Definición de la arquitectura, componentes y funcionalidad de Desduplicación de datos
La mayoría de las organizaciones y empresas, incluida Contoso, deben encargarse del procesamiento y almacenamiento de un volumen de datos cada vez mayor. Aunque hay soluciones que permiten descargar y archivar datos en la nube, en muchos casos es necesario mantenerlos en centros de datos locales. Una administración eficaz del almacenamiento de estos datos requiere de las herramientas adecuadas. Al usar Windows Server, tiene la opción de emplear Desduplicación de datos para este fin.
¿Qué es Desduplicación de datos?
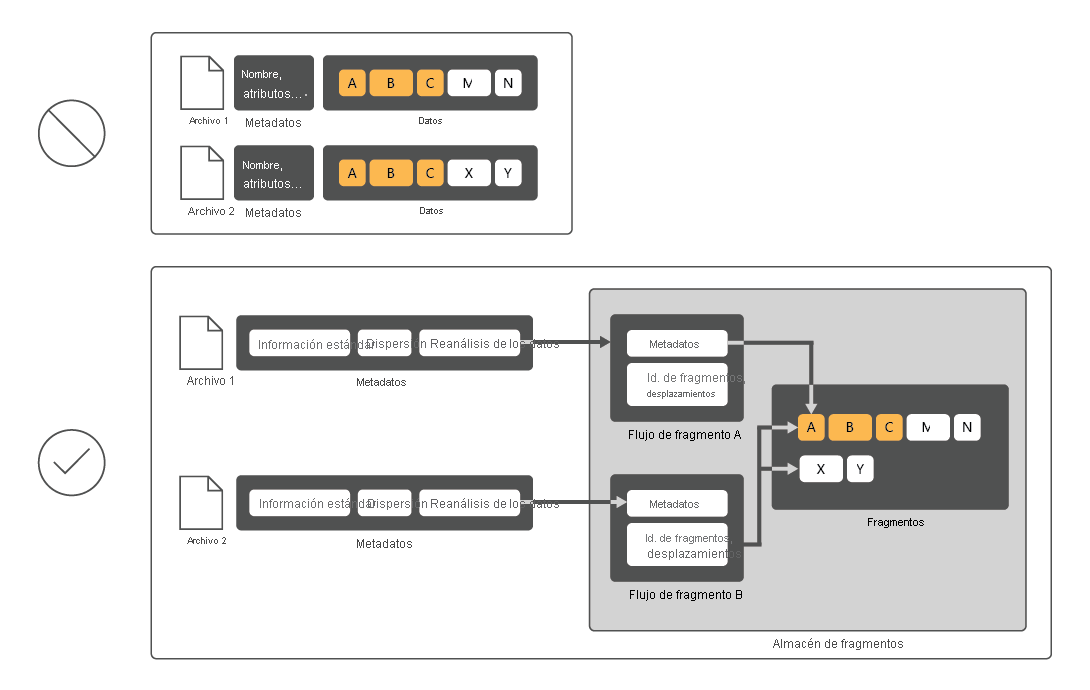
Desduplicación de datos es un servicio de rol de Windows Server que identifica y quita las duplicaciones de los datos sin poner en peligro la integridad de los mismos. De este modo, se cumplen los objetivos de almacenar más datos y usar menos espacio en disco físico.
Para reducir el uso de disco, Desduplicación de datos examina los archivos, los divide en fragmentos y, a continuación, solo conserva una copia de cada fragmento. Después de la desduplicación, los archivos ya no se almacenan como secuencias de datos independientes. En su lugar, Desduplicación de datos reemplaza los archivos por códigos auxiliares que apuntan a los bloques de datos que almacena en un almacén de fragmentos común. El proceso de acceso a los datos desduplicados es completamente transparente tanto para los usuarios como para las aplicaciones.
En muchos casos, Desduplicación de datos aumenta el rendimiento general del disco, ya que varios archivos pueden compartir un fragmento almacenado en memoria caché. De este modo, es posible recuperar datos de estos archivos con menos operaciones de lectura, lo que compensa el pequeño impacto en el rendimiento al leer archivos desduplicados. La desduplicación de datos no tiene ningún impacto en el rendimiento de las operaciones de escritura en disco porque se aplica a los datos que ya están en el disco.
¿Cuáles son los componentes de Desduplicación de datos?
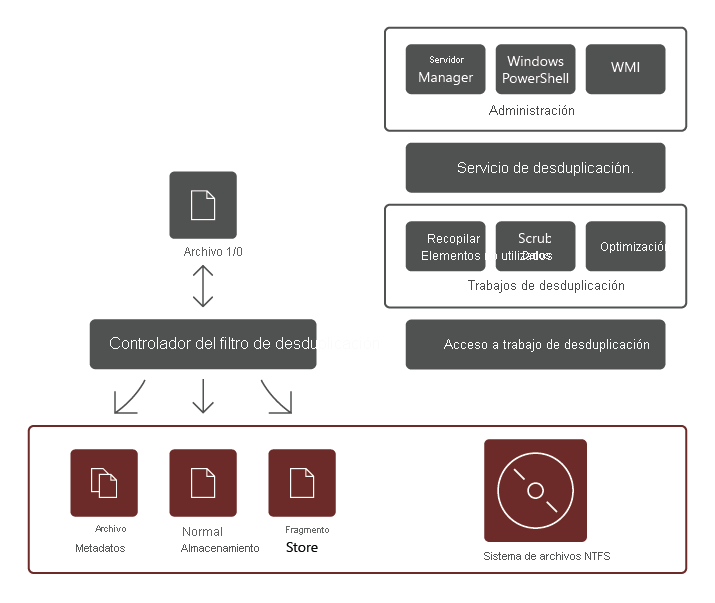
El servicio de rol Desduplicación de datos consta de los siguientes componentes:
- Controlador de filtro. Este componente redirige las solicitudes de lectura a los fragmentos que forman parte del archivo que se solicitó. Hay un controlador de filtro para cada volumen.
- Servicio de desduplicación. Este componente administra los siguientes trabajos:
- Desduplicación y compresión. Estos trabajos procesan archivos según la directiva de desduplicación de datos del volumen. Después de la optimización inicial de un archivo, si este se modifica y cumple el umbral de la directiva de desduplicación de datos para la optimización, el archivo se optimizará de nuevo.
- Recolección de elementos no utilizados. Este trabajo procesa los datos eliminados o modificados en el volumen para que los fragmentos de datos a los que ya no se hace referencia se quiten, lo que da lugar al espacio libre en disco. De manera predeterminada, la recolección de elementos no utilizados se ejecuta semanalmente; sin embargo, también puede considerar la posibilidad de invocarla después de eliminar muchos archivos.
- Limpieza de datos. Este trabajo usa las características de resistencia, como la validación de la suma de comprobación y la comprobación de coherencia de los metadatos para identificar y, siempre que sea posible, resolver automáticamente los problemas de integridad de los datos.
Nota:
Debido a las funcionalidades de validación adicionales, la desduplicación puede detectar los signos iniciales de daños en los datos e informar al respecto.
- Desoptimización. Este trabajo invierte la desduplicación en todos los archivos optimizados en el volumen. Algunos de los escenarios comunes para usar este tipo de trabajo son la solución de problemas con datos desduplicados o la migración de datos a otro sistema que no admite Desduplicación de datos.
Nota:
Antes de iniciar este trabajo, debe usar el cmdlet Disable-DedupVolume de Windows PowerShell para deshabilitar la actividad de desduplicación de datos adicional en uno o varios volúmenes.
Nota:
Después de deshabilitar Desduplicación de datos, el volumen permanece en estado desduplicado y los datos desduplicados existentes siguen siendo accesibles. Sin embargo, el servidor deja de ejecutar los trabajos de optimización para el volumen y no desduplica los datos nuevos. Más tarde podría usar el trabajo de desoptimización para deshacer los datos desduplicados existentes en un volumen. Al final de un trabajo de desoptimización realizado correctamente, todos los metadatos de desduplicación se eliminan del volumen.
Importante
Al usar el trabajo de desoptimización, asegúrese de comprobar que el volumen que hospeda estos datos tenga suficiente espacio disponible, ya que todos los archivos desduplicados se revertirán a su tamaño original.
Ámbito de Desduplicación de datos
Desduplicación de datos procesa todos los datos de un volumen seleccionado, con algunas excepciones, entre las que se incluyen:
- Archivos que no cumplen la directiva de desduplicación que ha configurado.
- Archivos en carpetas que se excluyeron explícitamente del ámbito de la desduplicación.
- Archivos de estado del sistema.
- Flujos de datos alternativos.
- Archivos cifrados.
- Archivos con atributos extendidos.
- Archivos de menos de 32 KB.
Nota:
A partir de Windows Server 2019, el Sistema de archivos resistente (ReFS) admite la desduplicación de datos para los volúmenes con un tamaño de hasta 64 terabytes (TB) y los archivos de hasta 4 TB. También emplea un almacén de fragmentos de tamaño variable que incluye compresión opcional para maximizar el ahorro de espacio en disco, mientras que la arquitectura de posprocesamiento con varios subprocesos reduce al mínimo el impacto en el rendimiento.