 'lot_of_vlfs'.
2022-05-08 14:46:04.76 spid22s Analysis of database 'lot_of_vlfs' (16) is 0% complete (approximately 0 seconds remain). Phase 1 of 3. This is an informational message only. No user action is required.
Además, SQL Server puede registrar un error MSSQLSERVER_9017 al restaurar una base de datos que tenga un gran número de VLF:
Database %ls has more than %d virtual log files which is excessive. Too many virtual log files can cause long startup and backup times. Consider shrinking the log and using a different growth increment to reduce the number of virtual log files.
Para obtener más información, consulte MSSQLSERVER_9017.
Corrección de bases de datos con un gran número de VLF
Para mantener el número total de VLF en una cantidad razonable, como un máximo de varios miles, puede restablecer el archivo de registro de transacciones para que contenga un número menor de VLF realizando los pasos siguientes:
Reduzca manualmente los archivos de registro de transacciones.
Aumente manualmente los archivos al tamaño necesario en un paso mediante el siguiente script de T-SQL:
ALTER DATABASE <database name> MODIFY FILE (NAME='Logical file name of transaction log', SIZE = <required size>);Nota:
Este paso también es posible en SQL Server Management Studio mediante la página de propiedades de la base de datos.
Después de establecer el nuevo diseño del archivo de registro de transacciones con menos VLF, revise y realice los cambios necesarios en la configuración de crecimiento automático del registro de transacciones. Esta validación de configuración garantiza que el archivo de registro evite encontrar el mismo problema en el futuro.
Antes de realizar cualquiera de estas operaciones, asegúrese de que tiene una copia de seguridad restaurable válida en caso de que encuentre problemas más adelante.
Para determinar la distribución óptima de VLF para el tamaño de registro de transacciones actual de todas las bases de datos en una instancia determinada, así como los incrementos de tamaño necesarios para conseguir el tamaño requerido, use el script de GitHub siguiente para corregir VLF.
Bloqueos de cierre
Cada VLF contiene uno o varios bloques de registro. Cada bloque de registro consta de los registros (alineados en un límite de 4 bytes). Un bloque de registro es variable de tamaño y siempre es un entero múltiplo de 512 bytes (el tamaño mínimo de sector que admite SQL Server), con un tamaño máximo de 60 KB. Un bloque de registro es la unidad básica de E/S para el registro de transacciones.
En resumen, un bloque de registro es un contenedor de registros que se usa como unidad básica de registro de transacciones al escribir registros de registro en disco.
Cada bloque de registro dentro de un VLF se aborda de forma única mediante su desplazamiento de bloque. El primer bloque siempre tiene un desplazamiento de bloque mayor a los primeros 8 KB del VLF.
En general, un VLF siempre se rellena con bloques de registro. Es posible que el último bloque de registro de un VLF esté vacío (por ejemplo, no contiene ningún registro). Esto sucede cuando un registro que se va a escribir no cabe en el bloque de registro actual y también cuando el espacio que queda en el VLF no es suficiente para contener este registro de registro. En este caso, se crea un bloque de registro vacío que rellena el VLF. El registro de registro se inserta en el primer bloque del siguiente VLF.
Naturaleza circular del registro de transacciones
El registro de transacciones es un archivo de registro circular. Considere, por ejemplo, una base de datos con un archivo de registro físico dividido en cuatro VLF. Cuando se crea la base de datos, el archivo de registro lógico empieza en el principio del archivo de registro físico. Las nuevas entradas del registro se agregan al final del registro lógico y se expanden hacia el final del archivo físico. El truncamiento del registro libera los registros virtuales cuyas entradas son anteriores al número de flujo de registro de recuperación mínimo (MinLSN). MinLSN es el número de flujo de registro de la entrada del registro más antigua necesaria para una reversión correcta de toda la base de datos. El registro de transacciones del ejemplo de la base de datos sería similar al del diagrama siguiente.
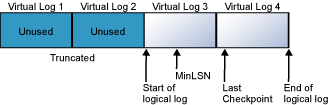
Cuando el final del registro lógico llega al final del archivo de registro físico, las nuevas entradas del registro se escriben al principio del archivo de registro físico.
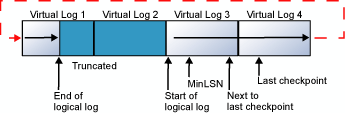
El ciclo se repite indefinidamente, siempre que el final del registro lógico no alcance el inicio del registro lógico. Si las entradas antiguas se truncan con la frecuencia suficiente para disponer siempre de espacio para todas las nuevas entradas de registro que se van a crear hasta el próximo punto de comprobación, el registro no se llena nunca. Sin embargo, si el final del registro lógico llega al principio del registro lógico, se produce una de estas dos situaciones:
Si el registro tiene habilitada la opción
FILEGROWTHy hay espacio disponible en el disco, el archivo se amplía en la cantidad especificada en el parámetro growth_increment y las nuevas entradas del registro se escriben en la extensión. Para más información sobre el valorFILEGROWTH, vea Opciones File y Filegroup de ALTER DATABASE (Transact-SQL).Si la opción
FILEGROWTHno está habilitada o el disco que almacena el archivo de registro tiene menos espacio disponible que la cantidad especificada en growth_increment, se genera el error 9002. Para más información, vea Solución de problemas de un registro de transacciones lleno (error 9002 de SQL Server).
Si el registro contiene varios archivos de registro físicos, el registro lógico pasa por todos los archivos de registro físicos antes de volver a empezar por el principio del primer archivo de registro físico.
Importante
Para más información sobre la administración de tamaño del registro de transacciones, vea Administración del tamaño del archivo de registro de transacciones.
Truncamiento del registro
El truncamiento del registro es esencial para evitar que se llene. El truncamiento del registro elimina los archivos de registro virtuales inactivos del registro de transacciones lógico de una base de datos de SQL Server, liberando espacio en el registro lógico para que lo reutilice el registro de transacciones físico. Si un registro de transacciones no se trunca nunca, acabará ocupando todo el espacio de disco que se asigna a los archivos de registro físicos. Sin embargo, para que se pueda truncar el registro, se debe realizar primero una operación de punto de comprobación. Un punto de comprobación escribe en el disco las páginas modificadas en memoria actuales (denominadas páginas desfasadas) y la información del registro de transacciones de la memoria. Cuando se lleva a cabo el punto de comprobación, la parte inactiva del registro de transacciones se marca como reutilizable. A partir de ese momento, se puede liberar la parte inactiva mediante el truncamiento del registro. Para más información sobre los puntos de comprobación, vea Puntos de comprobación de base de datos (SQL Server).
En los diagramas siguientes se muestra un registro de transacciones antes y después del truncamiento. En el primer diagrama se muestra un registro de transacciones que no se ha truncado nunca. El registro lógico tiene actualmente cuatro archivos de registro virtuales en uso. El registro lógico comienza al principio del primer archivo de registro virtual y finaliza en el registro virtual 4. El registro de MinLSN está en el registro virtual 3. Los registros virtuales 1 y 2 solo contienen entradas de registro inactivas. Estas entradas pueden truncarse. El registro virtual 5 no se utiliza aún y no forma parte del registro lógico actual.
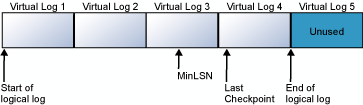
En el segundo diagrama se muestra el aspecto del registro después del truncamiento. Se han liberado los registros virtuales 1 y 2 para su reutilización. El registro lógico comienza ahora al principio del registro virtual 3. El registro virtual 5 no se utiliza aún y no forma parte del registro lógico actual.
El truncamiento del registro se produce automáticamente después de los eventos siguientes, excepto cuando se retrasa por alguna razón:
- En el modelo de recuperación simple, después de un punto de comprobación.
- Bajo el modelo de recuperación completa o el modelo de recuperación optimizado para cargas masivas de registros, después de una copia de seguridad del registro, si un punto de comprobación ha producirse desde la copia de seguridad anterior.
El truncamiento del registro se puede retrasar por varias factores. En caso de un retraso largo en el truncamiento del registro, el registro de transacciones se puede llenar. Para obtener información, vea Factores que pueden ralentizar el truncamiento del registro y Solución de problemas de un registro de transacciones lleno (Error 9002 de SQL Server).
Registro de transacciones de escritura anticipada
En esta sección se describe el rol que desempeña el registro de transacciones de escritura anticipada en la grabación de modificaciones de datos en disco. SQL Server usa un algoritmo de registro de escritura previa (WAL), lo cual garantiza que no se escriba ninguna modificación de datos en el disco antes de escribir en él la entrada de registro asociada. Así se mantienen las propiedades ACID para una transacción.
Para más información sobre WAL, vea Aspectos fundamentales de E/S de SQL Server.
Para entender cómo funciona el registro de escritura previa en relación con el registro de transacciones, es importante saber cómo se escriben los datos modificados en el disco. SQL Server mantiene una caché del búfer (también conocido como grupo de búferes)que lee las páginas de datos cuando estos deben recuperarse. Cuando se modifica una página en la caché del búfer, no se vuelve a escribir inmediatamente en el disco; en su lugar, la página se marca como desfasada. Una página de datos puede tener más de una escritura lógica antes de que se escriba físicamente en el disco. Para cada escritura lógica, se inserta una entrada del registro de transacciones en la caché del registro que registra la modificación. Las entradas del registro se tienen que escribir en el disco antes de que la página desfasada asociada se quite de la caché del búfer y se escriba en el disco. El proceso de punto de comprobación examina periódicamente la caché del búfer en busca de búferes con páginas de una base de datos especificada y escribe todas las páginas desfasadas en el disco. Los puntos de comprobación permiten ahorrar tiempo en una recuperación posterior al crear un punto en el que se garantiza que todas las páginas desfasadas se hayan escrito en el disco.
A la escritura en el disco de una página de datos modificada desde la caché del búfer se le llama vaciar la página. SQL Server tiene una lógica que evita que una página desfasada se vacíe antes de que se escriba la entrada del registro asociada. Las entradas de registro se escriben en el disco cuando se vacían los búferes de registro. Esto ocurre siempre que se confirma una transacción o se llenan los búferes de registro.
Copias de seguridad de registros de transacciones
En esta sección se presentan conceptos acerca de cómo realizar copias de seguridad y restaurar (aplicar) registros de transacciones. En los modelos de recuperación completa y de recuperación optimizada para cargas masivas de registros, es necesario realizar copias de seguridad periódicas de los registros de transacciones (copias de seguridad de registros) para recuperar datos. Puede realizar una copia de seguridad del registro mientras se está ejecutando cualquier copia de seguridad completa. Para obtener más información sobre modelos de recuperación, consulte Realizar copias de seguridad y restaurar bases de datos de SQL Server.
Antes de crear la primera copia de seguridad de registros, debe crear una copia de seguridad completa, como una copia de seguridad de la base de datos o la primera de un conjunto completo de copias de seguridad de archivos. La restauración de una base de datos utilizando únicamente copias de seguridad de archivos puede llegar a ser un proceso complejo. Por lo tanto, es recomendable que comience con una copia de seguridad de la base de datos completa si es posible. Posteriormente, será necesario realizar copias de seguridad del registro de transacciones con regularidad. De esta forma, no solo se minimiza el riesgo de pérdida de trabajo, sino que también se permite el truncamiento del registro de transacciones. Normalmente, el registro de transacciones se trunca tras cada copia de seguridad de registros convencional.
Importante
Es aconsejable realizar copias de seguridad de registros suficientemente regulares para ajustarse a los requisitos de su empresa, específicamente a la tolerancia a la pérdida de trabajo que un almacenamiento de registro dañada podría provocar.
La frecuencia adecuada para realizar copias de seguridad de registros varía en función de la tolerancia al riesgo de pérdida de trabajo y, por otra parte, de la cantidad de copias de seguridad de registros que puede almacenar, administrar y, potencialmente, restaurar. Tenga en cuenta los objetivos de tiempo de recuperación (RTO) y los objetivos de punto de recuperación (RPO) necesarios al implementar la estrategia de recuperación, específicamente el ritmo de realización de copias de seguridad de registros. Una copia de seguridad de registros cada 15 ó 30 minutos puede ser suficiente. Si su empresa necesita minimizar el riesgo de pérdida de trabajo, piense en la posibilidad de realizar copias de seguridad de registros más frecuentemente. La existencia de copias de seguridad más frecuentes de los registros tiene la ventaja añadida de aumentar la frecuencia de truncamiento del registro, lo que genera archivos de registro menores.
Para limitar el número de copias de seguridad del registro que necesita restaurar, es esencial que realice una copia de seguridad de sus datos periódicamente. Por ejemplo, podría programar una copia de seguridad completa de la base de datos cada semana y copias de seguridad diferenciales de la base de datos a diario.
Tenga en cuenta los RTO y RPO necesarios al implementar la estrategia de recuperación, específicamente el ritmo de realización de copias de seguridad de base de datos completas y diferenciales.
Para más información sobre las copias de seguridad del registro de transacciones, vea Copias de seguridad del registro de transacciones (SQL Server);.
La cadena de registros
Una secuencia continua de copias de seguridad de registros se denomina cadena de registros. Una cadena de registros empieza con una copia de seguridad completa de la base de datos. Normalmente, una cadena de registro nueva solo empieza cuando se realiza la primera copia de seguridad de la base de datos o después de que se cambie del modelo de recuperación simple al modelo de recuperación completa o al modelo de recuperación optimizado para cargas masivas de registros. A menos que se elija sobrescribir los conjuntos de copia de seguridad existentes al crear una copia de seguridad completa de la base de datos, la cadena de registros existente permanece intacta. Con la cadena de registros intacta, se puede restaurar la base de datos a partir de cualquier copia de seguridad completa de la base de datos del conjunto de medios, seguida de todas las copias de seguridad de los registros subsiguientes hasta el punto de recuperación. El punto de recuperación puede ser el final de la última copia de seguridad de registros o un punto de recuperación concreto de cualquiera de las copias de seguridad de registros. Para más información, vea Copias de seguridad del registro de transacciones (SQL Server).
Para restaurar una base de datos al momento del error, es preciso que la cadena de registros esté intacta. De esta forma, es necesario que una secuencia ininterrumpida de las copias de seguridad del registro de transacciones se extienda hasta el momento del error. El lugar en el que esta secuencia de registros debe comenzar depende del tipo de copias de seguridad de datos que esté restaurando: de base de datos, parcial o de archivos. En las copias de seguridad de base de datos o parciales, la secuencia de copias de seguridad de registros debe extenderse desde el final de la copia de seguridad de base de datos o parcial. En un conjunto de copia de seguridad de archivos, la secuencia de copias de seguridad de registros debe comenzar desde el principio del conjunto completo de copias de seguridad de archivos. Para obtener más información, vea Aplicar copias de seguridad del registro de transacciones (SQL Server).
Restaurar copias de seguridad de registros
Al restaurar una copia de seguridad de registros se ponen al día los cambios que se registraron en el registro de transacciones para volver a crear el estado exacto de la base de datos en el momento en que se inició la operación de copia de seguridad de registros. Al restaurar una base de datos, será necesario restaurar las copias de seguridad de registros creadas tras la copia de seguridad de la base de datos completa que esté restaurando o al principio de la primera copia de seguridad de archivos que esté restaurando. Normalmente, se debe restaurar una serie de copias de seguridad de registros hasta llegar al punto de recuperación después de haber restaurado la copia de seguridad de los datos o la copia de seguridad diferencial más recientes. A continuación, se realiza la recuperación de la base de datos. De esta manera, todas las transacciones que estaban incompletas cuando comenzó la recuperación se revertirán y la base de datos se conectará. Una vez recuperada la base de datos, ya no es posible restaurar más copias de seguridad. Para obtener más información, vea Aplicar copias de seguridad del registro de transacciones (SQL Server).
Puntos de comprobación y la parte activa del registro
Los puntos de comprobación vacían las páginas de datos desfasadas en la memoria caché del búfer de la base de datos actual en el disco. De este modo, se minimiza la parte activa del registro que se debe procesar durante una recuperación completa de una base de datos. Durante una recuperación completa, se llevan a cabo los siguientes tipos de acciones:
- Se ponen al día los registros de modificaciones que no se vaciaron en el disco antes de detenerse el sistema.
- Se revierten todas las modificaciones asociadas a transacciones incompletas, como las transacciones para las que no hay entradas COMMIT o ROLLBACK en el registro.
Funcionamiento de los puntos de comprobación
Un punto de comprobación realiza los procesos siguientes en la base de datos:
Escribe en el archivo de registro una entrada que marca el inicio del punto de comprobación.
Guarda información registrada para el punto de comprobación en una cadena de entradas de registro de puntos de comprobación.
Una parte de la información registrada en el punto de comprobación es el número de flujo de registro (LSN) de la primera entrada del registro que debe estar presente para una reversión correcta de toda la base de datos. Este LSN se denomina LSN de recuperación mínimo (MinLSN). El MinLSN es el mínimo de:
- El LSN del inicio del punto de comprobación
- El LSN del inicio de la transacción activa más antigua
- El LSN del inicio de la transacción de replicación más antigua que aún no se ha entregado a la base de datos de distribución.
Los registros del punto de comprobación también contienen una lista de las transacciones activas que han modificado la base de datos.
Si la base de datos utiliza el modelo de recuperación simple, marca para su reutilización el espacio que se encuentra antes del MinLSN.
Escribe en el disco todas las páginas de datos y de registro desfasadas.
Escribe en el archivo de registro un registro que marca el final del punto de comprobación.
Escribe el LSN del inicio de esta cadena en la página de arranque de la base de datos.
Actividades que provocan un punto de comprobación
Los puntos de comprobación pueden darse en las situaciones siguientes:
- Se ejecuta explícitamente una instrucción CHECKPOINT. Se produce un punto de comprobación en la base de datos actual para la conexión.
- Se realiza una operación registrada al mínimo en la base de datos; por ejemplo, se realiza una operación de copia masiva en una base de datos que utiliza el modelo de recuperación optimizado para cargas masivas de registros.
- Se han agregado o eliminado archivos de base de datos mediante ALTER DATABASE.
- Se detiene una instancia de SQL Server mediante una instrucción SHUTDOWN o deteniendo el servicio SQL Server (MSSQLSERVER). Las dos acciones insertan un punto de comprobación en cada base de datos de la instancia de SQL Server.
- Una instancia de SQL Server genera periódicamente puntos de comprobación de manera automática en cada base de datos para reducir el tiempo que tardará la instancia en recuperar la base de datos.
- Se realiza una copia de seguridad de la base de datos.
- Se realiza una actividad que requiere cerrar la base de datos. Esto puede ocurrir cuando la opción AUTO_CLOSE está activada y se cierra la última conexión de usuario a la base de datos. Otro ejemplo es cuando se realiza un cambio de opción de base de datos que necesita un reinicio de la base de datos.
Puntos de comprobación automáticos
El motor de base de datos de SQL Server genera puntos de comprobación automáticos. El intervalo entre puntos de comprobación automáticos se basa en el espacio del registro utilizado y en el tiempo transcurrido desde el último punto de comprobación. El intervalo de tiempo entre los puntos de comprobación automáticos puede ser muy variable y largo si se realizan pocas modificaciones en la base de datos. Los puntos de comprobación automáticos también se pueden producir con frecuencia si se modifican muchos datos.
El intervalo entre puntos de comprobación automáticos para todas las bases de datos de una instancia de servidor se calcula a partir de la opción de configuración del servidor recovery interval . Esta opción especifica el máximo de tiempo que el motor de base de datos debe usar para recuperar una base de datos al reiniciar el sistema. El motor de base de datos calcula cuántas entradas de registro puede procesar en el intervalo de recuperación durante una operación de recuperación.
El intervalo entre los puntos de comprobación automáticos depende también del modelo de recuperación:
Si la base de datos usa el modelo de recuperación completa o el modelo de recuperación optimizado para cargas masivas de registros, se generará un punto de comprobación automático cuando el número de entradas del registro alcance el número que el motor de base de datos estima que puede procesar durante el tiempo especificado en la opción de intervalo de recuperación.
Si la base de datos utiliza el modelo de recuperación simple, se generará un punto de comprobación automático cuando el número de registros alcance el menor de estos dos valores:
- El registro está ocupado en un 70 por ciento.
- El número de entradas de registro alcanza el número que el motor de base de datos calcula que puede procesar en el periodo especificado en la opción de intervalo de recuperación.
Para más información sobre la configuración del intervalo de recuperación, vea Configuración del intervalo de recuperación (mínimo) (opción de configuración del servidor).
Sugerencia
La opción de configuración avanzada -k de SQL Server permite a un administrador de base de datos limitar el comportamiento de E/S de los puntos de control según el rendimiento de E/S para algunos tipos de puntos de control. La opción de configuración -k es válida para los puntos de comprobación y para cualquier punto de comprobación sin limitar.
Los puntos de comprobación automáticos truncan la parte no utilizada del registro de transacciones si la base de datos utiliza el modelo de recuperación simple. No obstante, el registro no se trunca mediante puntos de comprobación automáticos si la base de datos utiliza el modelo de recuperación completa o el modelo optimizado para cargas masivas de registros. Para más información, vea El registro de transacciones.
Ahora la instrucción CHECKPOINT ofrece un argumento checkpoint_duration opcional que especifica en segundos el tiempo necesario para que finalicen los puntos de comprobación. Para obtener más información, consulte CHECKPOINT.
Registro activo
La parte del archivo de registro desde el MinLSN hasta el último registro escrito se denomina parte activa del registro o registro activo. Se trata de la sección del registro necesaria para una recuperación completa de la base de datos. No se puede truncar ninguna parte del registro activo. Los truncamientos del registro se deben realizar en las partes del registro anteriores al MinLSN.
En el diagrama siguiente se muestra una versión simplificada del final de un registro de transacciones con dos transacciones activas. Los registros de punto de comprobación se han compactado en un solo registro.

LSN 148 es la última entrada del registro de transacciones. En el momento en que se procesó el registro del punto de comprobación en LSN 147, Tran 1 se había confirmado y Tran 2 era la única transacción activa. Esto hace que la primera entrada del registro para Tran 2 sea la entrada de transacción activa más antigua del registro en el momento del último punto de comprobación. Esto convierte al registro de inicio del registro de transacciones para Tran 2, LSN 142, en el MinLSN.
Transacciones de ejecución prolongada
El registro activo debe incluir cada una de las partes de todas las transacciones no confirmadas. Una aplicación que inicia una transacción y no la confirma o la revierte impide que el motor de base de datos avance hacia el valor de MinLSN. Esta situación puede causar dos tipos de problemas:
- Si se cierra el sistema después de que la transacción haya realizado un gran número de modificaciones no confirmadas, la fase de recuperación del siguiente reinicio puede durar bastante más que el tiempo especificado en la opción recovery interval .
- Puede que el tamaño del registro aumente de forma considerable, porque no se puede truncar pasado el MinLSN. Esto ocurre incluso si la base de datos utiliza el modelo de recuperación simple, donde el registro de transacciones se trunca en cada punto de comprobación automático.
La recuperación de transacciones de larga duración y los problemas descritos en este artículo se pueden evitar mediante la recuperación acelerada de la base de datos, una característica disponible a partir de SQL Server 2019 (15.x) y en Azure SQL Database.
Transacciones de replicación
El Agente de registro del LOG supervisa el registro de transacciones de cada base de datos configurada para la replicación transaccional y copia las transacciones marcadas para la replicación desde el registro de transacciones a la base de datos de distribución. El registro activo debe contener todas las transacciones marcadas para la replicación, pero que aún no se han entregado a la base de datos de distribución. Si estas transacciones no se replican puntualmente, pueden evitar el truncamiento del registro. Para obtener más información, consulte Replicación transaccional.
Contenido relacionado
- El registro de transacciones
- Administrar el tamaño del archivo de registro de transacciones
- Copias de seguridad del registro de transacciones (SQL Server)
- Puntos de comprobación de base de datos (SQL Server)
- Configuración del intervalo de recuperación (mín.) (opción de configuración del servidor)
- Recuperación acelerada de bases de datos
- sys.dm_db_log_info (Transact-SQL)
- sys.dm_db_log_space_usage (Transact-SQL)
- Descripción del registro y la recuperación en SQL Server por Paul Randal
- Administración de registros de transacciones de SQL Server por Tony Davis y Gail Shaw
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de