Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Aplica a:![]() SQL Server 2016 (13.x) y versiones posteriores
SQL Server 2016 (13.x) y versiones posteriores ![]() Azure SQL Database
Azure SQL Database![]() Azure SQL Managed Instance
Azure SQL Managed Instance![]() Azure Synapse Analytics
Azure Synapse Analytics![]() Analytics Platform System (PDW)
Analytics Platform System (PDW)![]() Almacén en Microsoft Fabric
Almacén en Microsoft Fabric![]() base de datos en Microsoft Fabric
base de datos en Microsoft Fabric
Crea una tabla externa.
En este artículo se proporciona la sintaxis, argumentos, comentarios, permisos y ejemplos para cualquier producto SQL que elija.
Selección de un producto
En la fila siguiente, seleccione el nombre del producto que le interese; de esta manera, solo se mostrará la información de ese producto.
* SQL Server *
Introducción: SQL Server
Este comando crea una tabla externa para PolyBase con el fin de acceder a los datos almacenados en un clúster de Hadoop o una tabla externa de PolyBase en Azure Blob Storage en la que se hace referencia a datos almacenados en un clúster de Hadoop o en Azure Blob Storage.
Se aplica a: SQL Server 2016 (13.x) y versiones posteriores.
Usa una tabla externa con un origen de datos externo para consultas de PolyBase. Los orígenes de datos externos se usan para establecer la conectividad y admiten estos casos de uso principales:
- Virtualización de datos y carga de datos mediante virtualización de datos con PolyBase en SQL Server
- Operaciones de carga masiva mediante SQL Server o SQL Database utilizando
BULK INSERToOPENROWSET
Una tabla externa se basa en un origen de datos externo.
![]() Convenciones de sintaxis de Transact-SQL
Convenciones de sintaxis de Transact-SQL
Sintaxis
-- Create a new external table
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ , ...n ] )
WITH (
LOCATION = 'folder_or_filepath' ,
DATA_SOURCE = external_data_source_name ,
[ FILE_FORMAT = external_file_format_name ]
[ , <reject_options> [ , ...n ] ]
)
[ ; ]
<reject_options> ::=
{
| REJECT_TYPE = { value | percentage }
| REJECT_VALUE = reject_value
| REJECT_SAMPLE_VALUE = reject_sample_value ,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argumentos
{ database_name.nombre_schema.nombre_de_tabla_| schema_name.nombre_de_tabla_table_name }
Nombre de entre una y tres partes de la tabla que se va a crear.
En una tabla externa, SQL solo almacena los metadatos de tabla junto con estadísticas básicas sobre el archivo o carpeta a los que se hace referencia en Hadoop o Azure Blob Storage. Ningún dato real se mueve o se almacena en SQL Server.
Importante
Para obtener el mejor rendimiento, si el controlador de origen de datos externo admite un nombre de tres partes, debe proporcionar el nombre de tres partes.
< > column_definition [ ,... n ]
CREATE EXTERNAL TABLE admite la capacidad de configurar el nombre de columna, el tipo de datos, la nulabilidad y la intercalación. No se puede usar DEFAULT CONSTRAINT en tablas externas.
Las definiciones de columna, incluidos los tipos de datos y el número de columnas, deben coincidir con los datos de los archivos externos. Si hay un error de coincidencia, las filas de archivo se rechazan al consultar los datos reales.
UBICACIÓN = 'folder_or_filepath'
Especifica la carpeta o la ruta de acceso y el nombre de archivo para los datos en Hadoop o Azure Blob Storage. Además, se admite el almacenamiento de objetos compatible con S3 a partir de SQL Server 2022 (16.x). La ubicación empieza desde la carpeta raíz. La carpeta raíz es la ubicación de datos especificada en el origen de datos externo.
En SQL Server, la instrucción CREATE EXTERNAL TABLE crea la ruta de acceso y la carpeta si aún no existe. A continuación, puede usar INSERT INTO para exportar datos de una tabla local de SQL Server al origen de datos externo. Para más información, consulte Escenarios de consulta de PolyBase.
Si especifica LOCATION que sea una carpeta, una consulta de PolyBase que selecciona de la tabla externa recupera los archivos de la carpeta y todas sus subcarpetas. Al igual que Hadoop, PolyBase no devuelve carpetas ocultas. Tampoco devuelve archivos para los que el nombre de archivo comienza con un subrayado (_) o un punto (.).
En el ejemplo de imagen siguiente, si LOCATION='/webdata/'es , una consulta de PolyBase devuelve filas de mydata.txt y mydata2.txt. No devuelve mydata3.txt porque es un archivo en una subcarpeta oculta. Y no devuelve _hidden.txt porque es un archivo oculto.
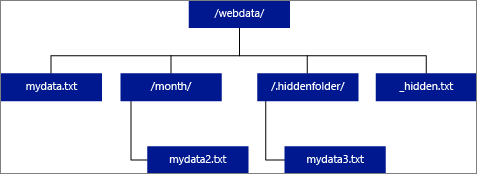
Para cambiar el valor predeterminado y leer solo de la carpeta raíz, establezca el atributo <polybase.recursive.traversal> en "false" en el archivo de configuración core-site.xml. Este archivo se encuentra en <SqlBinRoot>\PolyBase\Hadoop\Conf bajo el bin raíz de SQL Server. Por ejemplo, C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn.
DATA_SOURCE = external_data_source_name
Especifica el nombre del origen de datos externo que contiene la ubicación donde se almacenan los datos externos. Esta ubicación es un sistema de archivos de Hadoop (HDFS), un contenedor de Azure Blob Storage o Azure Data Lake Store. Para crear una fuente de datos externa, utiliza CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Especifica el nombre del objeto de formato de archivo externo que almacena el tipo de archivo y el método de compresión para los datos externos. Para crear un formato de archivo externo, use CREATE EXTERNAL FILE FORMAT.
Los formatos de archivo externos se pueden volver a usar en varios archivos externos similares.
Opciones de REJECT
Esta opción solo se puede usar con orígenes de datos externos donde TYPE = HADOOP.
Puede especificar los parámetros reject que determinan cómo PolyBase controla los registros sucios que recupera del origen de datos externo. Un registro de datos se considera "desfasado" si los tipos de datos reales o el número de columnas no coinciden con las definiciones de columna de la tabla externa.
Si no se especifican ni se cambian los valores de Reject, PolyBase usa los valores predeterminados. Esta información sobre los parámetros reject se almacena como metadatos adicionales al crear una tabla externa con CREATE EXTERNAL TABLE la instrucción . Cuando una instrucción o SELECT instrucción futura SELECT INTO SELECT selecciona datos de la tabla externa, PolyBase usa las opciones de rechazo para determinar el número o porcentaje de filas que se pueden rechazar antes de que se produzca un error en la consulta real. La consulta devuelve (parcial) resultados hasta que se supera el umbral de rechazo. Después, se produce un error con el mensaje de error correspondiente.
REJECT_TYPE = { valor | porcentaje }
Aclara si la REJECT_VALUE opción se especifica como un valor literal o un porcentaje.
valor
REJECT_VALUEes un valor literal, no un porcentaje. Se produce un error en la consulta cuando el número de filas rechazadas supera reject_value.Por ejemplo, si
REJECT_VALUE = 5yREJECT_TYPE = value, se produce un error en laSELECTconsulta después de que se rechacen cinco filas.porcentaje
REJECT_VALUEes un porcentaje, no un valor literal. Se produce un error en una consulta cuando el porcentaje de filas con error supera reject_value. El porcentaje de filas con errores se calcula a intervalos.
REJECT_VALUE = reject_value
Especifica el valor o el porcentaje de filas que se pueden rechazar antes de que se produzca un error en la consulta.
Para REJECT_TYPE = value, reject_value debe ser un entero entre 0 y 2.147.483.647.
Para REJECT_TYPE = percentage, reject_value debe ser un valor float entre 0 y 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Este atributo es necesario cuando se especifica REJECT_TYPE = percentage. Determina el número de filas que se intentan recuperar antes de que PolyBase vuelva a calcular el porcentaje de filas rechazadas.
El parámetro reject_sample_value debe ser un entero comprendido entre 0 y 2.147.483.647.
Por ejemplo, si REJECT_SAMPLE_VALUE = 1000, PolyBase calcula el porcentaje de filas con errores después de intentar importar 1000 filas desde el archivo de datos externo. Si el porcentaje de filas con errores es menor que reject_value, PolyBase intenta recuperar otras 1000 filas. Sigue recalculando el porcentaje de filas con error después de intentar importar cada 1000 filas adicionales.
Nota
Puesto que PolyBase calcula el porcentaje de filas con errores a intervalos, el porcentaje real de filas con errores puede superar el valor de reject_value.
Ejemplo
En este ejemplo se muestra cómo interactúan las tres REJECT opciones entre sí. Por ejemplo, si REJECT_TYPE = percentage, REJECT_VALUE = 30y REJECT_SAMPLE_VALUE = 100, podría producirse el siguiente escenario:
- PolyBase intenta recuperar las 100 primeras filas; 25 no se importan y 75 sí.
- El porcentaje de las filas con errores se calcula en un 25 %, que es menor que el valor de rechazo de 30 %. Como resultado, PolyBase continúa recuperando datos del origen de datos externo.
- PolyBase intenta cargar las siguientes 100 filas; esta vez, 25 lo hacen y 75 no.
- El porcentaje de filas con errores se recalcula en un 50 %. El porcentaje de filas con errores supera pues el valor de rechazo de 30 %.
- Se produce un error en la consulta de PolyBase con un 50 % de filas rechazadas después de intentar devolver las 200 primeras filas. Las filas coincidentes se devuelven antes de que la consulta de PolyBase detecte que se ha superado el umbral de rechazo.
REJECTED_ROW_LOCATION = ubicación del directorio
Se aplica a: SQL Server 2019 (15.x) CU 6 y versiones posteriores, y Azure Synapse Analytics.
Especifica el directorio del origen de datos externo en el que se deben escribir las filas rechazadas y el archivo de errores correspondiente.
Si la ruta de acceso especificada no existe, PolyBase crea una en su nombre. Se crea un directorio secundario con el nombre _rejectedrows. El carácter _ garantiza que se escape el directorio para otro procesamiento de datos, a menos que se mencione explícitamente en el parámetro de ubicación. Dentro de este directorio, hay una carpeta creada en función del tiempo de envío de carga en el formato YearMonthDay -HourMinuteSecond (por ejemplo, 20230330-173205). En esta carpeta, se escriben dos tipos de archivos: el archivo _reason y el archivo de datos. Esta opción solo se puede usar con orígenes de datos externos donde TYPE = HADOOP y para tablas externas mediante DELIMITEDTEXTFORMAT_TYPE. Para obtener más información, vea CREATE EXTERNAL DATA SOURCE y CREATE EXTERNAL FILE FORMAT.
Los archivos de razón y los archivos de datos tienen la queryID asociada a la instrucción CTAS. Como los datos y los archivos reason están en archivos independientes, los archivos correspondientes tienen un sufijo coincidente.
Permisos
Requiere estos permisos de usuario:
CREATE TABLEALTER ANY SCHEMAALTER ANY EXTERNAL DATA SOURCE-
ALTER ANY EXTERNAL FILE FORMAT(solo se aplica a orígenes de datos externos de Hadoop y Azure Storage) -
CONTROL DATABASE(solo se aplica a orígenes de datos externos de Hadoop y Azure Storage)
El inicio de sesión remoto especificado en el DATABASE SCOPED CREDENTIAL usado en el CREATE EXTERNAL TABLE comando debe tener permiso de lectura para la ruta de acceso, tabla o colección en el origen de datos externo especificado en el LOCATION parámetro . Si planea usarlo EXTERNAL TABLE para exportar datos a un origen de datos externo de Hadoop o Azure Storage, el inicio de sesión especificado debe tener permiso de escritura en la ruta de acceso especificada en LOCATION. Hadoop no se admite en SQL Server 2022 (16.x).
Para Azure Blob Storage, al configurar las claves de acceso y la firma de acceso compartido (SAS) en Azure Portal, las cuentas de almacenamiento de Azure Blob Storage o ADLS Gen2, configure los permisos permitidos para conceder al menos permisos de lectura y escritura. También es posible que se requiera el permiso de lista al buscar entre carpetas. También debe seleccionar Contenedor y Objeto como los tipos de recursos permitidos.
Importante
El ALTER ANY EXTERNAL DATA SOURCE permiso concede a cualquier entidad de seguridad la capacidad de crear y modificar cualquier objeto de origen de datos externo y, por tanto, también concede la capacidad de acceder a todas las credenciales con ámbito de base de datos en la base de datos. Debe considerarse como un permiso con muchos privilegios, por lo que solo debe concederse a las entidades de seguridad de confianza del sistema.
Control de errores
Al ejecutar la instrucción CREATE EXTERNAL TABLE, PolyBase intenta conectarse al origen de datos externo. Si se produce un error en el intento de conexión, se produce un error en la instrucción y no se crea la tabla externa. El error en el comando puede tardar un minuto o más en producirse, ya que PolyBase vuelve a intentar conectar hasta que al final da como errónea la consulta.
Comentarios
En escenarios de consulta ad hoc, como SELECT FROM EXTERNAL TABLE, PolyBase almacena las filas que se recuperan del origen de datos externo en una tabla temporal. Una vez finalizada la consulta, PolyBase quita y elimina la tabla temporal. En las tablas SQL no se almacenan datos permanentes. En cambio, en el escenario de importación, como SELECT INTO FROM EXTERNAL TABLE, PolyBase almacena las filas que se recuperan del origen de datos externo como datos permanentes en la tabla SQL. La tabla se crea durante la ejecución de la consulta cuando PolyBase recupera los datos externos.
El formato hadoop solo se admite en SQL Server 2016 (13.x), SQL Server 2017 (14.x) y SQL Server 2019 (15.x).
PolyBase puede insertar algunos de los cálculos de la consulta en Hadoop para mejorar el rendimiento. Esta acción se conoce como aplicación de predicado. Para habilitarlo, especifica la opción de ubicación del gestor de recursos de Hadoop en CREATE EXTERNAL DATA SOURCE.
Puede crear varias tablas externas que hagan referencia a los mismos orígenes de datos externos o a otros.
Limitaciones
Dado que los datos de una tabla externa no están bajo el control de administración directa de SQL Server, se pueden cambiar o quitar en cualquier momento mediante un proceso externo. Como resultado, no se garantiza que los resultados de la consulta sobre una tabla externa sean deterministas. La misma consulta puede devolver resultados diferentes cada vez que se ejecute en una tabla externa. Del mismo modo, es posible que se produzca un error en una consulta si los datos externos se mueven o se quitan.
Puede crear varias tablas externas que hagan referencia a diferentes orígenes de datos externos. Si ejecuta consultas de forma simultánea sobre otros orígenes de datos de Hadoop, cada uno tendrá que usar el mismo valor de configuración de servidor "hadoop connectivity". Por ejemplo, no se puede ejecutar simultáneamente una consulta en un clúster de Cloudera Hadoop y un clúster de Hortonworks Hadoop, ya que usan valores de configuración diferentes. Para conocer los valores de configuración y las combinaciones admitidas, consulte Configuración de conectividad de PolyBase.
Cuando la tabla externa usa DELIMITEDTEXT, CSV, PARQUET o DELTA como tipos de datos, las tablas externas solo admiten estadísticas para una columna por cada comando CREATE STATISTICS.
En tablas externas solo se admiten estas instrucciones de lenguaje de definición de datos (DDL):
-
CREATE TABLEyDROP TABLE -
CREATE STATISTICSyDROP STATISTICS -
CREATE VIEWyDROP VIEW
Construcciones y operaciones no admitidas:
- Restricción
DEFAULTen columnas de tabla externa - Operaciones de lenguaje de manipulación de datos (DML) delete, insert y update
Limitaciones de las consultas
PolyBase puede consumir un máximo de 33 000 archivos por carpeta cuando se ejecutan 32 consultas simultáneas de PolyBase. Esta cifra máxima engloba los archivos y las subcarpetas de cada carpeta de HDFS. Si el grado de simultaneidad es inferior a 32, un usuario puede ejecutar consultas de PolyBase en carpetas de HDFS que contengan más de 33 000 archivos. Se recomienda tener unas rutas de acceso de archivos externos cortas y no usar más de 30.000 archivos por carpeta de HDFS. Si hay referencias a demasiados archivos, podría producirse una excepción de memoria insuficiente de Máquina virtual Java (JVM).
Limitaciones de ancho de tabla
En SQL Server 2016 (13.x), PolyBase tiene un límite de ancho de fila de 32 KB en función del tamaño máximo de una sola fila válida por definición de tabla. Si la suma del esquema de columnas es superior a 32 KB, PolyBase no puede consultar los datos.
Limitaciones de tipos de datos
Los siguientes tipos de datos no se pueden usar en tablas externas de PolyBase:
- geography
- de geometría
- hierarchyid
- de imagen
- de texto
- contexto
- xml de
- Cualquier tipo definido por el usuario
Limitaciones específicas del origen de datos
Oráculo
Los sinónimos de Oracle no se admiten para su uso con PolyBase.
Tablas externas a colecciones de MongoDB que contienen matrices
Use sp_data_source_objects para detectar el esquema de colección (columnas) para colecciones de MongoDB que contienen matrices y crear manualmente la tabla externa. El procedimiento almacenado sp_data_source_table_columns también realiza automáticamente el acoplamiento mediante el controlador ODBC de PolyBase para MongoDB.
Bloqueo
Bloqueo compartido en el SCHEMARESOLUTION objeto .
Seguridad
Los archivos de datos de una tabla externa se almacenan en Hadoop o Azure Blob Storage. Son sus propios procesos los que crean y administran estos archivos de datos. Es su responsabilidad administrar la seguridad de los datos externos.
Ejemplos
Un. Crear una tabla externa con datos en formato delimitado por texto
En este ejemplo se muestran todos los pasos necesarios para crear una tabla externa que tenga datos con formato de archivos delimitados por texto. Define un origen de datos externo mydatasource y un formato de archivo externo myfileformat. A continuación, se hace referencia a estos objetos de nivel de base de datos en la instrucción CREATE EXTERNAL TABLE. Para obtener más información, vea CREATE EXTERNAL DATA SOURCE y CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
);
GO
CREATE EXTERNAL FILE FORMAT myfileformat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (FIELD_TERMINATOR = '|')
);
GO
CREATE EXTERNAL TABLE ClickStream
(
url VARCHAR (50),
event_date DATE,
user_IP VARCHAR (50)
)
WITH (
DATA_SOURCE = mydatasource,
LOCATION = '/webdata/employee.tbl',
FILE_FORMAT = myfileformat
);
B. Crear una tabla externa con datos en formato RCFile
En este ejemplo se muestran todos los pasos necesarios para crear una tabla externa que tenga datos con formato de RCFiles. Define un origen de datos externo mydatasource_rc y un formato de archivo externo myfileformat_rc. A continuación, se hace referencia a estos objetos de nivel de base de datos en la instrucción CREATE EXTERNAL TABLE. Para obtener más información, vea CREATE EXTERNAL DATA SOURCE y CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_rc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
);
GO
CREATE EXTERNAL FILE FORMAT myfileformat_rc
WITH (
FORMAT_TYPE = RCFILE,
SERDE_METHOD = 'org.apache.hadoop.hive.serde2.columnar.LazyBinaryColumnarSerDe'
);
GO
CREATE EXTERNAL TABLE ClickStream_rc
(
url VARCHAR (50),
event_date DATE,
user_ip VARCHAR (50)
)
WITH (
DATA_SOURCE = mydatasource_rc,
LOCATION = '/webdata/employee_rc.tbl',
FILE_FORMAT = myfileformat_rc
);
C. Crear una tabla externa con datos en formato ORC
En este ejemplo se muestran todos los pasos necesarios para crear una tabla externa que tenga datos con formato de archivos ORC. Se define un origen de datos externo mydatasource_orc y un formato de archivo externo myfileformat_orc. A continuación, se hace referencia a estos objetos de nivel de base de datos en la instrucción CREATE EXTERNAL TABLE. Para obtener más información, vea CREATE EXTERNAL DATA SOURCE y CREATE EXTERNAL FILE FORMAT.
CREATE EXTERNAL DATA SOURCE mydatasource_orc
WITH (
TYPE = HADOOP,
LOCATION = 'hdfs://xxx.xxx.xxx.xxx:8020'
);
GO
CREATE EXTERNAL FILE FORMAT myfileformat_orc
WITH (
FORMAT = ORC,
COMPRESSION = 'org.apache.hadoop.io.compress.SnappyCodec'
);
GO
CREATE EXTERNAL TABLE ClickStream_orc (
url VARCHAR (50),
event_date DATE,
user_ip VARCHAR (50)
)
WITH (
LOCATION='/webdata/',
DATA_SOURCE = mydatasource_orc,
FILE_FORMAT = myfileformat_orc
);
D. Consultar datos de Hadoop
ClickStream es una tabla externa que se conecta con el archivo de texto delimitado employee.tbl en un clúster de Hadoop. La consulta siguiente parece una consulta en una tabla estándar, pero recupera datos de Hadoop y luego calcula los resultados.
SELECT TOP 10 (url)
FROM ClickStream
WHERE user_ip = 'xxx.xxx.xxx.xxx';
E. Combinar datos de Hadoop con datos SQL
Esta consulta es similar a un estándar JOIN en dos tablas SQL. La diferencia es que PolyBase recupera la información de la secuencia de clic de Hadoop y luego los combina con la tabla UrlDescription. Una tabla es una tabla externa y la otra es una tabla SQL estándar.
SELECT url.description
FROM ClickStream AS cs
INNER JOIN UrlDescription AS url
ON cs.url = url.name
WHERE cs.url = 'msdn.microsoft.com';
F. Importar datos de Hadoop en una tabla SQL
En este ejemplo se crea una nueva tabla SQL ms_user que almacena de forma permanente el resultado de una combinación entre la tabla SQL estándar user y la tabla externa ClickStream.
SELECT DISTINCT user.FirstName, user.LastName
INTO ms_user
FROM user INNER JOIN (
SELECT * FROM ClickStream WHERE cs.url = 'www.microsoft.com'
) AS ms
ON user.user_ip = ms.user_ip;
G. Crear una tabla externa para SQL Server
Para poder crear una credencial con ámbito de base de datos, la base de datos debe tener una clave maestra para proteger la credencial. Para obtener más información, vea CREATE MASTER KEY y CREATE DATABASE SCOPED CREDENTIAL.
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';
GO
/* specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL SqlServerCredentials
WITH
IDENTITY = '<username>',
SECRET = '<password>';
Cree un nuevo origen de datos externo denominado SQLServerInstance y una tabla externa denominada sqlserver.customer:
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE SQLServerInstance
WITH (
LOCATION = 'sqlserver://SqlServer',
-- PUSHDOWN = ON | OFF,
CREDENTIAL = SQLServerCredentials
);
GO
CREATE SCHEMA sqlserver;
/* LOCATION: sql server table/view in 'database_name.schema_name.object_name' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE sqlserver.customer (
C_CUSTKEY INT NOT NULL,
C_NAME VARCHAR(25) NOT NULL,
C_ADDRESS VARCHAR(40) NOT NULL,
C_NATIONKEY INT NOT NULL,
C_PHONE CHAR(15) NOT NULL,
C_ACCTBAL DECIMAL(15,2) NOT NULL,
C_MKTSEGMENT CHAR(10) NOT NULL,
C_COMMENT VARCHAR(117) NOT NULL
)
WITH (
LOCATION='tpch_10.dbo.customer',
DATA_SOURCE=SqlServerInstance
);
Yo. Crear una tabla externa para Oracle
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';
GO
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH
IDENTITY = '<username>',
SECRET = '<password>';
GO
/*
* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = 'oracle://<server address>[:<port>]',
-- PUSHDOWN = ON | OFF,CREDENTIAL = credential_name
);
/*
* LOCATION: Oracle table/view in '<database_name>.<schema_name>.<object_name>' format. This may be case sensitive in the Oracle database.
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers
(
[O_ORDERKEY] DECIMAL (38) NOT NULL,
[O_CUSTKEY] DECIMAL (38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL (15, 2) NOT NULL,
[O_ORDERDATE] DATETIME2 (0) NOT NULL,
[O_ORDERPRIORITY] CHAR (15) COLLATE Latin1_General_BIN NOT NULL,
[O_CLERK] CHAR (15) COLLATE Latin1_General_BIN NOT NULL,
[O_SHIPPRIORITY] DECIMAL (38) NOT NULL,
[O_COMMENT] VARCHAR (79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
DATA_SOURCE = external_data_source_name,
LOCATION = 'DB1.mySchema.customer'
);
J. Crear una tabla externa para Teradata
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';
GO
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH
IDENTITY = '<username>',
SECRET = '<password>';
GO
/* LOCATION: Location string should be of format '<vendor>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = teradata://<server address>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL =credential_name
);
GO
/* LOCATION: Teradata table/view in '<database_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customer(
L_ORDERKEY INT NOT NULL,
L_PARTKEY INT NOT NULL,
L_SUPPKEY INT NOT NULL,
L_LINENUMBER INT NOT NULL,
L_QUANTITY DECIMAL(15,2) NOT NULL,
L_EXTENDEDPRICE DECIMAL(15,2) NOT NULL,
L_DISCOUNT DECIMAL(15,2) NOT NULL,
L_TAX DECIMAL(15,2) NOT NULL,
L_RETURNFLAG CHAR NOT NULL,
L_LINESTATUS CHAR NOT NULL,
L_SHIPDATE DATE NOT NULL,
L_COMMITDATE DATE NOT NULL,
L_RECEIPTDATE DATE NOT NULL,
L_SHIPINSTRUCT CHAR(25) NOT NULL,
L_SHIPMODE CHAR(10) NOT NULL,
L_COMMENT VARCHAR(44) NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
K. Crear una tabla externa para MongoDB
-- Create a Master Key
CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';
GO
/*
* Specify credentials to external data source
* IDENTITY: user name for external source.
* SECRET: password for external source.
*/
CREATE DATABASE SCOPED CREDENTIAL credential_name
WITH
IDENTITY = '<username>',
SECRET = '<password>';
GO
/* LOCATION: Location string should be of format '<type>://<server>[:<port>]'.
* PUSHDOWN: specify whether computation should be pushed down to the source. ON by default.
* CONNECTION_OPTIONS: Specify driver location
* CREDENTIAL: the database scoped credential, created above.
*/
CREATE EXTERNAL DATA SOURCE external_data_source_name
WITH (
LOCATION = mongodb://<server>[:<port>],
-- PUSHDOWN = ON | OFF,
CREDENTIAL = credential_name
);
/* LOCATION: MongoDB table/view in '<database_name>.<schema_name>.<object_name>' format
* DATA_SOURCE: the external data source, created above.
*/
CREATE EXTERNAL TABLE customers(
[O_ORDERKEY] DECIMAL(38) NOT NULL,
[O_CUSTKEY] DECIMAL(38) NOT NULL,
[O_ORDERSTATUS] CHAR COLLATE Latin1_General_BIN NOT NULL,
[O_TOTALPRICE] DECIMAL(15,2) NOT NULL,
[O_ORDERDATE] DATETIME2(0) NOT NULL,
[O_COMMENT] VARCHAR(79) COLLATE Latin1_General_BIN NOT NULL
)
WITH (
LOCATION='customer',
DATA_SOURCE= external_data_source_name
);
L. Consulta del almacenamiento de objetos compatible con S3 a través de una tabla externa
Se aplica a: SQL Server 2022 (16.x) y versiones posteriores.
En el ejemplo siguiente se muestra el uso de T-SQL para consultar un archivo PARQUET almacenado en el almacenamiento de objetos compatible con S3 mediante la consulta de tabla externa. En el ejemplo se usa una ruta de acceso relativa dentro del origen de datos externo.
CREATE EXTERNAL DATA SOURCE s3_ds
WITH
( LOCATION = 's3://<ip_address>:<port>/',
CREDENTIAL = s3_dc
);
GO
CREATE EXTERNAL FILE FORMAT ParquetFileFormat
WITH(
FORMAT_TYPE = PARQUET
);
GO
CREATE EXTERNAL TABLE Region (
r_regionkey BIGINT,
r_name CHAR(25),
r_comment VARCHAR(152)
)
WITH (
LOCATION = '/region/',
DATA_SOURCE = 's3_ds',
FILE_FORMAT = ParquetFileFormat
);
Contenido relacionado
* Azure SQL Database *
Introducción: Azure SQL Database
Crea una tabla externa que se usa para:
Consulte también CREATE EXTERNAL DATA SOURCE.
Sintaxis
Para su uso con virtualización de datos (versión preliminar)
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ , ...n ] )
WITH (
LOCATION = 'filepath' ,
DATA_SOURCE = external_data_source_name ,
FILE_FORMAT = external_file_format_name
)
[ ; ]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Para su uso con consultas elásticas (versión preliminar)::
-- Create a table for use with elastic query
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ , ...n ] )
WITH ( <sharded_external_table_options> )
[ ; ]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<sharded_external_table_options> ::=
DATA_SOURCE = external_data_source_name ,
SCHEMA_NAME = N'nonescaped_schema_name' ,
OBJECT_NAME = N'nonescaped_object_name' ,
[ DISTRIBUTION = SHARDED(sharding_column_name) | REPLICATED | ROUND_ROBIN ] ]
)
[ ; ]
Argumentos
{ database_name.nombre_schema.nombre_de_tabla_| schema_name.nombre_de_tabla_table_name }
Nombre de entre una y tres partes de la tabla que se va a crear.
En una tabla externa, SQL solo almacena los metadatos de tabla junto con estadísticas básicas sobre el archivo o la carpeta a los que se hace referencia en Azure SQL Database. No se mueven ni almacenan datos reales en Azure SQL Database cuando se crean tablas externas.
Importante
Para obtener el mejor rendimiento, si el controlador de origen de datos externo admite un nombre de tres partes, debe proporcionar el nombre de tres partes.
< > column_definition [ ,... n ]
CREATE EXTERNAL TABLE admite la capacidad de configurar el nombre de columna, el tipo de datos, la nulabilidad y la intercalación. No se puede usar DEFAULT CONSTRAINT en tablas externas. Estos tipos de datos no se admiten para las columnas de tablas externas para Azure SQL Database:
- geography
- de geometría
- hierarchyid
- de imagen
- de texto
- contexto
- xml de
- json
- Cualquier tipo definido por el usuario
Las definiciones de columna, incluidos los tipos de datos y el número de columnas, deben coincidir con los datos de los archivos externos. Si hay un error de coincidencia, las filas de archivo se rechazan al consultar los datos reales.
Opciones de tabla externa particionada
Especifica el origen de datos externo (un origen de datos no SQL Server) y un método de distribución para la consulta elástica.
UBICACIÓN = 'folder_or_filepath'
Especifica la carpeta o la ruta de acceso del archivo y el nombre de archivo de los datos reales en Azure Data Lake Gen2 o Azure Blob Storage. La ubicación empieza desde la carpeta raíz. La carpeta raíz es la ubicación de datos especificada en el origen de datos externo.
CREATE EXTERNAL TABLE no crea la ruta de acceso y la carpeta.
Si especifica LOCATION que sea una carpeta, una consulta que selecciona de la tabla externa recupera los archivos de la carpeta, pero no todas sus subcarpetas.
Azure SQL Managed Instance no puede encontrar archivos en subcarpetas ni carpetas ocultas. Tampoco devuelve archivos para los que el nombre de archivo comienza con un subrayado (_) o un punto (.).
En el ejemplo de imagen siguiente, si LOCATION='/webdata/'es , una consulta devuelve filas de mydata.txt. No devuelve mydata2.txt porque está en una subcarpeta, no devuelve mydata3.txt porque está en una carpeta oculta y no devuelve _hidden.txt porque es un archivo oculto.
DATA_SOURCE
DATA_SOURCE especifica el nombre del origen de datos externo que contiene la ubicación de los datos externos. Para crear una fuente de datos externa, utiliza CREATE EXTERNAL DATA SOURCE. Para obtener un ejemplo de consulta elástica, DATA_SOURCE es el mapa de particiones, consulte Creación de tablas externas.
FILE_FORMAT = external_file_format_name
Especifica el nombre del objeto de formato de archivo externo que almacena el tipo de archivo y el método de compresión para los datos externos. Para crear un formato de archivo externo, use CREATE EXTERNAL FILE FORMAT.
SCHEMA_NAME y OBJECT_NAME
Para su uso solo con consultas elásticas.
Las SCHEMA_NAME cláusulas y OBJECT_NAME asignan la definición de tabla externa a una tabla en un esquema diferente. Si se omite, se supone que el esquema del objeto remoto es dboy su nombre es idéntico al nombre de la tabla externa que se define. Esto es útil si el nombre de la tabla remota ya existe en la base de datos donde desea crear la tabla externa. Por ejemplo, quiere definir una tabla externa para obtener una vista agregada de las vistas de catálogo o DMV en la capa de datos con escala horizontal. Dado que las vistas de catálogo y las DMV ya existen localmente, no puede usar sus nombres para la definición de tabla externa. En su lugar, use un nombre diferente y use el nombre de la vista de catálogo o el nombre de la DMV en las SCHEMA_NAME cláusulas o OBJECT_NAME . Para obtener un ejemplo, vea Creación de tablas externas.
DISTRIBUCIÓN
Para su uso solo con consultas elásticas.
Opcional. Este argumento solo es necesario para las bases de datos de tipo SHARD_MAP_MANAGER. Este argumento controla si una tabla se trata como una tabla con particiones o una tabla replicada. Con SHARDED (<column name>) las tablas, los datos de las distintas tablas no se superponen.
REPLICATED especifica que las tablas tienen los mismos datos en cada partición.
ROUND_ROBIN indica que se usa un método específico de la aplicación para distribuir los datos.
La DISTRIBUTION cláusula especifica la distribución de datos utilizada para esta tabla. El procesador de consultas utiliza la información proporcionada en la DISTRIBUTION cláusula para crear los planes de consulta más eficaces.
-
SHARDEDsignifica que los datos se particionan horizontalmente entre las bases de datos. La clave de creación de particiones para la distribución de datos es el parámetrosharding_column_name. -
REPLICATEDsignifica que hay copias idénticas de la tabla en cada base de datos. Es responsabilidad suya asegurarse de que las réplicas son idénticas en las bases de datos. -
ROUND_ROBINsignifica que la tabla se particiona horizontalmente mediante un método de distribución dependiente de la aplicación.
Permisos
Los usuarios con acceso a la tabla externa obtienen automáticamente acceso a las tablas remotas subyacentes con la credencial proporcionada en la definición del origen de datos externo. Evite la elevación no deseada de privilegios a través de la credencial del origen de datos externo. Use GRANT o REVOKE para una tabla externa como si fuera una tabla normal. Una vez que defina el origen de datos externo y las tablas externas, puede usar el T-SQL completo en las tablas externas.
CREATE EXTERNAL TABLE requiere estos permisos de usuario:
CREATE TABLEALTER ANY SCHEMAALTER ANY EXTERNAL DATA SOURCEALTER ANY EXTERNAL FILE FORMAT-
CONTROL DATABASELos permisos son necesarios para crear solo la clave maestra, la credencial con ámbito de base de datos y el origen de datos externo.
El inicio de sesión que crea el origen de datos externo debe tener permiso para leer y escribir en el origen de datos externo, ubicado en Hadoop o Azure Blob Storage.
Importante
El ALTER ANY EXTERNAL DATA SOURCE permiso concede a cualquier entidad de seguridad la capacidad de crear y modificar cualquier objeto de origen de datos externo y, por tanto, también concede la capacidad de acceder a todas las credenciales con ámbito de base de datos en la base de datos. Debe considerarse como un permiso con muchos privilegios, por lo que solo debe concederse a las entidades de seguridad de confianza del sistema.
Bloqueo
Bloqueo compartido en el SCHEMARESOLUTION objeto .
Comentarios
En escenarios de consulta ad hoc, como SELECT FROM EXTERNAL TABLE, las filas que se recuperan del origen de datos externo se almacenan en una tabla temporal. Una vez completada la consulta, se quitan las filas y se elimina la tabla temporal. En las tablas SQL no se almacenan datos permanentes.
En cambio, en el escenario de importación, como SELECT INTO FROM EXTERNAL TABLE, las filas que se recuperan del origen de datos externo se almacenan como datos permanentes en la tabla SQL. La tabla se crea durante la ejecución de la consulta cuando se recuperan los datos externos.
Actualmente, la virtualización de datos con Azure SQL Database es de solo lectura.
Puede crear varias tablas externas que hagan referencia a los mismos orígenes de datos externos o a otros.
Limitaciones de ancho de tabla
El límite de ancho de fila de 1 MB se basa en el tamaño máximo de una sola fila válida por definición de tabla. Si la suma del esquema de columna es mayor que 1 MB, se producirá un error en las consultas de virtualización de datos.
Control de errores
Al ejecutar la CREATE EXTERNAL TABLE instrucción , si se produce un error en el intento de conexión, se produce un error en la instrucción y no se crea la tabla externa. El error en el comando puede tardar un minuto o más en producirse, ya que SQL Database reintenta la conexión antes de que se produzca un error en la consulta.
Limitaciones
Dado que los datos de una tabla externa no están bajo el control de administración directa del motor de base de datos o azure SQL Database, un proceso externo puede cambiarlos o quitarlos en cualquier momento. Como resultado, no se garantiza que los resultados de la consulta sobre una tabla externa sean deterministas. La misma consulta puede devolver resultados diferentes cada vez que se ejecute en una tabla externa. Del mismo modo, es posible que se produzca un error en una consulta si los datos externos se mueven o se quitan.
Puede crear varias tablas externas que hagan referencia a diferentes orígenes de datos externos.
En tablas externas solo se admiten estas instrucciones de lenguaje de definición de datos (DDL):
-
CREATE TABLEyDROP TABLE -
CREATE STATISTICSyDROP STATISTICS -
CREATE VIEWyDROP VIEW
Construcciones y operaciones no admitidas:
- Restricción
DEFAULTen columnas de tabla externa. - Operaciones de lenguaje de manipulación de datos (DML) delete, insert y update
Limitaciones con la consulta elástica
semántica de aislamiento: el acceso a los datos a través de una tabla externa no cumple la semántica de aislamiento dentro de SQL Server. Esto significa que la consulta de una tabla externa no impone ningún aislamiento de bloqueo o instantánea. Por lo tanto, la devolución de datos puede cambiar si cambian los datos del origen de datos externo. La misma consulta puede devolver resultados diferentes cada vez que se ejecute en una tabla externa. Del mismo modo, es posible que se produzca un error en una consulta si los datos externos se mueven o se quitan.
construcciones y operaciones no admitidas:
- Restricción
DEFAULTen columnas de tabla externa. - Operaciones de lenguaje de manipulación de datos (DML) delete, insert y update
- Enmascaramiento dinámico de datos en columnas de tabla externa.
- No se admiten cursores para tablas externas en Azure SQL Database.
- Restricción
Solo los predicados literales: solo los predicados literales definidos en una consulta se pueden insertar en el origen de datos externo. Esto es diferente de los servidores vinculados y el acceso a donde se pueden usar predicados determinados durante la ejecución de consultas, es decir, cuando se usa con un bucle anidado en un plan de consulta. Esto suele dar lugar a que toda la tabla externa se copie localmente y, a continuación, se una.
En el ejemplo siguiente, si
External.Orderses una tabla externa yCustomeres una tabla local, la consulta copia localmente toda la tabla externa porque el predicado necesario no se conoce en tiempo de compilación.SELECT Orders.OrderId, Orders.OrderTotal FROM External.Orders WHERE CustomerId IN ( SELECT TOP 1 CustomerId FROM Customer WHERE CustomerName = 'MyCompany' );sin paralelismo: el uso de tablas externas impide el uso del paralelismo en el plan de consulta.
Ejecutado como consulta remota: las tablas externas se implementan como consulta remota, por lo que el número estimado de filas devueltas suele ser 1000. Hay otras reglas basadas en el tipo de predicado usado para filtrar la tabla externa. Son estimaciones basadas en reglas en lugar de estimaciones basadas en los datos reales de la tabla externa. El optimizador no accede al origen de datos remoto para obtener una estimación más precisa.
No se admite para el punto de conexión privado: las consultas de tabla externa no se admiten cuando la conexión a la tabla remota es un punto de conexión privado.
Ejemplos
Para más ejemplos, consulta CREATE EXTERNAL DATA SOURCE o consulta Data virtualization with Azure SQL Database.
Un. Creación de una tabla externa para la consulta elástica
CREATE EXTERNAL TABLE [dbo].[CustomerInformation]
(
[CustomerID] INT NOT NULL,
[CustomerName] VARCHAR (50) NOT NULL,
[Company] VARCHAR (50) NOT NULL
)
WITH (
DATA_SOURCE = MyElasticDBQueryDataSrc
);
B. Crear una tabla externa para un origen de datos con particiones
En este ejemplo se vuelve a asignar una DMV remota a una tabla externa mediante las SCHEMA_NAME cláusulas y OBJECT_NAME .
CREATE EXTERNAL TABLE [dbo].[all_dm_exec_requests]
(
[session_id] SMALLINT NOT NULL,
[request_id] INT NOT NULL,
[start_time] DATETIME NOT NULL,
[status] NVARCHAR (30) NOT NULL,
[command] NVARCHAR (32) NOT NULL,
[sql_handle] VARBINARY (64),
[statement_start_offset] INT,
[statement_end_offset] INT,
[cpu_time] INT NOT NULL
)
WITH (
DATA_SOURCE = MyExtSrc,
SCHEMA_NAME = 'sys',
OBJECT_NAME = 'dm_exec_requests',
DISTRIBUTION = ROUND_ROBIN
);
C. Consulta de datos externos desde Azure SQL Database con una tabla externa
Para crear una credencial con ámbito de base de datos en Azure SQL Database, primero debe crear la clave maestra de base de datos, si aún no existe una. Se requiere una clave maestra de base de datos cuando la credencial requiere
SECRET.-- Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';Cree la credencial con ámbito de base de datos mediante un token de SAS. También puede usar una identidad administrada.
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>'; --Removing leading '?'Cree el origen de datos externo con la credencial.
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] );Cree y
EXTERNAL FILE FORMAT,EXTERNAL TABLEpara consultar los datos como si fuera una tabla local.-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE = PARQUET ); --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides ( vendorID VARCHAR (100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR (8000), doLocationId VARCHAR (8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR (8000), paymentType VARCHAR (8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR (8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( DATA_SOURCE = NYCTaxiExternalDataSource, LOCATION = 'yellow/puYear = */puMonth = */*.parquet', FILE_FORMAT = MyFileFormat ); --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides;
Contenido relacionado
* Azure Synapse
Análisis *
Introducción: Azure Synapse Analytics
Sugerencia
Microsoft Fabric Data Warehouse es un almacenamiento relacional de escala empresarial en una base de lago de datos, con una arquitectura lista para el futuro, inteligencia artificial integrada y nuevas características. Si no está familiarizado con el almacenamiento de datos, comience con Fabric Data Warehouse. Las cargas de trabajo del grupo dedicado de SQL pueden actualizarse a Fabric para acceder a funcionalidades avanzadas en ciencia de datos, análisis en tiempo real e informes.
Use una tabla externa para:
- Los grupos de SQL dedicados pueden consultar, importar y almacenar datos de Hadoop, Azure Blob Storage y Azure Data Lake Storage Gen1 y Gen2.
- Los grupos de SQL sin servidor pueden consultar, importar y almacenar datos de Azure Blob Storage y Azure Data Lake Storage Gen1 y Gen2. Sin servidor no admite
TYPE=Hadoop.
Consulte también CREATE EXTERNAL DATA SOURCE y DROP EXTERNAL TABLE.
Para más información y ejemplos sobre el uso de tablas externas con Azure Synapse, consulte Uso de tablas externas con Synapse SQL.
Sintaxis
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ ,...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath',
DATA_SOURCE = external_data_source_name,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ ,...n ] ]
)
[ ; ]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = { value | percentage },
| REJECT_VALUE = reject_value,
| REJECT_SAMPLE_VALUE = reject_sample_value,
| REJECTED_ROW_LOCATION = '/REJECT_Directory'
}
Argumentos
{ database_name.nombre_schema.nombre_de_tabla_| schema_name.nombre_de_tabla_table_name }
Nombre de entre una y tres partes de la tabla que se va a crear.
En una tabla externa, solo los metadatos de tabla junto con estadísticas básicas sobre el archivo o la carpeta a los que se hace referencia en Azure Data Lake, Hadoop o Azure Blob Storage. No se mueven ni almacenan datos reales cuando se crean tablas externas.
Importante
Para obtener el mejor rendimiento, si el controlador de origen de datos externo admite un nombre de tres partes, debe proporcionar el nombre de tres partes.
< > column_definition [ ,... n ]
CREATE EXTERNAL TABLE admite la capacidad de configurar el nombre de columna, el tipo de datos, la nulabilidad y la intercalación. No se puede usar DEFAULT CONSTRAINT en tablas externas.
Nota
Los tipos de datos text, ntext y xml no son tipos de datos admitidos para columnas en tablas externas para Synapse Analytics.
- Al leer archivos delimitados, las definiciones de columna, incluidos los tipos de datos y el número de columnas, deben coincidir con los datos de los archivos externos. Si hay un error de coincidencia, las filas de archivo se rechazan al consultar los datos reales.
- Al leer archivos con formato Parquet, solo puede especificar las columnas que desea leer y omitir el resto.
UBICACIÓN = 'folder_or_filepath'
Especifica la carpeta o la ruta y el nombre de archivo de los datos reales en Azure Data Lake, Hadoop o Azure Blob Storage. La ubicación empieza desde la carpeta raíz. La carpeta raíz es la ubicación de datos especificada en el origen de datos externo. La CREATE EXTERNAL TABLE AS SELECT instrucción (CETAS) crea la ruta y la carpeta si no existe.
CREATE EXTERNAL TABLE no crea la ruta de acceso y la carpeta.
Si especifica LOCATION que sea una carpeta, una consulta de PolyBase que selecciona de la tabla externa recupera los archivos de la carpeta y todas sus subcarpetas. Al igual que Hadoop, PolyBase no devuelve carpetas ocultas. Tampoco devuelve archivos para los que el nombre de archivo comienza con un subrayado (_) o un punto (.).
En el ejemplo de imagen siguiente, si LOCATION='/webdata/'es , una consulta de PolyBase devuelve filas de mydata.txt y mydata2.txt. No devuelve mydata3.txt porque está en una subcarpeta de una carpeta oculta y no devuelve _hidden.txt porque es un archivo oculto.
A diferencia de las tablas externas de Hadoop, las tablas externas nativas no devuelven subcarpetas a menos que especifique /** al final de la ruta de acceso. En este ejemplo, si LOCATION='/webdata/'es , una consulta de grupo de SQL sin servidor devuelve filas de mydata.txt. No devuelve mydata2.txt y mydata3.txt porque se encuentran en una subcarpeta. Las tablas de Hadoop devuelven todos los archivos dentro de cualquier subcarpeta.
Tanto Hadoop como las tablas externas nativas omiten los archivos con los nombres que comienzan por un subrayado (_) o un punto (.).
DATA_SOURCE = external_data_source_name
Especifica el nombre del origen de datos externo que contiene la ubicación donde se almacenan los datos externos. Esta ubicación se encuentra en Azure Data Lake. Para crear una fuente de datos externa, utiliza CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Especifica el nombre del objeto de formato de archivo externo que almacena el tipo de archivo y el método de compresión para los datos externos. Para crear un formato de archivo externo, use CREATE EXTERNAL FILE FORMAT.
OPCIONES DE TABLA
Especifica el conjunto de opciones que describen cómo leer los archivos subyacentes. Actualmente, la única disponible es {"READ_OPTIONS":["ALLOW_INCONSISTENT_READS"]}, que indica a la tabla externa que omita las actualizaciones que se realizan en los archivos subyacentes, aunque esto pueda provocar algunas operaciones de lectura incoherentes. Use esta opción solo en casos especiales en los que haya anexado archivos frecuentemente. Esta opción está disponible en el grupo de SQL sin servidor para el formato CSV.
Opciones de REJECT
Las opciones de Reject están en versión preliminar para los grupos de SQL sin servidor en Azure Synapse Analytics.
Esta opción solo se puede usar con orígenes de datos externos donde TYPE = HADOOP.
Puede especificar los parámetros reject que determinan cómo PolyBase controla los registros sucios que recupera del origen de datos externo. Un registro de datos se considera "desfasado" si los tipos de datos reales o el número de columnas no coinciden con las definiciones de columna de la tabla externa.
Si no se especifican ni se cambian los valores de Reject, PolyBase usa los valores predeterminados. Esta información sobre los parámetros reject se almacena como metadatos adicionales al crear una tabla externa con CREATE EXTERNAL TABLE la instrucción . Cuando una instrucción o SELECT instrucción futura SELECT INTO SELECT selecciona datos de la tabla externa, PolyBase usa las opciones de rechazo para determinar el número o porcentaje de filas que se pueden rechazar antes de que se produzca un error en la consulta real. La consulta devuelve (parcial) resultados hasta que se supera el umbral de rechazo. Después, se produce un error con el mensaje de error correspondiente.
La PARSER_VERSION opción de formato solo se admite en grupos de SQL sin servidor.
REJECT_TYPE = { valor | porcentaje }
Aclara si la REJECT_VALUE opción se especifica como un valor literal o un porcentaje.
valor
REJECT_VALUEes un valor literal, no un porcentaje. Se produce un error en la consulta de PolyBase cuando el número de filas rechazadas supera reject_value.Se produce un error en la consulta cuando el número de filas rechazadas supera reject_value. Por ejemplo, si
REJECT_VALUE = 5yREJECT_TYPE = value, se produce un error en la consulta de PolyBaseSELECTdespués de que se rechacen cinco filas.porcentaje
REJECT_VALUEes un porcentaje, no un valor literal. Se produce un error en una consulta de PolyBase cuando el porcentaje de filas con error supera reject_value. El porcentaje de filas con errores se calcula a intervalos.- Para
REJECT_TYPE = value, reject_value debe ser un entero entre 0 y 2.147.483.647. - Para
REJECT_TYPE = percentage, reject_value debe ser un valor float entre 0 y 100. El porcentaje solo es válido para grupos de SQL dedicados conTYPE = HADOOP.
- Para
REJECT_SAMPLE_VALUE = reject_sample_value
Este atributo es necesario cuando se especifica REJECT_TYPE = percentage. Determina el número de filas que se intentan recuperar antes de que PolyBase vuelva a calcular el porcentaje de filas rechazadas.
El parámetro reject_sample_value debe ser un entero comprendido entre 0 y 2.147.483.647.
Por ejemplo, si REJECT_SAMPLE_VALUE = 1000, PolyBase calcula el porcentaje de filas con errores después de intentar importar 1000 filas desde el archivo de datos externo. Si el porcentaje de filas con errores es menor que reject_value, PolyBase intenta recuperar otras 1000 filas. Sigue recalculando el porcentaje de filas con error después de intentar importar cada 1000 filas adicionales.
Nota
Puesto que PolyBase calcula el porcentaje de filas con errores a intervalos, el porcentaje real de filas con errores puede superar el valor de reject_value.
Ejemplo
En este ejemplo se muestra cómo interactúan las tres REJECT opciones entre sí. Por ejemplo, si REJECT_TYPE = percentage, REJECT_VALUE = 30y REJECT_SAMPLE_VALUE = 100, podría producirse el siguiente escenario:
- PolyBase intenta recuperar las 100 primeras filas; 25 no se importan y 75 sí.
- El porcentaje de las filas con errores se calcula en un 25 %, que es menor que el valor de rechazo de 30 %. Como resultado, PolyBase continúa recuperando datos del origen de datos externo.
- PolyBase intenta cargar las siguientes 100 filas; esta vez, 25 lo hacen y 75 no.
- El porcentaje de filas con errores se recalcula en un 50 %. El porcentaje de filas con errores supera pues el valor de rechazo de 30 %.
- Se produce un error en la consulta de PolyBase con un 50 % de filas rechazadas después de intentar devolver las 200 primeras filas. Las filas coincidentes se devuelven antes de que la consulta de PolyBase detecte que se ha superado el umbral de rechazo.
REJECTED_ROW_LOCATION = ubicación del directorio
Especifica el directorio del origen de datos externo en el que se deben escribir las filas rechazadas y el archivo de errores correspondiente.
Si la ruta de acceso especificada no existe, se crea. Se crea un directorio secundario con el nombre _rejectedrows. El carácter _ garantiza que se escape el directorio para otro procesamiento de datos, a menos que se mencione explícitamente en el parámetro de ubicación.
- En los grupos de SQL sin servidor, la ruta de acceso es
YearMonthDay_HourMinuteSecond_StatementID. Puede usarstatementIDpara correlacionar la carpeta con la consulta que la generó. - En los grupos de SQL dedicados, la ruta de acceso creada se basa en el tiempo de envío de carga en el formato
YearMonthDay -HourMinuteSecond; por ejemplo20180330-173205.
En esta carpeta, se escriben dos tipos de archivos: el archivo _reason y el archivo de datos.
Para obtener más información, consulte CREATE EXTERNAL DATA SOURCE.
Los archivos reason y los archivos de datos tienen el identificador de consulta asociado a la instrucción CTAS. Como los datos y los archivos reason están en archivos independientes, los archivos correspondientes tienen un sufijo coincidente.
En los grupos de SQL sin servidor, el archivo error.json contiene una matriz JSON con errores detectados relacionados con las filas rechazadas. Cada elemento que representa un error contiene los siguientes atributos:
| Atributo | Descripción |
|---|---|
Error |
Motivo por el que se rechaza la fila. |
Row |
Número ordinal de la fila rechazada en el archivo. |
Column |
Número ordinal de la columna rechazada. |
Value |
Valor de la columna rechazada. Si el valor es mayor que 100 caracteres, solo se muestran los primeros 100 caracteres. |
File |
Ruta de acceso al archivo al que pertenece la fila. |
Permisos
Requiere estos permisos de usuario:
CREATE TABLEALTER ANY SCHEMAALTER ANY EXTERNAL DATA SOURCEALTER ANY EXTERNAL FILE FORMAT-
CONTROL DATABASELos permisos son necesarios para crear solo la clave maestra, la credencial con ámbito de base de datos y el origen de datos externo.
El inicio de sesión remoto especificado en el DATABASE SCOPED CREDENTIAL usado en el CREATE EXTERNAL TABLE comando debe tener el permiso Read en la ruta de acceso especificada en el LOCATION parámetro . Si tiene previsto usar esta tabla externa para exportar datos a Azure Blob Storage o Azure Data Lake Storage, el inicio de sesión también debe tener permisos Write y List en la misma ruta de acceso.
Importante
El ALTER ANY EXTERNAL DATA SOURCE permiso concede a cualquier entidad de seguridad la capacidad de crear y modificar cualquier objeto de origen de datos externo y, por tanto, también concede la capacidad de acceder a todas las credenciales con ámbito de base de datos en la base de datos. Debe considerarse como un permiso con muchos privilegios, por lo que solo debe concederse a las entidades de seguridad de confianza del sistema.
Control de errores
Al ejecutar la instrucción CREATE EXTERNAL TABLE, PolyBase intenta conectarse al origen de datos externo. Si se produce un error en el intento de conexión, se produce un error en la instrucción y no se crea la tabla externa. El error en el comando puede tardar un minuto o más en producirse, ya que PolyBase vuelve a intentar conectar hasta que al final da como errónea la consulta.
Comentarios
En escenarios de consulta ad hoc, como SELECT FROM EXTERNAL TABLE, PolyBase almacena las filas que se recuperan del origen de datos externo en una tabla temporal. Una vez finalizada la consulta, PolyBase quita y elimina la tabla temporal. En las tablas SQL no se almacenan datos permanentes.
En cambio, en el escenario de importación, como SELECT INTO FROM EXTERNAL TABLE, PolyBase almacena las filas que se recuperan del origen de datos externo como datos permanentes en la tabla SQL. La tabla se crea durante la ejecución de la consulta cuando PolyBase recupera los datos externos.
PolyBase puede insertar algunos de los cálculos de la consulta en Hadoop para mejorar el rendimiento. Esta acción se conoce como aplicación de predicado. Para habilitarlo, especifica la opción de ubicación del gestor de recursos de Hadoop en CREATE EXTERNAL DATA SOURCE.
Puede crear varias tablas externas que hagan referencia a los mismos orígenes de datos externos o a otros.
Los grupos de SQL sin servidor y dedicados de Azure Synapse Analytics usan diferentes bases de código para la virtualización de datos. Los grupos de SQL sin servidor admiten una tecnología nativa de virtualización de datos. Los grupos de SQL dedicados admiten la virtualización de datos nativa y de PolyBase. La virtualización de datos de PolyBase se usa cuando EXTERNAL DATA SOURCE se crea con TYPE=HADOOP.
Limitaciones
Dado que los datos de una tabla externa no están bajo el control de administración directa de Azure Synapse, un proceso externo puede cambiarlos o quitarlos en cualquier momento. Como resultado, no se garantiza que los resultados de la consulta sobre una tabla externa sean deterministas. La misma consulta puede devolver resultados diferentes cada vez que se ejecute en una tabla externa. Del mismo modo, es posible que se produzca un error en una consulta si los datos externos se mueven o se quitan.
Las tablas externas no admiten datos de origen con intercalaciones UTF-8. Si los datos de origen usan la intercalación UTF-8, debe asignar explícitamente una intercalación que no sea UTF-8 a cada columna UTF-8 de la CREATE EXTERNAL TABLE instrucción . Si no lo hace, se produce un mensaje de error similar al siguiente resultado:
Msg 105105, Level 16, State 1, Line 22
105105;No column collation was specified in external table definition and the collation of current database 'Latin1_General_100_CI_AS_SC_UTF8' is not supported for external tables of type 'HADOOP'. Please specify a supported collation in the column definition.
Si la intercalación de base de datos de la tabla externa es UTF-8, se produce un error en la creación de la tabla a menos que cada columna se defina explícitamente con una intercalación que no sea UTF-8 (por ejemplo, [UTF8_column] VARCHAR(128) COLLATE LATIN1_GENERAL_100_CI_AS_KS_WS NOT NULL).
Puede crear varias tablas externas que hagan referencia a diferentes orígenes de datos externos.
En tablas externas solo se admiten estas instrucciones de lenguaje de definición de datos (DDL):
-
CREATE TABLEyDROP TABLE -
CREATE STATISTICSyDROP STATISTICS -
CREATE VIEWyDROP VIEW
Construcciones y operaciones no admitidas:
- Restricción
DEFAULTen columnas de tabla externa - Operaciones de lenguaje de manipulación de datos (DML) delete, insert y update
- Enmascaramiento dinámico de datos en columnas de tabla externa
Limitaciones de las consultas
Se recomienda no superar más de 30 000 archivos por carpeta. Cuando se hace referencia a demasiados archivos, es posible que se produzca una excepción de memoria insuficiente (JVM) de una máquina virtual Java o que el rendimiento se pueda degradar.
Limitaciones de ancho de tabla
PolyBase en Azure Data Warehouse tiene un límite de ancho de fila de 1 MB, en función del tamaño máximo de una sola fila válida por definición de tabla. Si la suma del esquema de columnas es superior a 1 MB, PolyBase no puede consultar los datos.
Limitaciones de tipos de datos
Los siguientes tipos de datos no se pueden usar en tablas externas de PolyBase:
- geography
- de geometría
- hierarchyid
- de imagen
- de texto
- contexto
- xml de
- Cualquier tipo definido por el usuario
Bloqueo
Bloqueo compartido en el SCHEMARESOLUTION objeto .
Ejemplos
Un. Importación de datos de ADLS Gen 2 en Azure Synapse Analytics
Para ver ejemplos de ADLS Gen 1, consulte Crear origen de datos externos.
-- These values come from your Azure Active Directory Application used to authenticate to ADLS Gen 2.
CREATE DATABASE SCOPED CREDENTIAL ADLUser
WITH
IDENTITY = '<clientID>@\<OAuth2.0TokenEndPoint>',
SECRET = '<KEY>';
GO
CREATE EXTERNAL DATA SOURCE AzureDataLakeStore
WITH (
TYPE = HADOOP,
LOCATION = 'abfss://data@pbasetr.azuredatalakestore.net'
);
GO
CREATE EXTERNAL FILE FORMAT TextFileFormat
WITH (
FORMAT_TYPE = DELIMITEDTEXT,
FORMAT_OPTIONS (
FIELD_TERMINATOR = '|',
STRING_DELIMITER = '',
DATE_FORMAT = 'yyyy-MM-dd HH:mm:ss.fff',
USE_TYPE_DEFAULT = FALSE
)
);
GO
CREATE EXTERNAL TABLE [dbo].[DimProduct_external]
(
[ProductKey] INT NOT NULL,
[ProductLabel] NVARCHAR NULL,
[ProductName] NVARCHAR NULL
)
WITH (
DATA_SOURCE = AzureDataLakeStore,
LOCATION = '/DimProduct/',
FILE_FORMAT = TextFileFormat,
REJECT_TYPE = value,
REJECT_VALUE = 0
);
GO
CREATE TABLE [dbo].[DimProduct]
WITH (DISTRIBUTION = HASH([ProductKey])) AS
GO
SELECT *
FROM [dbo].[DimProduct_external];
B. Importación de datos de Parquet en Azure Synapse Analytics
En el ejemplo siguiente se crea una tabla externa. Devuelve la primera fila:
CREATE EXTERNAL TABLE census_external_table
(
decennialTime VARCHAR (20),
stateName VARCHAR (100),
countyName VARCHAR (100),
population INT,
race VARCHAR (50),
sex VARCHAR (10),
minAge INT,
maxAge INT
)
WITH (
DATA_SOURCE = population_ds,
LOCATION = '/parquet/',
FILE_FORMAT = census_file_format
);
GO
SELECT TOP 1 *
FROM census_external_table;
Contenido relacionado
*Analítica
Sistema de plataforma (PDW) *
Introducción: Sistema de la plataforma de análisis
Use una tabla externa para:
- Consultar datos de Hadoop o Azure Blob Storage con instrucciones de Transact-SQL.
- Importar datos de Hadoop o Azure Blob Storage y almacenarlos en Analytics Platform System.
Consulte también CREATE EXTERNAL DATA SOURCE y DROP EXTERNAL TABLE.
Sintaxis
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ , ...n ] )
WITH (
LOCATION = 'hdfs_folder_or_filepath' ,
DATA_SOURCE = external_data_source_name ,
FILE_FORMAT = external_file_format_name
[ , <reject_options> [ , ...n ] ]
)
[ ; ]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
<reject_options> ::=
{
| REJECT_TYPE = { value | percentage },
| REJECT_VALUE = reject_value ,
| REJECT_SAMPLE_VALUE = reject_sample_value ,
}
Argumentos
{ database_name.nombre_schema.nombre_de_tabla_| schema_name.nombre_de_tabla_table_name }
Nombre de entre una y tres partes de la tabla que se va a crear.
En una tabla externa, Analytics Platform System solo almacena los metadatos de tabla junto con estadísticas básicas sobre el archivo o carpeta a los que se hace referencia en Hadoop o Azure Blob Storage. Ningún dato real se mueve o se almacena en Analytics Platform System.
Importante
Para obtener el mejor rendimiento, si el controlador de origen de datos externo admite un nombre de tres partes, debe proporcionar el nombre de tres partes.
< > column_definition [ ,... n ]
CREATE EXTERNAL TABLE admite la capacidad de configurar el nombre de columna, el tipo de datos, la nulabilidad y la intercalación. No se puede usar DEFAULT CONSTRAINT en tablas externas.
Las definiciones de columna, incluidos los tipos de datos y el número de columnas, deben coincidir con los datos de los archivos externos. Si hay un error de coincidencia, las filas de archivo se rechazan al consultar los datos reales.
UBICACIÓN = 'folder_or_filepath'
Especifica la carpeta o la ruta de acceso y el nombre de archivo para los datos en Hadoop o Azure Blob Storage. La ubicación empieza desde la carpeta raíz. La carpeta raíz es la ubicación de datos especificada en el origen de datos externo.
En Analytics Platform System, la CREATE EXTERNAL TABLE AS SELECT instrucción (CETAS) crea la ruta y la carpeta si no existen.
CREATE EXTERNAL TABLE no crea la ruta de acceso y la carpeta.
Si especifica LOCATION que sea una carpeta, una consulta de PolyBase que selecciona de la tabla externa recupera los archivos de la carpeta y todas sus subcarpetas. Al igual que Hadoop, PolyBase no devuelve carpetas ocultas. Tampoco devuelve archivos para los que el nombre de archivo comienza con un subrayado (_) o un punto (.).
En el ejemplo de imagen siguiente, si LOCATION='/webdata/'es , una consulta de PolyBase devuelve filas de mydata.txt y mydata2.txt. No devuelve mydata3.txt porque está en una subcarpeta de una carpeta oculta y no devuelve _hidden.txt porque es un archivo oculto.
Para cambiar el valor predeterminado y leer solo de la carpeta raíz, establezca el atributo <polybase.recursive.traversal> en "false" en el archivo de configuración core-site.xml. Este archivo se encuentra en <SqlBinRoot>\PolyBase\Hadoop\Conf\ bajo el bin raíz de SQL Server. Por ejemplo, C:\Program Files\Microsoft SQL Server\MSSQL13.XD14\MSSQL\Binn\.
DATA_SOURCE = external_data_source_name
Especifica el nombre del origen de datos externo que contiene la ubicación donde se almacenan los datos externos. Esta ubicación es Hadoop o Azure Blob Storage. Para crear una fuente de datos externa, utiliza CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Especifica el nombre del objeto de formato de archivo externo que almacena el tipo de archivo y el método de compresión para los datos externos. Para crear un formato de archivo externo, use CREATE EXTERNAL FILE FORMAT.
Opciones de REJECT
Esta opción solo se puede usar con orígenes de datos externos donde TYPE = HADOOP.
Puede especificar los parámetros reject que determinan cómo PolyBase controla los registros sucios que recupera del origen de datos externo. Un registro de datos se considera "desfasado" si los tipos de datos reales o el número de columnas no coinciden con las definiciones de columna de la tabla externa.
Si no se especifican ni se cambian los valores de Reject, PolyBase usa los valores predeterminados. Esta información sobre los parámetros reject se almacena como metadatos adicionales al crear una tabla externa con CREATE EXTERNAL TABLE la instrucción . Cuando una instrucción o SELECT instrucción futura SELECT INTO SELECT selecciona datos de la tabla externa, PolyBase usa las opciones de rechazo para determinar el número o porcentaje de filas que se pueden rechazar antes de que se produzca un error en la consulta real. La consulta devuelve (parcial) resultados hasta que se supera el umbral de rechazo. Después, se produce un error con el mensaje de error correspondiente.
REJECT_TYPE = { valor | porcentaje }
Aclara si la REJECT_VALUE opción se especifica como un valor literal o un porcentaje.
valor
REJECT_VALUEes un valor literal, no un porcentaje. Se produce un error en la consulta de PolyBase cuando el número de filas rechazadas supera reject_value.Por ejemplo, si
REJECT_VALUE = 5yREJECT_TYPE = value, se produce un error en la consulta de PolyBaseSELECTdespués de que se rechacen cinco filas.porcentaje
REJECT_VALUEes un porcentaje, no un valor literal. Se produce un error en una consulta de PolyBase cuando el porcentaje de filas con error supera reject_value. El porcentaje de filas con errores se calcula a intervalos.
REJECT_VALUE = reject_value
Especifica el valor o el porcentaje de filas que se pueden rechazar antes de que se produzca un error en la consulta.
Para REJECT_TYPE = value, reject_value debe ser un entero entre 0 y 2.147.483.647.
Para REJECT_TYPE = percentage, reject_value debe ser un valor float entre 0 y 100.
REJECT_SAMPLE_VALUE = reject_sample_value
Este atributo es necesario cuando se especifica REJECT_TYPE = percentage. Determina el número de filas que se intentan recuperar antes de que PolyBase vuelva a calcular el porcentaje de filas rechazadas.
El parámetro reject_sample_value debe ser un entero comprendido entre 0 y 2.147.483.647.
Por ejemplo, si REJECT_SAMPLE_VALUE = 1000, PolyBase calcula el porcentaje de filas con errores después de intentar importar 1000 filas desde el archivo de datos externo. Si el porcentaje de filas con errores es menor que reject_value, PolyBase intenta recuperar otras 1000 filas. Sigue recalculando el porcentaje de filas con error después de intentar importar cada 1000 filas adicionales.
Nota
Puesto que PolyBase calcula el porcentaje de filas con errores a intervalos, el porcentaje real de filas con errores puede superar el valor de reject_value.
Ejemplo
En este ejemplo se muestra cómo interactúan las tres REJECT opciones entre sí. Por ejemplo, si REJECT_TYPE = percentage, REJECT_VALUE = 30y REJECT_SAMPLE_VALUE = 100, podría producirse el siguiente escenario:
- PolyBase intenta recuperar las 100 primeras filas; 25 no se importan y 75 sí.
- El porcentaje de las filas con errores se calcula en un 25 %, que es menor que el valor de rechazo de 30 %. Como resultado, PolyBase continúa recuperando datos del origen de datos externo.
- PolyBase intenta cargar las siguientes 100 filas; esta vez, 25 lo hacen y 75 no.
- El porcentaje de filas con errores se recalcula en un 50 %. El porcentaje de filas con errores supera pues el valor de rechazo de 30 %.
- Se produce un error en la consulta de PolyBase con un 50 % de filas rechazadas después de intentar devolver las 200 primeras filas. Las filas coincidentes se devuelven antes de que la consulta de PolyBase detecte que se ha superado el umbral de rechazo.
Permisos
Requiere estos permisos de usuario:
CREATE TABLEALTER ANY SCHEMAALTER ANY EXTERNAL DATA SOURCEALTER ANY EXTERNAL FILE FORMATCONTROL DATABASE
El inicio de sesión que crea el origen de datos externo debe tener permiso para leer y escribir en el origen de datos externo, ubicado en Hadoop o Azure Blob Storage.
Importante
El ALTER ANY EXTERNAL DATA SOURCE permiso concede a cualquier entidad de seguridad la capacidad de crear y modificar cualquier objeto de origen de datos externo y, por tanto, también concede la capacidad de acceder a todas las credenciales con ámbito de base de datos en la base de datos. Debe considerarse como un permiso con muchos privilegios, por lo que solo debe concederse a las entidades de seguridad de confianza del sistema.
Control de errores
Al ejecutar la instrucción CREATE EXTERNAL TABLE, PolyBase intenta conectarse al origen de datos externo. Si se produce un error en el intento de conexión, se produce un error en la instrucción y no se crea la tabla externa. El error en el comando puede tardar un minuto o más en producirse, ya que PolyBase vuelve a intentar conectar hasta que al final da como errónea la consulta.
Comentarios
En escenarios de consulta ad hoc, como SELECT FROM EXTERNAL TABLE, PolyBase almacena las filas que se recuperan del origen de datos externo en una tabla temporal. Una vez finalizada la consulta, PolyBase quita y elimina la tabla temporal. En las tablas SQL no se almacenan datos permanentes.
En cambio, en el escenario de importación, como SELECT INTO FROM EXTERNAL TABLE, PolyBase almacena las filas que se recuperan del origen de datos externo como datos permanentes en la tabla SQL. La tabla se crea durante la ejecución de la consulta cuando PolyBase recupera los datos externos.
PolyBase puede insertar algunos de los cálculos de la consulta en Hadoop para mejorar el rendimiento. Esta acción se conoce como aplicación de predicado. Para habilitarlo, especifica la opción de ubicación del gestor de recursos de Hadoop en CREATE EXTERNAL DATA SOURCE.
Puede crear varias tablas externas que hagan referencia a los mismos orígenes de datos externos o a otros.
Limitaciones
Dado que los datos de una tabla externa no están bajo el control de administración directa del dispositivo, se pueden cambiar o quitar en cualquier momento mediante un proceso externo. Como resultado, no se garantiza que los resultados de la consulta sobre una tabla externa sean deterministas. La misma consulta puede devolver resultados diferentes cada vez que se ejecute en una tabla externa. Del mismo modo, es posible que se produzca un error en una consulta si los datos externos se mueven o se quitan.
Puede crear varias tablas externas que hagan referencia a diferentes orígenes de datos externos. Si ejecuta consultas de forma simultánea sobre otros orígenes de datos de Hadoop, cada uno tendrá que usar el mismo valor de configuración de servidor "hadoop connectivity". Por ejemplo, no se puede ejecutar simultáneamente una consulta en un clúster de Cloudera Hadoop y un clúster de Hortonworks Hadoop, ya que usan valores de configuración diferentes. Para conocer los valores de configuración y las combinaciones admitidas, consulte Configuración de conectividad de PolyBase.
En tablas externas solo se admiten estas instrucciones de lenguaje de definición de datos (DDL):
-
CREATE TABLEyDROP TABLE -
CREATE STATISTICSyDROP STATISTICS -
CREATE VIEWyDROP VIEW
Construcciones y operaciones no admitidas:
- Restricción
DEFAULTen columnas de tabla externa - Operaciones de lenguaje de manipulación de datos (DML) delete, insert y update
- Enmascaramiento dinámico de datos en columnas de tabla externa
Limitaciones de las consultas
PolyBase puede consumir un máximo de 33 000 archivos por carpeta cuando se ejecutan 32 consultas simultáneas de PolyBase. Esta cifra máxima engloba los archivos y las subcarpetas de cada carpeta de HDFS. Si el grado de simultaneidad es inferior a 32, un usuario puede ejecutar consultas de PolyBase en carpetas de HDFS que contengan más de 33 000 archivos. Se recomienda tener unas rutas de acceso de archivos externos cortas y no usar más de 30.000 archivos por carpeta de HDFS. Si hay referencias a demasiados archivos, podría producirse una excepción de memoria insuficiente de Máquina virtual Java (JVM).
Limitaciones de ancho de tabla
En SQL Server 2016 (13.x), PolyBase tiene un límite de ancho de fila de 32 KB en función del tamaño máximo de una sola fila válida por definición de tabla. Si la suma del esquema de columnas es superior a 32 KB, PolyBase no puede consultar los datos.
En Azure Synapse Analytics, esta limitación se ha elevado a 1 MB.
Limitaciones de tipos de datos
Los siguientes tipos de datos no se pueden usar en tablas externas de PolyBase:
- geography
- de geometría
- hierarchyid
- de imagen
- de texto
- contexto
- xml de
- Cualquier tipo definido por el usuario
Bloqueo
Bloqueo compartido en el SCHEMARESOLUTION objeto .
Seguridad
Los archivos de datos de una tabla externa se almacenan en Hadoop o Azure Blob Storage. Son sus propios procesos los que crean y administran estos archivos de datos. Es su responsabilidad administrar la seguridad de los datos externos.
Ejemplos
Un. Combinar datos HDFS con datos de Analytics Platform System
SELECT cs.user_ip
FROM ClickStream AS cs
INNER JOIN [User] AS u
ON cs.user_ip = u.user_ip
WHERE cs.url = 'www.microsoft.com';
B. Importar datos de filas de HDFS en una tabla distribuida de Analytics Platform System
CREATE TABLE ClickStream_PDW
WITH (DISTRIBUTION = HASH(url)) AS
SELECT url,
event_date,
user_ip
FROM ClickStream;
C. Importar datos de filas de HDFS en una tabla replicada de Analytics Platform System
CREATE TABLE ClickStream_PDW
WITH (DISTRIBUTION = REPLICATE) AS
SELECT url,
event_date,
user_ip
FROM ClickStream;
Contenido relacionado
* Instancia administrada de Azure SQL *
Introducción: Instancia administrada de Azure SQL
Crea una tabla de datos externa de Azure SQL Managed Instance. Para obtener información completa, consulte Virtualización de datos con Azure SQL Managed Instance.
La virtualización de datos en Azure SQL Managed Instance proporciona acceso a datos externos en varios formatos de archivo en Azure Data Lake Storage Gen2 o Azure Blob Storage, y para consultarlos con instrucciones T-SQL, incluso combinar datos con datos relacionales almacenados localmente mediante combinaciones.
Consulte también CREATE EXTERNAL DATA SOURCE y DROP EXTERNAL TABLE.
Sintaxis
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ , ...n ] )
WITH (
LOCATION = 'filepath' ,
DATA_SOURCE = external_data_source_name ,
FILE_FORMAT = external_file_format_name
)
[ ; ]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argumentos
{ database_name.nombre_schema.nombre_de_tabla_| schema_name.nombre_de_tabla_table_name }
Nombre de entre una y tres partes de la tabla que se va a crear.
En una tabla externa, solo los metadatos de tabla junto con estadísticas básicas sobre el archivo o la carpeta a los que se hace referencia en Azure Data Lake o Azure Blob Storage. No se mueven ni almacenan datos reales cuando se crean tablas externas.
Importante
Para obtener el mejor rendimiento, si el controlador de origen de datos externo admite un nombre de tres partes, debe proporcionar el nombre de tres partes.
< > column_definition [ ,... n ]
CREATE EXTERNAL TABLE admite la capacidad de configurar el nombre de columna, el tipo de datos, la nulabilidad y la intercalación. No se puede usar DEFAULT CONSTRAINT en tablas externas.
Las definiciones de columna, incluidos los tipos de datos y el número de columnas, deben coincidir con los datos de los archivos externos. Si hay un error de coincidencia, las filas de archivo se rechazan al consultar los datos reales.
UBICACIÓN = 'folder_or_filepath'
Especifica la carpeta o la ruta al archivo y el nombre de archivo de los datos reales en Azure Data Lake o Azure Blob Storage. La ubicación empieza desde la carpeta raíz. La carpeta raíz es la ubicación de datos especificada en el origen de datos externo.
CREATE EXTERNAL TABLE no crea la ruta de acceso y la carpeta.
Si especifica LOCATION que sea una carpeta, la consulta de Azure SQL Managed Instance que selecciona de la tabla externa recupera los archivos de la carpeta, pero no todas sus subcarpetas.
Azure SQL Managed Instance no puede encontrar archivos en subcarpetas ni carpetas ocultas. Tampoco devuelve archivos para los que el nombre de archivo comienza con un subrayado (_) o un punto (.).
En el ejemplo de imagen siguiente, si LOCATION='/webdata/'es , una consulta devuelve filas de mydata.txt. No devuelve mydata2.txt porque está en una subcarpeta, no devuelve mydata3.txt porque está en una carpeta oculta y no devuelve _hidden.txt porque es un archivo oculto.
DATA_SOURCE = external_data_source_name
Especifica el nombre del origen de datos externo que contiene la ubicación donde se almacenan los datos externos. Esta ubicación se encuentra en Azure Data Lake. Para crear una fuente de datos externa, utiliza CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Especifica el nombre del objeto de formato de archivo externo que almacena el tipo de archivo y el método de compresión para los datos externos. Para crear un formato de archivo externo, use CREATE EXTERNAL FILE FORMAT.
Permisos
Requiere estos permisos de usuario:
CREATE TABLEALTER ANY SCHEMAALTER ANY EXTERNAL DATA SOURCEALTER ANY EXTERNAL FILE FORMAT-
CONTROL DATABASELos permisos son necesarios para crear solo la clave maestra, la credencial con ámbito de base de datos y el origen de datos externo.
El inicio de sesión que crea el origen de datos externo debe tener permiso para leer y escribir en el origen de datos externo, ubicado en Hadoop o Azure Blob Storage.
Importante
El ALTER ANY EXTERNAL DATA SOURCE permiso concede a cualquier entidad de seguridad la capacidad de crear y modificar cualquier objeto de origen de datos externo y, por tanto, también concede la capacidad de acceder a todas las credenciales con ámbito de base de datos en la base de datos. Debe considerarse como un permiso con muchos privilegios, por lo que solo debe concederse a las entidades de seguridad de confianza del sistema.
Comentarios
En escenarios de consulta ad hoc, como SELECT FROM EXTERNAL TABLE, las filas que se recuperan del origen de datos externo se almacenan en una tabla temporal. Una vez completada la consulta, se quitan las filas y se elimina la tabla temporal. En las tablas SQL no se almacenan datos permanentes.
En cambio, en el escenario de importación, como SELECT INTO FROM EXTERNAL TABLE, las filas que se recuperan del origen de datos externo se almacenan como datos permanentes en la tabla SQL. La tabla se crea durante la ejecución de la consulta cuando se recuperan los datos externos.
Actualmente, la virtualización de datos con Azure SQL Managed Instance es de solo lectura.
Puede crear varias tablas externas que hagan referencia a los mismos orígenes de datos externos o a otros.
Limitaciones
Dado que los datos de una tabla externa no están bajo el control de administración directa de Azure SQL Managed Instance, un proceso externo puede cambiarlos o quitarlos en cualquier momento. Como resultado, no se garantiza que los resultados de la consulta sobre una tabla externa sean deterministas. La misma consulta puede devolver resultados diferentes cada vez que se ejecute en una tabla externa. Del mismo modo, es posible que se produzca un error en una consulta si los datos externos se mueven o se quitan.
Puede crear varias tablas externas que hagan referencia a diferentes orígenes de datos externos.
En tablas externas solo se admiten estas instrucciones de lenguaje de definición de datos (DDL):
-
CREATE TABLEyDROP TABLE -
CREATE STATISTICSyDROP STATISTICS -
CREATE VIEWyDROP VIEW
Construcciones y operaciones no admitidas:
- Restricción
DEFAULTen columnas de tabla externa - Operaciones de lenguaje de manipulación de datos (DML) delete, insert y update
Limitaciones de ancho de tabla
El límite de ancho de fila de 1 MB se basa en el tamaño máximo de una sola fila válida por definición de tabla. Si la suma del esquema de columna es mayor que 1 MB, se producirá un error en las consultas de virtualización de datos.
Limitaciones de tipos de datos
Los siguientes tipos de datos no se pueden usar en tablas externas de Azure SQL Managed Instance:
- geography
- de geometría
- hierarchyid
- de imagen
- de texto
- contexto
- xml de
- json
- Cualquier tipo definido por el usuario
Bloqueo
Bloqueo compartido en el SCHEMARESOLUTION objeto .
Ejemplos
Un. Consulta de datos externos de Azure SQL Managed Instance con una tabla externa
Para más ejemplos, consulta CREATE EXTERNAL DATA SOURCE o consulta Virtualización de datos con Azure SQL Managed Instance.
Cree la clave maestra de la base de datos, si no existe.
-- Optional: Create MASTER KEY if it doesn't exist in the database: CREATE MASTER KEY ENCRYPTION BY PASSWORD = '<password>';Cree la credencial con ámbito de base de datos mediante un token de SAS. También puede usar una identidad administrada.
CREATE DATABASE SCOPED CREDENTIAL MyCredential WITH IDENTITY = 'SHARED ACCESS SIGNATURE', SECRET = '<KEY>'; --Removing leading '?'Cree el origen de datos externo con la credencial.
--Create external data source pointing to the file path, and referencing database-scoped credential: CREATE EXTERNAL DATA SOURCE MyPrivateExternalDataSource WITH ( LOCATION = 'abs://public@pandemicdatalake.blob.core.windows.net/curated/covid-19/bing_covid-19_data/latest' CREDENTIAL = [MyCredential] );Cree y
EXTERNAL FILE FORMAT,EXTERNAL TABLEpara consultar los datos como si fuera una tabla local.-- Or, create an EXTERNAL FILE FORMAT and an EXTERNAL TABLE --Create external file format CREATE EXTERNAL FILE FORMAT DemoFileFormat WITH ( FORMAT_TYPE = PARQUET ); --Create external table: CREATE EXTERNAL TABLE tbl_TaxiRides ( vendorID VARCHAR (100) COLLATE Latin1_General_BIN2, tpepPickupDateTime DATETIME2, tpepDropoffDateTime DATETIME2, passengerCount INT, tripDistance FLOAT, puLocationId VARCHAR (8000), doLocationId VARCHAR (8000), startLon FLOAT, startLat FLOAT, endLon FLOAT, endLat FLOAT, rateCodeId SMALLINT, storeAndFwdFlag VARCHAR (8000), paymentType VARCHAR (8000), fareAmount FLOAT, extra FLOAT, mtaTax FLOAT, improvementSurcharge VARCHAR (8000), tipAmount FLOAT, tollsAmount FLOAT, totalAmount FLOAT ) WITH ( DATA_SOURCE = NYCTaxiExternalDataSource, LOCATION = 'yellow/puYear = */puMonth = */*.parquet', FILE_FORMAT = MyFileFormat ); --Then, query the data via an external table with T-SQL: SELECT TOP 10 * FROM tbl_TaxiRides;
Contenido relacionado
Obtenga más información sobre las tablas externas y los conceptos relacionados en los artículos siguientes:
Información general: Microsoft Fabric
Se aplica a: Almacenamiento de datos de Microsoft Fabric
Para obtener más información y ejemplos para OPENROWSET en Fabric Data Warehouse, consulte:
* Base de datos SQL Fabric *
Resumen: Base de datos SQL en Microsoft Fabric
Crea una tabla externa.
Para su uso con virtualización de datos (versión preliminar).
Sintaxis
CREATE EXTERNAL TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
( <column_definition> [ , ...n ] )
WITH (
LOCATION = 'filepath' ,
DATA_SOURCE = external_data_source_name ,
FILE_FORMAT = external_file_format_name
)
[ ; ]
<column_definition> ::=
column_name <data_type>
[ COLLATE collation_name ]
[ NULL | NOT NULL ]
Argumentos
{ database_name.nombre_schema.nombre_de_tabla_| schema_name.nombre_de_tabla_table_name }
Nombre de entre una y tres partes de la tabla que se va a crear.
Para una tabla externa, SQL almacena solo los metadatos de la tabla junto con estadísticas básicas sobre el archivo o la carpeta. No se mueven ni almacenan datos reales en la base de datos SQL de Fabric cuando se crean tablas externas.
Importante
Para obtener el mejor rendimiento, si el controlador de origen de datos externo admite un nombre de tres partes, debe proporcionar el nombre de tres partes.
< > column_definition [ ,... n ]
CREATE EXTERNAL TABLE admite la capacidad de configurar el nombre de columna, el tipo de datos, la nulabilidad y la intercalación. No se puede usar DEFAULT CONSTRAINT en tablas externas. Estos tipos de datos no se admiten para las columnas de tablas externas:
- geography
- de geometría
- hierarchyid
- de imagen
- de texto
- contexto
- xml de
- json
- Cualquier tipo definido por el usuario
Las definiciones de columna, incluidos los tipos de datos y el número de columnas, deben coincidir con los datos de los archivos externos. Si hay un error de coincidencia, las filas de archivo se rechazan al consultar los datos reales.
UBICACIÓN = 'folder_or_filepath'
Especifica la carpeta o la ruta de acceso del archivo y el nombre de archivo de los datos reales de OneLake en Microsoft Fabric.
DATA_SOURCE
DATA_SOURCE especifica el nombre del origen de datos externo que contiene la ubicación de los datos externos. Para crear una fuente de datos externa, utiliza CREATE EXTERNAL DATA SOURCE.
FILE_FORMAT = external_file_format_name
Especifica el nombre del objeto de formato de archivo externo que almacena el tipo de archivo y el método de compresión para los datos externos. Para crear un formato de archivo externo, use CREATE EXTERNAL FILE FORMAT.
Permisos
Los usuarios con acceso a la tabla externa obtienen automáticamente acceso a las tablas remotas subyacentes con la credencial proporcionada en la definición del origen de datos externo. Evite la elevación no deseada de privilegios a través de la credencial del origen de datos externo. Use GRANT o REVOKE para una tabla externa como si fuera una tabla normal. Una vez que defina el origen de datos externo y las tablas externas, puede usar el T-SQL completo en las tablas externas.
CREATE EXTERNAL TABLE requiere estos permisos de usuario:
CREATE TABLEALTER ANY SCHEMAALTER ANY EXTERNAL DATA SOURCEALTER ANY EXTERNAL FILE FORMAT-
CONTROL DATABASELos permisos son necesarios para crear solo la clave maestra, la credencial con ámbito de base de datos y el origen de datos externo.
El inicio de sesión que crea el origen de datos externo debe tener permiso para leer y escribir en el origen de datos externo, ubicado en Hadoop o Azure Blob Storage.
Importante
El ALTER ANY EXTERNAL DATA SOURCE permiso concede a cualquier entidad de seguridad la capacidad de crear y modificar cualquier objeto de origen de datos externo y, por tanto, también concede la capacidad de acceder a todas las credenciales con ámbito de base de datos en la base de datos. Debe considerarse como un permiso con muchos privilegios, por lo que solo debe concederse a las entidades de seguridad de confianza del sistema.
Bloqueo
Bloqueo compartido en el SCHEMARESOLUTION objeto .
Comentarios
En escenarios de consulta ad hoc, como SELECT FROM EXTERNAL TABLE, las filas que se recuperan del origen de datos externo se almacenan en una tabla temporal. Una vez completada la consulta, se quitan las filas y se elimina la tabla temporal. En las tablas SQL no se almacenan datos permanentes.
En cambio, en el escenario de importación, como SELECT INTO FROM EXTERNAL TABLE, las filas que se recuperan del origen de datos externo se almacenan como datos permanentes en la tabla SQL. La tabla se crea durante la ejecución de la consulta cuando se recuperan los datos externos.
La base de datos SQL de Fabric solo soporta OneLake en Microsoft Fabric como fuente de datos.
Puede crear varias tablas externas que hagan referencia a los mismos orígenes de datos externos o a otros.
Limitaciones de ancho de tabla
El límite de ancho de fila de 1 MB se basa en el tamaño máximo de una sola fila válida por definición de tabla. Si la suma del esquema de columna es mayor que 1 MB, se producirá un error en las consultas de virtualización de datos.
Control de errores
Al ejecutar la CREATE EXTERNAL TABLE instrucción , si se produce un error en el intento de conexión, se produce un error en la instrucción y no se crea la tabla externa. El error en el comando puede tardar un minuto o más en producirse, ya que SQL Database reintenta la conexión antes de que se produzca un error en la consulta.
Limitaciones
Actualmente, al crear tablas externas que apuntan a un archivo CSV en la base de datos SQL de Fabric, debe proporcionar el esquema de tabla, por ejemplo: SELECT * FROM [schema].[table_name]. De lo contrario, se muestra el siguiente mensaje de error:
Msg 208, Level 16, State 160, Line 1: Invalid object name 'SQLdatabase-id'
Dado que los datos de una tabla externa no están bajo el control de administración directa del motor de base de datos, se pueden cambiar o quitar en cualquier momento mediante un proceso externo. Como resultado, no se garantiza que los resultados de la consulta sobre una tabla externa sean deterministas. La misma consulta puede devolver resultados diferentes cada vez que se ejecute en una tabla externa. Del mismo modo, es posible que se produzca un error en una consulta si los datos externos se mueven o se quitan.
Puede crear varias tablas externas que hagan referencia a diferentes orígenes de datos externos.
En tablas externas solo se admiten estas instrucciones de lenguaje de definición de datos (DDL):
-
CREATE TABLEyDROP TABLE -
CREATE STATISTICSyDROP STATISTICS -
CREATE VIEWyDROP VIEW
Construcciones y operaciones no admitidas:
- Restricción
DEFAULTen columnas de tabla externa. - Operaciones de lenguaje de manipulación de datos (DML) delete, insert y update
Ejemplos
Un. Creación de una tabla externa destinada a un archivo Parquet disponible en OneLake en Microsoft Fabric
CREATE EXTERNAL DATA SOURCE [MainLakeHouse]
WITH (
LOCATION = 'abfss://<WorkspaceID>@<tenant>.dfs.fabric.microsoft.com/<Lakehouse_id'
);
GO
CREATE EXTERNAL FILE FORMAT [Parquetff]
WITH (
FORMAT_TYPE = PARQUET
);
GO
CREATE EXTERNAL TABLE Customer_parquet
(
CustomerKey INT,
GeoAreaKey INT,
StartDT DATETIME2,
EndDT DATETIME2,
Continent NVARCHAR (50),
Gender NVARCHAR (10),
Title NVARCHAR (10),
GivenName NVARCHAR (100),
MiddleInitial VARCHAR (2),
Surname NVARCHAR (100),
StreetAddress NVARCHAR (200),
City NVARCHAR (100),
State NVARCHAR (100),
StateFull NVARCHAR (100),
ZipCode NVARCHAR (20),
Country_Region NCHAR (2),
CountryFull NVARCHAR (100),
Birthday DATETIME2,
Age INT,
Occupation NVARCHAR (100),
Company NVARCHAR (100),
Vehicle NVARCHAR (100),
Latitude DECIMAL (10, 6),
Longitude DECIMAL (10, 6)
)
WITH (
DATA_SOURCE = MainLakeHouse,
LOCATION = '/Files/parquet/customer.parquet',
FILE_FORMAT = [parquetff]
);
GO
SELECT *
FROM Customer_parquet;