Modelado de entidades de búsqueda pequeñas
Nuestro modelo de datos incluye dos entidades de datos de referencia pequeñas: ProductCategory y ProductTag. Estas entidades se usan para los valores de referencia y están relacionadas con otras entidades a través de un objeto 1:Many relationship.
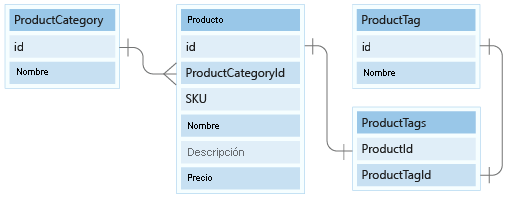
En esta unidad, modelaremos las entidades ProductCategory y ProductTag en nuestro modelo de documento.
Modelado de categorías de producto
Primero, en el caso de las categorías, modelaremos los datos con sus columnas de identificador y nombre como las únicas propiedades y los colocaremos en un nuevo contenedor llamado .
A continuación, debemos elegir una clave de partición. Vamos a explorar las operaciones que debemos realizar en estos datos.
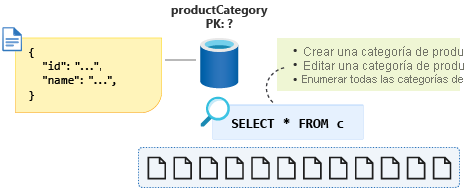
Crearemos una categoría de producto, editaremos una categoría de producto y, por último, enumeraremos todas las categorías de producto. La creación y edición de categorías de producto no son operaciones de ejecución frecuente. Nuestra aplicación de comercio electrónico a menudo enumerará todas las categorías de productos cuando los clientes visiten el sitio web. Por lo tanto, la última operación es la que más ejecutaremos.
La consulta de esta última operación tendrá el aspecto siguiente: SELECT * FROM c.
Con el identificador como clave de partición seleccionada, esta consulta ahora estará entre particiones; aunque queremos intentar optimizar estas operaciones con mucha actividad de lectura, use solo una sola partición si es posible. También sabemos que los datos para la categoría de producto nunca crecerán cerca de los 20 GB de tamaño; entonces, ¿cómo nos ayudaría esta información a modelar los datos de una manera que resulte en una consulta de partición única cuando enumeremos todas las categorías de productos?
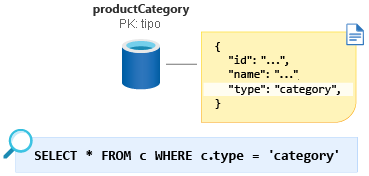
Para convertir esta pequeña cantidad de datos en una sola partición, podemos agregar la propiedad Discriminator de una entidad a nuestro esquema y usarla como clave de partición para este contenedor. Al asignar a esta propiedad un valor constante para todos los documentos de este tipo en el contenedor, nos aseguramos de que ahora tenemos una consulta de partición única. En este caso, llamaremos a la propiedad type y proporcionaremos un valor constante de category. Nuestra consulta ahora tendría el siguiente aspecto: SELECT * FROM c WHERE c.type = ”category”.
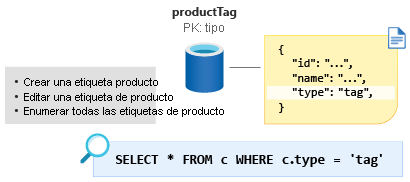
Modelado de las etiquetas de producto
A continuación, se encuentra la entidad ProductTag. La función de esta entidad es casi idéntica a la entidad ProductCategory que vimos en la sección anterior. Vamos a tomar el mismo enfoque aquí y modelar el documento para que contenga las propiedades de identificador y nombre y crear una propiedad Discriminator de la entidad denominada type; en este caso con un valor constante de tag. Crearemos un contenedor llamado ProductTag y convertiremos type en la nueva clave de partición.
A algunas personas les resulta extraña esta técnica para modelar tablas de búsqueda pequeñas. Sin embargo, al modelar los datos de esta manera, tenemos la oportunidad de realizar una optimización adicional que llevaremos a cabo en el módulo siguiente.