Caso práctico: Sistema de archivos CEPH
Ceph es un sistema de almacenamiento que se puede implementar en clústeres de servidores de gran tamaño con discos conectados. En el vídeo siguiente se habla de los conceptos básicos de Ceph.
Los objetivos de diseño de Ceph2 incluyen los siguientes:
- Clúster de almacenamiento de uso general que sea flexible para admitir una amplia gama de aplicaciones.
- Arquitectura que se pueda escalar sin problemas a cientos de miles de nodos y petabytes de almacenamiento.
- Sistema muy confiable sin ningún único punto de error, que se administre automáticamente y sea sólido.
- El sistema debe ejecutarse en hardware estándar fácilmente disponible. Ceph está diseñado para ser accesible a través de tres abstracciones diferentes, como se muestra en la ilustración siguiente.
El clúster de almacenamiento de Ceph es un almacén de objetos distribuido. Superpuestos sobre el clúster de almacenamiento hay diferentes servicios de almacenamiento orientados al cliente. El servicio de puerta de enlace de objetos de Ceph permite a los clientes acceder a un clúster de almacenamiento de Ceph mediante una interfaz HTTP basada en REST que actualmente es compatible con los protocolos S3 de Amazon y Swift de Openstack. El servicio de dispositivo de almacenamiento en bloque de Ceph permite a los clientes acceder al clúster de almacenamiento como dispositivos de almacenamiento en bloque, a los que se puede dar formato con un sistema de archivos local y montar en un sistema operativo, o usarse como un disco virtual para operar máquinas virtuales en Xen, KVM, VMWare o QEMU. Por último, el sistema de archivos Ceph (Ceph FS) proporciona la abstracción de archivo y directorio en todo el clúster de almacenamiento como un sistema de archivos compatible con POSIX.
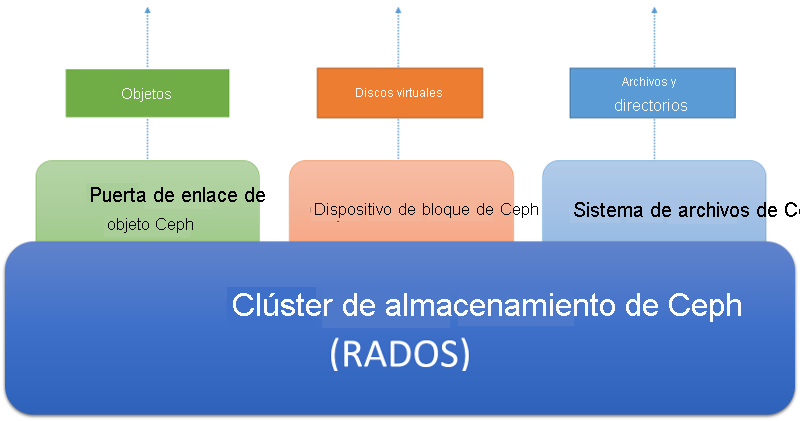
Figura 6: Ecosistema de Ceph
A continuación se muestra la arquitectura de Ceph en más detalle:

Figura 7: Arquitectura de Ceph
En el núcleo de Ceph hay un sistema de almacenamiento de objetos distribuido denominado RADOS. Los clientes pueden interactuar con RADOS directamente mediante una API de bajo nivel denominada librados, que se basa en socket y admite varios lenguajes de programación. Además, los clientes pueden interactuar con las tres API de nivel superior que proporcionan tres abstracciones independientes a RADOS.
Puerta de enlace de RADOS o radosgw permite a los clientes acceder a RADOS mediante una puerta de enlace basada en REST a través de HTTP. Esta emula al servicio de objetos S3 de Amazon y es compatible con las aplicaciones que usan la API S3 de Amazon o la API SWIFT de Openstack.
Dispositivo de almacenamiento en bloque de RADOS o RBS expone el almacén de objetos de RADOS como un dispositivo de almacenamiento en bloque distribuido de uso general, muy parecido a una SAN. El RBS permite que los dispositivos de almacenamiento en bloque se extraigan de RADOS y se monten en sistemas Linux con un controlador de kernel. Los RBD también se pueden usar como imágenes de disco virtual para sistemas de virtualización populares como Xen, VMWare, KVM y QEMU.
Ceph FS es un sistema de archivos distribuido compatible con POSIX superpuesto sobre RADOS que se puede montar directamente en los sistemas de archivos de los clientes Linux. Ceph FS se va a tratar en detalle más adelante en esta página.
Arquitectura de clúster de almacenamiento de Ceph (RADOS)
En el núcleo de Ceph se encuentra el almacén de objetos distribuido, autónomo y confiable (RADOS). En RADOS, los datos se almacenan como objetos distribuidos en un clúster de equipos. Los clientes interactúan con un clúster de RADOS mediante el almacenamiento y la recuperación de objetos. Un objeto consta de un nombre de objeto (que es la clave que se usa para identificar a un objeto), así como del contenido binario del objeto (que es el valor asociado a una clave de objeto determinada). El papel de RADOS es almacenar objetos de forma distribuida en un clúster de una manera escalable, confiable y tolerante a errores.
Hay dos tipos de nodos en un clúster de RADOS: los demonios de almacenamiento de objetos (OSD) y los nodos de supervisión (figura 8). Un OSD almacena objetos y responde a solicitudes de objetos. Los OSD almacenan estos objetos en nodos mediante el sistema de archivos local de cada nodo y mantienen una caché de búfer para mejorar el rendimiento. Los nodos de supervisión vigilan el estado del clúster para realizar un seguimiento de los OSD que entran y salen de él.
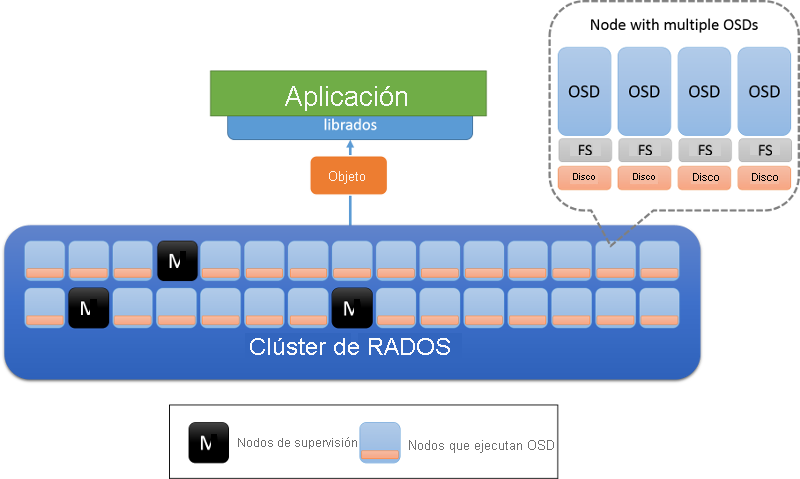
Figura 8: Arquitectura de RADOS. Los OSD son responsables de los datos de un nodo (normalmente, se implementa un OSD por disco físico). Los nodos marcados con M son los nodos de supervisión.
Estado y supervisores de clúster de RADOS
El estado de un clúster de RADOS se encapsula en un objeto conocido como mapa del clúster, compartido por todos los nodos de un clúster. El mapa del clúster contiene información sobre el estado de un clúster en un momento dado, incluido el número de OSD presentes en ese momento, una representación compacta de cómo se distribuyen los datos entre los OSD (que se va a tratar en detalle en la sección siguiente) y una marca de tiempo lógica que indica la hora a la que se ha compilado este mapa del clúster. Los nodos de supervisión realizan las actualizaciones del mapa del clúster de una forma incremental punto a punto. Esto significa que solo los cambios en el mapa del clúster de una marca de tiempo a otra se comunican entre los nodos de un clúster, para mantener al mínimo la cantidad de datos transferidos entre los nodos.
Los supervisores de RADOS son colectivamente responsables de la administración del sistema de almacenamiento mediante el almacenamiento de la copia maestra del mapa del clúster y el envío de actualizaciones periódicas en caso de que haya un cambio en el estado de los OSD. Los supervisores se organizan según el algoritmo paxos, que exige que la mayoría de los supervisores lean o actualicen el mapa del clúster. Los supervisores garantizan que las actualizaciones del mapa se serialicen y sean coherentes. Un clúster de RADOS está diseñado para tener un número reducido de supervisores (>3), que suele ser un número impar para asegurarse de que no haya que realizar desempates cuando los supervisores individuales deban llegar a un consenso.
Selección de ubicación de datos en RADOS
Para que un almacenamiento de objetos distribuido funcione correctamente, un cliente debe poder ponerse en contacto con el OSD correcto para interactuar con un objeto. En primer lugar, un cliente se pone en contacto con un supervisor para recuperar el mapa del clúster del clúster de almacenamiento en cuestión. La información incluida en el mapa del clúster se puede usar para determinar el OSD exacto responsable de un objeto determinado en el clúster.
El primer paso es determinar el grupo de selección de ubicación de un objeto determinado (figura 9). Un grupo de selección de ubicación se puede imaginar como un cubo en el que reside un objeto. Se hace mediante una función hash (la función hash más reciente que se va a usar siempre se obtiene del mapa del clúster). Una vez que se determina un grupo de selección de ubicación para el objeto dado, el cliente tiene que encontrar al OSD responsable de ese grupo de selección de ubicación.
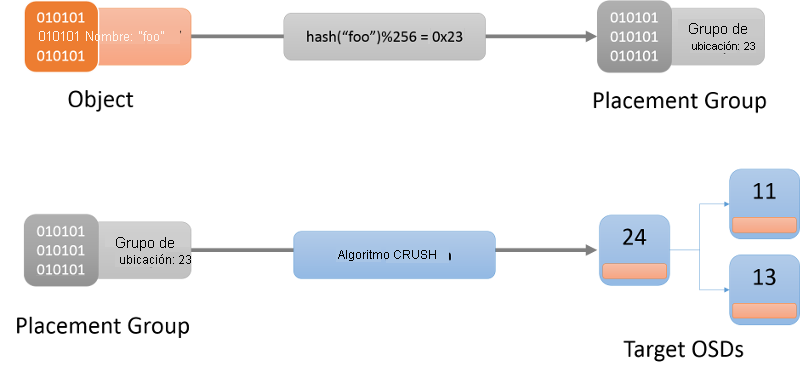
Figura 9: Localización de un objeto en un grupo de selección de ubicación y, por último, en un OSD con el algoritmo CRUSH.
El algoritmo usado para asignar grupos de selección de ubicación a los OSD se conoce como algoritmo Controlled Replication Under Scalable Hashing (CRUSH)1 (Figura 9). CRUSH asigna grupos de selección de ubicación en un clúster de una manera pseudoaleatoria, aunque determinista. CRUSH es más estable que una función hash, en el sentido de que cuando el OSD entra en el clúster o sale de él, CRUSH garantiza que la mayoría de los grupos de selección de ubicación permanezcan donde están y solo desplaza una pequeña cantidad de datos para mantener una distribución equilibrada. Por otro lado, una función hash simple exigiría la redistribución de una mayoría de claves al agregar o quitar cubos. La descripción completa del algoritmo CRUSH queda fuera del ámbito de este artículo. Los lectores interesados pueden referirse a CRUSH: Colocación controlada, escalable y descentralizada de datos replicados.
Cuando se asigna un nombre de objeto a un grupo de selección de ubicación, CRUSH genera una lista de exactamente r OSD responsables del grupo de selección de ubicación. Aquí, r es el número de réplicas de un objeto determinado. En función de la información del mapa del clúster, se identifican los OSD activos que hay en esta asignación y luego se puede establecer contacto con ese OSD para interactuar (operaciones como crear, leer, actualizar, eliminar) con el objeto especificado.
Replicación en RADOS
En RADOS, un objeto se replica en varios OSD asociados al grupo de selección de ubicación de ese objeto. Esto garantiza que haya varias copias de un objeto determinado en caso de que se produzca un error en un OSD concreto. RADOS tiene varios esquemas disponibles en los que tiene lugar realmente la replicación; estos son los esquemas de replicación de copia principal, de cadena y de visualización (figura 10).
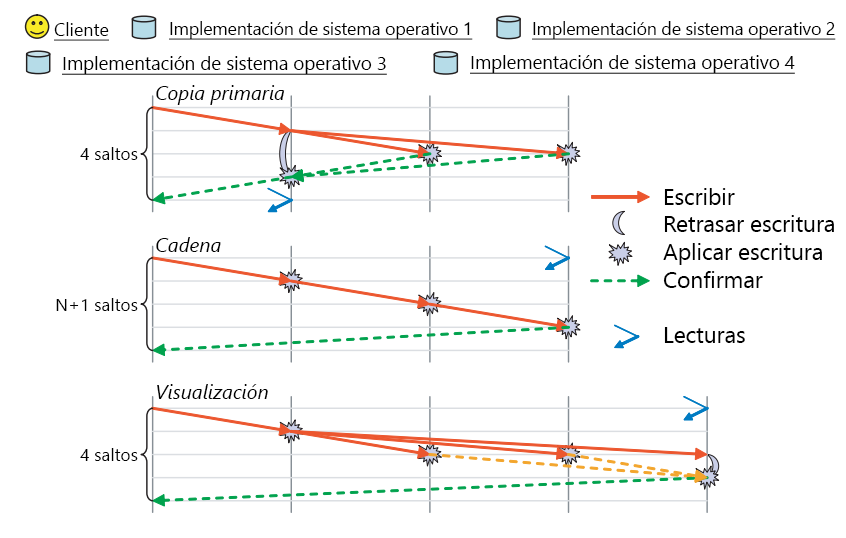
Figura 10: Modos de replicación admitidos en RADOS. (Fuente 2)
Replicación de copia principal: en el esquema de replicación de copia principal, un cliente interactúa con el primer OSD disponible (el OSD de réplica principal) para interactuar con un objeto. El OSD de réplica principal procesa la solicitud y responde al cliente. En caso de una escritura, el OSD de réplica principal reenvía la solicitud de escritura a r-1 réplicas, que actualizan sus copias locales del objeto y responden al maestro. La operación de escritura en el maestro se retrasa hasta que los demás OSD de ese objeto confirman todas las escrituras. Entonces, el maestro acepta la escritura en el cliente. La escritura no se completa hasta que todas las réplicas han respondido al OSD de la copia principal. El mismo proceso se aplica a las lecturas, la copia principal responde a una lectura solo después de que se haya establecido contacto con todas las réplicas y el valor del objeto sea el mismo en todas.
Replicación de cadena: las solicitudes de un objeto se reenvían hacia abajo de la cadena hasta que se encuentra la réplica rª (final). Si la operación es una escritura, se confirma en cada una de las réplicas de camino a la última réplica. Por último, el OSD final que contiene la réplica final confirma la escritura en el cliente. Cualquier operación de lectura se dirige directamente al final para reducir el número de saltos necesarios para leer los datos de un clúster.
Replicación de visualización: la replicación de visualización combina elementos de la replicación de copia principal y de cadena. Las solicitudes de lectura se dirigen al último OSD de la cadena de réplicas, mientras que las escrituras se envían primero al principio. A diferencia de la replicación de cadena, las actualizaciones en los OSD intermedios se realizan en paralelo, igual que en el esquema de replicación de copia principal.
Además de estos esquemas de replicación, la persistencia en RADOS se controla mediante dos mensajes de confirmación independientes (figura 11). Cada OSD tiene una caché del búfer de los datos que sirve. Las actualizaciones se escriben en la caché del búfer y se confirman de inmediato por medio de un mensaje de confirmación. Esta caché del búfer se vacía periódicamente en el disco y, cuando la última réplica ha confirmado los datos en el disco, se envía un mensaje de confirmación al cliente que indica que se han guardado los datos.
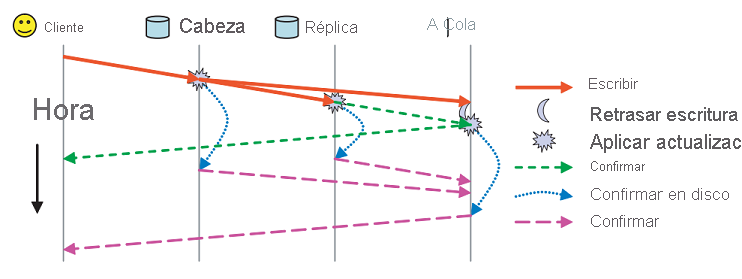
Figura 11: Confirmación frente a mensajes de confirmación en RADOS (Fuente 2)
Modelo de coherencia en RADOS
Cada mensaje de RADOS (tanto del cliente como los mensajes punto a punto entre nodos) se etiqueta con la marca de tiempo para garantizar que los mensajes se ordenen y se apliquen de manera coherente. Si los OSD detectan un mensaje incorrecto debido a un mapa del clúster obsoleto del solicitante del mensaje, envían las actualizaciones incrementales del mapa para actualizar al solicitante del mensaje.
Hay casos límite en los que se deben controlar cuidadosamente las garantías de coherencia estrictas que ofrece RADOS. Si las asignaciones de grupos de selección de ubicación de un OSD determinado cambian (en caso de un cambio en el mapa del clúster), el sistema debe asegurarse de que la transmisión de los grupos de selección de ubicación entre los antiguos OSD y los nuevos se realice de una forma perfecta y coherente. Durante un cambio de grupo de selección de ubicación, es necesario que los nuevos OSD se pongan en contacto con los OSD antiguos para la entrega del estado, durante la cual los antiguos OSD conocen el cambio y dejan de responder a las consultas de esos grupos de selección de ubicación concretos.
Otra ocasión en la que puede ser difícil lograr garantías de coherencia estrictas es en caso de un error de red que provoque una partición de red. En este caso, algunos clientes con un mapa del clúster antiguo podrían seguir realizando operaciones de lectura en ese OSD hasta que un mapa actualizado cambiara el OSD responsable de ese grupo de selección de ubicación. Recuerde que se trata de un escenario de error resaltado anteriormente en la sección sobre el teorema CAP. Esta ventana de incoherencia siempre va a existir en este caso. RADOS intenta mitigar el efecto de este escenario mediante la exigencia de que todos los OSD latan con otras réplicas en un intervalo predeterminado de 2 segundos. Si un OSD determinado no puede acceder a los demás grupos de réplicas de un umbral determinado, bloquea sus lecturas. Además, los OSD asignados como nuevos OSD principales de un grupo de selección de ubicación determinado deben recibir una confirmación de la entrega del OSD principal anterior del grupo de selección de ubicación o esperar a que el intervalo de latido asuma que el OSD principal anterior del grupo de selección de ubicación está inactivo. De este modo, se reduce la posible ventana de incoherencia de un clúster de RADOS en presencia de particiones de red.
Detección de errores y tolerancia a errores en RADOS
Los errores de nodo de RADOS se detectan durante un error de comunicación entre los OSD asignados a un grupo de selección de ubicación o entre los OSD y los nodos de supervisión. Si un nodo no responde en un número limitado de intentos de reconexión, se declara como inactivo. Los OSD que forman parte de un grupo de selección de ubicación intercambian mensajes de latido para asegurarse de que se detecten los errores. Esto se traduce en que los nodos de supervisión toman la iniciativa a la hora de actualizar el mapa del clúster y en que notifican a todos los nodos por medio de un mensaje de actualización incremental del mapa. Después de una actualización del mapa del clúster, los OSD intercambian objetos entre ellos para asegurarse de que se mantenga el número deseado de réplicas para cada grupo de selección de ubicación. Si un OSD detecta por medio de un mensaje que se ha declarado inactivo, simplemente sincroniza su búfer con el disco y se elimina para garantizar que el comportamiento sea coherente.
Sistema de archivos Ceph
Como se indica en la figura anterior, Ceph FS es una capa de abstracción sobre el sistema de almacenamiento RADOS. RADOS no tiene ninguna noción de los metadatos de un objeto aparte del nombre de este. El sistema de archivos Ceph permite que los metadatos de archivo se superpongan sobre los objetos de archivo individuales almacenados en RADOS. En el vídeo siguiente se explica el concepto de CephFS.
Además de los roles de nodo de clúster de los OSD y los supervisores, Ceph FS incorpora servidores de metadatos (MDS) (figura 12). Estos servidores almacenan los metadatos del sistema de archivos (el árbol de directorio, así como las listas control de acceso y los permisos, el modo, la información de propiedad y las marcas de tiempo de cada archivo).
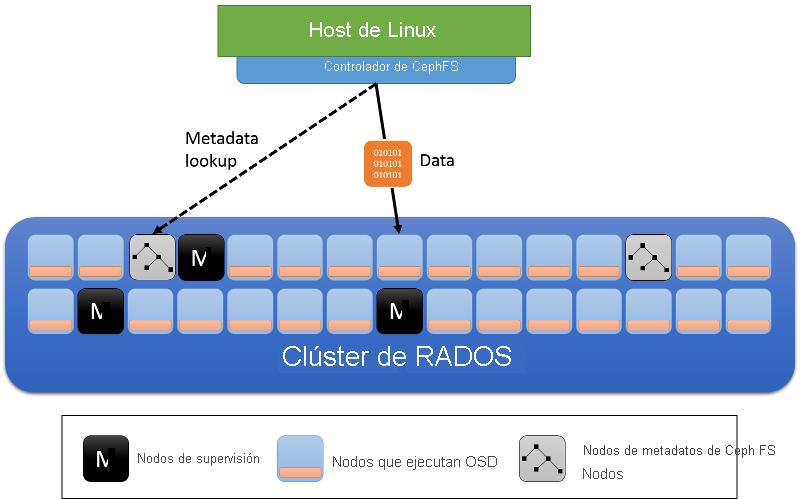
Figura 12: Servidores de metadatos del sistema de archivos Ceph
Los metadatos que usa Ceph FS difieren de los usados por el sistema de archivos local en varios aspectos. Recuerde que, en un sistema de archivos local, un archivo se describe mediante un inode, que contiene una lista de punteros que apuntan a los bloques de datos de un archivo. Los directorios de un sistema de archivos local son simplemente archivos especiales que tienen vínculos a otros inodes que pueden ser otros directorios o archivos. En Ceph FS, un objeto de directorio del servidor de metadatos contiene todos los inodes insertados en él.
Creación de particiones dinámica de subárbol
Al principio, un único servidor de metadatos es responsable de todos los metadatos del clúster. A medida que se agregan servidores de metadatos al clúster, se crean particiones del árbol de directorio del sistema de archivos, que se asigna al grupo resultante de servidores de metadatos (figura 13). Cada servidor de metadatos mide la popularidad de los metadatos de su jerarquía de directorios mediante contadores. Se usa un esquema ponderado3 no solo para actualizar el contador de un nodo hoja determinado del directorio, sino también para los antecesores de ese elemento del directorio hasta la raíz. Así, cada servidor de metadatos puede mantener una lista de zonas activas de los metadatos que se pueden pasar a un nuevo servidor de metadatos cuando este se agrega al clúster.
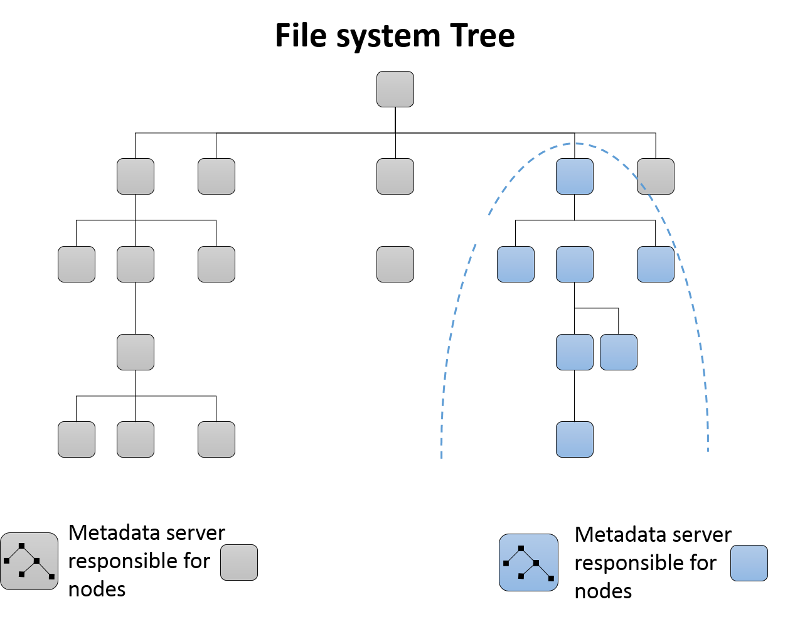
Figura 13: Creación de particiones dinámica de subárbol en el sistema de archivos Ceph
Almacenamiento en caché y tolerancia a errores en servidores de metadatos
Los servidores de metadatos de Ceph FS suelen almacenar en caché la información de metadatos en memoria y servir la mayoría de las solicitudes desde la memoria. Además, los servidores de metadatos usan una forma de registro en diario donde las actualizaciones se envían de bajada a RADOS como objetos de diario y estos se escriben por servidor de metadatos. En caso de error en un servidor de metadatos, se puede reproducir el diario para volver a compilar la parte del servidor de metadatos con errores en un nuevo servidor de metadatos o en uno existente.
Referencias
- Weil, S. A., Brandt, S. A., Miller, E. L., & Maltzahn, C. (2006). CRUSH: Controlled, scalable, decentralized placement of replicated data En Actas de la conferencia de ACM/IEEE de 2006 sobre supercomputación 122
- Weil, S. A., Brandt, S. A., Miller, E. L., & Maltzahn, C. (2006). Ceph: A scalable, high-performance distributed file system Actas del 7º simposio sobre diseño e implementación de sistemas operativos (OSDI) 307-320
- Weil, S. A., Pollack, K. T., Brandt, S. A., & Miller, E. L. (2004). Dynamic metadata management for petabyte-scale file systems En Actas de la conferencia de ACM/IEEE de 2004 sobre supercomputación 4