Descripción de las estadísticas de espera
Un enfoque completo para supervisar el rendimiento del servidor implica evaluar lo que el servidor está esperando. Las estadísticas de espera son complejas y SQL Server está equipada con cientos de tipos de espera que supervisan cada subproceso en ejecución y registran lo que el subproceso está esperando.
Para detectar y solucionar problemas de rendimiento de SQL Server de forma eficaz, es esencial comprender cómo funcionan las estadísticas de espera y cómo los utiliza el motor de base de datos durante el procesamiento de solicitudes. Este conocimiento le permite identificar cuellos de botella y optimizar el rendimiento con mayor precisión.
Las estadísticas de espera se dividen en tres tipos de espera: esperas de recursos, esperas de colas y esperas externas.
- Las esperas de recursos se producen cuando un subproceso de trabajo de SQL Server solicita acceso a un recurso que un subproceso usa actualmente. Algunos ejemplos de espera de recursos son bloqueos, bloqueos temporales y esperas de E/S de disco.
- Cola espera se producen cuando un subproceso de trabajo está inactivo y esperando que se asigne trabajo. Las esperas de cola de ejemplo son la supervisión de interbloqueos y la limpieza de registros eliminados.
- Las esperas externas se producen cuando SQL Server espera a que se complete un proceso externo, como una consulta de servidor vinculado. Un ejemplo de una espera externa es una espera de red, relacionada con la devolución de un gran conjunto de resultados a una aplicación cliente.
Puede comprobar sys.dm_os_wait_stats vista del sistema para explorar todas las esperas encontradas por subprocesos que se ejecutan y sys.dm_db_wait_stats para Azure SQL Database. La vista del sistema sys.dm_exec_session_wait_stats enumera las sesiones de espera activas.
Estas vistas del sistema le permiten obtener información general sobre el rendimiento del servidor y identificar fácilmente problemas de configuración o hardware. Estos datos se conservan desde el inicio de la instancia, pero los datos se pueden borrar según sea necesario para identificar los cambios.
Las estadísticas de espera se evalúan como porcentaje del total de esperas en el servidor.
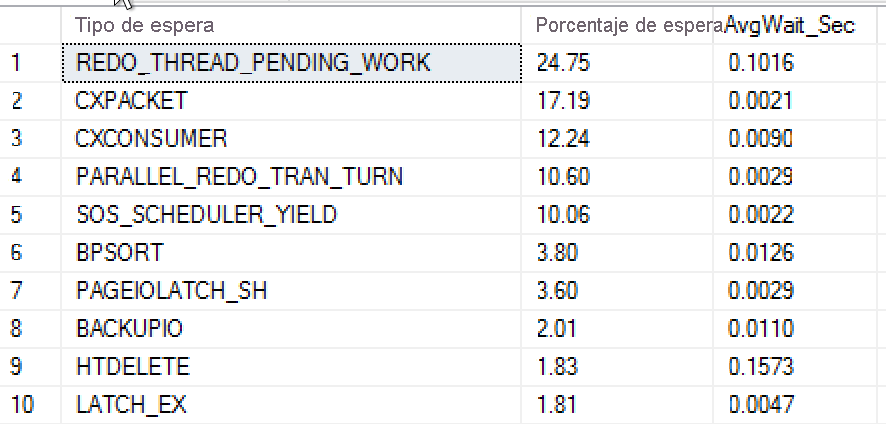
El resultado de esta consulta de sys.dm_os_wait_stats muestra el tipo de espera y la agregación del porcentaje de tiempo de espera (columna Porcentaje de espera) y el tiempo de espera promedio en segundos para cada tipo de espera.
En este caso, el servidor tiene grupos de disponibilidad Always On, tal y como se indica en los tipos de espera REDO_THREAD_PENDING_WORK y PARALLEL_REDO_TRAN_TURN. El porcentaje relativamente alto de esperas CXPACKET y SOS_SCHEDULER_YIELD indica que la CPU de este servidor está bajo algo de presión.
Como las DMV proporcionan una lista de tipos de espera con el mayor tiempo acumulado desde el último inicio de SQL Server, recopilar y almacenar periódicamente datos de estadísticas de espera podría ayudarle a comprender y correlacionar problemas de rendimiento con otros eventos de la base de datos.
Teniendo en cuenta que las DMV proporcionan una lista de tipos de espera con el tiempo acumulado más alto desde el último inicio de SQL Server, recopilar y almacenar periódicamente estadísticas de espera puede ayudarle a comprender y correlacionar los problemas de rendimiento con otros eventos de la base de datos.
Hay varios tipos de esperas disponibles en SQL Server, pero algunos de ellos son comunes.
RESOURCE_SEMAPHORE: indica que las consultas están esperando a que la memoria esté disponible, a menudo debido a concesiones excesivas de memoria a determinadas consultas. Este problema normalmente se manifiesta como tiempos de ejecución de consulta largos o incluso tiempos de espera. Las causas de estos tipos de espera pueden incluir estadísticas obsoletas, índices que faltan y simultaneidad de consultas elevadas.
LCK_M_X: suele indicar un problema de bloqueo. Este problema se puede resolver cambiando al nivel de aislamiento, optimizando la
READ COMMITTED SNAPSHOTindexación para reducir los tiempos de transacción o mejorando la administración de transacciones en el código T-SQL.PAGEIOLATCH_SH: este tipo de espera puede indicar problemas con índices o la ausencia de índices útiles, lo que hace que SQL Server examine cantidades excesivas de datos. Como alternativa, si el recuento de esperas es bajo, pero el tiempo de espera es alto, puede sugerir problemas de rendimiento de almacenamiento. Puede observar este comportamiento mediante el análisis de los datos de las
waiting_tasks_countcolumnas ywait_time_msde la vista delsys.dm_os_wait_statssistema para calcular el tiempo de espera promedio de un tipo de espera determinado.SOS_SCHEDULER_YIELD— este tipo de espera puede indicar un uso elevado de la CPU, que se correlaciona con un gran número de exámenes grandes o índices que faltan, y a menudo con un gran número de CXPACKET esperas.
CXPACKET: una alta aparición de este tipo de espera puede indicar una configuración incorrecta. Antes de SQL Server 2019, la configuración predeterminada para el grado máximo de paralelismo (MAXDOP) era usar todas las CPU disponibles para las consultas. Además, el umbral de costo para paralelismo se estableció en 5, lo que podría hacer que las consultas pequeñas se ejecuten en paralelo y limitar el rendimiento. Para reducir este tipo de espera, puede disminuir el valor de MAXDOP y aumentar el umbral de costo para el paralelismo. Sin embargo, el tipo de esperaCXPACKET también puede indicar un uso elevado de la CPU, que normalmente se resuelve a través del ajuste del índice.
PAGEIOLATCH_UP— Este tipo de espera en páginas de datos 2:1:1 puede indicar la contención de TempDB en páginas de datos espacio libre de páginas (PFS). Cada archivo de datos tiene una página PFS por cada 64 MB de datos. Esta espera suele deberse a que solo hay un archivo TempDB, como antes de SQL Server 2016, el comportamiento predeterminado era usar un archivo de datos para TempDB. El procedimiento recomendado para TempDB es usar un archivo por núcleo de CPU, hasta ocho archivos. También es importante asegurarse de que los archivos de datos de TempDB tengan el mismo tamaño y tengan el mismo valor de crecimiento automático para asegurar que se usen de manera uniforme. SQL Server 2016 y versiones posteriores controlan el crecimiento de los archivos de datos de TempDB para asegurar que crezcan de manera coherente y simultánea.
Además de las DMV mencionadas anteriormente, el Almacén de consultas también realiza un seguimiento de las esperas asociadas a consultas específicas. Aunque los datos de espera de los que realiza seguimiento el Almacén de Consultas no son tan granulares como los datos de las DMV, aún proporcionan una visión general útil de lo que una consulta está esperando.