Descripción y prueba del modelo
¡Hemos creado un modelo de Machine Learning! Vamos a probarlo y veamos lo bien que funciona.
Rendimiento del modelo
Custom Vision muestra tres métricas al probar el modelo. Las métricas son indicadores que pueden ayudarle a entender cómo funciona el modelo. Los indicadores no revelan lo objetivo o preciso que es el modelo. Los indicadores solo indican el rendimiento del modelo con los datos proporcionados. El rendimiento del modelo en datos conocidos le da una idea de cómo funcionará el modelo en datos nuevos.
Se proporcionan las métricas siguientes para todo el modelo y para cada clase:
| Métrica | Descripción |
|---|---|
precision |
Si el modelo predice una etiqueta, esta métrica indica la probabilidad de que se prediga la etiqueta correcta. |
recall |
De las etiquetas que el modelo debe predecir correctamente, esta métrica indica el porcentaje de etiquetas que el modelo predijo correctamente. |
average precision |
Mide el rendimiento del modelo calculando la precisión y la coincidencia en distintos umbrales. |
Al probar el modelo de Custom Vision, veremos los números para cada una de estas métricas en los resultados de las pruebas de iteración.
Errores comunes
Antes de probar el modelo, veamos algunos de los "errores de principiante" que se deben tener en cuenta al empezar a crear modelos de Machine Learning.
Uso de datos no equilibrados
Podría ver esta advertencia al implementar el modelo:
Unbalanced data detected. The distribution of images per tag should be uniform to ensure model performance.
Esta advertencia indica que no tiene un número par de muestras para cada clase de datos. Aunque tenga varias opciones en este escenario, una manera habitual de resolver los datos no equilibrados es usar Synthetic Minority Over-sampling Technique (SMOTE). SMOTE duplica los ejemplos de entrenamiento del grupo de entrenamiento existente.
Nota
En nuestro modelo, es posible que no vea esta advertencia, especialmente si cargó una fracción del conjunto de datos. El subconjunto de datos del modelo de buteo jamaicensis (morfo oscuro) contiene menos de 60 fotos en comparación con los otros modelos que tienen más de 100 fotos. El uso de datos desequilibrados es algo que se debe tener en cuenta en cualquier modelo de aprendizaje automático.
Sobreajuste del modelo
Si no tiene datos suficientes o si no son lo suficientemente variados, el modelo se puede sobreajustar. Cuando un modelo se sobreajusta, conoce bien el conjunto de datos proporcionado y se sobreajusta a los patrones de esos datos. En este caso, el modelo funciona bien con los datos de entrenamiento, pero lo hace de forma deficiente con los datos nuevos que no haya visto antes. ¡Por esta razón, siempre usamos nuevos datos para probar un modelo!
Uso de datos de entrenamiento para probar
Al igual que en el caso del sobreajuste, si el modelo se prueba con los mismos datos que se usaron para entrenar el modelo, este parece funcionar correctamente. Sin embargo, al implementar el modelo en producción, lo más probable es que tenga un rendimiento bajo.
Uso de datos incorrectos
Otro error común es usar datos incorrectos para entrenar el modelo. Algunos datos pueden reducir realmente la precisión del modelo. Por ejemplo, el uso de datos "ruidosos" podría disminuir la precisión de un modelo. En los datos ruidosos, hay demasiada información que no es útil en el conjunto de datos y provoca confusión en el modelo. Una mayor cantidad de datos es mejor, pero solo si son datos de buena calidad que el modelo puede usar. Es posible que tenga que limpiar datos o quitar características para mejorar la precisión del modelo.
Prueba del modelo
En función de las métricas que Custom Vision proporciona, el modelo funciona a un nivel satisfactorio. Ahora se probará y se verá cómo funciona con datos desconocidos. Usaremos una imagen de un pájaro de una búsqueda en Internet.
En el explorador web, busque una imagen de un pájaro que coincida con una de las especies con las que se ha entrenado al modelo para que las reconozca. Copie la dirección URL de la imagen.
En el portal de Custom Vision, seleccione el proyecto Bird Classification (Clasificación de aves).
En la barra de menús superior, seleccione Quick Test (Prueba rápida).
En Quick Test (Prueba rápida), pegue la dirección URL en Image URL (Dirección URL de imagen) y luego presione Entrar para probar la precisión del modelo. La predicción se muestra en la ventana.
Custom Vision analiza la imagen para probar la precisión del modelo y muestra los resultados:
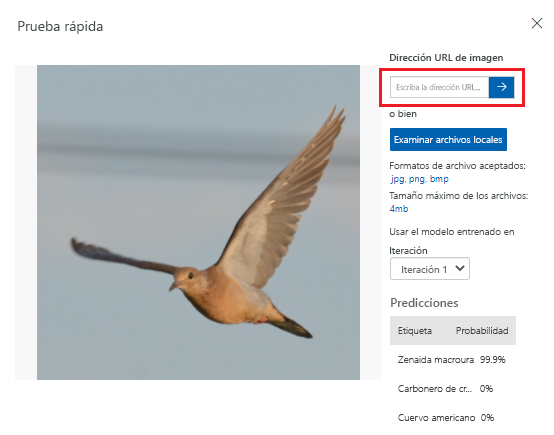
En el paso siguiente se implementará el modelo. Una vez que se ha implementado el modelo, se pueden realizar más pruebas con un punto de conexión que se crea.