Implementación de clústeres extendidos
Tradicionalmente, los clústeres de conmutación por error proporcionaban protección de alta disponibilidad frente a errores localizados en uno o varios nodos de clúster que residen en la misma ubicación física. Puede usar clústeres extendidos cuando sea necesario proporcionar la funcionalidad equivalente en varias ubicaciones físicas.
¿Qué son los clústeres extendidos?
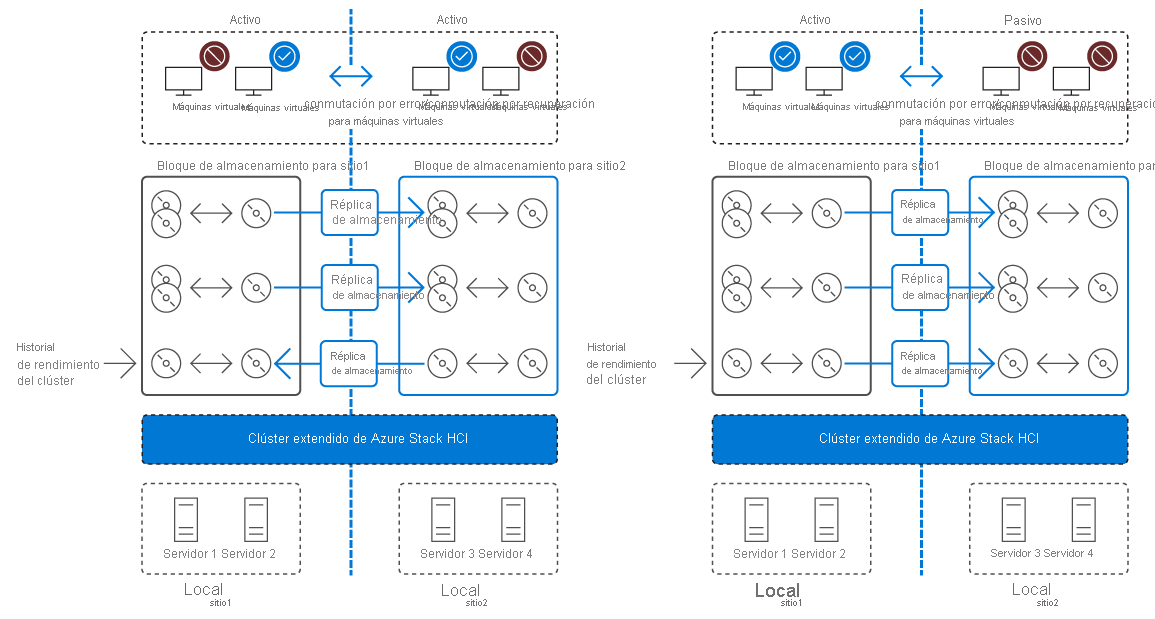
Un clúster extendido implementa la alta disponibilidad y la recuperación ante desastres en dos ubicaciones físicas independientes. Ambas ubicaciones hospedan un sistema de almacenamiento independiente, con replicación sincrónica unidireccional desde el sitio principal al sitio secundario. Si un error afecta a la disponibilidad del sitio principal, para minimizar el tiempo de inactividad, el clúster realiza automáticamente la transición de sus cargas de trabajo a los nodos del sitio secundario. En el caso de los eventos de mantenimiento esperados en el sitio principal, puede usar Migración en vivo de Hyper-V para realizar la transición sin problemas de las cargas de trabajo al otro sitio, evitando así tiempos de inactividad.
El uso de clústeres extendidos ofrece varias ventajas sobre el mantenimiento manual de un sitio de recuperación ante desastres:
- Replicación y conmutación por error automáticas de cargas de trabajo en clúster.
- Reduzca la sobrecarga administrativa.
- Minimice la posibilidad de que se produzcan errores humanos, que es inherente a los procesos manuales.
Por otro lado, los clústeres extendidos son más complejos de diseñar e implementar. Normalmente, también requieren una inversión adicional en la infraestructura de red y almacenamiento.
Información general sobre Réplica de almacenamiento
Los clústeres extendidos aprovechan Réplica de almacenamiento, una característica de Windows Server que proporciona la replicación de volúmenes entre servidores o clústeres para la recuperación ante desastres. Mediante el uso de Réplica de almacenamiento, los clústeres extendidos pueden sincronizar los volúmenes de almacenamiento asociados a los nodos de clúster extendidos en dos ubicaciones independientes.
La Réplica de almacenamiento admite la replicación sincrónica y asincrónica:
- La replicación sincrónica replica los datos a través de una red de baja latencia, en milisegundos de la hora de recorrido de ida y vuelta, lo que garantiza que no se pierdan datos en el nivel de sistema de archivos durante una conmutación por error.
- La replicación asincrónica replica los datos a través de distancias más largas que están sujetas a latencias mayores, pero sin ninguna garantía de que ambos sitios tengan copias idénticas de los datos en el momento de una conmutación por error.
Importante
Los clústeres extendidos requieren la replicación sincrónica. Este requisito impone el límite de latencia de red de ida y vuelta de 5 ms entre dos grupos de nodos de clúster en los sitios replicados. En función de las características de conectividad de red física, esta restricción normalmente se traduce en una distancia de unas 20-30 millas.
Características de Réplica de almacenamiento
En la tabla siguiente se enumeran las características principales de Réplica de almacenamiento.
| Característica | Descripción |
|---|---|
| Replicación a nivel de bloque | Con la replicación a nivel de bloque, no existe la posibilidad de que se bloquee el archivo. |
| Simplicidad | Puede confiar en Windows Admin Center para guiarle en el proceso de creación de una asociación de replicación entre dos servidores. Para implementar un clúster extendido, puede usar un asistente basado en Administrador de clústeres de conmutación por error. |
| Uso de Bloque de mensajes del servidor (SMB) 3.0 | Réplica de almacenamiento se basa en SMB 3.x, que se incorporó en Windows Server 2012 y mejoró considerablemente en versiones posteriores de Windows Server. Todas las características avanzadas de SMB, como SMB multicanal y SMB directo, están disponibles para Réplica de almacenamiento. |
| Seguridad | Réplica de almacenamiento presenta una amplia gama de mecanismos de seguridad, como la firma de paquetes, el cifrado de datos completo AES-128-GCM, la compatibilidad con la aceleración de cifrado de terceros y la prevención de ataques de tipo "Man in the Middle" de la integridad de la autenticación previa. Réplica de almacenamiento también se basa en Kerberos AES256 para toda la autenticación entre nodos. |
| Las restricciones de red | En los casos en los que hay varias rutas de red entre volúmenes replicados, puede configurar el tráfico de Réplica de almacenamiento para usar adaptadores de red designados. Esto permite minimizar el impacto potencial del tráfico de replicación en las cargas de trabajo de producción. |
| Aprovisionamiento fino | Tiene la opción de implementar el aprovisionamiento fino en Espacios de almacenamiento directo, lo que minimiza los tiempos de replicación iniciales. |
Requisitos previos para la implementación de clústeres extendidos
Los requisitos previos para la implementación de clústeres extendidos incluyen:
Los nodos de clúster deben ser miembros del mismo bosque de AD DS o de confianza.
Cada nodo de clúster debe tener al menos 2 GB de RAM y dos núcleos de CPU por servidor.
Cada nodo de clúster debe ejecutar Windows Server 2025 Datacenter o la edición Windows Server 2016 Datacenter. Aunque se puede usar la edición Windows Server 2025 Standard, sin embargo, esta configuración solo admite la replicación de un único volumen de hasta 2 terabytes (TB) de tamaño.
Cada nodo del clúster debe tener como mínimo un adaptador Ethernet Gigabit para la replicación sincrónica, aunque Acceso directo a memoria remota (RDMA) es preferible.
Dos conjuntos de volúmenes (uno para los datos y el otro para los registros) en el sitio principal y el secundario, con la siguiente configuración:
Los discos deben inicializarse como tabla de particiones GUID (GPT), en lugar de registro de arranque maestro (MBR).
- Se debe dar formato a los volúmenes con ReFS o NTFS.
- Los tamaños de los volúmenes de datos y los tamaños de sector deben coincidir.
- Los tamaños de los volúmenes de registro y los tamaños de sector deben coincidir.
- Los volúmenes de registro deben usar un almacenamiento más rápido que los volúmenes de datos.
- Los volúmenes de registro no deben usarse para otras cargas de trabajo.
Conectividad bidireccional a través del Protocolo de mensajes de control de Internet (ICMP), SMB (puerto 445, más el puerto 5445 para SMB directo) y Web Services-Management (WS-MAN) (puerto 5985) entre los dos sitios.
Una red entre servidores con suficiente ancho de banda para igualar las escrituras de E/S de las cargas de trabajo en clúster y una latencia de ida y vuelta de menos de 5 ms.
Consideraciones para implementar un clúster extendido
Los clústeres extendidos no son adecuados para cada carga de trabajo y cada escenario. Al diseñar una solución de clústeres extendidos, identifique claramente las expectativas y los requisitos de la organización. Además, tenga en cuenta que los clústeres extendidos imponen más sobrecarga de administración que los clústeres tradicionales en los que todos los nodos residen dentro de la misma ubicación física. También debe considerar detenidamente la opción óptima del testigo de cuórum para maximizar su disponibilidad en caso de que se produzca un desastre que afecte a todo un sitio físico.
Importante
Las aplicaciones y servicios con estado como Microsoft SQL Server, Hyper-V, Microsoft Exchange Server y AD DS deben usar sus propios mecanismos de resistencia nativos en lugar de confiar en clústeres extendidos para lograr alta disponibilidad.
Consideraciones sobre la conmutación por error y la conmutación por recuperación en un clúster extendido
Como parte de la planeación de la implementación de un clúster extendido, debe definir su configuración de conmutación por error y conmutación por recuperación, teniendo en cuenta las consideraciones siguientes:
- Dependencias de infraestructura. Debe definir claramente los servicios críticos, como AD DS, DNS y DHCP, que deben permanecer disponibles después de una conmutación por error al sitio secundario.
- Modelo de cuórum. Es importante elegir el modelo de cuórum que conserva la funcionalidad del clúster después de una conmutación por error.
- Publicación de servicios y resolución de nombres. Si tiene servicios publicados en los usuarios internos o externos, como correo electrónico y páginas web, tenga en cuenta que, en algunos casos, la conmutación por error a otro sitio requiere cambios de nombre o dirección IP. Si ese es el caso, debe tener un procedimiento para cambiar los registros de DNS en el DNS interno o público. Para reducir el tiempo de inactividad, recomendamos que reduzca el valor de período de vida (TTL) de los registros de DNS críticos.
- Conectividad de clientes. En caso de desastre, un plan de conmutación por error debe alojar la conectividad de las aplicaciones cliente a las cargas de trabajo en clúster. Esto incluye tanto clientes internos como externos.
- El procedimiento de conmutación por recuperación. Debe planear e implementar un proceso de conmutación por recuperación que se realizará después de que el sitio principal vuelva a estar en línea. La conmutación por recuperación es tan importante como una conmutación por error, ya que si la realiza de forma incorrecta puede dar lugar a la pérdida de datos y tiempo de inactividad del servicio.
Creación de un clúster extendido
Puede crear un clúster extendido con Windows Admin Center, Administrador de clústeres de conmutación por error o Windows PowerShell. Windows Admin Center simplifica la implementación de clústeres extendidos mediante el proceso de aprovisionamiento y la automatización de la mayoría de las tareas de configuración. Esto incluye la compatibilidad para:
- Clústeres hiperconvergidos (clústeres de conmutación por error, Hyper-V y Espacios de almacenamiento directo).
- Clústeres de almacenamiento (clústeres de conmutación por error y Espacios de almacenamiento directo).
Nota:
La creación de un clúster extendido con Administrador de clústeres de conmutación por error o Windows PowerShell es más compleja. Ambos métodos requieren la realización de cada uno de los pasos de implementación intermedios. En los términos más simples, esto comienza con la creación de un clúster de conmutación por error tradicional y no extendido que consta de todos los nodos del sitio principal y el secundario. Después de crear el clúster y completar su validación, en cada sitio, creará un conjunto independiente de volúmenes de almacenamiento. Por último, configure Réplica de almacenamiento para replicar volúmenes de almacenamiento entre los dos sitios.