Diseñar índices
SQL Server ofrece varios tipos de índice para admitir diferentes cargas de trabajo. En un nivel alto, se puede considerar un índice como una estructura en disco asociada a una tabla o vista, lo que permite a SQL Server encontrar más fácilmente la fila o las filas asociadas a la clave de índice (que consta de una o varias columnas de la tabla o vista), en comparación con el examen de toda la tabla.
Índices agrupados
Una pregunta común de la entrevista de trabajo de DBA es formular al candidato la diferencia entre un índice agrupado y no clúster, ya que los índices son tecnologías fundamentales de almacenamiento de datos en SQL Server. Un índice agrupado es la tabla subyacente, almacenada en orden ordenado en función del valor de clave. Solo puede haber un índice agrupado en una tabla determinada porque las filas solo se pueden almacenar en un orden. Normalmente, una tabla sin un índice agrupado se denomina montón y los montones solo se usan como tablas de almacenamiento provisional. Un principio de diseño de rendimiento importante es mantener la clave de índice agrupada lo más estrecha posible. Al considerar una o varias columnas de clave para el índice agrupado, debe elegir columnas únicas o contener muchos valores distintos. Otra propiedad de una buena clave de índice agrupada es para los registros a los que se accede secuencialmente y se usan con frecuencia para ordenar los datos recuperados de la tabla. Tener el índice agrupado en la columna usada para la ordenación puede impedir el costo de ordenar cada vez que se ejecute la consulta porque los datos ya se almacenarán en el orden deseado.
Nota:
Cuando decimos que la tabla se "almacena" en un orden determinado, nos referimos al orden lógico, no al orden físico en disco. Los índices tienen punteros entre páginas y los punteros ayudan a crear el orden lógico. Al examinar un índice en orden, SQL Server sigue los punteros de la página a la página. Inmediatamente después de crear un índice, es más probable que también se almacene en orden físico en el disco, pero después de empezar a realizar modificaciones en los datos y las páginas nuevas deben agregarse al índice, los punteros seguirán dando el orden lógico correcto, pero las páginas nuevas probablemente no estarán en orden de disco físico.
Índices no agrupados
Los índices no clúster son estructuras independientes de las filas de datos. Un índice no clúster contiene los valores de clave definidos para el índice y un puntero a la fila de datos que contiene el valor de clave. Puede agregar columnas no clave adicionales al nivel hoja del índice no agrupado mediante la característica de columnas incluidas en SQL Server, lo que le permite cubrir más columnas. Puede crear varios índices no agrupados en una tabla.
En el ejemplo siguiente se muestra cuándo necesita agregar un índice o agregar columnas a un índice no clúster existente.
Plan de consulta y plan de ejecución de consulta con un operador de búsqueda de claves
El plan de consulta indica que para cada fila recuperada mediante la búsqueda de índice, es necesario recuperar más datos del índice agrupado (la propia tabla). Hay un índice no clúster, pero solo incluye la columna de producto. Si agrega las otras columnas de la consulta a un índice no agrupado, puede ver el cambio del plan de ejecución para eliminar la consulta de claves.
" "
"
El índice creado anteriormente es un ejemplo de un índice de cobertura. Además de la columna de clave, se incluyen columnas adicionales para cubrir la consulta y eliminar la necesidad de acceder a la propia tabla.
Tanto los índices no agrupados como los clústeres se pueden definir como únicos, lo que significa que no puede haber duplicación de los valores de clave. Los índices únicos se crean automáticamente al crear una restricción PRIMARY KEY o UNIQUE en una tabla.
Esta sección se centra en los índices de árbol-B en SQL Server, también conocidos como índices de almacenamiento por filas. La imagen siguiente representa la estructura general de un árbol b:
La arquitectura de árbol B de un índice en SQL Server y Azure SQL.
Cada página de un árbol b de índice se denomina nodo de índice y el nodo superior del árbol b se denomina nodo raíz. Los nodos inferiores de un índice se denominan nodos hoja, y el conjunto de nodos hoja constituye el nivel hoja.
El diseño de índices es una mezcla de arte y ciencia. Un índice estrecho con pocas columnas en su clave requiere menos tiempo para actualizar y tiene una menor sobrecarga de mantenimiento; sin embargo, puede que no sea útil para tantas consultas como un índice más amplio que incluya más columnas. Es posible que tenga que experimentar con varios enfoques de indexación en función de las columnas seleccionadas por las consultas de la aplicación. Por lo general, el optimizador de consultas elegirá lo que considera que es el mejor índice existente para una consulta; sin embargo, eso no significa que no haya un índice mejor que se pueda compilar.
La indexación correcta de una base de datos puede ser una tarea compleja. Al planear los índices para una tabla, debe tener en cuenta algunos principios básicos:
- Comprenda las cargas de trabajo del sistema. Las tablas usadas principalmente para las operaciones de inserción se benefician menos de índices adicionales en comparación con las tablas usadas para las operaciones de almacenamiento de datos con una actividad de lectura elevada.
- Optimice los índices en torno a las consultas que se ejecutan con más frecuencia.
- Elija los tipos de datos adecuados para las columnas de las consultas. Los índices funcionan mejor con tipos de datos enteros, columnas únicas o no null.
- Cree índices no agrupados en columnas que se usan con frecuencia en predicados y cláusulas de combinación, manteniéndolos lo más estrechos posibles para minimizar la sobrecarga.
- Considere el tamaño o el volumen de los datos. Los escaneos en tablas pequeñas son relativamente baratos, mientras que en tablas grandes son caros.
Otra opción proporcionada por SQL Server es la creación de índices filtrados. Los índices filtrados son ideales para las columnas de tablas grandes en las que un porcentaje significativo de filas comparten el mismo valor en esa columna. En el ejemplo siguiente se muestra una tabla de empleados que almacena registros de todos los empleados, incluidos aquellos que se han dejado o retirado.
CREATE TABLE [HumanResources].[Employee](
[BusinessEntityID] [int] NOT NULL,
[NationalIDNumber] [nvarchar](15) NOT NULL,
[LoginID] [nvarchar](256) NOT NULL,
[OrganizationNode] [hierarchyid] NULL,
[OrganizationLevel] AS ([OrganizationNode].[GetLevel]()),
[JobTitle] [nvarchar](50) NOT NULL,
[BirthDate] [date] NOT NULL,
[MaritalStatus] [nchar](1) NOT NULL,
[Gender] [nchar](1) NOT NULL,
[HireDate] [date] NOT NULL,
[SalariedFlag] [bit] NOT NULL,
[VacationHours] [smallint] NOT NULL,
[SickLeaveHours] [smallint] NOT NULL,
[CurrentFlag] [bit] NOT NULL,
[rowguid] [uniqueidentifier] ROWGUIDCOL NOT NULL,
[ModifiedDate] [datetime] NOT NULL)
En esta tabla, hay una columna denominada CurrentFlag, que indica si un empleado está empleado actualmente. En este ejemplo se usa el bit tipo de datos , que representa dos valores: uno para el empleado actualmente y cero para no empleados actualmente. La creación de un índice filtrado con WHERE CurrentFlag = 1 en la CurrentFlag columna permite consultas eficaces de los empleados actuales.
Además, puede crear índices en las vistas, lo que puede proporcionar mejoras de rendimiento significativas cuando las vistas contienen elementos de consulta como agregaciones o combinaciones de tabla.
Índices de almacén de columnas
Los índices columnstore ofrecen un rendimiento mejorado para las consultas que implican grandes cargas de trabajo de agregación. Inicialmente dirigido a almacenes de datos, los índices de almacén de columnas se han adoptado desde entonces para otras cargas de trabajo para solucionar problemas de rendimiento de consultas en tablas grandes. Al igual que los índices de árbol b, un índice de almacén de columnas agrupado representa la propia tabla almacenada de forma especial, mientras que los índices de almacén de columnas no agrupados se almacenan independientemente de la tabla. Los índices de almacén de columnas agrupados incluyen inherentemente todas las columnas de una tabla, pero no están ordenadas.
Normalmente, los índices de almacén de columnas no agrupados se usan en dos escenarios. La primera es cuando el tipo de datos de una columna no se admite en un índice de almacén de columnas (por ejemplo, XML, CLR, sql_variant, ntext, text e image). Dado que un índice de almacén de columnas agrupado siempre contiene todas las columnas de la tabla, un índice no clúster es la única opción. El segundo escenario implica índices filtrados, usados en arquitecturas híbridas de procesamiento analítico transaccional (HTAP), donde los datos se cargan en la tabla mientras se ejecutan los informes simultáneamente. El filtrado del índice (normalmente en un campo de fecha) permite un rendimiento eficaz de inserción e informes.
Los índices de almacenamiento en columnas almacenan cada columna de forma independiente, lo que ofrece dos ventajas: la reducción del IO al examinar solo las columnas necesarias y una mayor compresión debido a datos similares dentro de las columnas. Funcionan mejor en consultas analíticas que examinan grandes conjuntos de datos, como tablas de hechos en almacenes de datos. Puede aumentar un índice de almacén de columnas con un índice no agrupado de árbol b para búsquedas de valores singleton.
Estos índices también se benefician del modo de ejecución por lotes, procesando conjuntos de aproximadamente 900 filas a la vez en lugar de una por una. Este enfoque reduce significativamente las instrucciones de CPU.
SELECT SUM(Sales) FROM SalesAmount;
El modo por lotes puede proporcionar un aumento del rendimiento en el procesamiento de filas tradicional. Aunque el modo por lotes para el almacenamiento por filas no tiene el mismo nivel de rendimiento de lectura que un índice de almacén de columnas, las consultas analíticas pueden experimentar una mejora de rendimiento de hasta cinco veces.
Otra ventaja de los índices de almacén de columnas para cargas de trabajo de almacenamiento de datos es la ruta de acceso de carga optimizada para operaciones de inserción masiva de 102 400 filas o más. Aunque 102 400 es el valor mínimo que se va a cargar directamente en el almacén de columnas, cada colección de filas, denominada grupo de filas, puede ser de hasta aproximadamente 1024 000 filas. Tener menos grupos de filas, pero más completos, hace SELECT que las consultas sean más eficaces porque es necesario examinar menos grupos de filas para recuperar los registros solicitados. Estas cargas se producen en la memoria y se cargan directamente en el índice. Para volúmenes más pequeños, los datos se escriben en una estructura de árbol b denominada almacén delta y se cargan asincrónicamente en el índice.
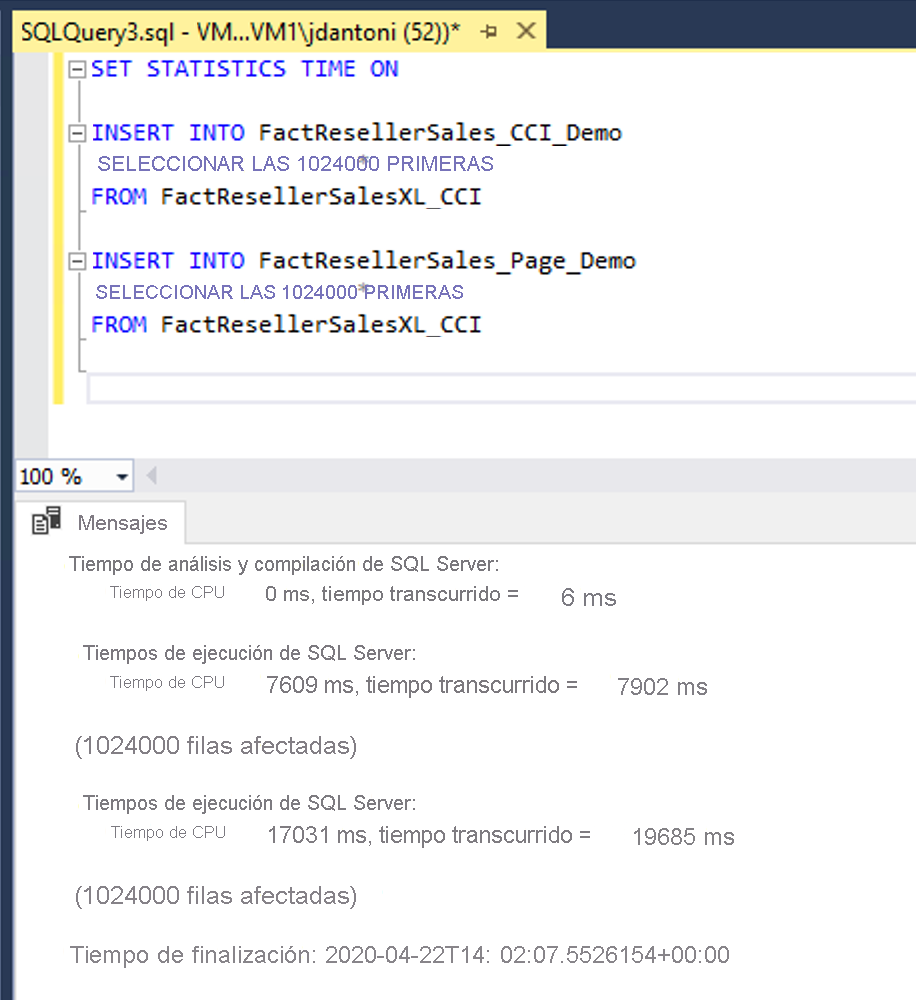
En este ejemplo, los mismos datos se cargan en dos tablas, FactResellerSales_CCI_Demo y FactResellerSales_Page_Demo. La tabla FactResellerSales_CCI_Demo tiene un índice de almacén de columnas agrupado y la tabla FactResellerSales_Page_Demo tiene un índice de árbol B agrupado con dos columnas y compresión de página. Como puede ver, cada tabla carga 1.024.000 filas desde la tabla FactResellerSalesXL_CCI. Cuando la opción SET STATISTICS TIME es ON, SQL Server realiza un seguimiento del tiempo transcurrido durante la ejecución de la consulta. Cargar los datos en las tablas columnstore tardó aproximadamente 8 segundos. La carga en las tablas de página comprimida, en cambio, tardó casi 20 segundos. En este ejemplo, todas las filas que se incluyen en el índice de almacén de columnas se cargan en un único grupo de filas.
Si se cargan menos de 102 400 filas de datos en un índice de almacén de columnas en una sola operación, se cargarán en una estructura de árbol B conocida como "almacén delta". El motor de base de datos moverá estos datos al índice de almacén de columnas mediante un proceso asincrónico denominado "motor de tupla". Tener almacenes delta abiertos puede afectar al rendimiento de las consultas, ya que la lectura de esos registros es menos eficiente que la lectura del almacén de columnas. También puede reorganizar el índice con la opción COMPRESS_ALL_ROW_GROUPS para forzar que los almacenes delta se agreguen y se compriman en los índices de almacén de columnas.