Antes de la nube
Ahora que hemos definido lo que es la informática en la nube, echemos un vistazo a ejemplos de cómo se usaba la informática en diferentes dominios, como informática empresarial, informática científica e informática personal antes de que apareciera.
Informática empresarial: la informática empresarial suele implicar el uso de sistemas de información de administración que controlan la logística y las operaciones, la planificación de recursos empresariales (ERP), la administración de relaciones con los clientes (CRM), la productividad de oficina y la inteligencia empresarial (BI). Tales herramientas permitían procesos más optimizados que llevaban a una mayor productividad y a una reducción de los costos en una gran variedad de empresas.
Por ejemplo, el software de CRM permite a las empresas recopilar, almacenar, administrar e interpretar diversos datos sobre los clientes pasados, presentes y futuros. Este software ofrece una vista integrada (en tiempo real o casi en tiempo real) de todas las interacciones organizativas con los clientes. En el caso de una empresa de fabricación, un equipo de ventas podía usar el software de CRM para programar reuniones y tareas y realizar un seguimientos con los clientes. Un equipo de marketing podía dirigirse a los clientes con campañas basadas en patrones específicos. Los equipos de facturación pueden realizar el seguimiento de ofertas y facturas. Como tal, se trata de un repositorio centralizado para almacenar esta información. Para permitir esta funcionalidad, la organización y los equipos de ventas emplean diversas tecnologías de hardware y software con el fin de recopilar los datos que se deben almacenar y analizar mediante varios sistemas de base de datos y análisis.
Informática científica: la informática científica emplea modelos matemáticos y técnicas de análisis implementados en los equipos para intentar resolver problemas científicos. Un caso conocido es la simulación de los fenómenos físicos que usan, por ejemplo, modelos climáticos para predecir el tiempo. Este campo ha alterado los métodos teóricos y experimentales de laboratorio tradicionales al permitir que científicos e ingenieros reconstruyan eventos conocidos o predigan situaciones futuras mediante el desarrollo de programas para simular y estudiar diferentes sistemas en distintas circunstancias. Estas simulaciones normalmente requieren un gran número de cálculos que se ejecutan a menudo en superequipos o plataformas informáticas distribuidas.
Informática personal: en la informática personal, un usuario ejecuta diversas aplicaciones en un equipo personal (PC) de uso general. Ejemplos de estas aplicaciones son procesadores de texto y otro software de productividad de oficina, aplicaciones de comunicación, como clientes de correo electrónico, y software de entretenimiento, como videojuegos y reproductores multimedia. Lo habitual es que un usuario de PC posea, instale y mantenga el software y el hardware utilizados para llevar a cabo estas tareas.
Abordar la escalabilidad
Uno de los mayores desafíos de la TI es el escalado de recursos de proceso para satisfacer la demanda, por ejemplo, para aumentar la capacidad de un sitio web para satisfacer las necesidades de una creciente base de clientes o para controlar la "ráfaga" de cargas durante las horas laborales punta o eventos especiales que atraen a un público masivo.
El aumento de la informática de reducción horizontal ha sido un proceso continuo, tanto en el aumento del número de clientes y eventos para capturar, supervisar y analizar en CRM, como en el aumento de la precisión de las simulaciones numéricas en informática científica o el realismo de las aplicaciones de videojuegos. Además, la necesidad de mayor escala ha venido impulsada por el aumento en la adopción de tecnología por parte de varios dominios o la expansión de empresas y mercados, y también por el aumento continuo del número de usuarios y sus necesidades. Las organizaciones deben tener en cuenta el aumento de la escala cuando planeen la implementación de sus soluciones y elaboren su presupuesto.
Las organizaciones suelen planear su infraestructura de TI en un proceso denominado planeamiento de la capacidad. Durante el proceso de planeamiento de la capacidad, el crecimiento del uso de distintos servicios de TI se mide y se usa como un criterio de referencia para la expansión futura. Las organizaciones tienen que planear de antemano la adquisición, la configuración y el mantenimiento de servidores, dispositivos de almacenamiento y equipos de red más nuevos y mejores. En ocasiones, las organizaciones están limitadas por el software, ya que puede que hayan adquirido un conjunto limitado de licencias y necesiten más para expandir la infraestructura a fin de abarcar un conjunto mayor de usuarios.
La forma más básica de escalado se conoce como escalado vertical, en el que los sistemas antiguos se sustituyen por sistemas más nuevos y con un mejor rendimiento, con CPU más rápidas y más memoria y espacio en disco. En muchos casos, el escalado vertical consiste en actualizar o sustituir servidores y agregar capacidad a las matrices de almacenamiento. Este proceso puede tardar meses en planearse y ejecutarse, y con frecuencia requiere breves períodos de tiempo de inactividad a medida que se implementan las actualizaciones.
El escalado también puede realizarse horizontalmente mediante el aumento o la disminución del número de recursos dedicados al sistema. Un ejemplo de esto es la informática de alto rendimiento, donde se pueden agregar servidores y capacidad de almacenamiento adicionales a los clústeres existentes, de forma que aumenta el número de cálculos que se pueden realizar por segundo. Otro ejemplo son las granjas de servidores web: clústeres de servidores que hospedan sitios y aplicaciones web, donde se pueden poner en línea servidores adicionales para controlar el aumento del tráfico. Al igual que el escalado vertical, este proceso puede tardar meses en planearse y ejecutarse, con la posibilidad también de tiempos de inactividad.
Dado que las empresas poseen y mantienen su equipamiento de TI, a medida que el costo de abordar el escalado ha seguido creciendo, las empresas han identificado otros métodos de reducir el costo. Las grandes empresas han consolidado las necesidades informáticas de diferentes departamentos en un solo centro de datos de gran tamaño (por ejemplo, la superficie, la alimentación, la refrigeración y la red) con el fin de reducir los costos. Por su parte, las pequeñas y medianas empresas pueden colocar su equipamiento de TI en un centro de datos compartido y alquilar la superficie, la red, la alimentación, la refrigeración y la seguridad física. Esto se conoce normalmente como servicio de ubicación compartida, que adoptaron las pequeñas y medianas empresas que no querían crear sus propios centros de datos internos. Los servicios de ubicación compartida se siguen adoptando en varios dominios como un enfoque rentable para reducir los gastos operativos.
La informática empresarial ha abordado el escalado vertical y horizontal, así como la consolidación de los recursos de TI en centros de datos y ubicaciones compartidas. En informática científica, se han adoptado sistemas paralelos y distribuidos con el fin de escalar verticalmente el tamaño de los problemas y la precisión de sus simulaciones numéricas. Una definición de procesamiento paralelo es el uso de varios equipos homogéneos que comparten el estado y funcionan como un solo equipo de gran tamaño para ejecutar cálculos a gran escala o de alta precisión. La informática distribuida es el uso de varios sistemas informáticos autónomos conectados por una red para dividir un problema grande en subtareas que se ejecutan de manera simultánea y que se comunican mediante mensajes a través de la red. La comunidad científica ha seguido innovando en estos ámbitos para abordar el escalado. En informática personal, la influencia del escalado se ha dejado sentir por las mayores demandas suscitadas por contenido más abundante y aplicaciones que consumen mucha memoria. Los usuarios reemplazan sus equipos por modelos más nuevos y rápidos o actualizan los modelos existentes para cumplir con estas demandas.
Aumento de los servicios de Internet
Los últimos años de la década de los 90 estuvieron marcados por un aumento constante en la adopción de estas aplicaciones y plataformas informáticas en todos los ámbitos. En breve, se espera que el software no solo sea funcional, sino que también sea capaz de generar valor y conocimientos sobre los requisitos empresariales y personales. El uso de estas aplicaciones evolucionó hacia la colaboración; las aplicaciones se combinaron y ajustaron para retroalimentarse. La TI ya no era solo un centro de costo para una empresa, sino un origen de innovación y eficiencia.
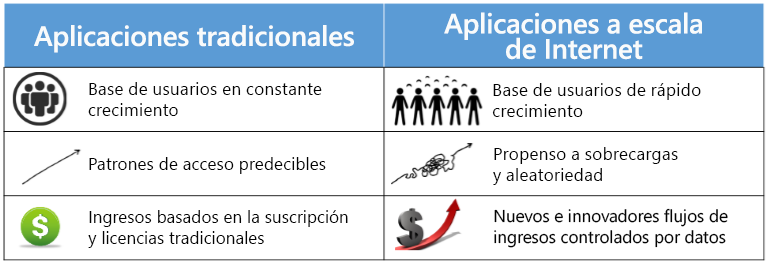
Figura 1.2: Comparación de la informática tradicional y de escalado a Internet.
El siglo XXI ha estado marcado por una explosión en el volumen y la capacidad de las comunicaciones inalámbricas, la Web e Internet. Estos cambios han llevado a una sociedad orientada a los datos y a la red, donde se simplifica la generación, la difusión y el acceso a la información digitalizada. Internet ha creado un mercado global de más de 4 mil millones usuarios. Este aumento en los datos y las conexiones es valioso para las empresas. Los datos generan valor de varias maneras; por ejemplo, permiten la experimentación, la segmentación de las poblaciones y el apoyo a la toma de decisiones con la automatización1 Mediante la adopción de tecnologías digitales, se esperaba que las 10 principales economías del mundo aumentaran su producto en más de un billón de dólares entre 2015 y 2020.
El creciente número de conexiones habilitadas por Internet también ha impulsado su valor. Los investigadores han especulado que el valor de una red varía enormemente como una función del número de usuarios. Por lo tanto, a escala de Internet, obtener y retener clientes es una prioridad, y esto se consigue creando servicios confiables y dinámicos y realizando cambios en función de los patrones de datos observados.
Algunos ejemplos de sistemas de escala de Internet son:
- Motores de búsqueda, que rastrean, almacenan, indexan y realizan búsquedas en grandes conjuntos de datos (de hasta petabytes). Por ejemplo, Google comenzó como un índice web gigante que rastreaba y analizaba el tráfico web una vez cada pocos días y relacionaba estos índices con palabras clave. Ahora, actualiza sus índices prácticamente en tiempo real y es una de las formas más conocidas de acceder a la información en Internet. Su índice tiene billones de páginas con un tamaño de miles de terabytes.3.
- Redes sociales como Facebook y LinkedIn, que permiten a los usuarios crear relaciones personales y profesionales, y construir comunidades basadas en intereses similares. Por ejemplo, Facebook tiene ahora más de 2 mil millones de usuarios activos al mes.
- Los servicios comerciales en línea como Amazon mantienen un inventario de millones de productos y prestan servicio a una base de usuarios global. En 2017, la operación comercial en línea de Amazon alcanzó ventas netas de 178 mil millones de USD, un 31 % más que el año anterior.
- Las aplicaciones multimedia enriquecidas en streaming permiten que los usuarios vean y compartan vídeos, y otras formas de contenido enriquecido. Un ejemplo es YouTube, que sirve hasta 5 mil millones de vídeos al día y en el que se cargan 300 minutos de vídeo por segundo.
- Los sistemas de comunicaciones en tiempo real con chat de audio, vídeo y texto como Skype, que registran más de 50 mil millones de minutos de llamadas al mes.
- Los conjuntos de colaboración y productividad que sirven millones de documentos a muchos usuarios simultáneos, lo que permite actualizaciones persistentes en tiempo real. Por ejemplo, Microsoft 365 atiende a unos 60 millones de usuarios activos cada mes.
- Las aplicaciones de CRM de proveedores como SalesForce se implementan en más de cien mil organizaciones. Los CRM de gran tamaño ahora proporcionan paneles intuitivos para realizar el seguimiento del estado, análisis para encontrar a los clientes que generan la mayor parte del negocio y previsiones de ingresos para predecir el crecimiento futuro.
- Las aplicaciones de minería de datos e inteligencia empresarial que analizan el uso de otros servicios (como los anteriores) para encontrar deficiencias y oportunidades de monetización.
Evidentemente, se espera que estos sistemas se encarguen de un gran volumen de usuarios simultáneos. Esto requiere una infraestructura con capacidad para administrar grandes cantidades de tráfico de red, generar y almacenar datos de forma segura, todo ello sin retrasos perceptibles. Estos servicios derivan su valor proporcionando un estándar constante y confiable de calidad. También proporcionan interfaces de usuario enriquecidas para dispositivos móviles y exploradores web, lo que hace que sean fáciles de usar pero más difíciles de compilar y mantener.
Aquí se resumen algunos de los requisitos de los sistemas basados en Internet:
- Ubicuidad: ser accesible desde cualquier lugar y en cualquier momento, desde multitud de dispositivos. Por ejemplo, un comercial espera que su servicio CRM ofrezca actualizaciones oportunas en un dispositivo móvil para que las visitas a los clientes sean más cortas, más rápidas y eficaces. El servicio debe funcionar sin problemas en diversas conexiones de red.
- Alta disponibilidad: el servicio debe estar "siempre activo". Los tiempos de actividad se miden en términos de número de nueves. Tres nueves, o 99,9 %, implica que un servicio no estará disponible durante 9 horas al año. Cinco nueves (aproximadamente 6 minutos al año) es un umbral típico para un servicio de alta disponibilidad. Incluso unos pocos minutos de tiempo de inactividad en las aplicaciones comerciales en línea pueden afectar a millones de dólares de ventas.
- Latencia baja: tiempos de acceso rápido y con capacidad de respuesta. Se ha demostrado que incluso tiempos de carga de página ligeramente más lentos reducen significativamente el uso de la página web afectada. Por ejemplo, el aumento de la latencia de búsqueda de 100 milisegundos a 400 milisegundos reduce el número de búsquedas por usuario del 0,8% al 0,6%, y el cambio persiste incluso después de que la latencia se restaure a los niveles originales.
- Escalabilidad: la capacidad de atender cargas variables resultantes de la estacionalidad y la viralidad, lo que causa picos y valles en el tráfico durante períodos de tiempo largos y cortos. En días como "Black Friday" y "Cyber Monday", los distribuidores como Amazon y Walmart reciben varias veces más tráfico de red que la media.
- Rentabilidad: un servicio basado en Internet requiere significativamente más infraestructura que una aplicación tradicional, además de una mejor administración[4]. Una manera de simplificar los costos es hacer que los servicios sean más fáciles de administrar y reducir el número de administradores que controlan un servicio. Los servicios más pequeños pueden permitirse tener una relación servicio-administrador baja (por ejemplo, 2:1, lo que significa que un único administrador debe mantener dos servicios). Aunque para mantener la rentabilidad, los servicios como Microsoft Bing deben tener una relación servicio-administrador elevada (por ejemplo, 2500:1, lo que significa que un único administrador mantiene 2500 servicios).
- Interoperabilidad: muchos de estos servicios suelen usarse juntos y, por lo tanto, deben proporcionar una interfaz sencilla para reutilizar y admitir mecanismos estandarizados para la importación y exportación de datos. Por ejemplo, servicios como Uber pueden integrar Google Maps en sus productos para ofrecer información simplificada de localización y navegación a los usuarios.
Ahora exploraremos algunas de las primeras soluciones a los diversos problemas mencionados anteriormente. El primer desafío que tuvo que abordarse fue el gran tiempo de ida y vuelta de los primeros servicios web, que en su mayoría estaban ubicados en los Estados Unidos. Los primeros mecanismos para tratar los problemas de baja latencia (debido a servidores distantes) y errores en los servidores simplemente se basaban en la redundancia. Una técnica para lograr esto fue la "creación de reflejo" del contenido, por la cual se almacenaban copias de las páginas web más populares en diferentes lugares del mundo. Esto minimizó la cantidad de carga en el servidor central, redujo la latencia experimentada por los usuarios finales y permitió que el tráfico pasara a otro servidor en caso de errores. El inconveniente era el aumento de la complejidad para hacer frente a las incoherencias si se modificaba una sola copia de los datos. Por tanto, esta técnica resulta más útil con cargas de trabajo estáticas con mucha actividad de lectura, como el servicio de imágenes, vídeos o música. Debido a la eficacia de esta técnica, la mayoría de los servicios basados en Internet usan redes de entrega de contenido (CDN) para almacenar memorias caché globales distribuidas de contenido popular. Por ejemplo, Cable News Network (CNN) ahora mantiene réplicas de sus vídeos en varios servidores "perimetrales" en diferentes ubicaciones de todo el mundo, con publicidad personalizada por ubicación.
Por supuesto, no siempre tenía sentido que distintas empresas compraran docenas de servidores en todo el mundo. A menudo se obtuvieron eficiencias de costos mediante el uso de servicios de hospedaje compartidos. Aquí, los recursos compartidos de un único servidor web se cederían en concesión a varios inquilinos, lo que amortiza el costo del mantenimiento del servidor. Los servicios de hospedaje compartidos podrían ser muy eficaces en el uso de los recursos, ya que estos podrían aprovisionarse en exceso si se parte del supuesto de que no todos los servicios funcionarían al máximo de su capacidad al mismo tiempo. (Un servidor físico aprovisionado en exceso es aquél en el que la capacidad agregada de todos los inquilinos es mayor que la capacidad real del servidor). El inconveniente fue que era prácticamente imposible aislar los servicios de los inquilinos de los de sus vecinos. Por lo tanto, un solo servicio sobrecargado o propenso a errores podría afectar negativamente a todos sus vecinos. Otro problema surgió porque los inquilinos podían ser malintencionados y tratar de aprovechar la ventaja de la colocalización para robar datos o denegar el servicio a otros usuarios.
Para contrarrestar esto, se desarrollaron servidores privados virtuales como variantes del modelo de hospedaje compartido. Al inquilino se le proporcionaría una máquina virtual (VM) en un servidor compartido. Estas máquinas virtuales solían asignarse estáticamente y estaban conectadas a una sola máquina física, lo que significaba que eran difíciles de escalar y a menudo necesitaban recuperación manual de cualquier error. Si bien ya no se podían aprovisionar en exceso, tenían un mejor rendimiento y aislamiento de seguridad entre los servicios colocalizados que el simple uso compartido de recursos.
Otro problema de compartir recursos públicos era que requería almacenar datos privados en una infraestructura de terceros. Algunos de los servicios basados en Internet descritos anteriormente no podían permitirse perder el control sobre el almacenamiento de datos, ya que cualquier divulgación de los datos privados de sus clientes tendría consecuencias desastrosas. Por lo tanto, estas empresas tenían que crear su propia infraestructura global. Antes de la llegada de la nube pública, estos servicios solo se podían implementar en grandes corporaciones como Google y Amazon. Cada una de estas empresas crearía centros de datos grandes y homogéneos en todo el mundo mediante componentes de uso estándar, donde un centro de datos se podría considerar como un único equipo de escala de almacén (WSC) masivo. Un WSC proporcionaba una abstracción sencilla para distribuir las aplicaciones y los datos de forma global, a la vez que se mantiene la propiedad.
Debido a las economías de escala, el uso de un centro de datos podría estar optimizado para reducir los costos. Aunque todavía no era tan eficaz como los recursos de uso compartido público (la nube), estos equipos de escala de almacén tenían muchas propiedades deseables que servían como punto de partida para la creación de servicios basados en Internet. La escala de las aplicaciones informáticas pasó de servir a una base fija de usuarios a servir a una población mundial dinámica. Los WSC estandarizados permitieron que las grandes empresas prestaran servicios a un público tan amplio. Una infraestructura ideal combinaría el rendimiento y la confiabilidad de un WSC con el modelo de hospedaje de uso compartido. Esto permitiría que incluso una pequeña corporación desarrollara e iniciara una aplicación globalmente competitiva, sin la gran sobrecarga de crear centros de datos de gran tamaño.
Otro enfoque para compartir recursos ha sido la computación en malla, que ha permitido compartir sistemas informáticos autónomos entre instituciones y ubicaciones geográficas. Varias instituciones académicas y científicas colaborarían y agruparían sus recursos para lograr un objetivo común. Cada institución se uniría entonces a una "organización virtual" dedicando un conjunto específico de recursos a través de reglas de uso compartido bien definidas. Los recursos suelen ser heterogéneos y estar poco relacionados, por lo que se requieren complejas construcciones de programación para unirlos. Las cuadrículas estaban orientadas a la compatibilidad con la investigación y los proyectos académicos no comerciales y se basaban en tecnologías de código abierto existentes.
La nube era una sucesora lógica que combinaba muchas de las características de las soluciones anteriores. Por ejemplo, en lugar de que las universidades contribuyan y compartan el acceso a un grupo de recursos mediante una cuadrícula, la nube les permite ceder una infraestructura informática en concesión que administra centralmente un proveedor de servicios en la nube. Dado que el proveedor central mantenía un gran grupo de recursos para satisfacer a todos los clientes, la nube facilitó la escalabilidad dinámica de la demanda en un corto periodo de tiempo. Aunque, en lugar de estándares abiertos como la cuadrícula, la informática en la nube se basa en protocolos de propiedad y requiere que el usuario deposite un cierto nivel de confianza en el CSP.
Referencias
- IBM (2017). ¿Qué son los macrodatos?https://www.ibm.com/analytics/hadoop/big-data-analytics
- Google Inc. (2015). Cómo funciona la Búsqueda de Google. https://www.google.com/insidesearch/howsearchworks/thestory/
- Hamilton, James R y otros (2007). Sobre el diseño y la implementación de servicios basados en Internet