Diseñar una solución de integración de datos con Azure Data Factory
Azure Data Factory es un servicio de integración de datos basado en la nube que ayuda a crear y programar flujos de trabajo controlados por datos. Puede usar Azure Data Factory para orquestar el movimiento de datos y transformar los datos a escala. Los flujos de trabajo controlados por datos, o canalizaciones, ingieren datos de almacenes de datos dispares. Azure Data Factory es un proceso de integración de datos ETL (extracción, transformación y carga de datos). Este proceso de integración combina datos de varios orígenes de datos en un único almacén de datos.
Aspectos que debe saber sobre Azure Data Factory
Hay cuatro pasos principales para crear e implementar un flujo de trabajo controlado por datos en la arquitectura de Azure Data Factory:
- Conectar y recopilar. En primer lugar, ingiera los datos para recopilar todos los datos de distintos orígenes en una ubicación centralizada.
- Transformar y enriquecer. Posteriormente, transforme los datos mediante un servicio de proceso como Azure Databricks y Azure HDInsight Hadoop.
- Proporcionar integración continua y entrega continua (CI/CD), y publicación. Admita CI/CD mediante el uso de GitHub y Azure DevOps para entregar el proceso ETL de forma incremental antes de publicar los datos en el motor de análisis.
- Supervisión. Finalmente, usar Azure Portal para supervisar la canalización para las actividades programadas y para los errores.
En el diagrama siguiente se muestra de qué forma Azure Data Factory orquesta la ingesta de datos de distintos orígenes de datos. Los datos se ingieren en Storage Blob y se almacenan en Azure Synapse Analytics. Los componentes de análisis y visualización también están conectados a Azure Data Factory. Azure Data Factory proporciona una interfaz de administración común para todas sus necesidades de integración de datos.
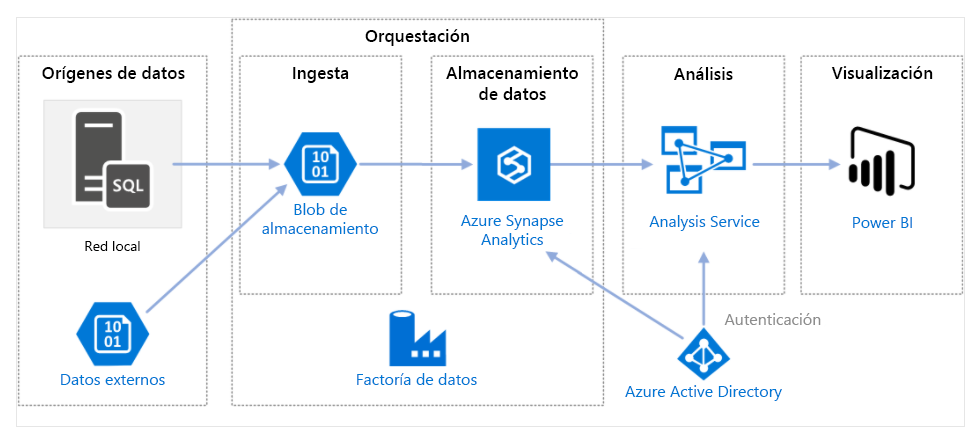
Componentes de Azure Data Factory
Azure Data Factory tiene los siguientes componentes que funcionan conjuntamente para proporcionar la plataforma para el movimiento y la integración de datos.
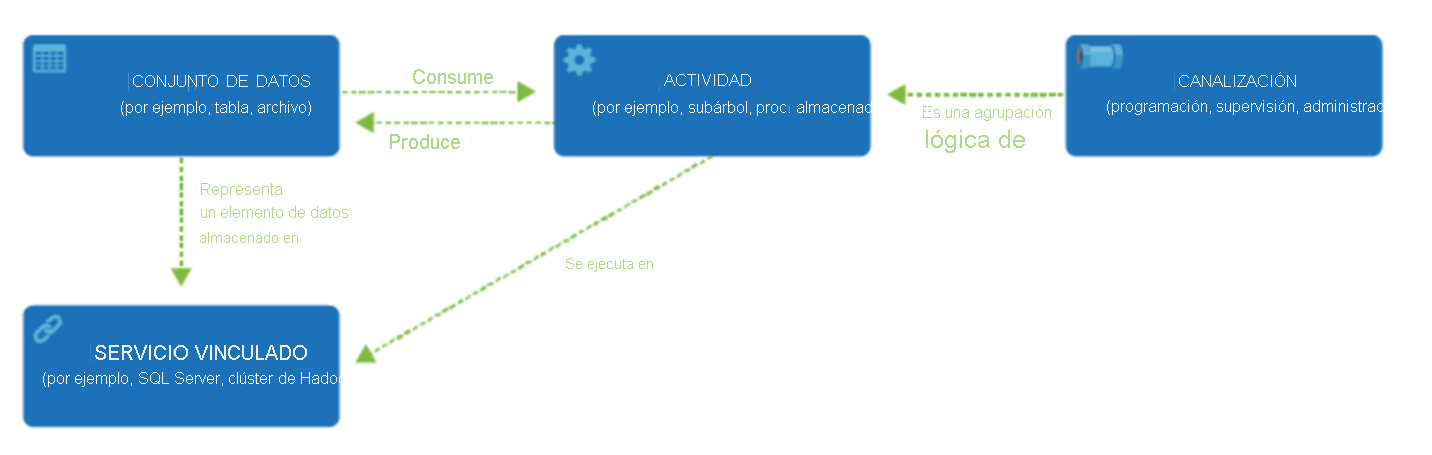
- Canalizaciones y actividades: las canalizaciones proporcionan una agrupación lógica de actividades que realizan una tarea. Una actividad es un único paso de procesamiento en una canalización. Azure Data Factory admite el movimiento de datos, la transformación de datos y las actividades de control.
- Conjuntos de datos: los conjuntos de datos son estructuras de datos dentro de los almacenes de datos.
- Servicios vinculados: los servicios vinculados definen la información de conexión necesaria para que Azure Data Factory se conecte a recursos externos.
- Flujos de datos: los flujos de datos permiten a los ingenieros de datos desarrollar lógica de transformación de datos sin necesidad de escribir código. Las actividades de flujo de datos pueden ponerse en marcha mediante las capacidades de programación, control, flujo y supervisión existentes de Azure Data Factory.
- Entornos de ejecución de integración: los entornos de ejecución de integración sirven de puente entre la actividad y los objetos de servicios vinculados. Hay tres tipos de entornos de ejecución de integración: Azure, autohospedado y Azure-SSIS.
Escenario empresarial
Un desafío importante para una empresa minorista de rápido crecimiento dedicada a la remodelación del hogar como Tailwind Traders es que genera un gran volumen de datos almacenados en sistemas de almacenamiento relacionales, no relacionales y de otro tipo, tanto en la nube como a nivel local. La administración precisa de información empresarial útil de estos datos que sea tan casi en tiempo real como sea posible. Además, el equipo de ventas quiere configurar e implementar soluciones de venta directa y cruzada. ¿Cómo puede crear una solución de ingesta de datos a gran escala en la nube? ¿Qué servicios y soluciones de Azure va a adoptar para facilitar el movimiento y la transformación de datos entre varios almacenes de datos y recursos de proceso?
Veamos cómo intervienen los componentes de Azure Data Factory en un escenario de preparación y movimiento de datos para Tailwind Traders. Tienen muchos orígenes de datos diferentes a los que conectarse y esos datos deben ingerirse y transformarse mediante procedimientos almacenados que se ejecutan en los datos. Por último, los datos se deben insertar en la plataforma de análisis para su análisis.
- En este escenario, el servicio vinculado permite a Tailwind Traders ingerir datos de orígenes diferentes y almacena cadenas de conexión para activar los servicios de proceso a petición.
- Puede ejecutar procedimientos almacenados para la transformación de datos que se produce mediante el servicio vinculado en Azure-SSIS, que es el entorno de ejecución de integración para Tailwind Traders.
- El objeto de actividad usa los componentes de los conjuntos de datos y el objeto de actividad contiene la lógica de transformación.
- Puede desencadenar la canalización, que engloba todas las actividades agrupadas.
- Posteriormente, puede usar Azure Data Factory para publicar el conjunto de datos final en otro servicio vinculado utilizado por tecnologías como Power BI o Machine Learning.
Aspectos que se deben tener en cuenta al usar Azure Data Factory
Evalúe Azure Data Factory con los siguientes criterios de decisión y considere de qué forma el servicio puede beneficiar a la solución de integración de datos para Tailwind Traders.
- Requisitos de integración de datos a tener en cuenta. Azure Data Factory atiende a dos comunidades: la comunidad de macrodatos y la comunidad de almacenamiento de datos relacionales que usa SQL Server Integration Services (SSIS). En función de las necesidades de datos de la organización, puede configurar canalizaciones en la nube mediante Azure Data Factory. Puede acceder a datos desde servicios de datos locales y en la nube.
- Considere la posibilidad de codificar recursos. Si prefiere una interfaz gráfica para configurar las canalizaciones, la herramienta de creación y supervisión de Azure Data Factory es la más adecuada para sus necesidades. Azure Data Factory proporciona un proceso que requiere poco o ningún código para trabajar con orígenes de datos.
- Compatibilidad con varios orígenes de datos a tener en cuenta. Azure Data Factory usa más de 90 conectores para integrarse con orígenes de datos dispares.
- Considere la posibilidad de una infraestructura sin servidor. Hay ventajas en el uso de una solución sin servidor totalmente administrada para la integración de datos. No es necesario mantener, configurar o implementar servidores, y se obtiene la capacidad de escalar con cargas de trabajo fluctuantes.