Exploración de Microsoft Dataverse
Microsoft Dataverse es una solución basada en la nube que estructura con facilidad una gran variedad de datos y lógica de negocios para admitir aplicaciones y procesos interconectados de una manera segura y compatible. Administrada y mantenida por Microsoft, Dataverse está disponible de forma global, pero se implementa geográficamente para cumplir la posible residencia de datos. No está diseñada para usarse de forma independiente en los servidores, por lo que necesitará una conexión a Internet para acceder a ella y usarla.
A diferencia de las bases de datos tradicionales, Dataverse es más que solo tablas. Incorpora seguridad, lógica, datos y almacenamiento en un punto central. Se ha diseñado para ser el repositorio central de los datos empresariales y es posible que incluso ya lo use. En segundo plano, potencia muchas soluciones de Microsoft Dynamics 365, como el servicio de campo, Customer Insights, el servicio al cliente y las ventas. También está disponible como parte de Power Apps y Power Automate con conectividad nativa integrada. En las características AI Builder y Portales de Microsoft Power Platform también se usa Dataverse.
En la imagen se muestra una visualización en la que se reúnen las numerosas ofertas de Microsoft Dataverse.
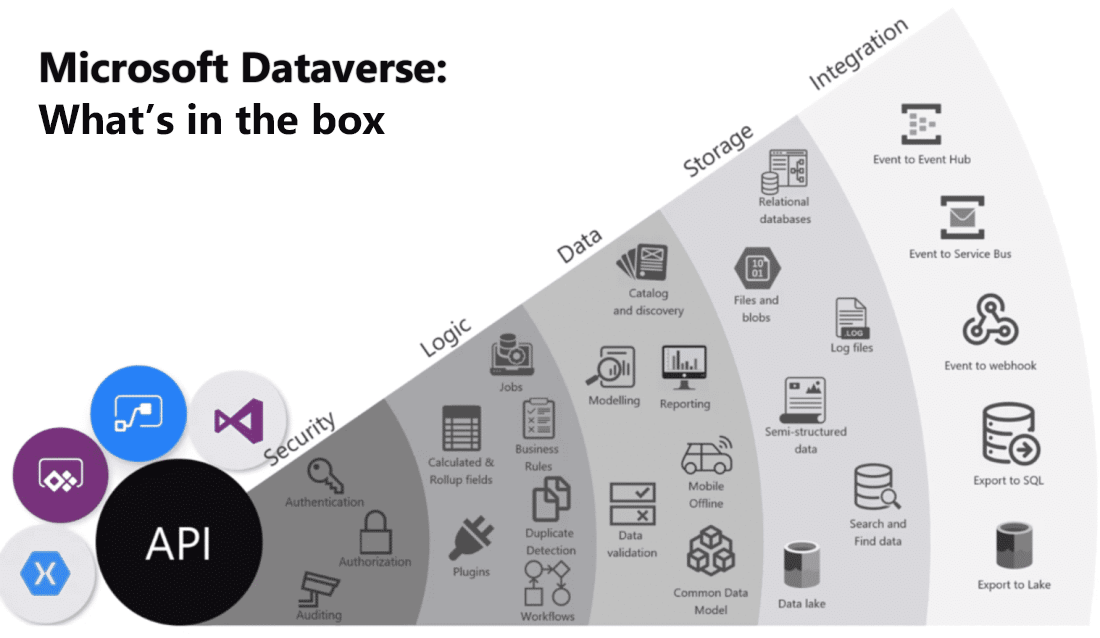
Esta es una breve explicación de cada categoría de características.
Seguridad: Dataverse controla la autenticación con Azure Active Directory (Azure AD) para permitir el acceso condicional y la autenticación multifactor. Admite la autorización hasta el nivel de fila y columna, y proporciona completas funciones de auditoría.
Lógica: Dataverse permite aplicar fácilmente la lógica de negocios en el nivel de datos. Independientemente del modo en que un usuario interactúe con los datos, se aplican las mismas reglas. Estas reglas podrían estar relacionadas con la detección de duplicados, las reglas de negocios, los flujos de trabajo, etc.
Datos: Dataverse le ofrece el control para dar forma a los datos, lo que le permite detectar, modelar, validar e informar sobre los datos. Este control garantiza que los datos tengan la apariencia que quiera, independientemente de cómo se usen.
Almacenamiento: Dataverse almacena los datos físicos en la nube de Azure. Este almacenamiento basado en la nube elimina la preocupación de dónde residen los datos o cómo se escalan. Estos problemas se controlan automáticamente.
Integración: Dataverse se conecta de maneras diferentes para satisfacer las necesidades de su empresa. Las API, los webhooks, los eventos y las exportaciones de datos proporcionan flexibilidad para archivar y extraer los datos.
Como podemos ver, Microsoft Dataverse es una solución eficaz basada en la nube para almacenar y trabajar con datos empresariales. En las secciones siguientes examinaremos Microsoft Dataverse desde el punto de vista del almacenamiento de datos para Microsoft Power Platform, donde comenzaremos el recorrido. Recordemos las demás capacidades indicadas, que podemos explorar más a medida que el uso aumente.
Para empezar, Microsoft Dataverse le permite crear una o varias instancias basadas en la nube de una base de datos normalizada. La base de datos incluye tablas y columnas predefinidas que almacenan los datos que suelen encontrarse en casi todas las organizaciones y empresas. Podemos personalizar y ampliar lo que se almacena si agregamos nuevas columnas o tablas. La facilidad de configuración de una base de datos de Microsoft Dataverse y su modelo de datos normalizado simplifica la capacidad de concentrar los esfuerzos en la creación de soluciones sin preocuparse por la infraestructura, el almacenamiento y la integración de los datos. Hay muchas maneras de acceder a los datos almacenados en Microsoft Dataverse. Puede trabajar con los datos de forma nativa con herramientas como Power Apps o Power Automate. Cualquier solución empresarial puede conectarse a Dataverse mediante las API de los conectores. Con la eficacia de las características, como la seguridad basada en roles y las reglas de negocio, puede confiar en que sus datos estarán protegidos, independientemente de cómo se acceda a ellos.
Escalabilidad
Una base de datos de Dataverse admite conjuntos de datos grandes y modelos de datos complejos. Las tablas pueden contener millones de elementos, y puede ampliar el almacenamiento de cada instancia de una base de datos de Microsoft Dataverse a 4 terabytes. La cantidad de datos disponibles en la instancia de Microsoft Dataverse se basa en el número y el tipo de licencias que tenga asociadas. El almacenamiento de datos se agrupa entre todos los usuarios con licencia, por lo que puede asignar almacenamiento según sea necesario para cada solución que cree. Se puede adquirir almacenamiento incremental si necesita más almacenamiento del que ofrecen las licencias estándar.
Ventajas y estructura de Microsoft Dataverse
La estructura de una base de datos de Microsoft Dataverse se basa en las definiciones y el esquema de Common Data Model. El uso de Common Data Model como base de una base de datos de Microsoft Dataverse simplifica la integración de las soluciones que usen un esquema de Common Data Model. Esto se debe a que Common Data Model es la base de una base de datos de Microsoft Dataverse y usa un esquema de Common Data Model. Las tablas estándar de la solución son las mismas. También podemos aprovechar un completo ecosistema de soluciones que los proveedores han creado a partir de Common Data Model. Lo mejor de todo es que no hay prácticamente límites en lo que se refiere a la ampliación de una base de datos de Microsoft Dataverse.
Describir tablas, columnas y relaciones
Una tabla es una estructura lógica con filas y columnas que representa un conjunto de datos. En la captura de pantalla veremos la tabla de cuentas estándar y varios elementos que se pueden administrar como parte de ella.
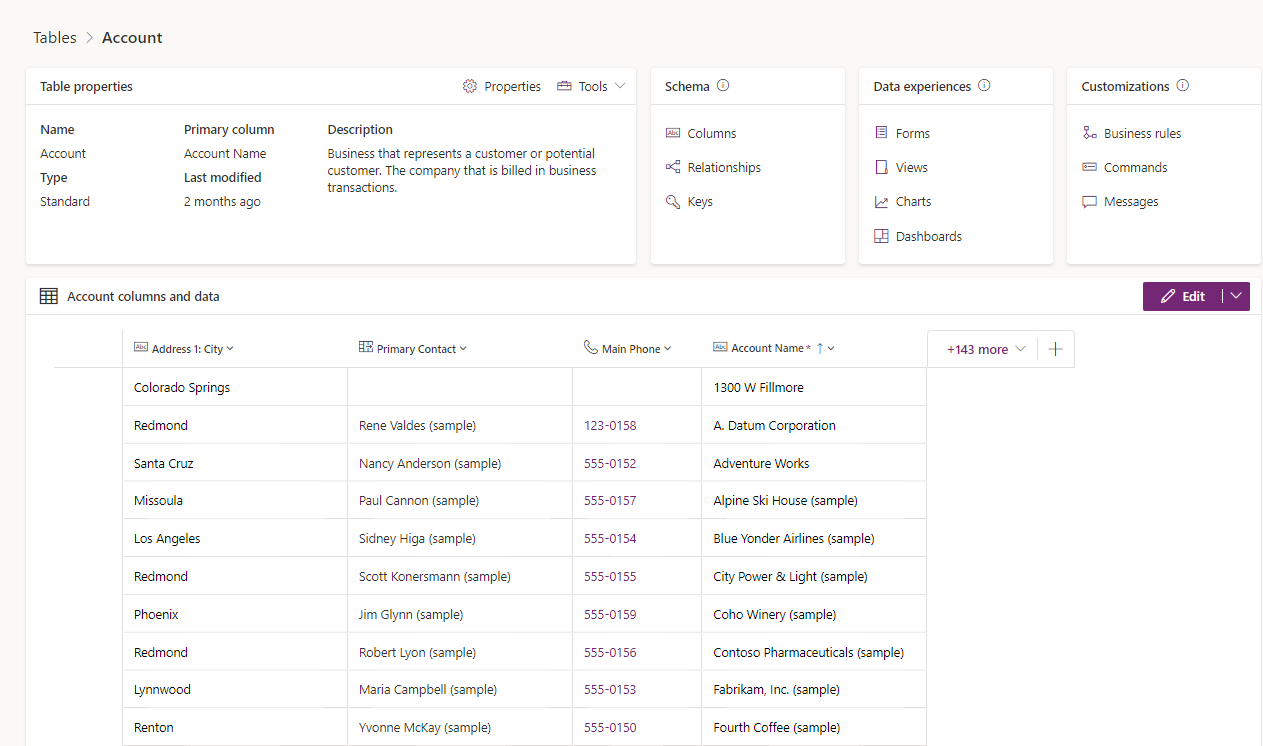
Tipos de tablas
Los tres tipos de tablas son los siguientes:
Estándar : se incluyen varias tablas estándar, también conocidas como "tablas integradas", con un entorno de Dataverse. Las tablas account, business unit, contact, task y user son ejemplos de tablas estándar en Dataverse. La mayoría de las tablas estándar incluidas con Dataverse se pueden personalizar.
Administradas: las tablas que no son personalizables y se han importado en el entorno como parte de una solución administrada.
Personalizado: las tablas personalizadas son tablas no administradas que se importan desde una solución no administrada o son tablas nuevas creadas directamente en el entorno de Dataverse.
Columnas
Las columnas almacenan información concreta dentro de una fila de una tabla. Pueden considerarse como una columna de Excel. Las columnas tienen tipos de datos, lo que significa que puede almacenar datos de un tipo concreto en una columna que coincida con ese tipo de datos. Por ejemplo, si tenemos una solución que requiere fechas, como capturar la fecha de un evento o cuando se produjo algo, almacenaremos la fecha en una columna con el tipo Date. Del mismo modo, si quiere almacenar un número, debe almacenarlo en una columna con el tipo de Número.
El número de columnas de una tabla oscila entre varias y cien o más. Todas las bases de datos de Microsoft Dataverse comienzan con un conjunto estándar de tablas y cada tabla estándar tiene un conjunto estándar de columnas.
Descripción de las relaciones
Para crear una solución eficaz y escalable para la mayoría de las soluciones que cree, tiene que dividir los datos en contenedores diferentes (tablas). Probablemente, intentar almacenar todo en un único contenedor resultaría ineficaz e incomprensible.
En el ejemplo siguiente se ilustra este concepto.
Imagine que necesita crear un sistema para administrar los pedidos de venta. Necesita una lista de los productos junto con el inventario disponible, el costo del artículo y el precio de venta. También necesita una lista maestra de clientes con sus direcciones y calificaciones crediticias. Por último, tiene que administrar las facturas de ventas, así como almacenar los datos de la factura. La factura debe incluir información como:
date
número de factura
vendedor
información del cliente, incluida la dirección y la clasificación de crédito
un elemento de línea para cada elemento de la factura
Cada elemento de línea debe incluir una referencia al producto vendido. El elemento de línea también debe proporcionar el costo y el precio adecuados para cada producto. Y, por último, la línea también debe reducir la cantidad a mano en función de la cantidad que se vende en ese elemento de línea. Crear una sola tabla para admitir la funcionalidad en el ejemplo anterior no serviría de nada. Una manera mejor de abordar este escenario empresarial consiste en crear las cuatro tablas siguientes:
Clientes
Productos
Facturas
Elementos de línea
Crear una tabla para cada uno de estos elementos y relacionarlos entre sí le permite crear una solución eficaz que se puede escalar mientras se mantiene un alto rendimiento. La división de los datos en varias tablas también significa que no tiene que almacenar datos repetitivos ni admitir filas enormes con grandes cantidades de datos en blanco. Además, los informes serán mucho más fáciles si divide los datos en tablas independientes.
Las tablas que se relacionan entre sí tienen una conexión relacional. Hay muchas formas de relaciones entre tablas, pero las dos más comunes son la de uno a varios y la de varios a varios, que son compatibles con Microsoft Dataverse. Para más información sobre los diferentes tipos de relaciones, consulte : Relaciones entre tablas.
La lógica de negocios en Microsoft Dataverse
Muchas organizaciones tienen lógica empresarial que afecta al trabajo con los datos. Por ejemplo, una organización que usa Dataverse para almacenar la información del cliente podría querer hacer que un campo como el del número de identificación sea obligatorio. En Microsoft Dataverse, esta lógica se crea mediante reglas de negocio. Las reglas de negocio permiten aplicar y mantener la lógica de negocios en la capa de datos en lugar de en la capa de aplicación. Básicamente, al crear reglas de negocio en Microsoft Dataverse, entran en vigor independientemente de dónde los usuarios interactúen con los datos.
Por ejemplo, las reglas de negocio se pueden usar en las aplicaciones de lienzo y basadas en modelo para establecer o borrar valores en una o varias columnas de una tabla. También se pueden usar para validar datos almacenados o mostrar mensajes de error. Las aplicaciones basadas en modelos pueden usar reglas de negocio para mostrar u ocultar campos, habilitar o deshabilitar columnas, y crear recomendaciones basadas en la inteligencia empresarial.
Las reglas de negocio ofrecen una manera eficaz de aplicar reglas, establecer valores o validar datos independientemente del formulario que se use para introducir los datos. Además, las reglas de negocio son eficaces para ayudar a aumentar la precisión de los datos, simplificar el desarrollo de aplicaciones y simplificar los formularios presentados a los usuarios finales.
Considera este como un ejemplo de un uso sencillo, pero eficaz, de las reglas de negocio. La regla de negocio está configurada para que el campo Credit Limit VP Approver sea obligatorio si el límite de crédito se establece en un valor mayor que $1,000,000. Si el límite de crédito es menor que $1,000,000, el campo es opcional.
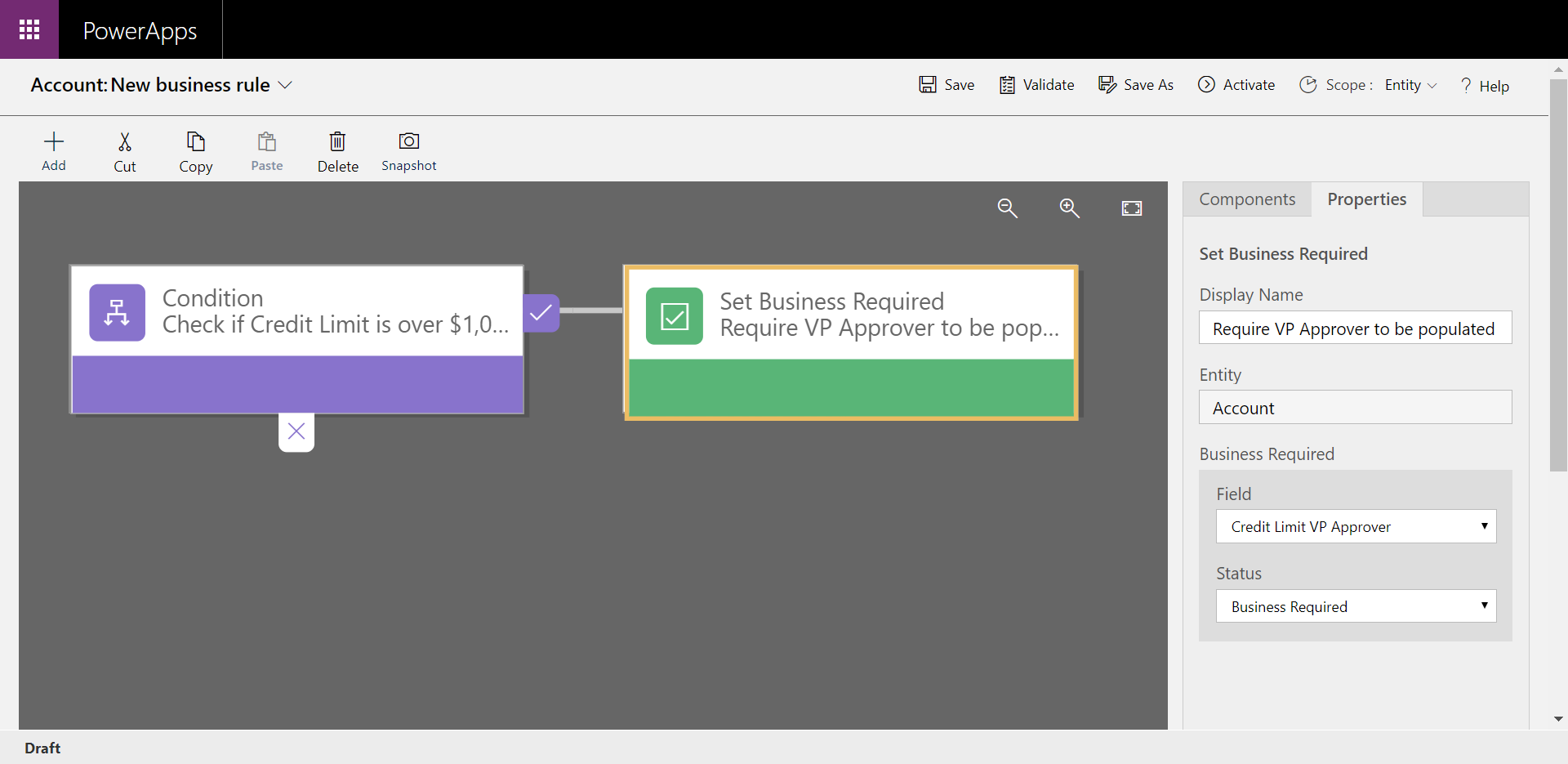
Al aplicar esta regla de negocio en el nivel de datos en lugar del nivel de aplicación, tiene un mayor control de los datos. Esto asegura que se siga la lógica de negocios si se accede a ella directamente desde Power Apps, Power Automate o incluso una API. La regla está vinculada a los datos, no a la aplicación.
Para más información sobre el uso de reglas de negocio en Dataverse, consulte: Crear una regla de negocio para una tabla.
Trabajar con flujos de trabajo
Los flujos de datos son tecnología de preparación de datos basada en la nube y de autoservicio. Se usan para ingerir, transformar y cargar datos en entornos de Microsoft Dataverse, en áreas de trabajo de Power BI o en la cuenta de Azure Data Lake Storage de la organización. Los flujos de datos se crean mediante Power Query, una experiencia de preparación y conectividad de datos que ya se incluye en muchos productos de Microsoft, como Excel y Power BI. Los clientes pueden desencadenar flujos de datos para que se ejecuten a petición o automáticamente según una programación, los datos siempre se mantienen actualizados.
Dado que los flujos de datos almacenan las entidades resultantes en almacenamiento en la nube, otros servicios pueden interactuar con los datos que estos generan.
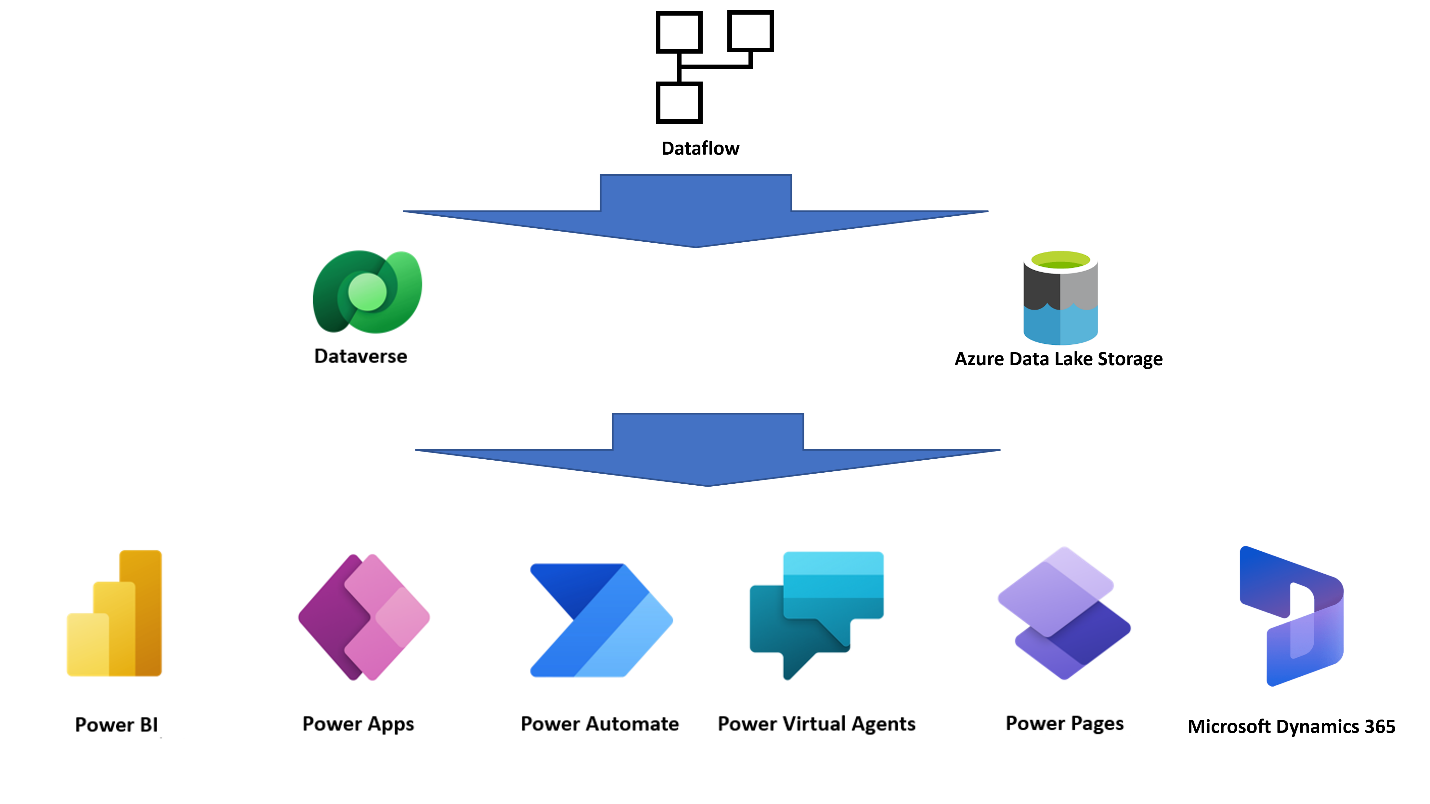
Por ejemplo, las aplicaciones de Power BI, Power Apps, Power Automate, Power Virtual Agents y Dynamics 365 pueden obtener los datos que genere el flujo de datos mediante la conexión a Dataverse, un conector de flujo de datos de Power Platform. Como alternativa, pueden obtener los datos directamente a través del lago, en función del destino configurado en el momento de la creación del flujo de datos.
En la lista siguiente se resaltan algunas de las ventajas de usar flujos de datos:
Desacoplan la capa de transformación de datos de la capa de modelado y visualización en las soluciones de Power BI.
El código de transformación de datos puede residir en una ubicación central (flujo de datos), en lugar de distribuirse entre varios artefactos.
El creador de flujos de datos solo necesita conocimientos de Power Query. En un entorno con varios creadores, el creador del flujo de datos puede formar parte de un equipo que compile toda la solución de BI o la aplicación operativa.
Los flujos de datos son independientes del producto. No son solo un componente de Power BI, ya que puede obtener sus datos con otras herramientas y servicios.
Los flujos de datos aprovechan Power Query, una experiencia de transformación de datos eficaz, gráfica y de autoservicio.
Los flujos de datos se ejecutan completamente en la nube. No se requiere ninguna otra infraestructura.
Hay varias opciones para empezar a trabajar con flujos de datos: mediante licencias para Power Apps, Power BI y Customer Insights.
Los flujos de datos admiten las transformaciones avanzadas, pero están diseñados para escenarios de autoservicio y no requieren conocimientos de TI o de desarrollo.
Common Data Model
Al crear soluciones empresariales, a menudo necesita integrar datos en las distintas aplicaciones empresariales de las organizaciones. Esta integración entre aplicaciones puede ser difícil en ocasiones. Aunque los datos son similares, no almacenan necesariamente lo mismo en distintas aplicaciones. Para ayudar a simplificar esto, varios líderes tecnológicos crearon la iniciativa Common Data Model. El objetivo es tener una estructura común que se aplique fácilmente en diferentes aplicaciones. Las organizaciones pueden crear y compartir sus propios tipos de datos y etiquetas mediante Common Data Model de Microsoft, que tiene un amplio sistema de metadatos. Esto ayuda a capturar información empresarial valiosa, que se puede integrar y enriquecer con datos para ofrecer inteligencia accionable.
Con Common Data Model, puede estructurar los datos para representar conceptos y actividades que se suelen usar y comprender bien. Puede consultar y analizar esos datos, reutilizarlos e interoperar con otras empresas y aplicaciones que usan el mismo formato. Las organizaciones pueden crear y compartir sus propios tipos de datos y etiquetas mediante Common Data Model de Microsoft, que tiene un amplio sistema de metadatos.
En lugar de crear un nuevo modelo de datos para la aplicación, puede simplemente las definiciones de tabla disponibles. Common Data Model lo usan varias aplicaciones y servicios, como Microsoft Dataverse, Dynamics 365, Microsoft Power Platform y Azure. Esta semejanza del modelo de datos garantiza que todos los servicios puedan acceder a los mismos datos. Un ejemplo adecuado de cómo usar Common Data Model es las funcionalidades de preparación de datos en flujos de datos de Power BI. Estos flujos de datos crean archivos de datos, que siguen la definición de Common Data Model. Esos archivos de datos se almacenan en Azure Data Lake. Las definiciones de Common Data Model están abiertas y disponibles para cualquier servicio o aplicación que quiera usarlas.

Los datos descritos mediante Common Data Model se pueden usar con servicios de Azure para crear una solución analítica escalable. También puede ser un origen de datos semánticamente enriquecidos para aplicaciones que impulsan información accionable, como Dynamics 365 Customer Insights. Common Data Model se usa para definir entidades para aplicaciones de Dynamics 365 en Ventas, Finanzas, Administración de cadenas de suministro y Comercio. De este modo, puede estar disponible fácilmente en Azure Data Lake.
Microsoft sigue ampliando Common Data Model en colaboración con muchos asociados y expertos en la materia. Al crear aceleradores del sector, Microsoft permite que los siguientes sectores se beneficien de Common Data Model y de las plataformas que lo admiten: