Explicación de las opciones de PaaS para implementar SQL Server en Azure
Una plataforma como servicio (PaaS) proporciona un entorno de desarrollo e implementación completo en la nube, que se puede usar para aplicaciones sencillas basadas en la nube, así como para aplicaciones empresariales avanzadas.
Azure SQL Database y Azure SQL Managed Instance forman parte de la oferta de PaaS para Azure SQL.
Azure SQL Database: parte de una familia de productos creados sobre el motor de SQL Server, en la nube. Proporciona a los desarrolladores una gran flexibilidad para crear servicios de aplicación y opciones de implementación granulares a gran escala. SQL Database ofrece una solución de bajo mantenimiento que puede ser una excelente opción para determinadas cargas de trabajo.
Azure SQL Managed Instance: es mejor para la mayoría de los escenarios de migración a la nube, ya que proporciona servicios y funcionalidades totalmente administrados.
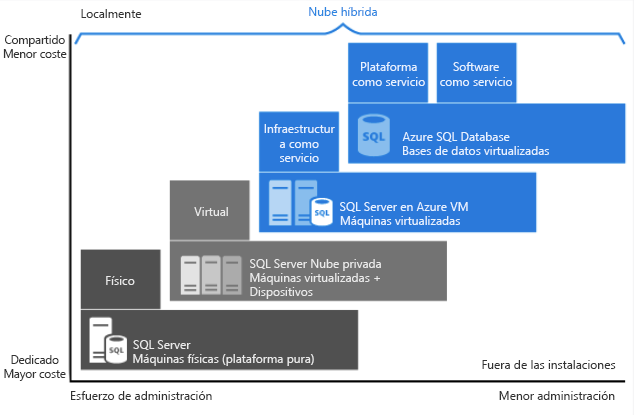
Como se ve en la imagen anterior, cada oferta proporciona un cierto nivel de administración que se tiene sobre la infraestructura y el grado de relación coste-eficacia.
Modelos de implementación
Azure SQL Database está disponible en dos modelos de implementación diferentes:
Una sola base de datos: una base de datos única que se factura y administra por nivel de base de datos. Cada una de las bases de datos se administra individualmente desde perspectivas de escala y tamaño de datos. Cada base de datos implementada en este modelo tiene sus propios recursos dedicados, incluso si se implementa en el mismo servidor lógico.
Grupos elásticos: un grupo de bases de datos que se administran juntas y comparten un conjunto común de recursos. Los grupos elásticos proporcionan una solución rentable para el modelo de aplicación de software como servicio, ya que los recursos se comparten entre todas las bases de datos. Puede configurar recursos basados en el modelo de compra basado en DTU o en el modelo de compra basado en núcleo virtual.
Modelo de compra
En Azure, todos los servicios están respaldados por hardware físico y puede elegir entre dos modelos de compra diferentes:
Unidad de transacción de base de datos (DTU)
Las DTU se calculan en función de una fórmula que combina el proceso, el almacenamiento y los recursos de E/S. Es una buena opción para los clientes que quieren disponer de opciones de recursos sencillas y configuradas previamente.
El modelo de compra de DTU viene en varios niveles de servicio diferentes: Básico, Estándar y Premium. Cada nivel tiene funcionalidades distintas, que proporcionan una amplia gama de opciones al elegir esta plataforma.
En términos de rendimiento, el nivel Básico se usa para cargas de trabajo menos exigentes, mientras que el Premium se usa para los requisitos de cargas de trabajo intensivas.
Los recursos de proceso y almacenamiento dependen del nivel de DTU y proporcionan varias funcionalidades de rendimiento con un límite de almacenamiento fijo, retención de copia de seguridad y costo.
Nota
El modelo de compra de DTU solo es compatible con Azure SQL Database.
Para más información sobre el modelo de compra de DTU, consulte Información general sobre el modelo de compra basado en DTU.
vCore
El modelo de núcleo virtual permite comprar un número especificado de núcleos virtuales basado en las cargas de trabajo dadas. El núcleo virtual es el modelo de compra predeterminado al comprar recursos de Azure SQL Database. Las bases de datos de núcleo virtual tienen una relación específica entre el número de núcleos y la cantidad de memoria y almacenamiento que se proporciona a la base de datos. El modelo de compra de núcleo virtual es compatible con Azure SQL Database y Azure SQL Managed Instance.
También puede adquirir bases de datos de núcleo virtual en tres niveles de servicio diferentes:
De uso general: este nivel es para cargas de trabajo de uso general. Está respaldado por el almacenamiento prémium de Azure. Tendrá una latencia mayor que Crítico para la empresa. También proporciona los siguientes niveles de proceso:
- Aprovisionado: los recursos de proceso se reasignan previamente. Facturación por hora según los núcleos virtuales configurados.
- Sin servidor: los recursos de proceso se escalan automáticamente. Facturación por segundo según los núcleos virtuales usados.
Crítico para la empresa: este nivel es para cargas de trabajo de alto rendimiento que ofrecen la menor latencia de cualquier nivel de servicio. Este nivel está respaldado por SSD locales, en lugar de Azure Blob Storage. También ofrece la máxima resistencia a los errores, además de proporcionar una réplica de base de datos de solo lectura integrada que se puede usar para descargar cargas de trabajo de informes.
Hiperescala: las bases de datos de hiperescala pueden escalar más allá del límite de 4 TB el resto de las ofertas de Azure SQL Database y tener una arquitectura única que admita bases de datos de hasta 100 TB.
Sin servidor
La denominación “Sin servidor” puede resultar un poco confusa, dado que el usuario sigue implementando Azure SQL Database en un servidor lógico, al que se conecta. Azure SQL Database sin servidor es un nivel de proceso que aumenta o reduce verticalmente los recursos de una base de datos determinada en función de la demanda de cargas de trabajo. Si la carga de trabajo ya no requiere recursos de proceso, la base de datos se pondrá "en pausa" y solo se cobrará el almacenamiento durante el período en el que la base de datos se encuentre inactiva. Cuando se realice un intento de conexión, la base de datos se “reanudará” y estará disponible.
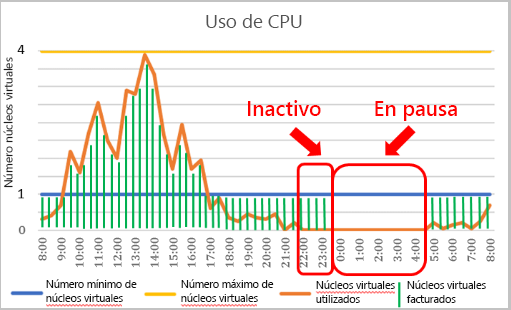
La configuración para controlar la puesta en pausa se conoce como retraso de pausa automática y tiene un valor mínimo de 60 minutos y un valor máximo de siete días. Si la base de datos ha estado inactiva durante ese período, se pausará.
Una vez que la base de datos ha estado inactiva durante el período especificado, se pausará hasta que se intente realizar una conexión posterior. La configuración de un intervalo de escalado automático de proceso y un retraso de pausa automática afectan al rendimiento de la base de datos y a los costos de proceso.
Cualquier aplicación que use el modelo sin servidor debe configurarse para controlar los errores de conexión e incluir lógica de reintento, ya que, al conectarse a una base de datos en pausa, se generará un error de conexión.
Otra diferencia entre el modelo sin servidor y el modelo de núcleo virtual normal de Azure SQL Database es que con el modelo sin servidor puede especificar un número mínimo y máximo de núcleos virtuales. Los límites de memoria y E/S son proporcionales al intervalo de núcleos virtuales especificado.

En la imagen anterior, se muestra la pantalla de configuración de una base de datos sin servidor en Azure Portal. Tiene la opción de seleccionar como mínimo la mitad de un núcleo virtual y un máximo de 16 núcleos virtuales.
Sin servidor no es totalmente compatible con todas las características de Azure SQL Database, ya que algunas requieren la ejecución de procesos en segundo plano en todo momento, como por ejemplo:
- Replicación geográfica
- Retención de copia de seguridad a largo plazo
- Una base de datos de trabajo en trabajos elásticos
- La base de datos de sincronización en SQL Data Sync (Data Sync es un servicio que replica datos entre un grupo de bases de datos)
Nota
SQL Database sin servidor solo se admite actualmente en el nivel de uso general en el modelo de compra de núcleos virtuales.
Copias de seguridad
Una de las características más importantes de la oferta de plataforma como servicio son las copias de seguridad. En este caso, las copias de seguridad se realizan automáticamente sin intervención del usuario. Las copias de seguridad se almacenan en el almacenamiento con redundancia geográfica de blobs de Azure y, de forma predeterminada, se conservan entre 7 y 35 días, según el nivel de servicio de la base de datos. Las bases de datos básicas y de núcleo virtual tienen como valor predeterminado siete días de retención y, en las bases de datos de núcleo virtual, el administrador puede ajustar este valor. El tiempo de retención se puede extender mediante la configuración de la retención a largo plazo (LTR), que permite conservar las copias de seguridad durante un máximo de 10 años.
Para proporcionar redundancia, también puede usar el almacenamiento de blobs con redundancia geográfica con acceso de lectura. Este almacenamiento replicará las copias de seguridad de base de datos en una región secundaria. También permite leer la región secundaria, si es necesario. Las copias de seguridad manuales de las bases de datos no están admitidas y la plataforma denegará cualquier solicitud para llevarlas a cabo.
Las copias de seguridad de base de datos se realizan según una programación determinada:
- Completa: una vez a la semana
- Diferencial: cada 12 horas
- Registro: cada 5-10 minutos, según la actividad del registro de transacciones
Esta programación de copia de seguridad debe satisfacer las necesidades de la mayoría de los objetivos de punto y tiempo de recuperación (RPO/RTO); sin embargo, cada cliente debe evaluar si cumplen sus requisitos empresariales.
Hay varias opciones disponibles para restaurar una base de datos. Debido a la naturaleza de PaaS, no puede restaurar una base de datos manualmente mediante métodos convencionales, como la emisión del comando T-SQL RESTORE DATABASE.
Independientemente del método de restauración que se implemente, no es posible realizar una restauración en una base de datos existente. Si es necesario restaurar una base de datos, se debe anular o cambiar el nombre de la base de datos existente antes de iniciar el proceso de restauración. Además, tenga en cuenta que, según el nivel de servicio de la plataforma, los tiempos de restauración no están garantizados y podrían fluctuar. Se recomienda probar el proceso de restauración para obtener métricas de línea base sobre cuánto tiempo podría tardar una restauración.
Las opciones de restauración disponibles son las siguientes:
Restauración mediante Azure Portal: con Azure Portal tiene la opción de restaurar una base de datos al mismo servidor de Azure SQL Database, o bien puede usar la restauración para crear una nueva base de datos en un nuevo servidor de cualquier región de Azure.
Restauración mediante lenguajes de scripting: se puede usar tanto PowerShell como la CLI de Azure para restaurar una base de datos.
Nota
La copia de seguridad de solo copia en Azure Blob Storage está disponible para SQL Managed Instance. SQL Database no admite esta característica.
Para más información sobre las copias de seguridad automatizadas, vea Copias de seguridad automatizadas: Azure SQL Database y Azure SQL Managed Instance.
Replicación geográfica activa
La replicación geográfica es una característica de continuidad del negocio que replica de forma asincrónica una base de datos en un máximo de cuatro réplicas secundarias. A medida que las transacciones se confirman en la réplica principal (y sus réplicas dentro de la misma región), las transacciones se envían a las réplicas secundarias que se van a reproducir. Dado que esta comunicación se realiza de forma asincrónica, la aplicación que realiza la llamada no tiene que esperar a que la réplica secundaria confirme la transacción antes de que SQL Server devuelva el control al autor de la llamada.
Las bases de datos secundarias son legibles y se pueden usar para descargar cargas de trabajo de solo lectura, liberando así los recursos para cargas de trabajo transaccionales en el servidor principal o colocando los datos más cerca de los usuarios finales. Además, las bases de datos secundarias pueden estar en la misma región que la principal o en otra región de Azure.
Con la replicación geográfica, puede iniciar una conmutación por error, manualmente por parte del usuario o desde la aplicación. Si se produce una conmutación por error, es posible que necesite actualizar las cadenas de conexión de la aplicación para reflejar el nuevo punto de conexión de lo que ahora es la base de datos principal.
Grupos de conmutación por error
Los grupos de conmutación por error se basan en la tecnología usada en la replicación geográfica, pero proporcionan un punto de conexión único para la conexión. La principal razón para el uso de grupos de conmutación por error es que la tecnología proporciona puntos de conexión, que se pueden usar para enrutar el tráfico a la réplica adecuada. La aplicación puede conectarse después de una conmutación por error sin cambios en la cadena de conexión.