Administrar Espacios de almacenamiento directo en VMM
En este artículo se proporciona información general sobre Espacios de almacenamiento directo (S2D) y cómo se implementa en el tejido de System Center Virtual Machine Manager (VMM).
Espacios de almacenamiento directo (S2D) era nuevo en Windows Server 2016. Agrupa las unidades de almacenamiento físico en grupos de almacenamiento virtual para proporcionar almacenamiento virtualizado. Con el almacenamiento virtualizado, puedes hacer lo siguiente:
- Administrar varios orígenes de almacenamiento físico como una sola entidad virtual.
- Usar almacenamiento barato, con y sin dispositivos de almacenamiento externos.
- Recopilar diferentes tipos de almacenamiento en un único grupo de almacenamiento virtual.
- Aprovisionar fácilmente el almacenamiento y expandir el almacenamiento virtualizado a petición agregando nuevas unidades.
Nota:
VMM 2019 UR3 admite Infraestructura hiperconvergida de Azure Stack (HCl, versión 20H2).
Nota:
VMM 2022 admite Infraestructura hiperconvergida de Azure Stack (HCl, versión 20H2 y 21H2).
¿Cómo funciona?
S2D crea grupos de almacenamiento a partir del almacenamiento que está conectado a nodos específicos de un clúster de Windows Server. El almacenamiento puede ser interno del nodo o de disco conectado directamente a un único nodo. Las unidades de almacenamiento admitidas incluyen NVMe, SSD conectado a través de SATA o SAS y HDD. Más información.
- Al habilitar S2D en un clúster de Windows Server, S2D detecta automáticamente el almacenamiento apto y lo agrega a un grupo de almacenamiento para el clúster.
- S2D también crea una caché de almacenamiento integrado del lado servidor para maximizar el rendimiento. Las unidades más rápidas se usan para el almacenamiento en caché y las unidades restantes para la capacidad. Más información sobre la caché.
- Creas volúmenes a partir de un bloque de almacenamiento. La creación de un volumen crea el disco virtual (espacio de almacenamiento), las particiones y los da formato, lo agrega al clúster y lo convierte en un volumen compartido de clúster (CSV).
- Configura distintos niveles de tolerancia a errores para un volumen para especificar cómo se distribuyen los discos virtuales entre discos físicos del grupo, mediante SMB 3.0. Puedes configurar un volumen sin resistencia o con resistencia reflejada o paridad. Más información.
Implementación convergente y no convergente
Un clúster que ejecuta S2D se puede implementar de dos maneras:
- Implementación hiperconvergida: el proceso de Hyper-V y el almacenamiento S2D se ejecutan dentro del mismo clúster, sin separación entre ellos. Esto proporciona escalado simultáneo de recursos de proceso y almacenamiento.
- Implementación desagregada: los recursos de proceso se ejecutan en un clúster de Hyper-V. El almacenamiento S2D se ejecuta en un clúster diferente. Puedes escalar los clústeres por separado para lograr una administración optimizada.
Implementación hiperconvergida
Esta es una ilustración para la implementación hiperconvergida
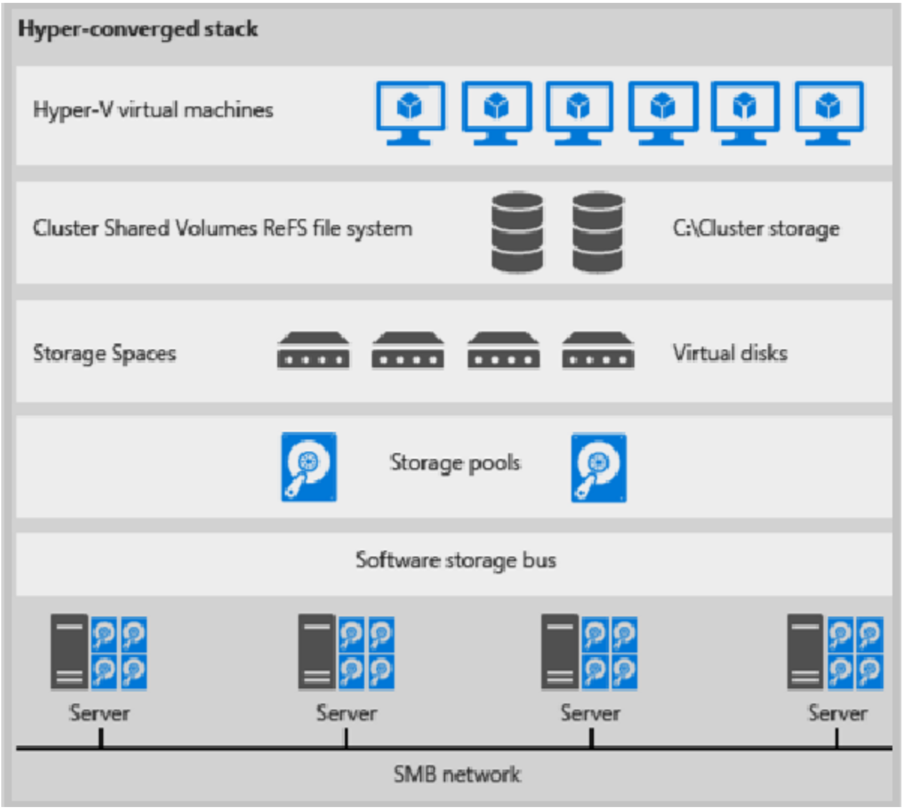
Figura 1: Implementación hiperconvergida
- Los archivos de VM se almacenan en los CSV locales.
- No se usan recursos compartidos de archivos ni SMB.
- Después de que los volúmenes CSV de S2D estén disponibles, los aprovisionas como lo harías con cualquier otra implementación de Hyper-V.
- Escala el clúster de proceso de Hyper-V junto con su almacenamiento S2D.
Implementación desagregada
Esta es una ilustración para la implementación desagregada
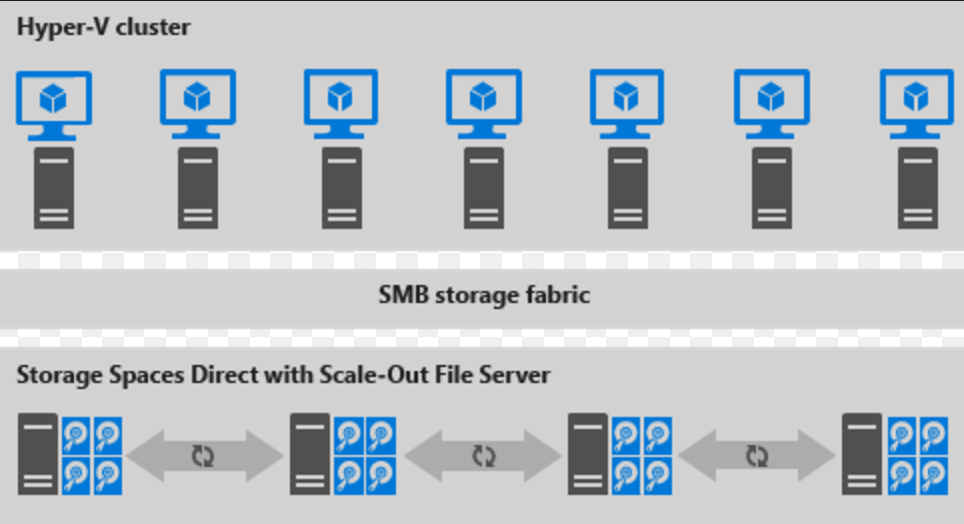
Figura 2: Implementación desagregada
- Los recursos compartidos de archivos se crean en los CSV de S2D.
- Las VM de Hyper-V están configuradas para almacenar sus archivos en el servidor de archivos escalado horizontal (SOFS) y se accede a ellas mediante SMB 3.0.
- Puedes escalar los clústeres de Hyper-V y SOFS por separado para lograr una administración optimizada. Por ejemplo, los nodos de proceso podrían estar cerca de la capacidad completa en muchas VM, pero es posible que los nodos de almacenamiento tengan un exceso de capacidad de disco e IOPS, por lo que solo se agregan nodos de proceso adicionales.