Descripción de Text Analytics
Antes de explorar las funcionalidades de análisis de texto del servicio Azure AI Language, vamos a examinar algunos principios generales y técnicas comunes que se usan para realizar análisis de texto y otras tareas de procesamiento de lenguaje natural (NLP).
Algunas de las primeras técnicas usadas para analizar texto con equipos implican análisis estadísticos de un cuerpo de texto (un corpus) para deducir algún tipo de significado semántico. En pocas palabras, si puede determinar las palabras más usadas en un documento determinado, a menudo puede hacerse una buena idea de lo que trata el documento.
Tokenización
El primer paso para analizar un corpus es dividirlo en tokens. En aras de la simplicidad, se puede considerar que cada palabra distinta del texto de entrenamiento es un token, aunque, en realidad, se pueden generar tokens para palabras parciales o combinaciones de palabras y signos de puntuación.
Por ejemplo, piense en esta frase de un famoso discurso presidencial estadounidense: "we choose to go to the moon". La frase se puede dividir en los siguientes tokens, con identificadores numéricos:
- we
- choose
- to
- GO
- el
- moon
Observe que "to" (número de token 3) se usa dos veces en el corpus. La frase "we choose to go to the moon" puede representarse mediante los tokens [1,2,3,4,3,5,6].
Nota:
Hemos usado un ejemplo sencillo en el que los tokens se identifican para cada palabra del texto. Sin embargo, tenga en cuenta los siguientes conceptos que pueden aplicarse a la tokenización en función del tipo específico de problema de NLP que está intentando resolver:
- Normalización de texto: Antes de generar tokens, puede optar por normalizar el texto quitando la puntuación y cambiando todas las palabras a minúsculas. Para el análisis que se basa exclusivamente en la frecuencia de palabras, este enfoque mejora el rendimiento general. Sin embargo, se puede perder algún significado semántico; por ejemplo, piense en la frase "Mr Banks has worked in many banks". Es posible que desee que su análisis diferencie entre la persona, el Mr. Banks, y los bancos, "the banks ", en los que ha trabajado. También puede considerar "banks." como un token diferente de "banks" porque la inclusión de un punto proporciona la información que la palabra llega al final de una frase
- Eliminación de palabras vacías. Las palabras irrelevantes son palabras que se deben excluir del análisis. Por ejemplo, las partículas "the", "a" o "it" facilitan la lectura de texto, pero agregan poco significado semántico. Al excluir estas palabras, una solución de análisis de texto puede identificar mejor las palabras importantes.
- n-gramas son frases formadas por varios términos, como "yo tengo" o "él camina". Una frase de una sola palabra es un unigrama, una frase de dos palabras es un bigrama, una frase de tres palabras es un trigrama, etc. Al considerar las palabras como grupos, un modelo de Machine Learning puede entender mejor el texto.
- La lematización es una técnica en la que se aplican algoritmos para consolidar palabras antes de contarlas, de modo que las palabras con la misma raíz, como "power", "powered" y "powerful", se interpretan como el mismo token.
Análisis de frecuencia
Después de tokenizar las palabras, puede realizar un análisis para contar el número de repeticiones de cada token. Las palabras más usadas (que no sean palabras irrelevantes como "a", "the", etc.) a menudo pueden proporcionar una pista sobre el tema principal de un corpus de texto. Por ejemplo, las palabras más comunes del texto completo del discurso "go to the moon" que mencionamos anteriormente incluyen "new", "go", "space", y "moon". Si fueramos a tokenizar el texto como bigramas (pares de palabras), el bigrama más común en el discurso es "the moon". A partir de esta información, podemos tener fácilmente en cuenta que el texto se ocupa principalmente del viaje espacial y de ir a la luna.
Sugerencia
El análisis de frecuencia simple en el que simplemente se cuenta el número de repeticiones de cada token puede ser una manera eficaz de analizar un solo documento, pero cuando se necesita diferenciar entre varios documentos dentro del mismo corpus, es necesaria una manera de determinar qué tokens son más relevantes en cada documento. Frecuencia de término: frecuencia inversa del documento (TF-IDF) es una técnica común en la que se calcula una puntuación en función de la frecuencia con la que aparece una palabra o término en un documento en comparación con su frecuencia más general en toda la colección de documentos. Con esta técnica, se supone un alto grado de relevancia para las palabras que aparecen con frecuencia en un documento determinado, pero con poca frecuencia en una amplia gama de otros documentos.
Aprendizaje automático para la clasificación de textos
Otra técnica de análisis de texto útil es usar un algoritmo de clasificación, como la regresión logística, para entrenar un modelo de aprendizaje automático que clasifica el texto basado en un conjunto conocido de categorizaciones. Una aplicación común de esta técnica es entrenar un modelo que clasifica el texto como positivo o negativo para realizar análisis de opiniones o minería de opiniones.
Por ejemplo, piense en las siguientes reseñas de restaurantes, que ya están etiquetadas como 0 (negativo) o 1 (positivo):
- La comida y el servicio fueron excelentes: 1
- Una experiencia terrible: 0
- ¡Mmm! comida deliciosa y un ambiente divertido: 1
- Servicio lento y comida mediocre: 0
Con suficientes reseñas etiquetadas, puede entrenar un modelo de clasificación mediante el texto tokenizado como características y la opinión (0 o 1) como etiquetas. El modelo encapsulará una relación entre los tokens y la opinión; por ejemplo, las reseñas con tokens para palabras como "genial", "sabroso" o "divertido" tienen más probabilidades de devolver una opinión de 1 (positiva), mientras que las reseñas con palabras como "terrible", "lento", y "mediocre" tienen más probabilidades de devolver 0 (negativa).
Modelos de lenguaje semántico
Como el estado de la tecnología para NLP ha avanzado, la capacidad de entrenar modelos que encapsulan la relación semántica entre tokens ha llevado a la aparición de modelos de lenguaje eficaces. En el centro de estos modelos se encuentra la codificación de tokens de lenguaje como vectores (matrices multivalor de números) conocidas como incrustaciones.
Puede ser útil considerar que los elementos de un vector de inserción de tokens son coordenadas en el espacio multidimensional, de modo que cada token ocupa una "ubicación" específica. Cuanto más cerca estén los tokens unos de otros en una dimensión determinada, más relacionados semánticamente estarán. En otras palabras, las palabras relacionadas se agrupan más cerca. Por ejemplo, supongamos que las inserciones de nuestros tokens constan de vectores con tres elementos, por ejemplo:
- 4 ("dog"): [10.3.2]
- 5 ("bark"): [10,2,2]
- 8 ("cat"): [10,3,1]
- 9 ("meow"): [10,2,1]
- 10 ("skateboard"): [3,3,1]
Podemos trazar la ubicación de los tokens en función de estos vectores en el espacio tridimensional, de la siguiente manera:
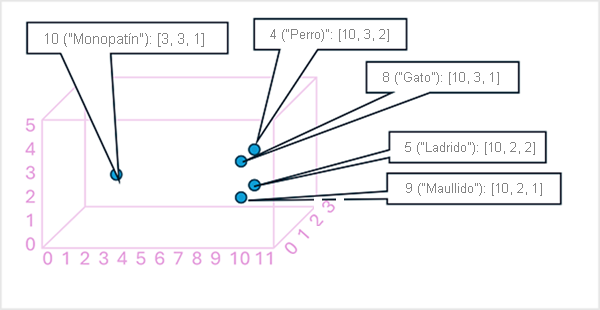
Las ubicaciones de los tokens en el espacio de inserciones incluyen cierta información sobre cómo de estrecha es la relación de los tokens entre sí. Por ejemplo, el token de "dog" está cerca de "cat" y también de "bark". Los tokens de "cat" y "bark" están cerca de "meow". El token de "skateboard" está más lejos de los demás tokens.
Los modelos de lenguaje que usamos en el sector se basan en estos principios, pero tienen mayor complejidad. Por ejemplo, los vectores usados suelen tener muchas más dimensiones. También hay varias maneras de calcular las incrustaciones adecuadas para un conjunto determinado de tokens. Los distintos métodos dan lugar a predicciones diferentes de los modelos de procesamiento de lenguaje natural.
En el siguiente diagrama se muestra una vista generalizada de la mayoría de las soluciones modernas de procesamiento de lenguaje natural. Se tokeniza un gran corpus de texto sin formato y se usa para entrenar modelos de lenguaje, que pueden admitir muchos tipos diferentes de tareas de procesamiento de lenguaje natural.
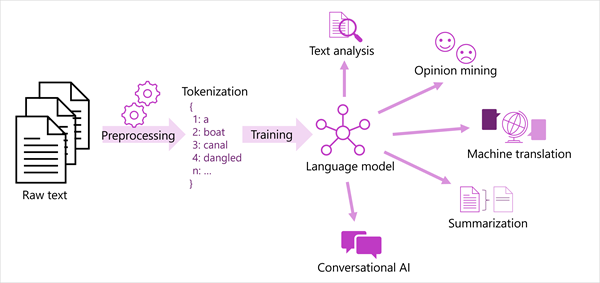
Entre las tareas comunes de NLP admitidas por los modelos de lenguaje se incluyen las siguientes:
- Análisis de texto, como extraer términos clave o identificar entidades con nombre en texto.
- Análisis de sentimiento y minería de opiniones para clasificar textos como positivo o negativo.
- Traducción automática, en la que el texto se traduce automáticamente de un idioma a otro.
- Resumen, en el que se resumen los puntos principales de un corpus de texto grande.
- Soluciones de inteligencia artificial conversacional, como bots o asistentes digitales en los que el modelo de lenguaje puede interpretar la entrada del lenguaje natural y devolver una respuesta adecuada.
Estas funcionalidades y mucho más son compatibles con los modelos del servicio Lenguaje Azure AI, que exploraremos a continuación.