Definición de los casos de uso y la interoperabilidad de Desduplicación de datos
Los ahorros que genera Desduplicación de datos varían según el tipo de datos, la combinación de datos, el tamaño de los volúmenes y los archivos que contienen dichos volúmenes. Tiene la opción de evaluar el ahorro por volumen antes de habilitar la opción de desduplicación.
Casos de uso de Desduplicación de datos
En la lista siguiente se proporcionan escenarios de desduplicación típicos, así como su ahorro de espacio de volumen correspondiente:
| Caso de uso | Contenido | Ahorro de espacio |
|---|---|---|
| Documentos de usuario | Publicación o uso compartido de contenido de grupo, carpetas principales de usuario y redirección de perfiles para acceder a los archivos sin conexión. | 30 a 50 % |
| Recursos compartidos de implementación de software | Archivos binarios de software, archivos CAB, archivos de símbolos, imágenes y actualizaciones. | 70 a 80 % |
| Bibliotecas de virtualización | Almacenamiento de archivos de disco duro virtual (es decir, archivos .vhd y .vhdx) para el aprovisionamiento de hipervisores. | 80 a 95 % |
| Recursos compartidos de archivos generales | Combinación de todos los tipos de datos previamente identificados. | 50 a 60 % |
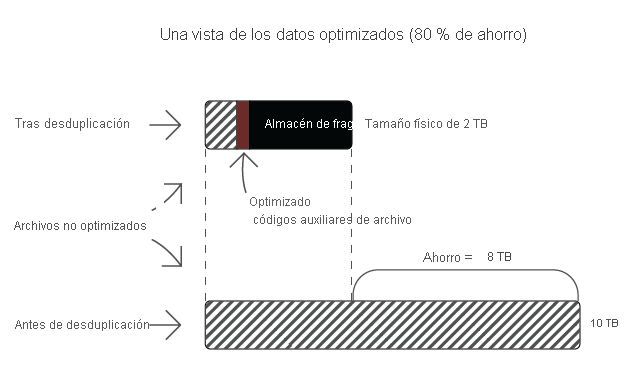
Casos de uso de Desduplicación de datos recomendados
En función del ahorro potencial y del uso típico de recursos en Windows Server, los candidatos de implementación para la desduplicación se clasifican como candidatos idóneos, que deben evaluarse o no idóneos.
- Candidatos idóneos para la desduplicación:
- Servidores de redireccionamiento de carpetas.
- Depósito de virtualización o biblioteca de aprovisionamiento.
- Recursos compartidos de implementación de software.
- Volúmenes de copia de seguridad de Microsoft SQL Server y Microsoft Exchange Server.
- Archivos en volúmenes compartidos de clúster (CSV) de servidores de archivos de escalabilidad horizontal (SOFS).
- VHD de copia de seguridad virtualizados (por ejemplo, Microsoft System Center Data Protection Manager).
- VHD de VDI de infraestructura de escritorio virtual (solo VDI personales).
Importante
En la mayoría de las implementaciones de VDI, es necesaria una planeación especial para considerar los arranques masivos. Este término hace referencia a la situación en la que muchos usuarios intentan iniciar sesión de manera simultánea en su VDI, normalmente al comienzo de un día laboral. Los arranques masivos suponen una carga pesada en el sistema de almacenamiento de VDI y pueden dar lugar a retrasos prolongados para los usuarios de VDI durante el inicio de sesión inicial. Puede minimizar el impacto de los arranques masivos al habilitar la desduplicación. De esta manera, los fragmentos leídos del almacén de desduplicación en disco al iniciar las VM se almacenan en la memoria caché. Como resultado, las lecturas posteriores no necesitan acceso frecuente a los fragmentos del disco, porque están disponibles en la memoria caché.
Deben evaluarse en base al contenido:
- Servidores de línea de negocio (LOB).
- Proveedores de contenido estático.
- Servidores web.
- Informática de alto rendimiento (HPC).
Candidatos que no son idóneos para la desduplicación:
- Windows Server Update Services (WSUS).
- Volúmenes de base de datos de SQL Server y Exchange Server.
Evalúe los ahorros con la Herramienta de evaluación de desduplicación.
Puede usar la Herramienta de evaluación de desduplicación, DDPEval.exe, para determinar el ahorro que se espera de la desduplicación de un volumen determinado. DDPEval.exe admite la evaluación de unidades locales, así como de recursos compartidos remotos asignados y sin asignar.
Sugerencia
Cuando instale la característica de desduplicación, DDPEval.exe se instalará automáticamente en el directorio \Windows\System32\.
Interoperabilidad de Desduplicación de datos
En Windows Server, debe tener en cuenta las siguientes tecnologías relacionadas y posibles problemas al implementar Desduplicación de datos:
Windows BranchCache
Puede optimizar el acceso a los datos a través de la red de área extensa (WAN) si habilita BranchCache en los sistemas operativos de cliente Windows y Windows Server. Al combinar ambas tecnologías, todos los archivos desduplicados ya están indexados y se les ha aplicado un algoritmo hash, lo que acelera el procesamiento de las solicitudes de datos de una sucursal. Esto es similar al indexado o uso de hash previos en un servidor habilitado para BranchCache.
Nota:
BranchCache es una característica que puede reducir el uso de WAN y mejorar la capacidad de respuesta de las aplicaciones de red cuando los usuarios tienen acceso al contenido de una oficina central desde las ubicaciones de las sucursales. Cuando habilitas BranchCache, se almacena en caché una copia del contenido que se recupera del servidor web o el servidor de archivos dentro de la sucursal. Si otro cliente de la sucursal solicita el mismo contenido, el cliente puede descargarlo directamente de la red de la sucursal local, en lugar de volver a usar la WAN para recuperar el contenido desde la oficina central.
Clústeres de conmutación por error
Los clústeres de conmutación por error cuentan con compatibilidad total para la Desduplicación de datos, lo que significa que los volúmenes desduplicados conmutan por error correctamente entre los nodos del clúster. Sin embargo, esto requiere la instalación de la característica Desduplicación de datos en cada nodo del clúster que participa en una conmutación por error.
Cuotas de FSRM
Aunque no debe crear una cuota máxima para una carpeta raíz de volumen que esté habilitada para la desduplicación, puede usar el Administrador de recursos del servidor de archivos (FSRM) para crear una cuota de advertencia en este escenario. Cuando FSRM detecta un archivo desduplicado, identifica el tamaño lógico del archivo para los cálculos de cuota. Por lo tanto, el uso de la cuota (incluidos todos los umbrales de cuotas) no cambia cuando la desduplicación procesa un archivo. Toda la demás funcionalidad de las cuotas de FSRM, incluidas las cuotas de advertencia para raíces de volumen y las cuotas en subcarpetas, funcionarán según lo previsto cuando se use la desduplicación.
Nota:
FSRM es un conjunto de herramientas que le ayudarán a identificar, controlar y administrar el tipo y la cantidad de datos almacenados en los servidores. FSRM le permite configurar cuotas máximas o de advertencia en las carpetas y volúmenes. Una cuota máxima impide a los usuarios guardar archivos una vez alcanzado el límite de cuota; mientras que una cuota de advertencia no aplica el límite de cuota, sino que genera una notificación cuando los datos del volumen alcanzan un umbral.
Replicación DFS
Desduplicación de datos es compatible con la replicación del Sistema de archivos distribuido (DFS). Optimizar o desoptimizar un archivo no desencadenará una replicación porque el archivo no cambia. Replicación DFS usa la compresión diferencial remota (RDC) (no los fragmentos del almacén de fragmentos) para ahorrar en la conexión.