Diseñar una solución de integración y análisis de datos con Azure Synapse Analytics
Azure Synapse Analytics combina características de análisis de macrodatos, almacenamiento de datos empresariales e integración de datos. El servicio le permite ejecutar consultas en datos o datos sin servidor a escala. Azure Synapse admite la ingesta de datos, la exploración, la transformación y la administración, y admite el análisis de todas las necesidades de inteligencia empresarial y aprendizaje automático.
Aspectos que debe saber sobre Azure Synapse Analytics
Azure Synapse Analytics implementa una arquitectura de procesamiento paralelo masivo (MPP) y tiene las siguientes características.
La arquitectura de Azure Synapse Analytics incluye un nodo de control y un grupo de nodos de ejecución.
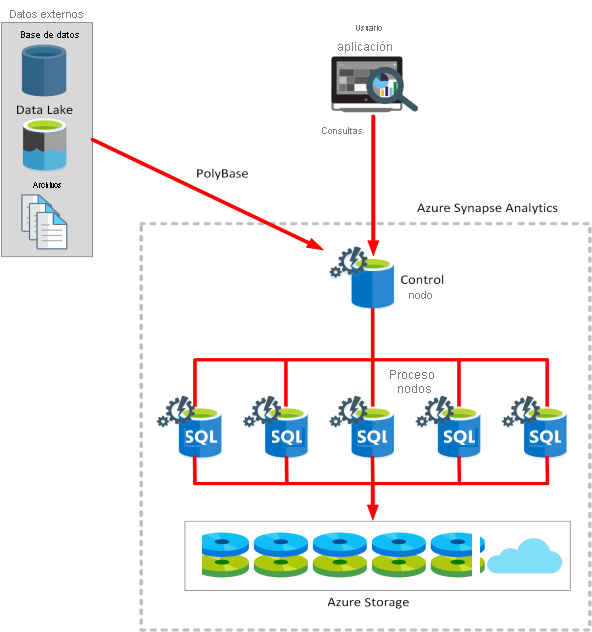
El nodo de control es el cerebro de la arquitectura. Es el front-end que interactúa con todas las aplicaciones. Los nodos de proceso proporcionan la eficacia de cálculo. Los datos que se van a procesar se distribuyen uniformemente entre los nodos.
Las consultas se envían en forma de instrucciones Transact-SQL y Azure Synapse Analytics las ejecuta.
Azure Synapse usa una tecnología denominada PolyBase que permite recuperar y consultar datos de orígenes relacionales y no relacionales. Puede guardar los datos leídos como tablas SQL en el servicio Azure Synapse.

Componentes de Azure Synapse Analytics
Azure Synapse Analytics se compone de cinco elementos:
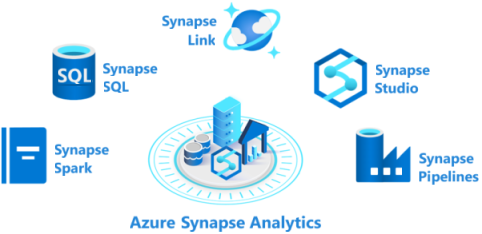
- Grupo de Azure Synapse SQL: Synapse SQL ofrece modelos de recursos dedicados y sin servidor con los que trabajar con la arquitectura basada en nodos. Para obtener un rendimiento y un costo predecibles, puede crear grupos de SQL dedicados. En el caso de cargas de trabajo irregulares o no planificadas, puede usar el punto de conexión SQL sin servidor siempre disponible.
- Grupo de Azure Synapse Spark: este grupo es un clúster de servidores que ejecutan Apache Spark para procesar datos. Para escribir la lógica de procesamiento de datos, se usa uno de los cuatro lenguajes admitidos: Python, Scala, SQL y C# (a través de .NET para Apache Spark). Apache Spark para Azure Synapse integra el motor de macrodatos de código abierto de Apache Spark, que se usa para la preparación de datos, la ingeniería de datos, ETL y el aprendizaje automático.
- Canalizaciones de Azure Synapse: las canalizaciones de Azure Synapse aplican las funcionalidades de Azure Data Factory. Las canalizaciones son un servicio de integración de datos y ETL basado en la nube que le permite crear flujos de trabajo orientados a datos a fin de coordinar el movimiento y la transformación de datos a escala. Puede incluir actividades que transformen los datos a medida que se transfieran o combinar los datos de varios orígenes.
- Azure Synapse Link: este componente permite conectarse a Azure Cosmos DB. Se puede usar para realizar análisis casi en tiempo real de los datos operativos almacenados en una base de datos de Azure Cosmos DB.
- Azure Synapse Studio: este elemento es un IDE basado en Web que se puede usar de forma centralizada para trabajar con todas las funcionalidades de Azure Synapse Analytics. Puede usar Azure Synapse Studio para crear grupos de SQL y Spark, definir y ejecutar canalizaciones, y configurar vínculos a orígenes de datos externos.
Opciones analíticas
Azure Synapse Analytics admite una serie de escenarios analíticos. A medida que revise la tabla, tenga en cuenta cómo se aplican los escenarios a la organización Tailwind Traders.
| Análisis | Escenario | Descripción |
|---|---|---|
| Descriptivo | ¿Qué pasa? | Azure Synapse aplica la funcionalidad de grupo de SQL dedicado, que permite crear un almacenamiento de datos persistente para analizar qué va a suceder posteriormente. Puede usar el grupo de SQL sin servidor a fin de preparar los datos de los archivos almacenados en un lago de datos para crear un almacenamiento de datos de forma interactiva. |
| Diagnostic | ¿Por qué está sucediendo? | Puede usar la funcionalidad de grupo de SQL sin servidor en Azure Synapse para explorar de forma interactiva los datos de un lago de datos. Los grupos de SQL sin servidor permiten de forma rápida que un usuario busque datos adicionales que puedan ayudarle a comprender por qué sucede algo. |
| Predictivo | ¿Qué es probable que suceda? | Azure Synapse Analytics usa su motor de Apache Spark integrado y grupos de Azure Synapse Spark para el análisis predictivo. Combina esta acción con otros servicios, como Azure Machine Learning Services y Azure Databricks, para ayudarle a obtener respuestas sobre qué sucederá en el futuro. |
| Prescriptivo | ¿Qué hay que hacer? | Puede usar datos prescriptivos en tiempo real o casi en tiempo real para ayudarle a identificar soluciones para las acciones necesarias. Azure Synapse Analytics proporciona esta funcionalidad tanto mediante Apache Spark como de Azure Synapse Link, y mediante la integración de tecnologías de streaming como Azure Stream Analytics. |
Escenario empresarial
Vamos a examinar un escenario en el que la empresa atiende a los clientes con información de mercado de valores. Debe proporcionar una combinación de procesamiento por lotes y flujos para admitir la infraestructura de Tailwind Traders. Los datos actualizados al segundo se pueden usar para ayudar a supervisar en tiempo real dónde se requiere una decisión instantánea para tomar decisiones informadas de compra o venta en cuestión de segundos. Los datos históricos son igualmente importantes para una vista de las tendencias del rendimiento. ¿Qué tipo de solución de integración de datos y almacenamiento de datos recomendaría para proporcionar acceso a los flujos de datos sin procesar y a la información empresarial cocinada derivada de estos datos? Con Azure Synapse Analytics, puede ingerir datos de orígenes externos y, a continuación, transformarlos y agregarlos en un formato adecuado para el procesamiento de análisis.
Aspectos que se deben tener en cuenta al elegir Azure Data Factory o Azure Synapse Analytics
En la tabla siguiente se comparan los criterios de la solución de almacenamiento para usar Azure Data Factory o Azure Synapse Analytics. Revise los criterios y considere cuál es la solución óptima para Tailwind Traders.
| Comparación | Azure Data Factory | Azure Synapse Analytics |
|---|---|---|
| Uso compartido de datos | Los datos pueden compartirse entre diferentes factorías de datos | No compatible |
| Plantillas de solución | Las plantillas de solución se proporcionan con la galería de plantillas de Azure Data Factory | Las plantillas de solución se proporcionan en el Centro de conocimientos del área de trabajo de Synapse |
| Flujos de entorno de ejecución de integración entre regiones | Se admiten flujos de datos entre regiones | No compatible |
| Supervisión de datos | La supervisión de datos se integra con Azure Monitor | Hay disponibles registros de diagnóstico en Azure Monitor |
| Supervisión de trabajos de Spark para el flujo de datos | No compatible | Los trabajos de Spark se pueden supervisar para el flujo de datos mediante grupos de Spark de Synapse |
Azure Synapse Analytics es una solución ideal para muchos otros escenarios. Considere las opciones siguientes:
- Considere la variedad de orígenes de datos. Cuando tenga distintos orígenes de datos que usen Azure Synapse Analytics para actividades de flujo de datos y ETL sin código.
- Considere la posibilidad de usar el aprendizaje automático. Cuando tenga que implementar soluciones de aprendizaje automático mediante Apache Spark, puede usar Azure Synapse Analytics para la compatibilidad integrada con AzureML.
- Considere la posibilidad de integrar lagos de datos. Cuando tenga datos existentes almacenados en un lago de datos y necesite integración con Azure Data Lake y orígenes de entrada adicionales, Azure Synapse Analytics proporciona una integración perfecta entre los dos componentes.
- Considere la posibilidad de realizar análisis en tiempo real. Cuando necesite análisis en tiempo real, puede usar características como Azure Synapse Link para analizar en tiempo real y ofrecer información.