Comprensión del procesamiento de flujos y por lotes
Tip
Consulte la pestaña Texto e imágenes para obtener más detalles.
El procesamiento de datos es simplemente la conversión de datos sin procesar en información significativa a través de un proceso. Existen dos métodos generales para procesar los datos:
- Procesamiento por lotes, en el que se recopilan y almacenan varios registros de datos antes de procesarse juntos en una sola operación.
- Procesamiento de flujos, en el que un origen de datos se supervisa y procesa constantemente en tiempo real a medida que se producen nuevos eventos de datos.
Comprender el procesamiento por lotes
En el procesamiento por lotes, los elementos de datos recién llegados se recopilan y almacenan, y todo el grupo se procesa conjuntamente como un lote. El momento en el que se procesa cada grupo se puede determinar de varias maneras. Por ejemplo, los datos se pueden procesar según un intervalo de tiempo programado (por ejemplo, cada hora), o bien el procesamiento puede desencadenarse cuando se alcance una determinada cantidad de datos o como resultado de algún otro evento.
Por ejemplo, supongamos que quiere analizar el tráfico de carreteras contando el número de automóviles en un tramo de carretera. Un enfoque de procesamiento por lotes requeriría recopilar los automóviles de un aparcamiento y, a continuación, contarlos en una sola operación mientras están en reposo.

Si la carretera está ocupada, con un gran número de automóviles que conducen a intervalos frecuentes, este enfoque puede ser poco práctico. Tenga en cuenta que no obtiene ningún resultado hasta que haya estacionado un lote de automóviles y los haya contado.
Un ejemplo real de procesamiento por lotes es la forma en que las empresas de tarjetas de crédito controlan la facturación. El cliente no recibe una factura por cada compra que hace con su tarjeta de crédito, sino una factura mensual para todas las compras de ese mes.
| Aspecto | Ventajas del procesamiento por lotes | Desventajas del procesamiento por lotes |
|---|---|---|
| Capacidad de procesamiento | Los grandes volúmenes de datos se pueden procesar de forma eficaz en un momento conveniente. | Todos los datos de entrada deben estar totalmente preparados para poder comenzar el procesamiento. |
| Uso del sistema | Los trabajos se pueden programar durante las horas inactivas o fuera del pico (por ejemplo, durante la noche), lo que mejora el uso de los recursos. | A menudo hay un retraso entre la entrada de datos y la recepción de resultados. |
| Confiabilidad y control de errores | — | Los errores de datos, bloqueos o errores de programa pueden detener todo el proceso por lotes. |
| Validación de datos | — | Los datos de entrada deben comprobarse cuidadosamente antes de volver a ejecutar el trabajo por lotes. |
| Impacto de errores menores | — | Incluso los errores de datos pequeños pueden impedir que todo el trabajo por lotes se ejecute correctamente. |
Comprender el procesamiento de flujos
En el procesamiento de flujos, cada nuevo fragmento de datos se procesa cuando llega. A diferencia del procesamiento por lotes, no hay espera hasta el siguiente intervalo de procesamiento por lotes: los datos se procesan como unidades individuales en tiempo real en lugar de procesarse un lote a la vez. El procesamiento de datos de flujos es beneficioso en los escenarios donde se generan datos dinámicos nuevos de forma continua.
Por ejemplo, un enfoque mejor para nuestro hipotético problema de recuento de automóviles podría ser aplicar un enfoque de flujo de datos, contando los automóviles en tiempo real a medida que pasan:
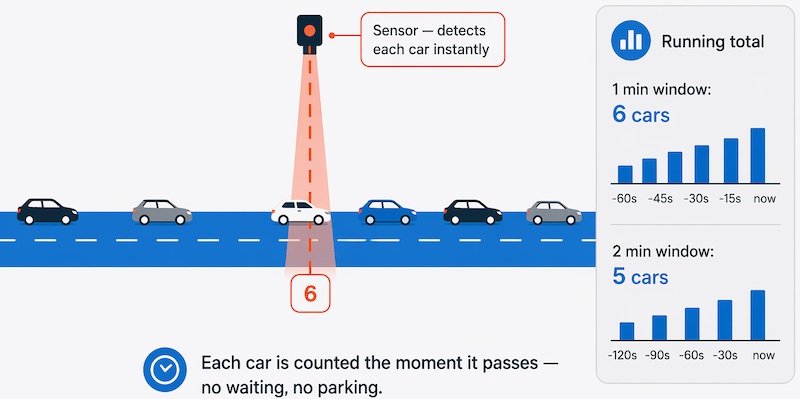
En este enfoque, no es necesario esperar hasta que todos los automóviles hayan estacionado para comenzar a procesarlos, y puede sumar los datos a lo largo de intervalos de tiempo. Por ejemplo, contando el número de automóviles que pasan cada minuto.
Entre los ejemplos reales de datos en streaming se incluyen:
- Una institución financiera realiza un seguimiento de los cambios en el mercado de valores en tiempo real, calcula el valor en riesgo y reequilibra automáticamente las carteras en función de los movimientos de precio de las acciones.
- Una empresa de juegos en línea recopila datos en tiempo real sobre las interacciones de los jugadores con los juegos y los incorpora en su plataforma de juegos. Después, analiza los datos en tiempo real y ofrece incentivos y experiencias dinámicas para atraer a los jugadores.
- Un sitio web inmobiliario hace un seguimiento de un subconjunto de datos de dispositivos móviles y ofrece recomendaciones en tiempo real de las propiedades que pueden visitar los clientes en función de su ubicación geográfica.
El procesamiento de flujos es ideal para las operaciones críticas en tiempo que requieren una respuesta instantánea en tiempo real. Por ejemplo, un sistema que supervisa la presencia de humo y altas temperaturas en un edificio necesita activar alarmas y desbloquear puertas para permitir que los residentes puedan salir inmediatamente en caso de que se produzca un incendio.
Comprender las diferencias entre los datos por lotes y de streaming
Además de las diferencias en la forma en que el procesamiento por lotes y en streaming controlan los datos, hay otras diferencias:
Ámbito de los datos: el procesamiento por lotes puede procesar todos los datos del conjunto de datos. Normalmente, el procesamiento en streaming solo tiene acceso a los datos más recientemente recibidos o dentro de una ventana de tiempo móvil (los últimos 30 segundos, por ejemplo).
Tamaño de los datos: el procesamiento por lotes es adecuado para administrar grandes conjuntos de datos de forma eficaz. El procesamiento en streaming está diseñado para registros individuales o microlotes que constan de pocos registros.
Rendimiento: la latencia es el tiempo que se tarda en recibir y procesar los datos. la latencia del procesamiento por lotes suele ser de unas horas. Normalmente, el procesamiento en streaming se produce inmediatamente, con la latencia en segundos o milisegundos.
Análisis: normalmente se usa el procesamiento por lotes para realizar análisis complejos. El procesamiento en streaming se usa para funciones de respuesta simples, agregaciones o cálculos, como el cálculo de la media acumulada.
Combinación del procesamiento por lotes y por flujos
Muchas soluciones de análisis a gran escala incluyen una combinación de procesamiento por lotes y de flujos, lo que permite el análisis de datos históricos y en tiempo real. Es habitual que las soluciones de procesamiento de flujos capturen datos en tiempo real, los filtren o agreguen para procesarlos y los presenten a través de paneles y visualizaciones en tiempo real (por ejemplo, muestran el total de automóviles que han pasado por una carretera durante la hora actual), al tiempo que también se conservan los resultados procesados en un almacén de datos para el análisis histórico junto con los datos procesados por lotes (por ejemplo, para habilitar el análisis de los volúmenes de tráfico durante el último año).
Incluso cuando no se requiere análisis o visualización de datos en tiempo real, las tecnologías de streaming a menudo se usan para capturar datos en tiempo real y almacenarlos en un almacén de datos para el posterior procesamiento por lotes (esto equivale a redirigir todos los coches que viajan a lo largo de una carretera a un estacionamiento antes de contarlos).
En el diagrama siguiente se muestra una arquitectura lambda, un patrón común para combinar el procesamiento por lotes y flujos en una solución de análisis de datos a gran escala.
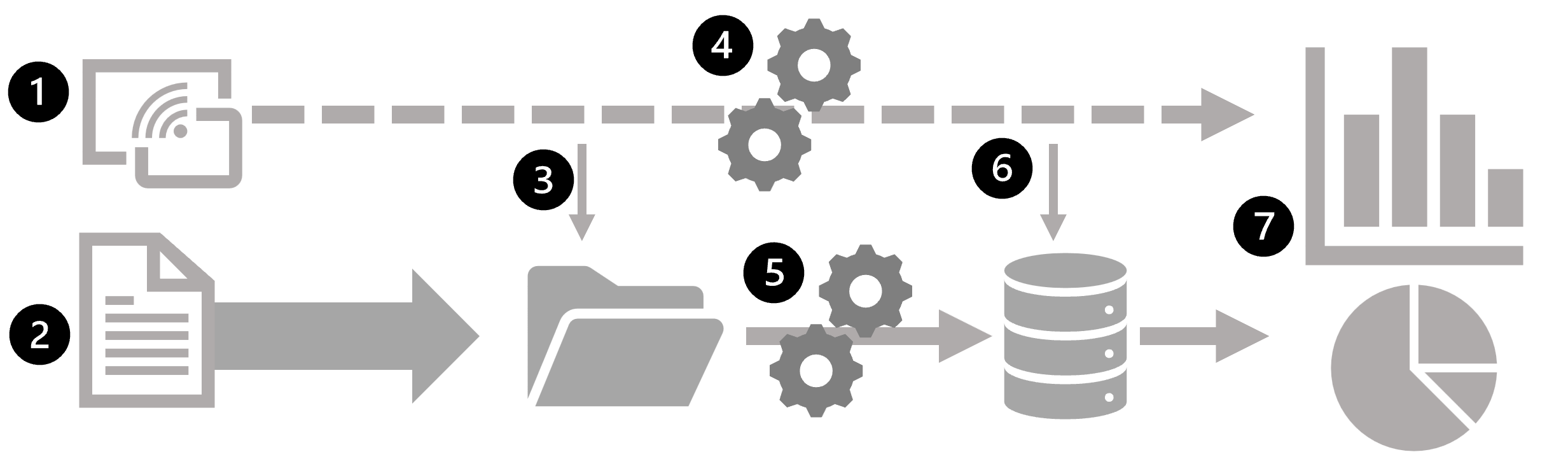
- Los eventos de datos de un origen de datos de streaming se capturan en tiempo real.
- Los datos de otros orígenes se ingieren en un almacén de datos (a menudo, un lago de datos) para el procesamiento por lotes.
- Si no se requiere análisis en tiempo real, los datos de streaming capturados se escriben en el almacén de datos para su posterior procesamiento por lotes.
- Cuando se requiere un análisis en tiempo real, se usa una tecnología de procesamiento de flujos para preparar los datos de flujos para el análisis o visualización en tiempo real. A menudo, se filtran o suman los datos por periodos de tiempo.
- Los datos que no son de transmisión por lotes se procesan periódicamente para prepararlos para su análisis y los resultados se conservan en un almacén de datos analíticos (a menudo denominado almacenamiento de datos) para el análisis histórico.
- Los resultados del procesamiento de flujos también se pueden conservar en el almacén de datos analíticos para admitir el análisis histórico.
- Las herramientas analíticas y de visualización se usan para presentar y explorar los datos históricos y en tiempo real.
Nota:
Entre las arquitecturas de soluciones usadas con más frecuencia para un procesamiento de datos de flujos y por lotes de manera combinada, se encuentran arquitecturaslambda y delta. La arquitectura kappa es una alternativa más sencilla que elimina completamente la capa de lote independiente, tratando todos los datos como una secuencia continua y reproduciendolos cuando se necesita reprocesamiento histórico. Las plataformas modernas, como Microsoft Fabric y Apache Kafka, hacen que las soluciones de estilo kappa sean cada vez más prácticas. Los detalles de estas arquitecturas están fuera del ámbito de este curso.