Ejercicio: Ejecución de consultas en un clúster de HDInsight Spark
En este ejercicio, aprenderá a crear un dataframe a partir de un archivo CSV y a ejecutar consultas de Spark SQL interactivas en un clúster de Apache Spark en Azure HDInsight. En Spark, una trama de datos es una colección distribuida de datos que se organizan en columnas con nombre. El dataframe es conceptualmente equivalente a una tabla en una base de datos relacional o a un dataframe en R o Python.
En este tutorial, aprenderá a:
- Creación de una trama de datos a partir de un archivo csv
- Ejecución de consultas en la trama de datos
Creación de una trama de datos a partir de un archivo csv
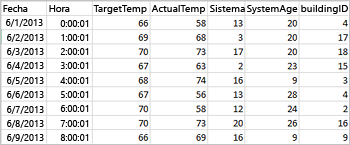
El siguiente archivo CSV de ejemplo contiene información sobre la temperatura de un edificio y está almacenado en el sistema de archivos del clúster de Spark.
Pegue el código siguiente en una celda vacía del cuaderno de Jupyter Notebook y presione MAYÚS + ENTRAR para ejecutarlo. El código importa los tipos necesarios para este escenario.
from pyspark.sql import * from pyspark.sql. types import *Al ejecutar una consulta interactiva en Jupyter, la ventana del explorador web o la leyenda de la pestaña muestran el estado (Ocupado) junto con el título del cuaderno. También verá un círculo sólido junto al texto PySpark en la esquina superior derecha. Cuando finaliza el trabajo, cambia a un círculo vacío.
Ejecute el código siguiente para crear una trama de datos y una tabla temporal (hvac).
# Create a dataframe and table from sample data csvFile = spark.read.csv ('/HdiSamples/HdiSamples/SensorSampleData/hvac/HVAC.csv', header=True, inferSchema=True) csvFile.write. saveAsTable("hvac")
Ejecución de consultas en la trama de datos
Una vez creada la tabla, puede ejecutar una consulta interactiva en los datos.
Ejecute el siguiente código en una celda vacía del cuaderno:
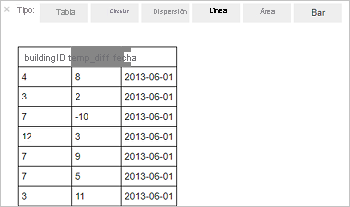
%%sql SELECT buildingID, (targettemp - actualtemp) AS temp_diff, date FROM hvac WHERE date = \"6/1/13\"Se muestra la siguiente salida tabular.
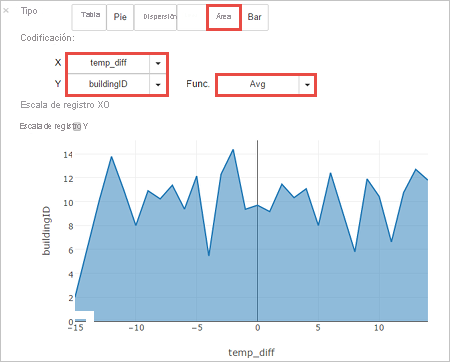
También puede ver la salida en otras visualizaciones. Para ver un gráfico de áreas para la misma salida, seleccione Área y establezca otros valores tal como se muestra.
En la barra de menús del cuaderno, vaya a Archivo > > Save and Checkpoint (Guardar y punto de control).
Cierre el cuaderno para liberar los recursos de clúster: en la barra de menús del cuaderno, vaya a Archivo > Close and Halt (Cerrar y detener).