Clasificación de los datos
En un negocio minorista en línea, puede haber diferentes tipos de datos. Cada tipo de datos podría beneficiarse de una solución de almacenamiento diferente.
Los datos de la aplicación se pueden clasificar de tres maneras diferentes: estructurados, semiestructurados y no estructurados. Aquí, aprenderá a clasificar los datos para poder elegir la solución de almacenamiento adecuada para el tipo de datos.
Enfoques para almacenar datos en la nube
En el vídeo siguiente se presentan las opciones para almacenar datos en la nube:
Datos estructurados
En los datos estructurados, a veces denominados datos relacionales, todos los datos tienen los mismos campos o propiedades. Todos los datos tienen la misma organización y forma, o esquema. El esquema compartido hace que sea fácil realizar búsquedas en este tipo de datos mediante lenguajes de consulta como Lenguaje de consulta estructurado (SQL). Esta capacidad hace que este estilo de datos sea idóneo para aplicaciones como los sistemas CRM, las reservas y la administración de inventarios.
Los datos estructurados a menudo se almacenan en tablas de base de datos con filas y columnas. En la tabla, una columna de clave indica cómo se relaciona una fila de una tabla con los datos de otra fila de otra tabla. En la imagen siguiente, una tabla que tiene datos sobre calificaciones obtiene datos de una tabla de nombres de alumnos y una tabla de datos de clase mediante columnas clave.
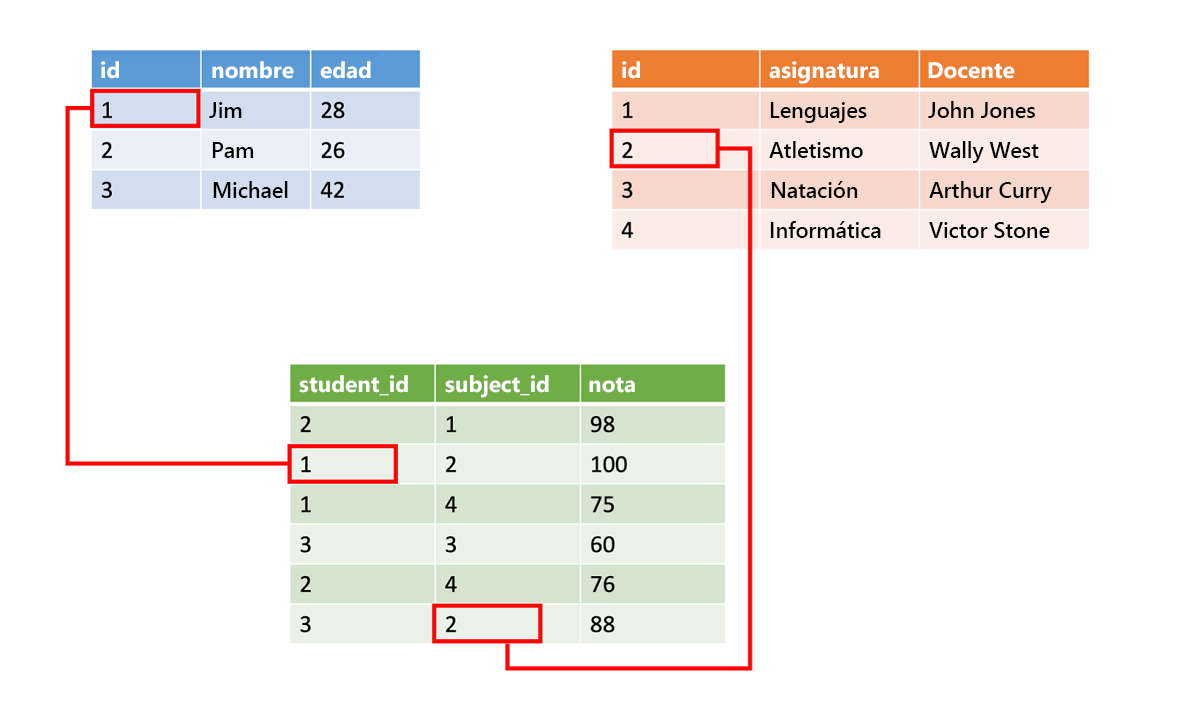
Los datos estructurados son sencillos porque son fáciles de escribir, consultar y analizar. Todos los datos tienen el mismo formato. Pero forzar una estructura coherente también significa que la evolución de los datos es más complicada. Si agrega o quita campos de datos, tendrá que actualizar cada registro para que se ajuste a la nueva estructura.
Datos semiestructurados
Los datos semiestructurados están menos organizados que los datos estructurados. Los datos semiestructurados no se almacenan en un formato relacional porque los campos no encajan a la perfección en tablas, filas y columnas. Los datos semiestructurados contienen etiquetas que hacen evidentes la organización y la jerarquía de los datos. Un ejemplo son los pares clave-valor. Los datos semiestructurados también se conocen como datos no relacionales o datos no solo SQL (NoSQL).
Un lenguaje de serialización de datos define datos semiestructurados. En la clasificación de datos, la serialización es el proceso de conversión de datos a un formato que se pueda transmitir o almacenar.
Los desarrolladores de software usan lenguajes de serialización de datos para escribir datos almacenados en memoria en un archivo, que después se puede enviar a otro sistema, analizarse y leerse. El remitente y el receptor no necesitan conocer los detalles del otro sistema. Ambos sistemas pueden comprender los datos si usan el mismo lenguaje de serialización.
Lenguajes de serialización comunes
Tres lenguajes de serialización comunes son XML, JSON y YAML.
XML
Lenguaje de marcado extensible (XML) fue uno de los primeros lenguajes de datos que se usaron ampliamente. XML se basa en texto, lo que facilita la lectura tanto humana como mecánica. Hay analizadores XML disponibles para casi todas las plataformas de desarrollo populares.
Puede usar XML para expresar relaciones. XML tiene estándares de esquema, de transformación e incluso de representación en la web.
Este es un ejemplo de el nombre, la edad y las aficiones de una persona expresado en XML:
<Person Age="23">
<FirstName>Quinn</FirstName>
<LastName>Anderson</LastName>
<Hobbies>
<Hobby Type="Sports">Golf</Hobby>
<Hobby Type="Leisure">Reading</Hobby>
<Hobby Type="Leisure">Guitar</Hobby>
</Hobbies>
</Person>
XML expresa la forma de los datos mediante etiquetas que se definen dentro de llaves angulares. Las etiquetas adoptan dos formatos: elementos, como <FirstName>, y atributos que se pueden expresar en texto, como Age="23". Los elementos pueden tener elementos secundarios para expresar relaciones. Por ejemplo, la etiqueta <Hobbies> expresa una colección de elementos Hobby.
XML es flexible y puede expresar datos complejos con facilidad, Pero tiende a ser más detallado, lo que hace que los resultados que hay que almacenar, procesar o pasar por una red sean más voluminosos. Este es el motivo por el que otros formatos se han vuelto más populares.
JSON
Notación de objetos JavaScript (JSON) tiene una especificación ligera y usa llaves para indicar la estructura de los datos. En comparación con XML, JSON es menos detallado y más fácil de leer para los humanos. Los servicios web usan JSON con frecuencia para devolver datos.
Esto son el nombre, la edad y las aficiones de la misma persona expresadas en JSON:
{
"firstName": "Quinn",
"lastName": "Anderson",
"age": "23",
"hobbies": [
{ "type": "Sports", "value": "Golf" },
{ "type": "Leisure", "value": "Reading" },
{ "type": "Leisure", "value": "Guitar" }
]
}
El formato JSON no es tan formal como XML. Es más similar a un modelo de pares clave-valor que a una expresión de datos formal. Como se puede deducir del nombre, el lenguaje de programación JavaScript tiene compatibilidad integrada con este formato, lo que hace que sea muy popular para el desarrollo web. Al igual que XML, otros lenguajes tienen analizadores que se pueden usar para trabajar con este formato de datos. El inconveniente de JSON es que tiende a estar más orientado a los programadores, lo que dificulta su lectura y modificación por parte de usuarios sin conocimientos técnicos.
YAML
YAML Ain't Markup Language (YAML) es un lenguaje de serialización de datos desarrollado más recientemente. Una de las ventajas de usar YAML es que es más fácil de leer para los seres humanos que otros lenguajes. La separación de líneas y la sangría definen la estructura de datos. El formato YAML reduce la dependencia de caracteres estructurales como paréntesis, comas y corchetes.
Estos son los mismos datos, expresados en YAML:
firstName: Quinn
lastName: Anderson
age: 23
hobbies:
- type: Sports
value: Golf
- type: Leisure
value: Reading
- type: Leisure
value: Guitar
Este formato es más legible que JSON. Los archivos de configuración que los usuarios escriben pero los programas analizan es un uso común para él. YAML es el más reciente de estos formatos de datos.
A menudo se usa para archivos de configuración escritos por personas, pero analizados por programas.
¿Qué son los datos semiestructurados o NoSQL?
En el vídeo siguiente se describen las opciones de almacenamiento de datos semiestructurados y NoSQL:
Datos no estructurados
La organización de los datos no estructurados es indefinida. Los datos no estructurados a menudo se entregan en formato de archivo, como en archivos de fotos o vídeos. El propio archivo de vídeo podría tener una estructura general e incluir metadatos semiestructurados, pero los datos que forman el vídeo en sí mismo no están estructurados. Por tanto, las fotos, los vídeos y otros archivos similares se clasifican como datos no estructurados.
Ejemplos de datos no estructurados son:
- Archivos multimedia, como fotos, vídeos y archivos de audio.
- Archivos de Microsoft 365, como documentos de Word.
- Archivos de texto.
- Archivos de registro.
Clasificación de datos: evaluación de los tipos de datos
Puede clasificar los datos de tres maneras: estructurados, semiestructurados y no estructurados. Comprender las diferencias para poder clasificar los datos le ayudará a elegir la solución de almacenamiento correcta.
Los datos estructurados son datos organizados que encajan fácilmente en tablas y columnas de datos. Los datos semiestructurados todavía están organizados y tienen propiedades y valores claros, pero hay diversidad en los datos. Los datos no estructurados no encajan a la perfección en tablas o columnas, y no tienen un esquema uniforme.
Ahora se verán los conjuntos de datos que se usan en una empresa minorista en línea y se clasificarán.
Datos del catálogo de productos
Los datos del catálogo de productos para una empresa minorista en línea están semiestructurados por naturaleza. Cada producto tiene una SKU de producto, una descripción, una cantidad, un precio, opciones de tamaño y color, una fotografía y, posiblemente, un vídeo. Estos datos parecen relacionales para comenzar porque todos tienen la misma estructura. Pero cuando incorpore productos nuevos o distintos tipos de productos, es posible que quiera agregar otros campos. Por ejemplo, los nuevos zapatos de tenis que lleva son habilitados para Bluetooth para retransmitir los datos del sensor del zapato a una aplicación de fitness en el teléfono del usuario. Esta característica parece ser una tendencia creciente y quiere permitir que los clientes filtren por zapatillas "Habilitadas para Bluetooth". No quier actualizar todos los datos de zapatillas existentes con un propiedad Habilitado para Bluetooth. Quiere agregar esta nueva propiedad solo a las zapatillas nuevas.
Con la adición de la propiedad Habilitado para Bluetooth, los datos de zapatos ya no son homogéneos. Ha introducido diferencias en el esquema. Si este cambio es la única excepción que espera encontrar, puede normalizar los datos existentes para que todos los productos incluyan un campo "Habilitado para Bluetooth" a fin de mantener una organización relacional estructurada. Pero si es solo uno de los muchos campos de especialidad que prevé admitir en el futuro, la clasificación de los datos es semiestructurada. Las etiquetas organizan los datos, pero cada producto del catálogo puede contener campos únicos.
La clasificación de los datos del catálogo de productos está semiestructurada.
Fotografías y vídeos
Las fotos y vídeos que se muestran en las páginas de productos son datos no estructurados. Aunque el archivo multimedia podría contener metadatos, el cuerpo del archivo multimedia no está estructurado.
La clasificación de datos de fotos y vídeos es no estructurada.
Datos empresariales
Los analistas de negocios quieren implementar inteligencia empresarial para realizar evaluaciones de canalizaciones de inventario y revisiones de datos de ventas. Para realizar estas operaciones, se deben agregar datos de varios meses y, luego, se deben consultar. Debido a la necesidad de agregar datos similares, estos datos deben ser estructurados, para que un mes se pueda comparar con el siguiente.
La clasificación de los datos empresariales es estructurada.