Descripción del procesamiento de consultas inteligentes
En SQL Server 2017 y 2019, y con Azure SQL, Microsoft ha incorporado muchas características nuevas en los niveles de compatibilidad 140 y 150. Muchas de estas características corrigen lo que anteriormente eran antipatrones, como el empleo de funciones escalares definidas por el usuario y el uso de variables de tabla.
Estas características se dividen en varias familias de características:
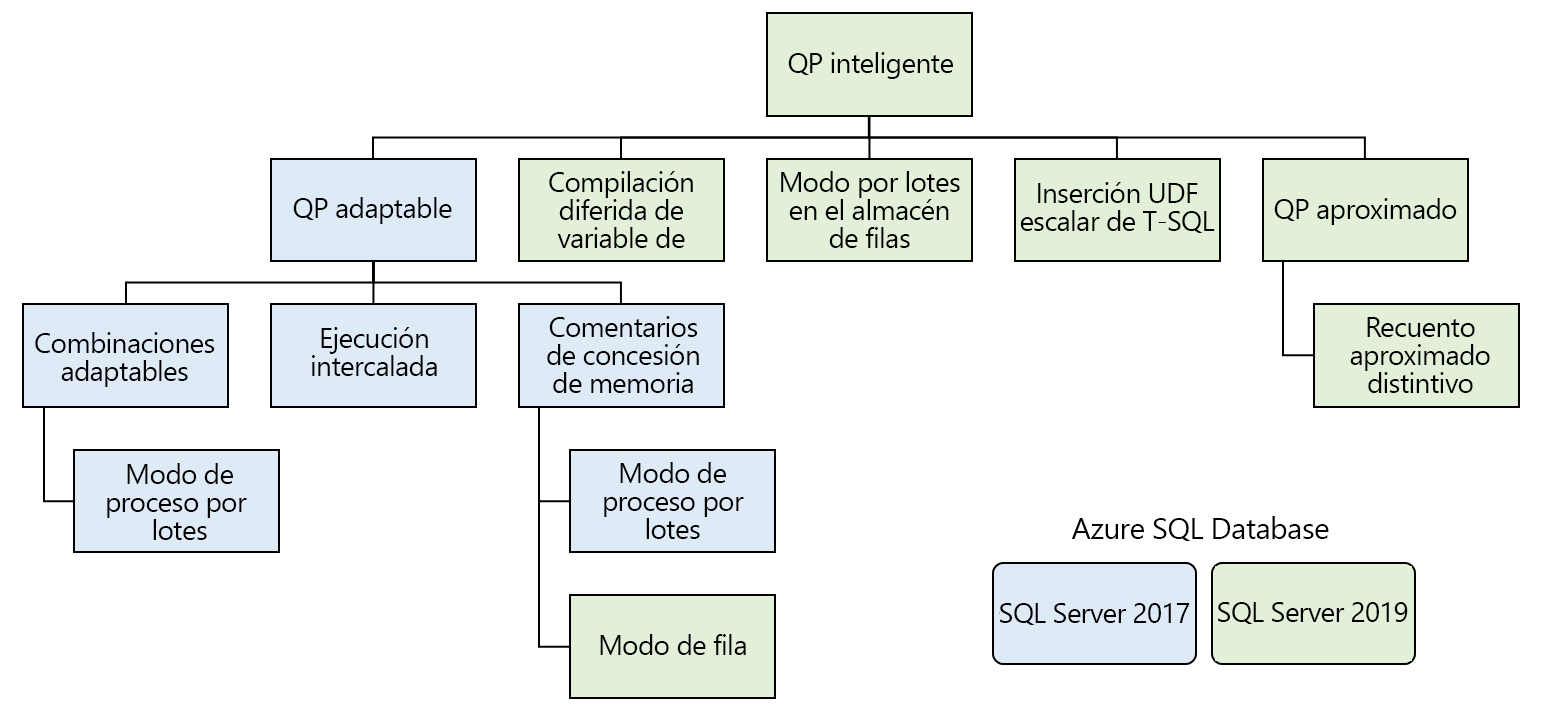
El procesamiento de consultas inteligente incluye características que mejoran el rendimiento de la carga de trabajo existente con un esfuerzo mínimo de implementación.
Para que las cargas de trabajo sean aptas automáticamente para el procesamiento de consultas inteligentes, cambie el nivel de compatibilidad de base de datos aplicable a 150. Por ejemplo:
ALTER DATABASE [WideWorldImportersDW] SET COMPATIBILITY_LEVEL = 150;
Procesamiento de consultas adaptable
El procesamiento de consultas adaptable incluye muchas opciones que hacen que el procesamiento de consultas sea más dinámico, según el contexto de ejecución de una consulta. Estas opciones incluyen varias características que mejoran el procesamiento de las consultas.
Combinaciones adaptables: el motor de base de datos pospone la elección de combinación entre hash y bucles anidados en función del número de filas que entran en la combinación. Actualmente, las combinaciones adaptables solo funcionan en el modo de ejecución por lotes.
Ejecución intercalada: actualmente esta característica admite funciones con valores de tabla de varias instrucciones (MSTVF). Antes de SQL Server 2017, las MSTVF usaban una estimación de fila fija de una o cien filas, en función de la versión de SQL Server. Esta estimación podía dar lugar a planes de consulta poco óptimos si la función devolvía muchas más filas. Se genera un recuento de filas real a partir de MSTVF antes de compilar el resto del plan con ejecución intercalada.
Comentarios de concesión de memoria: SQL Server genera una concesión de memoria en el plan inicial de la consulta en función de las estimaciones de recuento de filas de las estadísticas. La asimetría grave de datos podría dar lugar a unas estimaciones excesivas o inferiores de recuentos de filas, lo que puede provocar sobreasignación de memoria que disminuya la simultaneidad o concesiones insuficientes, lo que puede hacer que la consulta voltee los datos a tempdb. Con el Feedback de Concesión de Memoria, SQL Server detecta estas condiciones y reduce o aumenta la cantidad de memoria asignada a la consulta para evitar el derramamiento o la sobreasignación.
Estas características están habilitadas automáticamente en el modo de compatibilidad 150 y no requieren ningún otro cambio para su habilitación.
Compilación diferida de variables de tabla
Al igual que las MSTVF, las variables de tabla de los planes de ejecución de SQL Server llevan una estimación de recuento de filas fija de una fila. Al igual que las MSTVF, esta estimación fija llevó a un rendimiento deficiente cuando la variable tenía un recuento de filas mayor de lo esperado. Con SQL Server 2019, las variables de tabla se analizan y tienen un recuento de filas real. La compilación diferida tiene una naturaleza similar a la de la ejecución intercalada de MSTVF, salvo que se realiza en la primera compilación de la consulta en lugar de hacerlo de forma dinámica en el plan de ejecución.
Modo por lotes en el almacén de filas
El modo de ejecución por lotes permite procesar los datos por lotes en lugar de fila a fila. Las consultas que incurren en costos significativos de CPU para cálculos y agregaciones ven la mayor ventaja de este modelo de procesamiento. Al separar el procesamiento por lotes y los índices de almacén de columnas, más cargas de trabajo pueden beneficiarse del procesamiento por lotes.
Inserción de función escalar definida por el usuario
En versiones anteriores de SQL Server, las funciones escalares tenían un rendimiento deficiente por varias razones. Las funciones escalares se ejecutaban de manera iterativa, procesando en realidad una fila cada vez. No tenían una estimación de costos adecuada en un plan de ejecución y no permitían el paralelismo en un plan de consulta. Con la inserción de funciones definidas por el usuario, estas funciones se transforman en subconsultas escalares en lugar del operador de función definido por el usuario en el plan de ejecución. Esta transformación puede mejorar considerablemente el rendimiento de las consultas que implican llamadas a funciones escalares.
Recuento aproximado distintivo
Un modelo de consulta de almacenamiento de datos común es ejecutar un recuento distintivo de pedidos o usuarios. Este modelo de consulta puede ser costoso en una tabla grande. La diferencia de recuento aproximado presenta un enfoque más rápido para recopilar un recuento distinto mediante la agrupación de filas. Esta función garantiza una tasa de error del 2 % con un intervalo de confianza del 97 %.