Uso de la API Text to Speech
De manera similar a las API de conversión de voz en texto, el servicio Voz de Azure AI ofrece dos API de REST para la síntesis de voz:
- La API Text to Speech, que es la forma principal de realizar la síntesis de voz.
- La API Batch synthesis, que está diseñada para admitir operaciones por lotes que convierten grandes volúmenes de texto en audio (por ejemplo, para generar un libro de audio a partir del texto de origen).
Puede obtener más información sobre las API de REST en la documentación de las API de REST de texto a voz . En la práctica, la mayoría de las aplicaciones interactivas habilitadas para voz usan el servicio de Voz de Azure AI a través de un SDK específico del lenguaje (programación).
Uso del SDK de Voz de Azure AI
Al igual que ocurre con el reconocimiento de voz, en la práctica, la mayoría de las aplicaciones interactivas habilitadas para voz se han creado mediante la SDK de Voz de Azure AI.
El patrón para implementar la síntesis de voz es similar al del reconocimiento de voz:
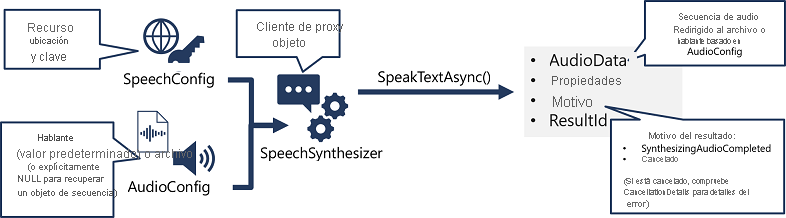
- Use un objeto SpeechConfig para encapsular la información requerida para conectarse al recurso de Voz de Azure AI. En concreto, su ubicación y clave.
- Opcionalmente, use AudioConfig para definir el dispositivo de salida para la voz que se va a sintetizar. De forma predeterminada, este es el altavoz del sistema predeterminado, pero también puede especificar un archivo de audio, o si establece explícitamente este valor en un valor NULL, puede procesar el objeto de la secuencia de audio que se devuelve directamente.
- Use SpeechConfig y AudioConfig para crear un objeto SpeechSynthesizer. Este objeto es un cliente proxy para la API Text to Speech.
- Use los métodos del objeto SpeechSynthesizer para llamar a las funciones de API subyacentes. Por ejemplo, el método SpeakTextAsync() usa el servicio de Voz de Azure AI para convertir texto en audio hablado.
- Procese la respuesta del servicio de Voz de Azure AI. En el caso del método SpeakTextAsync, el resultado es un objeto SpeechSynthesisResult que contiene las siguientes propiedades:
- AudioData
- Propiedades
- Motivo
- ResultId
Cuando la voz se ha sintetizado correctamente, la propiedad Reason se establece en la enumeración SynthesizingAudioCompleted y la propiedad AudioData contiene la secuencia de audio (que, según AudioConfig, se puede haber enviado automáticamente a un altavoz o archivo).