Clústeres de conmutación por error de Windows Server con SQL Server
Se aplica a: ![]() SQL Server
SQL Server
Un clúster de conmutación por error de Windows Server (WSFC) es un grupo de servidores independientes que funcionan conjuntamente para aumentar la disponibilidad de aplicaciones y servicios. SQL Server aprovecha los servicios y las capacidades de WSFC para admitir instancias de clúster de conmutación por error de Grupos de disponibilidad AlwaysOn y SQL Server .
Términos y definiciones
Clúster de conmutación por error de Windows Server (WSFC) Un WSFC es un grupo de servidores independientes que funcionan conjuntamente para aumentar la disponibilidad de aplicaciones y servicios.
Nodo
Un servidor que participa en un WSFC.
Recurso de clúster
Una entidad física o lógica que puede ser propiedad de un nodo, ser puesta en línea y sin conexión, ser movida entre nodos y ser administrada como un objeto de clúster. Un recurso de clúster puede ser propiedad de un único nodo en cualquier momento.
Rol
Una colección de recursos de clúster administrados como un único objeto de clúster para proporcionar una funcionalidad específica. Para SQL Server, un rol debe ser un grupo de disponibilidad Always On (AG) o una instancia de clúster de conmutación por error Always On (FCI). Un rol contiene todos los recursos de clúster necesarios para un AG o una FCI. La conmutación por error y la conmutación por recuperación siempre actúan en contexto de roles. Para una FCI, un rol contendrá un recurso de dirección IP, un recurso de nombre de red y los recursos de SQL Server. Un rol de AG contendrá el recurso de AG y, si hay un agente de escucha configurado, un nombre de red y un recurso de IP.
Recurso de nombre de red
Un nombre de servidor lógico que se administra como un recurso de clúster. Un recurso de nombre de red debe utilizarse con un recurso de dirección IP. Estas entradas pueden requerir objetos en Active Directory Domain Services y DNS.
Dependencia de recursos
Un recurso del que depende otro recurso. Si el recurso A depende del recurso B, entonces B es una dependencia de A. El recurso A no podrá iniciarse sin el recurso B.
Propietario preferido
Un nodo en el que un grupo de recursos prefiere ejecutarse. Cada grupo de recursos está asociado a una lista de propietarios preferidos clasificados en orden de preferencia. Durante la conmutación por error automática, el grupo de recursos se pasa al nodo preferido siguiente en la lista de propietarios preferidos.
Posible propietario
Un nodo secundario en el que se puede ejecutar un recurso. Cada grupo de recursos está asociado a una lista de posibles propietarios. Los roles pueden ser objeto de conmutación por error solo en los nodos enumerados como posibles propietarios.
Modo de quórum
La configuración de quórum en un clúster de conmutación por error que determina el número de errores de nodo que el clúster puede admitir.
Forzar el cuórum
El proceso para iniciar el clúster aunque solo una minoría de los elementos necesarios para el quórum esté en comunicación.
Información general de clústeres de conmutación por error de Windows Server
Los clústeres de conmutación por error de Windows Server proporcionan características de infraestructura que admiten escenarios de alta disponibilidad y recuperación ante desastres de aplicaciones de servidor hospedadas, como Microsoft SQL Server y Microsoft Exchange. Si un nodo o un servicio de clúster tiene un error, los servicios hospedados en ese nodo se pueden transferir automática o manualmente a otro nodo disponible en un proceso denominado conmutación por error.
Los nodos de WSFC trabajan juntos para proporcionar colectivamente estos tipos de funciones:
Notificaciones y metadatos distribuidos. El servicio de WSFC y lo metadatos de aplicaciones hospedadas se mantiene en cada nodo del clúster. Estos metadatos incluyen la configuración y el estado de WSFC además de la configuración de la aplicación hospedada. Los cambios en los metadatos o el estado de un nodo se propagan automáticamente a los demás nodos del WSFC.
Administración de recursos. Los nodos individuales del WSFC pueden proporcionar recursos físicos como almacenamiento asociado directo, interfaces de red y acceso al almacenamiento en disco compartido. Las aplicaciones hospedadas se registran como un recurso de clúster y pueden configurar dependencias de inicio y de estado en otros recursos.
Supervisión de estado. La detección del estado del nodo principal y entre nodos se realiza mediante una combinación de comunicaciones de red de tipo latido y supervisión de recursos. Los votos de un cuórum de nodos del WSFC determinan el estado general del WSFC.
Coordinación de conmutación por error. Cada uno de los recursos se configura para ser hospedado en un nodo principal y se pueden transferir automática o manualmente a uno o varios nodos secundarios. Una directiva de conmutación por error basada en el estado controla la transferencia automática de la propiedad de recursos entre los nodos. Los nodos y las aplicaciones hospedadas son informadas cuando se produce la conmutación por error para puedan reaccionar correctamente.
Para más información, consulte: Failover Clustering Overview - Windows Server(Introducción a los clústeres de conmutación por error - Windows Server).
Tecnologías de SQL Server AlwaysOn y WSFC
SQL Server AlwaysOn es una solución de alta disponibilidad y recuperación ante desastres que aprovecha las ventajas de WSFC. Las características de Always On proporcionan soluciones integradas y flexibles que aumentan la disponibilidad de las aplicaciones, proporcionan mejores réditos en inversiones de hardware y simplifican la implementación y administración de alta disponibilidad.
Tanto las instancias de clúster de conmutación por error Grupos de disponibilidad AlwaysOn como AlwaysOn usan WSFC como tecnología de plataforma, registrando los componentes como recursos de clúster de WSFC. Los recursos relacionados se combinan en un rol que puede hacerse dependiente de otros recursos de clúster de WSFC. El WSFC puede detectar y designar la necesidad de reiniciar la instancia de SQL Server o realizar automáticamente la conmutación por error a otro nodo del servidor del WSFC.
Importante
Para aprovechar las tecnologías de SQL Server AlwaysOn, se deben aplicar varios requisitos previos relacionados con WSFC.
Para obtener más información, vea Requisitos previos, restricciones y recomendaciones para Grupos de disponibilidad AlwaysOn (SQL Server)
Alta disponibilidad en el nivel de instancia con instancias de clúster de conmutación por error AlwaysOn
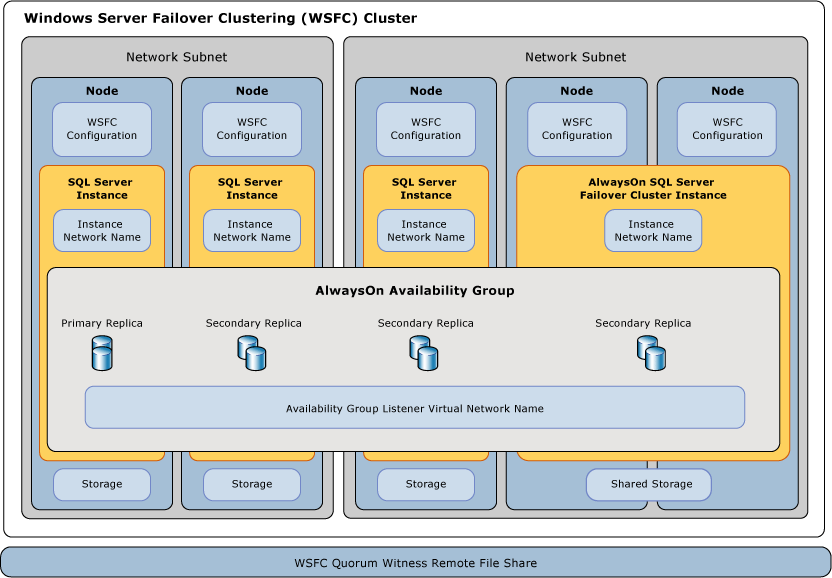
Una instancia de clúster de conmutación por error (FCI) de Always On es una instancia de SQL Server que está instalada en los nodos de un WSFC. Este tipo de instancia depende de los recursos de almacenamiento y el nombre de red virtual. El almacenamiento puede usar Canal de fibra, iSCSI, FCoE o SAS para almacenamiento en disco compartido o usar almacenamiento conectado localmente con Espacios de almacenamiento directo (S2D). El recurso de nombre de red virtual depende de una o más direcciones IP virtuales, cada una en una subred diferente. El servicio SQL Server y el servicio del Agente SQL Server también son recursos, y ambos dependen de los recursos de nombre de red virtual y almacenamiento.
En caso de conmutación por error, el servicio de WSFC transfiere la propiedad de los recursos de la instancia a un nodo de conmutación por error designado. La instancia de SQL Server vuelve a iniciarse en el nodo de conmutación por error y las bases de datos se recuperan de la forma habitual. En cualquier momento determinado, solo un nodo del clúster puede hospedar la FCI y los recursos subyacentes.
Nota:
Una instancia de clúster de conmutación por error Always On requiere almacenamiento en disco compartido simétrico como una red de área de almacenamiento (SAN) o un recurso compartido de archivos SMB. Los volúmenes de almacenamiento en disco compartido deben estar disponible para todos los nodos potenciales de conmutación por error en el clúster de WSFC.
Para obtener más información, vea: Instancias de clúster de conmutación por error de Always On (SQL Server)
Alta disponibilidad en el nivel de base de datos con Grupos de disponibilidad AlwaysOn
Un grupo de disponibilidad Always On (AG) es un conjunto de bases de datos de uno o más usuarios que se conmutan por error conjuntamente. Un grupo de disponibilidad consta de una réplica de disponibilidad principal y de una a cuatro réplicas secundarias que se mantienen mediante el movimiento de datos basado en registros de SQL Server para la protección de datos sin necesidad de almacenamiento compartido. Cada réplica está hospedada en una instancia de SQL Server en otro nodo del WSFC. El grupo de disponibilidad y un nombre de red virtual correspondiente se registran como recursos del clúster de WSFC.
Un agente de escucha de grupo de disponibilidad del nodo de la réplica principal responde a las solicitudes de cliente entrantes para conectarse al nombre de red virtual y, en función de los atributos de la cadena de conexión, redirige cada solicitud a la instancia adecuada de SQL Server .
En el caso de una conmutación por error, en lugar de transferir la propiedad de los recursos físicos compartidos a otro nodo, WSFC aprovecha para volver a configurar una réplica secundaria en otra instancia de SQL Server y que se convierta en la réplica principal del grupo de disponibilidad. El recurso de nombre de red virtual del grupo de disponibilidad se transfiere después a esa instancia.
En cualquier momento dado, solo una instancia de SQL Server puede hospedar la réplica principal de las bases de datos de un grupo de disponibilidad, todas las réplicas secundarias asociadas deben residir cada una en una instancia independiente, y cada instancia debe residir en nodos físicos distintos.
Nota:
Grupos de disponibilidad AlwaysOn no necesita la implementación de una instancia de clúster de conmutación por error ni el uso de almacenamiento compartido simétrico (SAN o SMB).
Una instancia de clúster de conmutación por error (FCI) se puede usar junto con un grupo de disponibilidad para mejorar la disponibilidad de una réplica de disponibilidad. Sin embargo, para evitar posibles condiciones de carrera en el clúster de WSFC, la conmutación automática por error del grupo de disponibilidad no se admite en o desde una réplica de disponibilidad hospedada en una FCI.
Para más información, consulte: Información general de los grupos de disponibilidad AlwaysOn (SQL Server).
Seguimiento de estado y conmutación por error de WSFC
La alta disponibilidad para una solución de AlwaysOn se consigue mediante el seguimiento de estado proactivo de los recursos de clúster de WSFC físicos y lógicos, junto con la conmutación por error automática y la reconfiguración de hardware redundante. Un administrador del sistema también puede iniciar una conmutación por error manual de un grupo de disponibilidad o una instancia de SQL Server entre nodos.
Directivas de conmutación por error para nodos, instancias de clúster de conmutación por error y grupos de disponibilidad
Una directiva de conmutación por error se configura en los siguientes niveles: nodo del WSFC, instancia de clúster de conmutación por error (FCI) de SQL Server y grupo de disponibilidad. Estas directivas, basadas en la gravedad, duración y frecuencia del estado incorrecto de los recursos de clúster y la capacidad de respuesta de los nodos, puede desencadenar el reinicio de un servicio o una conmutación automática por error de los recursos de clúster entre nodos, o puede desencadenar el paso de la réplica principal de un grupo de disponibilidad desde una instancia de SQL Server a otra.
La conmutación por error de la réplica de un grupo de disponibilidad no afecta a la instancia de SQL Server subyacente. La conmutación por error de una FCI mueve las réplicas hospedadas de grupo de disponibilidad con la instancia.
Para obtener más información, vea: Directiva de conmutación por error para instancias de clústeres de conmutación por error.
Detección del estado de los recursos de WSFC
Cada recurso de un WSFC puede notificar su condición y estado periódicamente o a petición. Una variedad de circunstancias puede indicar el error de recursos. Por ejemplo, una interrupción del suministro eléctrico, errores de disco o de memoria, errores de la comunicación de red o servicios que no responden.
Los recursos de WSFC como redes, almacenamiento o servicios se pueden hacer dependientes unos de otros. El estado acumulativo de un recurso está determinado por la acumulación sucesiva de su condición con el estado de cada una de sus dependencias de recursos.
Detección del estado entre nodos de WSFC y votos de quórum
Cada nodo de un WSFC participa en la comunicación periódica de latido para compartir el estado de mantenimiento del nodo con los demás nodos. Los nodos que no responden se consideran que se encuentran en estado de error.
Cuórum es un mecanismo que ayuda a garantizar que el WSFC está en funcionamiento y en ejecución para asegurar que hay recursos suficientes conectados en el WSFC. Si el WSFC tiene suficientes votos, es correcto y puede proporcionar tolerancia a errores de nivel de nodo.
En el WSFC se configura un modo de cuórum que dicta la metodología empleada para los votos de cuórum y cuándo se ha de realizar una conmutación por error automática o poner el clúster sin conexión.
Sugerencia
Se recomienda tener siempre un número impar de votos de cuórum en un WSFC. A efectos de los votos de quórum, no es necesario que SQL Server esté instalado en todos los nodos del clúster. Un servidor adicional puede actuar como miembro de quórum, o el modelo de quórum de WSFC se puede configurar para que se use un recurso compartido de archivos remoto como factor de desempate.
Para más información, consulte Configuración de los votos y modos de cuórum WSFC (SQL Server).
Recuperación ante desastres mediante cuórum forzado
Según las prácticas operativas y la configuración del WSFC, se puede incurrir en conmutaciones por error automáticas y manuales manteniendo al mismo tiempo una solución sólida y con tolerancia a errores de SQL Server Always On. Pero si un cuórum de los nodos con derecho a voto del clúster de WSFC no puede comunicarse con otro, o si el WSFC tiene un error en la validación del estado, el WSFC puede pasar a estar sin conexión.
Si el WSFC pasa a estar sin conexión debido a un desastre imprevisto o a un error persistente de hardware o de comunicaciones, se requiere la intervención manual administrativa para forzar un cuórum y poner de nuevo en línea los nodos de clúster supervivientes en una configuración sin tolerancia a errores.
Posteriormente, también debe realizarse una serie de pasos para volver a configurar el WSFC, recuperar las réplicas de base de datos afectadas y restablecer un nuevo cuórum.
Para más información, consulte: Recuperación ante desastres del clúster WSFC mediante cuórum forzado (SQL Server)
Relación de los componentes de SQL Server AlwaysOn con WSFC
Existen varios niveles de relaciones entre SQL Server AlwaysOn y las características y los componentes de WSFC.
Los grupos de disponibilidad AlwaysOn se hospedan en instancias de SQL Server .
Una solicitud de cliente que especifica un nombre de red de agente de escucha del grupo de disponibilidad lógico para conectarse a la base de datos principal o secundaria se redirige al nombre de red de instancia adecuado de la instancia de SQL Server o de la FCI SQL Server subyacente.
Las instancias de SQL Server se hospedan activamente en un solo nodo.
Si está presente, una Instancia de SQL Server independiente reside siempre en un único Nodo con un nombre de red de instancia estático. Si está presente, una FCI de SQL Server está activa en uno de dos o más nodos de conmutación por error posibles con un único Nombre de red de instancia virtual.
Los nodos son miembros de un clúster de WSFC.
Los metadatos de configuración de WSFC y el estado de todos los nodos se almacenan en cada nodo. Cada servidor puede proporcionar volúmenes asimétricos de almacenamiento o almacenamiento compartido (SAN) para las bases de datos del sistema o de usuario. Cada servidor tiene al menos una interfaz de red física en una o varias subredes IP.
El WSFC supervisa el estado y administra la configuración de un grupo de servidores.
Los mecanismos de WSFC propagan los cambios a los metadatos de configuración de WSFC y el estado a todos los nodos en el WSFC. Si se usa un testigo de disco, los metadatos también se almacenan ahí. De manera predeterminada, cada nodo del WSFC obtiene un voto a favor del cuórum y se usará un testigo si es necesario y se configura.
Grupos de disponibilidad AlwaysOn son subclaves del clúster de WSFC.
Si elimina y vuelve a crear un WSFC, debe deshabilitar y volver a habilitar la característica de Grupos de disponibilidad AlwaysOn en cada instancia del servidor habilitada para Grupos de disponibilidad AlwaysOn en el WSFC original. Para obtener más información, vea Habilitar y deshabilitar grupos de disponibilidad AlwaysOn (SQL Server).
Related Tasks
Contenido relacionado
Tecnologías de Windows Server: clústeres de conmutación por error
Información general de los Espacios de almacenamiento directo (S2D)
Clústeres de conmutación por error de Windows Server 2008 R2
Consulte también
Instancias de clúster de conmutación por error de AlwaysOn (SQL Server)Información general de los grupos de disponibilidad AlwaysOn (SQL Server)Configuración de los votos y modos de cuórum WSFC (SQL Server)Directiva de conmutación por error para instancias de clústeres de conmutación por errorRecuperación ante desastres del clúster WSFC mediante cuórum forzado (SQL Server)
SQL Server 2016 Supports Windows Server 2016 Storage Spaces Direct (SQL Server 2016 admite ahora Espacios de almacenamiento directo en Windows Server 2016)
Comentarios
Próximamente: A lo largo de 2024 iremos eliminando gradualmente GitHub Issues como mecanismo de comentarios sobre el contenido y lo sustituiremos por un nuevo sistema de comentarios. Para más información, vea: https://aka.ms/ContentUserFeedback.
Enviar y ver comentarios de