Exploración de las funcionalidades de Hiperescala
El nivel de servicio Hiperescala de Azure SQL Database es un nivel de servicio en el modelo de compra basado en vCore, ideal para cargas de trabajo empresariales. Este nivel de servicio es un nivel altamente escalable de almacenamiento y de rendimiento de proceso que usa Azure para escalar horizontalmente el almacenamiento y los recursos de proceso para una base de datos de Azure SQL considerablemente más allá de los límites disponibles para los niveles de servicio Uso general y Crítico para la empresa. Desacopla el motor de procesamiento de consultas de componentes de almacenamiento a largo plazo, lo que permite un escalado sin problemas de los recursos de proceso y almacenamiento.
Hiperescala simplifica la infraestructura y el diseño de aplicaciones, lo que permite a los desarrolladores centrarse en las necesidades empresariales en lugar de administrar recursos de base de datos.
Azure SQL Database solía limitarse a 4 TB de almacenamiento por base de datos. Sin embargo, el nivel de servicio Hiperescala ahora permite que las bases de datos superen los 100 TB. Hiperescala usa el escalado horizontal para agregar nodos de proceso a medida que crecen los datos. Aunque el costo es similar al de Azure SQL Database normal, hay un costo adicional por almacenamiento de terabyte.
Descripción de las ventajas
El nivel de servicio Hiperescala elimina muchas de las limitaciones prácticas que normalmente se encuentran en las bases de datos en la nube. A diferencia de la mayoría de las otras bases de datos restringidas por los recursos de un solo nodo, las bases de datos de Hiperescala no tienen estas restricciones. Con su arquitectura de almacenamiento flexible, el almacenamiento se expande según sea necesario y no hay ningún tamaño máximo predefinido. Solo paga por la capacidad que usa. Para cargas de trabajo de lectura intensiva, Hiperescala ofrece un escalado horizontal rápido mediante el aprovisionamiento de réplicas adicionales para descargar las operaciones de lectura.
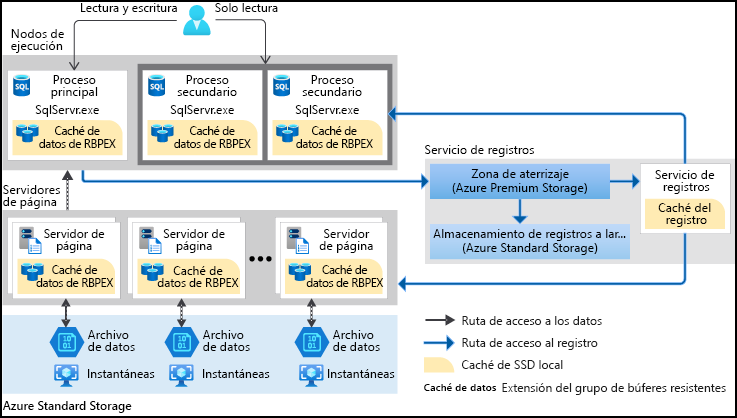
Además, el tiempo necesario para crear copias de seguridad de bases de datos o para escalar hacia arriba o hacia abajo ya no está ligado al volumen de datos. Pueden crearse copias de seguridad de las bases de datos de hiperescala de manera instantánea. También puede ampliar o reducir una base de datos de decenas de terabytes en cuestión de minutos. Esta funcionalidad le libra de la preocupación de estar atado por las opciones de la configuración inicial. Hiperescala también proporciona restauraciones rápidas de base de datos que se ejecutan en minutos en lugar de horas o días.
Hiperescala proporciona una rápida escalabilidad según la demanda de la carga de trabajo.
| Característica | Descripción | Prestación | Caso de uso |
|---|---|---|---|
| Escalar hacia arriba/abajo | Puede aumentar el tamaño de procesamiento principal en términos de recursos como CPU y memoria, y luego reducirlo, de manera constante. Dado que el almacenamiento se comparte, el escalado y la reducción vertical no están vinculados al volumen de datos de la base de datos. | Garantiza la flexibilidad y la eficacia en la administración de recursos. | Ideal para aplicaciones con distintas cargas de trabajo que requieren distintos niveles de potencia de proceso. |
| Scale In/Out | También puede aprovisionar una o varias réplicas de proceso para controlar las solicitudes de lectura. Estas réplicas de proceso adicionales actúan como réplicas de solo lectura, descargando la carga de trabajo de lectura del proceso principal. Además, estas réplicas sirven como esperas activas, listas para asumir el control si hay un error de proceso principal. | Mejora el rendimiento y la confiabilidad descargando cargas de trabajo de lectura y proporcionando funcionalidades de conmutación por error. | Adecuado para aplicaciones de lectura intensiva que necesitan alta disponibilidad y conmutación por error rápida. |
Maximizar el rendimiento
El nivel de servicio Hiperescala está diseñado para los clientes con bases de datos de SQL Server locales grandes que desean modernizar sus aplicaciones moviendo a la nube. También es ideal para los clientes que ya usan Azure SQL Database que desean ampliar significativamente su potencial de crecimiento de la base de datos. Además, Hiperescala es perfecta para aquellos que buscan un alto rendimiento y una alta escalabilidad
Además de las características de escalado rápido, Hiperescala proporciona las siguientes funcionalidades de rendimiento.
- Las copias de seguridad de base de datos son casi instantáneas, independientemente del tamaño, sin ningún efecto en los recursos de proceso.
- Las restauraciones de base de datos se completan en minutos, en lugar de horas o días.
- Mayor rendimiento general debido a una mayor capacidad de proceso de los registros de transacciones y tiempos más rápidos de confirmación de estas, independientemente de los volúmenes de datos.
Nota:
Para implementar una base de datos de Hiperescala en Azure SQL Database, consulte
Desplegar una base de datos Azure SQL a hiperescala
Para implementar Azure SQL Database con el nivel Hiperescala:
Inicie sesión en Azure Portal.
Vaya a la página Azure SQL y seleccione + Crear.
Seleccione SQL Database, Base de datos única y el botón Crear.
En la pestaña Aspectos básicos de la página Crear SQL Database, seleccione la suscripción que quiera, el grupo de recursos y el nombre de la base de datos.
Seleccione el vínculo Crear nuevo para el Servidor y rellene la nueva información del servidor, como el nombre del servidor, el inicio de sesión y la contraseña del administrador del servidor y la ubicación.
En Proceso y almacenamiento, seleccione el vínculo Configurar base de datos.
Seleccione Hiperescala para Nivel de servicio, y Aprovisionado para Nivel de computación.
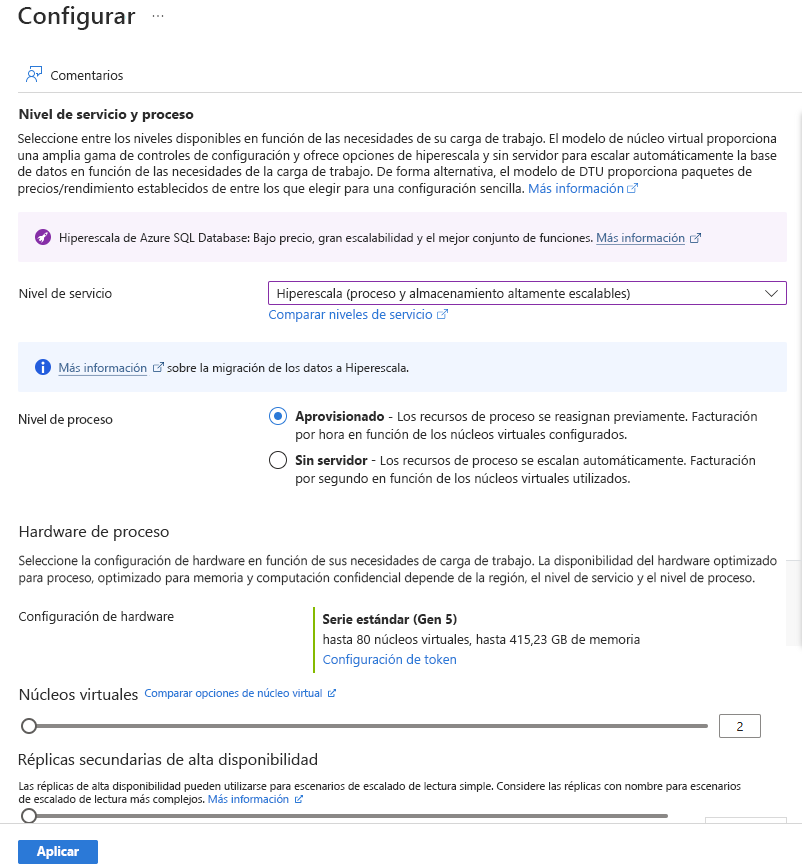
En Configuración de hardware, seleccione el vínculo Cambiar configuración. Revise las configuraciones de hardware disponibles y seleccione la configuración más adecuada para la base de datos. En este ejemplo, dejamos la opción predeterminada de Standard-series (Gen5).
Opcionalmente, ajuste el control deslizante Núcleos virtuales si desea aumentar el número de núcleos virtuales de la base de datos.
Ajuste el control deslizante Réplicas secundarias de alta disponibilidad para crear una réplica. Seleccione Aplicar.
Seleccione Siguiente: Redes en la parte inferior de la página.
En la pestaña Redes, establezca Agregar dirección IP de cliente actual en Sí.
Seleccione Revisar y crear y, luego, Crear.

Nota:
Después de convertir una base de datos en Hiperescala, no es posible revertirla a una base de datos de Azure SQL normal. Para obtener más información sobre las limitaciones de Hiperescala, consulte las limitaciones conocidas del nivel de servicio Hiperescala.
Conexión a una réplica de solo lectura
Puede conectarse a una réplica de solo lectura estableciendo el argumento ApplicationIntent de su cadena de conexión en ReadOnly. Todas las conexiones con la intención de aplicaciones ReadOnly se enrutan automáticamente a una de las réplicas de proceso de solo lectura.
Server=tcp:<your_server_name>.database.windows.net,1433;Database=<your_database_name>;User ID=<your_username>@<your_server_name>;Password=<your_password>;Encrypt=true;Connection Timeout=30;ApplicationIntent=ReadOnly;