Modelado de datos
El modelado de datos en Microsoft Power Platform examina la imagen completa de la arquitectura de datos e incluye una visión lógica de los datos de Dataverse, los lagos de datos y fuentes externas mediante el uso de conectores.
Se dispone de varios tipos y estándares para el modelado de datos, incluido el Lenguaje unificado de modelado (UML), IDEF1X y otros. Los estándares de modelos de datos específicos se salen del ámbito de esta unidad, pero los modelos de datos para las estructuras de datos de Dataverse generalmente se dividen en dos categorías generales:
- Modelos de datos lógicos
- Modelos de datos físicos
Diagramas de relación entre entidades (ERD)
Los modelos de datos lógicos son diagramas de alto nivel que muestran la forma en que los datos fluyen a través del sistema. Los modelos de datos lógicos con frecuencia se agrupan al comienzo del proyecto durante la detección, y antes de que se hayan definido todas las columnas. Generalmente, el diagrama del modelo de datos lógico usa los nombres comerciales de las entidades, en lugar de los nombres esquemáticos.
Los diagramas de modelos de datos lógicos representan el flujo de datos en una solución sin preocuparse por la implementación física.
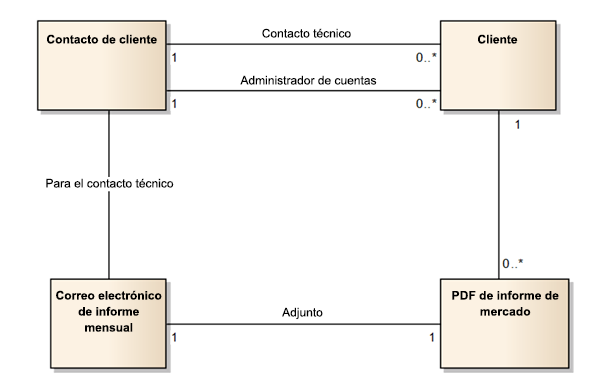
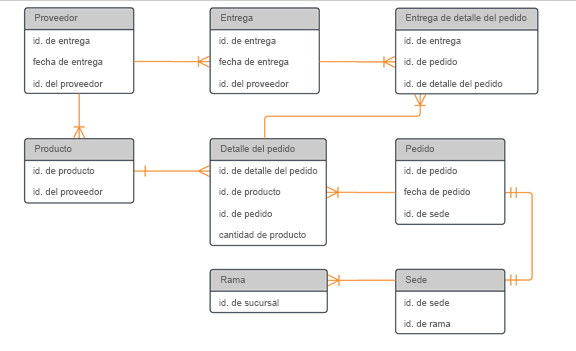
Los modelos de datos físicos son de menor nivel que los modelos de datos lógicos. Por lo general, incluyen detalles en el nivel de columna y, con mayor precisión, relaciones de diseño. El modelo de datos físicos se crea cuando el diseño lógico de alto nivel se traduce en entidades físicas.
Los diagramas de modelos de datos físicos deben incluir el mostrar Dataverse, Microsoft Azure Data Lake Storage, Analysis Services Connector u otros límites de almacenamiento de datos.
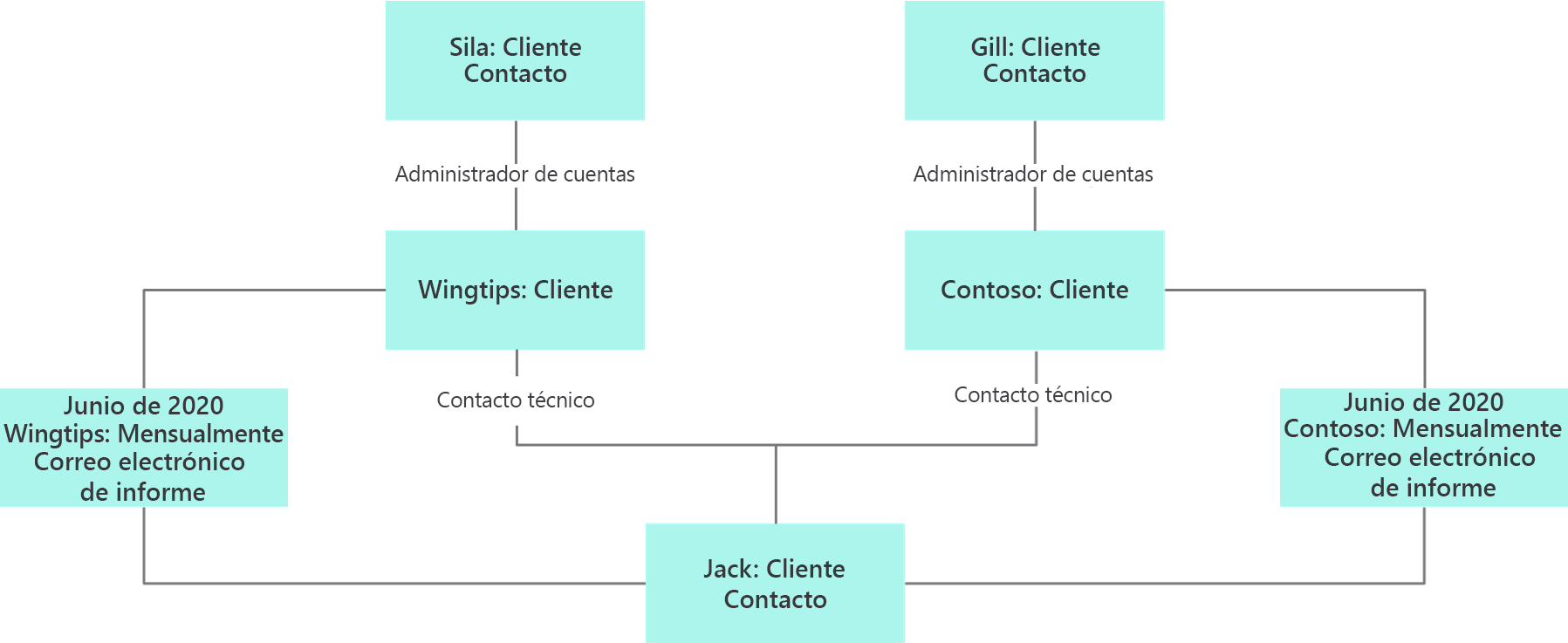
También puede crear diagramas de objetos. Los diagramas de objetos le muestran lo que desea saber y, lo que es más importante, aquello que no desea saber. Los diagramas de objetos deben realizarse en sesiones de modelado con expertos en el dominio.
Estrategias de modelado de datos
Tenga en cuenta las siguientes directrices para la creación de un modelo de datos:
- Comenzar por las tablas y relaciones principales: a menudo, los equipos pasarán a desviarse del problema en su conjunto; sin embargo, finalmente es mucho más fácil resolver pequeñas partes del desafío y analizarlo posteriormente de forma holística.
- Sobrenormalización: los equipos que cuentan con personas con sólidos conocimientos de arquitectura de datos tienden a crear un modelo de datos de Dataverse como lo harían si estuvieran creando una base de datos tradicional de SQL Server. Este enfoque puede dar lugar a una mala experiencia del usuario y a requisitos de procesamiento adicional. Los arquitectos de soluciones deberán colaborar con esas personas para determinar la causa y el efecto de las relaciones en la experiencia del usuario y ayudarlos así a comprender el objetivo.
- Necesidades actuales: Una excelente característica de Dataverse es que puede irse creando escalonadamente con un proceso ágil; no obstante, tener una idea del futuro a corto y largo plazo pude ayudar a sentar las bases. Asegúrese de no sumergirse en tratar de identificar todos los requisitos futuros que se le ocurran.
- Prueba de concepto: Dataverse simplifica el proceso de crear un entorno, probar un modelo, desecharlo y volver a intentarlo. Ocasionalmente, desafiar a dos equipos con el mismo problema de modelado de datos puede producir resultados útiles.
Elementos que influyen en los modelos de datos
En el modelo de datos pueden influir una serie de factores:
- Requisitos de seguridad: los arquitectos de soluciones siempre deben apostar por la simplificación, pero estas simplificaciones pueden generar requisitos en el modelo de datos.
- Experiencia de usuario: un concepto que se olvida fácilmente es que, a medida que se agregan la normalización y las relaciones, se crearán nuevas construcciones que los usuarios necesitan para navegar en las aplicaciones.
- Ubicación y retención de datos: no se permite almacenar todos los datos. A menudo, los datos de los servicios no se pueden almacenar en caché y las empresas tienen políticas internas que rigen el uso de los datos. Algunos datos están protegidos por leyes administrativas o podrían tener requisitos específicos de almacenamiento, por ejemplo, la información identificable, los números de tarjetas de crédito, etc.
- Informes de autoservicio: si se necesita un arquitecto de datos para navegar por el modelo de datos, es probable que muchas de las herramientas de Power BI y la exportación a Excel resulten menos valiosas para el usuario. La mayoría de las características de autoservicio de Dataverse permiten la navegación en un nivel de relación.
- Sistemas existentes: considere si los sistemas son sistemas heredados, si existe una API o si se puede acceder a los datos o copiarlos.
- Localización: evalúe si los requisitos son para varias regiones, varios idiomas o varias divisas.