Nota:
El acceso a esta página requiere autorización. Puede intentar iniciar sesión o cambiar directorios.
El acceso a esta página requiere autorización. Puede intentar cambiar los directorios.
Se aplica a:![]() SQL Server 2016 (13.x)
SQL Server 2016 (13.x) ![]() SQL Server 2017 (14.x)
SQL Server 2017 (14.x) ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Importante
SQL Server Distributed Replay no está disponible con SQL Server 2022 (16.x) y versiones posteriores.
La característica Microsoft SQL Server Distributed Replay le ayuda a evaluar el efecto de las actualizaciones de SQL Server futuras. También puede usarla para ayudar a evaluar el efecto de las actualizaciones del sistema operativo y el hardware, y de la optimización de SQL Server.
Desuso de Distributed Replay en SQL Server 2022
Distributed Replay está en desuso a partir de SQL Server 2022 (16.x), como se indica en Características del motor de base de datos en desuso en SQL Server 2022 (16.x). Distributed Replay tiene una dependencia de SQL Server Native Client (SNAC), que se quitó de SQL Server 2022 (16.x). Este cambio se documenta en Directivas de soporte para SQL Server Native Client. Además, Distributed Replay depende de archivos .trc, que se capturan con SQL Trace y SQL Server Profiler, ambos en desuso.
El controlador de Distributed Replay se ha quitado del programa de instalación de SQL Server 2022 (16.x) y el cliente de Distributed Replay ya no está disponible en SQL Server Management Studio (SSMS) a partir de la versión 18. Para obtener el controlador de Distributed Replay, debe instalar SQL Server 2019 (15.x) o una versión anterior. Para obtener el cliente de Distributed Replay, debe instalar SSMS 17.9.1.
En el caso de los clientes de SQL Server 2022 (16.x), puede usar Utilidades de Lenguaje de marcado de reproducción (RML), que incluye ostress, para reproducir una carga de trabajo.
Ventajas de Distributed Replay
De forma similar a SQL Server Profiler, puede usar Distributed Replay para reproducir un seguimiento capturado en un entorno de prueba actualizado. A diferencia de SQL Server Profiler, Distributed Replay no se limita a reproducir la carga de trabajo de un único equipo.
Distributed Replay proporciona una solución más escalable que SQL Server Profiler. Con Distributed Replay, puede reproducir una carga de trabajo de varios equipos y simular mejor una carga de trabajo esencial.
La característica Distributed Replay puede usar varios equipos para reproducir los datos de seguimiento y simular una carga de trabajo esencial. Utilice Distributed Replay para probar la compatibilidad de las aplicaciones o el rendimiento, o planear la capacidad.
Cuándo usar Distributed Replay
SQL Server Profiler y Distributed Replay proporcionan cierta superposición en la funcionalidad.
Puede usar SQL Server Profiler para reproducir un seguimiento capturado en un entorno de prueba actualizado. También puede analizar los resultados de la reproducción para buscar posibles incompatibilidades en el rendimiento y la funcionalidad. Pero SQL Server Profiler solo puede reproducir una carga de trabajo de un equipo. Al reproducir una aplicación OLTP que requiere muchos recursos y que tiene muchas conexiones simultáneas activas o un rendimiento alto, SQL Server Profiler se puede convertir en un cuello de botella para los recursos.
Distributed Replay proporciona una solución más escalable que SQL Server Profiler. Use Distributed Replay para volver a reproducir una carga de trabajo de varios equipos y simular mejor una carga de trabajo esencial.
En la siguiente tabla se describe cuándo usar cada herramienta.
| Herramienta | Use cuando... |
|---|---|
| SQL Server Profiler | Quiere usar el mecanismo de reproducción convencional en un solo equipo. En concreto, necesita las funcionalidades de depuración línea por línea, como los comandos Paso, Ejecutar hasta el cursory Alternar punto de interrupción. Quiere reproducir un seguimiento de Analysis Services. |
| Reproducción Distribuida | Desea evaluar la compatibilidad de las aplicaciones. Por ejemplo, desea probar escenarios de actualización de sistemas operativos y SQL Server , actualizaciones de hardware o la optimización de los índices. La concurrencia en la traza capturada es tan alta que un solo cliente de reproducción no puede simularla adecuadamente. |
Conceptos de Reproducción Distribuida
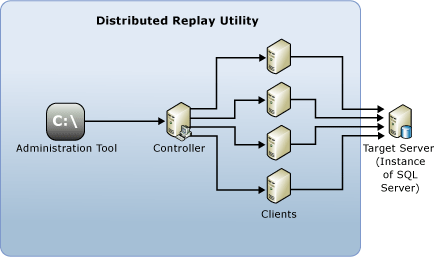
Los siguientes componentes conforman el entorno de Distributed Replay:
Herramienta de administración Distributed Replay: una aplicación de consola, DReplay.exe, que se usa para comunicarse con Distributed Replay Controller. Use la herramienta de administración para controlar la reproducción distribuida.
Distributed Replay Controller: equipo que ejecuta el servicio de Windows denominado Distributed Replay Controller de SQL Server. El controlador de Distributed Replay orquestra las acciones de los clientes de Distributed Replay. Solo puede haber una instancia de controlador en cada entorno de Distributed Replay.
Distributed Replay Clients: uno o varios equipos (físicos o virtuales) que ejecutan el servicio de Windows denominado SQL Server Distributed Replay Client. Los clientes de Distributed Replay colaboran para simular cargas de trabajo en una instancia de SQL Server. Puede haber uno o más clientes en cada entorno de Distributed Replay.
Servidor de destino: : instancia de SQL Server que Distributed Replay Clients pueden usar para reproducir datos de seguimiento. Se recomienda que el servidor de destino se encuentre en un entorno de prueba.
La herramienta de administración, Distributed Replay Controller y Distributed Replay Client se pueden instalar en equipos distintos o en el mismo equipo. Solo puede haber una instancia del servicio de Distributed Replay Controller o Client ejecutándose en el mismo equipo.
La ilustración siguiente muestra la arquitectura física de Distributed Replay de SQL Server :
Tareas de Distributed Replay
| Descripción de la tarea | Artículo |
|---|---|
| Describe cómo configurar Distributed Replay. | Configurar Reproducción Distribuida |
| Describe cómo preparar la información de seguimiento de entrada. | Preparación de los datos de seguimiento de entrada |
| Describe cómo reproducir los datos de seguimiento. | Reproducir datos de seguimiento |
| Describe cómo revisar los resultados de los datos de seguimiento de Distributed Replay. | Revisión de los resultados del replay |
| Describe cómo usar la herramienta de administración para iniciar, supervisar y cancelar operaciones en el controlador. | Opciones de línea de comandos para la herramienta de administración de comandos (utilidad de reproducción distribuida) |
Requisitos
Antes de utilizar la característica Distributed Replay, tenga en cuenta los requisitos de productos que se describen en este artículo.
Requisitos de seguimiento de entrada
Para reproducir correctamente los datos de seguimiento, deben cumplir los requisitos de versión y el formato, y contener las columnas y eventos necesarios.
Versiones de seguimiento de entrada
Distributed Replay admite los datos de seguimiento de entrada que se recopilan en las siguientes versiones de SQL Server:
- SQL Server 2019 (15.x)
- SQL Server 2017 (14.x) (Actualización Acumulativa 1 y versiones posteriores - vea versiones de compilación de SQL Server 2017)
- SQL Server 2016 (13.x)
- SQL Server 2014 (12.x)
- SQL Server 2012 (11.x)
- SQL Server 2008 R2 (10.50.x)
- SQL Server 2008 (10.0.x)
- SQL Server 2005 (9.x)
Formatos de seguimiento de entrada
Los datos de seguimiento de entrada pueden estar en cualquiera de los siguientes formatos:
Un archivo de seguimiento con la extensión
.trc.Conjunto de archivos de seguimiento de sustitución por sustitución que siguen la convención de nomenclatura de sustitución por sustitución de archivos, por ejemplo:
<TraceFile>.trc,<TraceFile>_1.trc,<TraceFile>_2.trc,<TraceFile>_3.trc, ...<TraceFile>_n.trc.
Eventos y columnas de seguimiento de entrada
Los datos de seguimiento de entrada deben contener columnas y eventos específicos que se reproduzcan mediante Distributed Replay. La plantilla TSQL_Replay de SQL Server Profiler contiene todas las columnas y eventos necesarios, además de información adicional. Para obtener más información acerca de esa plantilla, vea Replay Requirements.
Advertencia
Si no usa la plantilla de TSQL_Replay para capturar los datos de seguimiento de entrada o si no se cumplen los requisitos de seguimiento de entrada, es posible que reciba resultados inesperados de reproducción.
También puede crear una plantilla de seguimiento personalizada y utilizarla para reproducir los eventos mediante Distributed Replay, siempre que contenga los eventos siguientes:
- Inicio de sesión de auditoría
- Cerrar sesión de auditoría
- Conexión Existente
- Parámetro de salida RPC
- RPC:Completado
- RPC:Iniciando
- SQL:BatchCompleted
- SQL:BatchStarting
Si reproduce los cursores de servidor, los siguientes eventos también se requieren:
- CerrarCursor
- CursorExecute
- CursorAbrir
- CursorPrepare
- CursorUnprepare
Si reproduce instrucciones de SQL preparadas en el servidor, los siguientes eventos también se requieren:
- Ejecutar SQL Preparado
- Preparación de SQL
Todos los datos de seguimiento de entrada deben contener las columnas siguientes:
- Clase de eventos
- Secuencia de Eventos
- TextData
- Nombre de la aplicación
- NombreDeUsuario
- Nombre de la base de datos
- Identificador de base de datos
- Nombre del host
- Datos binarios
- SPID (Servicios de Identidad Digital)
- Hora de comienzo
- Hora de finalización
- IsSystem
Combinaciones admitidas de traza de entrada y servidor de destino
En la tabla siguiente se enumeran las versiones admitidas de los datos de seguimiento y, para cada una, las versiones admitidas de SQL Server en las que se pueden reproducir los datos.
| Versión de los datos de seguimiento de entrada | Versiones admitidas de SQL Server para la instancia del servidor de destino |
|---|---|
| SQL Server 2005 (9.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x) y SQL Server 2019 (15.x) |
| SQL Server 2008 (10.0.x) | SQL Server 2008 (10.0.x), SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x) y SQL Server 2019 (15.x) |
| SQL Server 2008 R2 (10.50.x) | SQL Server 2008 R2 (10.50.x), SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x) y SQL Server 2019 (15.x) |
| SQL Server 2012 (11.x) | SQL Server 2012 (11.x), SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x) y SQL Server 2019 (15.x) |
| SQL Server 2014 (12.x) | SQL Server 2014 (12.x), SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2016 (13.x) | SQL Server 2016 (13.x), SQL Server 2017 (14.x), SQL Server 2019 (15.x) |
| SQL Server 2017 (14.x) | SQL Server 2017 (14.x): SQL Server 2019 (15.x) |
| SQL Server 2019 (15.x) | SQL Server 2019 (15.x) |
Requisitos de sistema operativo
Los sistemas operativos admitidos para ejecutar la herramienta de administración y los servicios del controlador y el cliente son los mismos que para la instancia de SQL Server . Para obtener más información sobre qué sistemas operativos son compatibles con la instancia de SQL Server, consulte Requisitos de hardware y software para SQL Server 2016 y SQL Server 2017.
Las características de Distributed Replay se admiten en sistemas operativos basados en x86 y en x64. Para los sistemas operativos basados en x64, solo se admite el modo Windows sobre Windows (WOW).
Limitaciones de la instalación
Un equipo solo puede tener instalada una única instancia de cada característica Distributed Replay. La siguiente tabla muestra cuántas instalaciones de cada característica se permiten en un único entorno de Distributed Replay.
| Característica de Reproducción Distribuida | Instalaciones máximas por cada entorno de reproducción |
|---|---|
| Servicio del controlador de reproducción distribuida de SQL Server | 1 |
| Servicio cliente distributed Replay de SQL Server | 16 (equipos físicos o virtuales) |
| Herramienta de administración | Sin límite |
Nota
Aunque solo se puede instalar una instancia de la herramienta de administración en un solo equipo, puede iniciar varias instancias de la herramienta de administración. Los comandos emitidos desde varias herramientas de administración se resuelven en el mismo orden en el que se reciben.
Proveedor de acceso a datos
Distributed Replay solamente admite el proveedor de acceso a datos ODBC de SQL Server Native Client.
Requisitos de preparación del servidor de destino
Se recomienda que el servidor de destino se encuentre en un entorno de prueba. Para reproducir los datos de seguimiento en otra instancia de SQL Server diferente a donde se registró originalmente, asegúrese de que se han realizado los pasos siguientes en el servidor de destino:
Todos los inicios de sesión y los usuarios que se encuentran en los datos de seguimiento deben estar presentes en la misma base de datos del servidor de destino.
Todos los inicios de sesión y los usuarios en el servidor destino deben tener los mismos permisos que tenían en el servidor original.
Los Id. de base de datos del destino deben ser los mismos que los del origen. Sin embargo, si no son los mismos, se puede realizar la coincidencia basándose en DatabaseName, si está presente en el seguimiento.
La base de datos predeterminada para cada inicio de sesión contenido en los datos de seguimiento debe establecerse (en el servidor de destino) en la base de datos de destino correspondiente del inicio de sesión. Por ejemplo, los datos de seguimiento que se van a reproducir contienen la actividad del inicio de sesión, Fred, en la base de datos Fred_Db de la instancia original de SQL Server. Por tanto, en el servidor de destino, la base de datos predeterminada del inicio de sesión, Fred, debe establecerse en la base de datos que coincida con Fred_Db (aunque el nombre de la base de datos sea diferente). Para establecer la base de datos predeterminada del inicio de sesión, utilice el procedimiento almacenado del sistema
sp_defaultdb.
La reproducción de eventos asociados a inicios de sesión que faltan o que son incorrectos tendrá como resultado errores de reproducción, pero la operación de reproducción continuará.