Describir la normalización
La normalización de la base de datos es un proceso de diseño que se usa para organizar los datos en tablas y columnas dentro de una base de datos. Cada tabla debe contener datos relacionados con una entidad específica e incluir solo información que admita esa entidad. El objetivo principal de la normalización es minimizar los datos duplicados dentro de la base de datos, lo que ayuda a evitar la degradación del rendimiento durante las inserciones y actualizaciones. Por ejemplo, si es necesario actualizar la dirección de un cliente, es más sencillo implementar el cambio si la dirección se almacena en una sola ubicación, como la Customers tabla.
Las formas más comunes de normalización son las formas primero, segunda y tercera normal.
Primer formulario normal
El primer formulario normal tiene las siguientes especificaciones:
- Crear una tabla independiente para cada conjunto de datos relacionados
- Eliminación de grupos repetidos en tablas individuales
- Identificar cada conjunto de datos relacionados con una clave principal
En este modelo, debe evitar el uso de varias columnas en una sola tabla para almacenar datos similares. Por ejemplo, si un producto puede tener varios colores, no debe tener varias columnas en una sola fila que contenga los distintos valores de color. La primera tabla siguiente, ProductColors, no está en el primer formato normal porque tiene valores repetidos para color. En el caso de los productos con un solo color, hay espacio desperdiciado. Además, si un producto entra en más de tres colores, resulta poco práctico establecer un número máximo de columnas. En su lugar, podemos volver a crear la tabla como se muestra en la segunda tabla, ProductColor.
El primer formulario normal también requiere que haya una clave única para la tabla, que es una columna (o columnas) cuyo valor identifica de forma única cada fila. En la segunda tabla, ninguna de las columnas es única por sí sola, pero juntas, la combinación de ProductID y Color forma una clave única. Cuando se necesitan varias columnas para crear una clave única, se conoce como clave compuesta.
ProductColorsmesa:Productid #C1 Color1 de #B0 Color2 #C1 color3 de #B0 1 Rojo Verde Amarillo 2 Amarillo 3 Azul Rojo 4 Azul 5 Rojo ProductColormesa:Productid color 1 Rojo 1 Verde 1 Amarillo 2 Amarillo 3 Azul 3 Rojo 4 Azul 5 Rojo
La tercera tabla, ProductInfo, tiene la primera forma normal porque cada fila hace referencia a un producto determinado, no hay grupos repetidos y tenemos la columna ProductID para usarla como clave principal.
| Productid | ProductName | Precio | #B0 ProductionCountry #C1 | #B0 shortLocation #C1 |
|---|---|---|---|---|
| 1 | Widget | 15.95 | Estados Unidos | EE. UU. |
| 2 | Foop | 41.95 | Reino Unido | Reino Unido |
| 3 | Glombit | 49.95 | Reino Unido | Reino Unido |
| 4 | Sorfin | 99.99 | República de Filipinas | RepPhil |
| 5 | Bolt de tallo | 29.95 | Estados Unidos | EE. UU. |
Segunda forma normal
La segunda forma normal tiene la especificación siguiente, además de las requeridas por la primera forma normal:
- Si la tabla tiene una clave compuesta, todos los atributos deben depender de la clave completa y no solo de ella.
El segundo formulario normal solo es relevante para las tablas con claves compuestas, como en la tabla ProductColor, que es la segunda tabla. Tenga en cuenta el caso en el que la ProductColor tabla también incluye el precio del producto. Esta tabla tiene una clave compuesta en ProductID y Color, porque solo el uso de ambos valores de columna puede identificar de forma única una fila. Si el precio de un producto no cambia con el color, es posible que veamos los datos como se muestra en esta tabla.
| Productid | color | Precio |
|---|---|---|
| 1 | Rojo | 15.95 |
| 1 | Verde | 15.95 |
| 1 | Amarillo | 15.95 |
| 2 | Amarillo | 41.95 |
| 3 | Azul | 49.95 |
| 3 | Rojo | 49.95 |
| 4 | Azul | 99,95 |
| 5 | Rojo | 29.95 |
Esta tabla no está en segundo formato normal. El valor de precio depende de , ProductID pero no de .Color Hay tres filas para ProductID 1, por lo que el precio de ese producto se repite tres veces. El problema con infringir la segunda forma normal es que si necesitamos actualizar el precio, debemos asegurarnos de que se actualice en todas partes. Si actualizamos el precio en la primera fila pero no en la segunda o tercera, encontraríamos una anomalía de actualización. Después de la actualización, no podríamos determinar el precio real de ProductID 1. La solución consiste en mover la Price columna a una tabla que tiene ProductID como clave de columna única, ya que es la única columna de la que Price depende. Por ejemplo, podríamos usar la tabla 3 para almacenar .Price
Si el precio de un producto era diferente en función de su color, la cuarta tabla estaría en la segunda forma normal, ya que el precio dependía de ambas partes de la clave: y ProductIDColor.
Tercera forma normal
El tercer formato normal suele ser el objetivo de la mayoría de las bases de datos OLTP. La tercera forma normal tiene la especificación siguiente, además de las requeridas por segunda forma normal:
- Todas las columnas que no son clave dependen de forma notransitiva de la clave principal.
Una relación transitiva implica que una columna de una tabla está relacionada con otras columnas a través de una segunda columna. Dependencia significa que una columna puede derivar su valor de otro como resultado de esta relación. Por ejemplo, su edad se puede determinar a partir de su fecha de nacimiento, haciendo que su edad dependa de su fecha de nacimiento. Consulte la tercera tabla, ProductInfo. Esta tabla está en segundo formato normal, pero no en tercera. La ShortLocation columna depende de la ProductionCountry columna, que no es la clave. Al igual que la segunda forma normal, infringir la tercera forma normal puede provocar anomalías de actualización. Terminaríamos con datos incoherentes si actualizamos en ShortLocation una fila, pero no lo actualizamos en todas las filas donde se produjo esa ubicación. Para evitar esto, podríamos crear una tabla independiente para almacenar los nombres de país o región y sus formularios abreviados.
Desnormalización
Aunque la tercera forma normal es teóricamente deseable, no siempre es posible para todos los datos. Además, una base de datos normalizada no siempre proporciona el mejor rendimiento. Los datos normalizados suelen requerir varias operaciones de combinación para obtener todos los datos necesarios devueltos en una sola consulta. Hay un equilibrio entre normalizar los datos cuando el número de combinaciones necesarias para devolver los resultados de la consulta tiene un uso elevado de la CPU y datos desnormalizados que tienen menos combinaciones y menos CPU necesaria, pero abre la posibilidad de anomalías de actualización.
Los datos desnormalizados pueden ser más eficaces para realizar consultas, especialmente para cargas de trabajo intensivas de lectura, como un almacenamiento de datos. En esos casos, tener columnas adicionales puede ofrecer mejores patrones de consulta o más consultas simplistas.
Esquema de estrella
Aunque la mayoría de la normalización está destinada a cargas de trabajo OLTP, los almacenes de datos tienen su propia estructura de modelado, que normalmente es un modelo desnormalizado . Este diseño usa tablas de hechos para registrar medidas o métricas para eventos específicos, como ventas, y combinarlas con tablas de dimensiones. Las tablas de dimensiones son más pequeñas en términos de recuento de filas, pero pueden tener un gran número de columnas para describir los datos de hechos. Algunos ejemplos de dimensiones incluyen inventario, tiempo y geografía. Este patrón de diseño facilita la consulta de la base de datos y ofrece mejoras de rendimiento para cargas de trabajo de lectura.
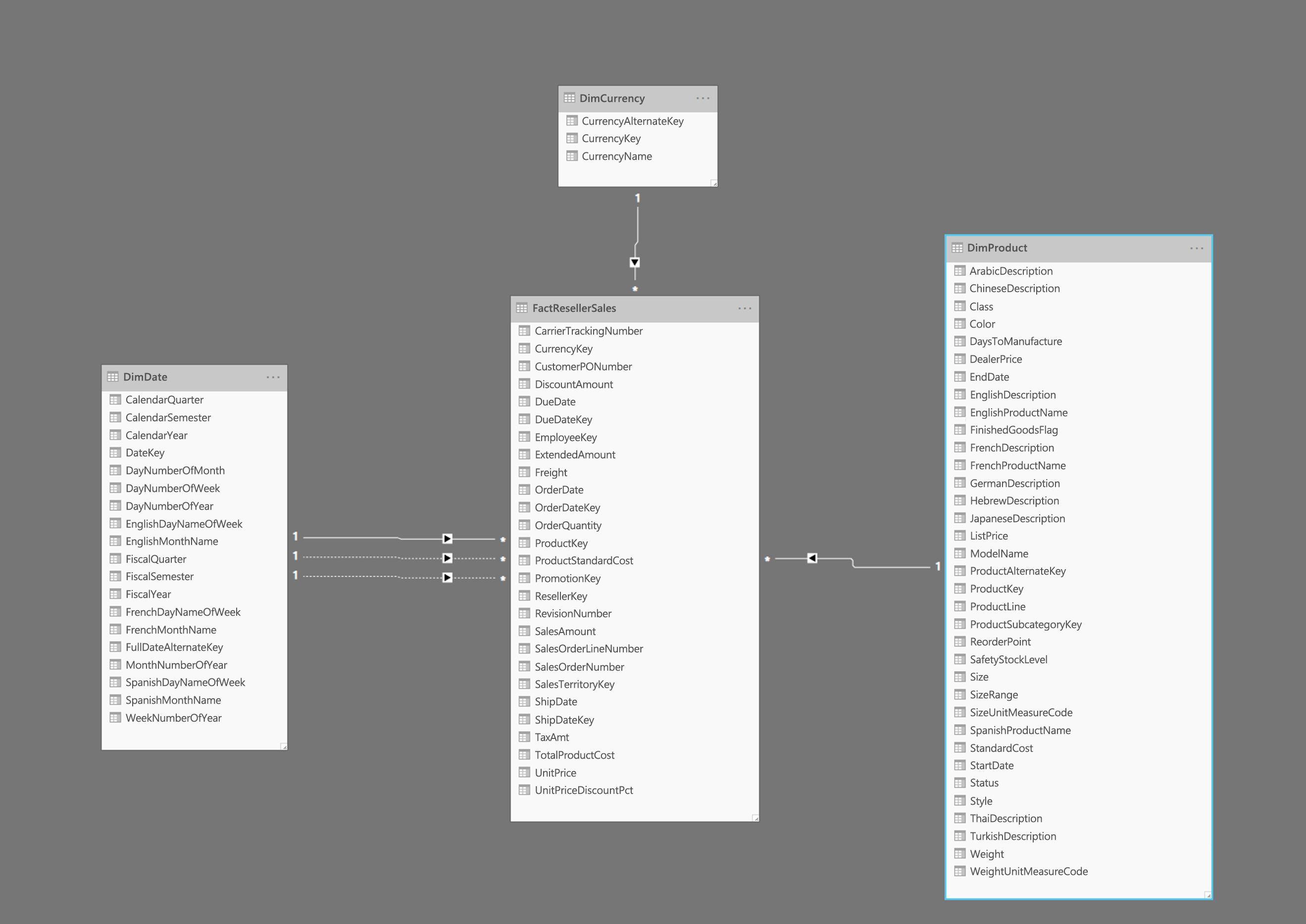
La imagen muestra un ejemplo de un esquema de estrella, con una FactResellerSales tabla de hechos y dimensiones para la fecha, la moneda y los productos. La tabla de hechos contiene datos relacionados con las transacciones de ventas, mientras que las dimensiones solo contienen datos relacionados con elementos específicos de los datos de ventas. Por ejemplo, la FactResellerSales tabla solo incluye un ProductKey para indicar qué producto se vendió. Todos los detalles de cada producto se almacenan en la DimProduct tabla y se relacionan con la tabla de hechos mediante la ProductKey columna .
Relacionado con el diseño de esquema de estrella es el esquema de copo de nieve, que usa un conjunto de tablas más normalizadas para una sola entidad empresarial. En la imagen siguiente se muestra un ejemplo de una sola dimensión en un esquema de copo de nieve. La dimensión Products se normaliza y almacena en tres tablas: DimProductCategory, DimProductSubcategoryy DimProduct.
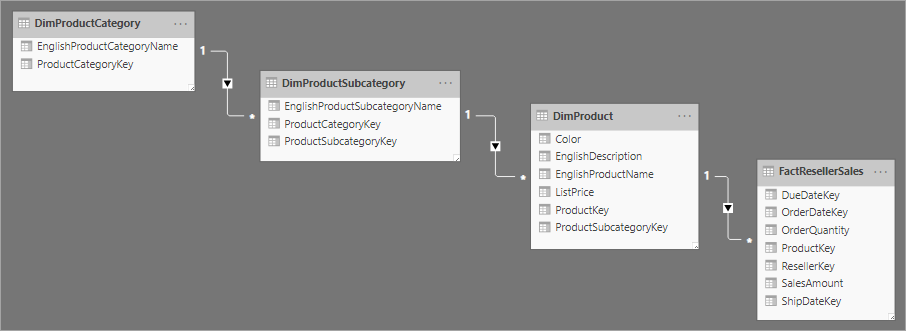
La principal diferencia entre los esquemas de estrella y copo de nieve es que las dimensiones de un esquema de copo de nieve se normalizan para reducir la redundancia, lo que ahorra espacio de almacenamiento. El inconveniente es que las consultas requieren más combinaciones, lo que puede aumentar la complejidad y reducir el rendimiento.