Exploración del control de código fuente y el control de versiones
El uso del control de código fuente y de versiones es una práctica fundamental de DevOps. También es un requisito previo para estos procedimientos, como la integración continua y la infraestructura como código, que son fundamentales para alcanzar el potencial completo de DevOps. La organización de nuestro escenario de ejemplo debe revisar su estrategia de desarrollo de software de colaboración actual y pasar a un modelo de control de versiones distribuido, como Git, especialmente teniendo en cuenta sus planes para usar GitHub para su administración del ciclo de vida de software. Sin embargo, esto requiere una comprensión sólida de los principios de control de código fuente y de versión y sus ventajas, que trataremos aquí.
Control de código fuente y control de versiones
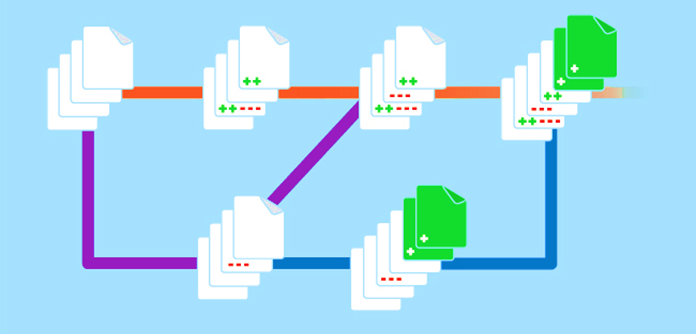
Los términos control de código fuente y control de versiones a menudo se usan indistintamente y, en muchos contextos, hacen referencia al mismo concepto. En general, ambos están asociados a la práctica de administrar cambios en el código en un entorno de desarrollo compartido. Sin embargo, es posible que encuentre escenarios más matizados en los que su significado sea ligeramente diferente. En estos escenarios, el control de código fuente designa un sistema que administra los cambios en los archivos de código fuente, mientras que el control de versiones incluye la administración de cambios de cualquier tipo de archivo con fines que se extienden más allá del código fuente por sí solo. En el futuro, por motivos de coherencia, usaremos el término control de versiones para representar repositorios de software de colaboración basados en Git disponibles en GitHub y Azure DevOps.
¿Cuáles son las ventajas del control de versiones?
El control de versiones realiza un seguimiento de los cambios en los archivos dentro de su ámbito de administración. Esto ofrece una amplia gama de ventajas:
Historial y seguimiento de versiones: tiene la capacidad de revisar el historial de cambios en cualquier archivo, incluida la capacidad de determinar cuándo tuvo lugar cada cambio individual y cuál era su ámbito. Esto también proporciona rastreabilidad, normalmente asociando cada conjunto de cambios con un identificador único.
Reversión y recuperación: si se produce un error o un problema, puede revertir fácilmente los cambios para recuperar la versión de trabajo conocida del archivo afectado.
Bifurcación y combinación: si necesita ampliar la funcionalidad del código actual agregando otra característica o corrige un error recién detectado, puede crear una rama denominada , lo que le permite trabajar de forma independiente con el código base existente. La nueva rama es inicialmente idéntica a la rama principal que hospeda el código actual. Una vez completados los cambios, combinará la nueva rama con la rama principal. Aunque esto puede provocar conflictos (si otro desarrollador decidió modificar el mismo conjunto de archivos mientras tanto a través de otra rama), su ámbito es limitado y normalmente se pueden identificar y resolver fácilmente.
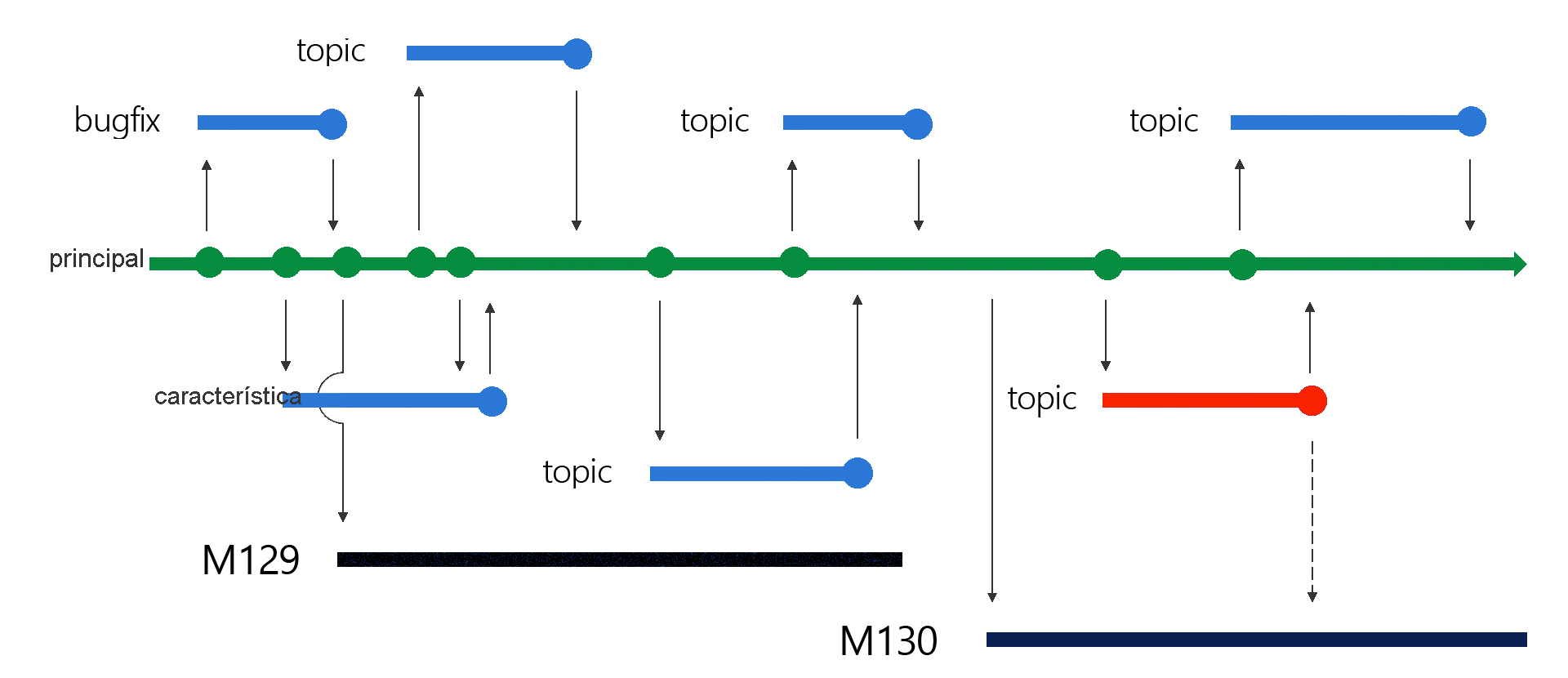
Colaboración y desarrollo paralelo: las disposiciones de resolución de conflictos complementadas por la bifurcación y la combinación facilitan que varios desarrolladores trabajen en el mismo código base, lo que aumenta la eficacia. Con los sistemas de control distribuido, como Git, incluso es posible crear código en modo desconectado. La colaboración también implica revisiones por pares de las solicitudes de incorporación de cambios, promoviendo la compartición de conocimientos y la transparencia.
Automatización: el control de versiones es una parte esencial de la integración continua y las implementaciones automatizadas. La compilación y las pruebas automatizadas se pueden desencadenar automáticamente cada vez que se inserta una nueva versión del código en el repositorio de control de versiones o se combina con la rama principal. Se pueden implementar diferentes versiones del código en distintos entornos.