Enumeración de las funcionalidades y los componentes de Réplica de almacenamiento
La disponibilidad de los datos es fundamental para la continuidad empresarial. Tradicionalmente, el aumento de la resistencia de almacenamiento requería soluciones costosas y específicas del proveedor que confiaban en el hardware de tecnología avanzada. Réplica de almacenamiento elimina esta dependencia, lo que proporciona funcionalidades rentables, de alta disponibilidad y recuperación ante desastres independientes del hardware.
¿Qué es Réplica de almacenamiento?
Réplica de almacenamiento es una tecnología de Windows Server que permite la replicación unidireccional e independiente del almacenamiento entre los volúmenes de almacenamiento que residen en servidores independientes o en clúster con fines de alta disponibilidad o recuperación ante desastres. Puede usar Réplica de almacenamiento para crear clústeres de conmutación por error extendidos que abarquen dos sitios físicos distintos, con todos los nodos sincronizados.
Réplica de almacenamiento requiere dos volúmenes con formato de sistema de archivos NTFS o Sistema de archivos resistente (ReFS) en el origen, y dos en el destino, donde cada par se usa para los registros de datos y de replicación, respectivamente. Cada par debe tener características de tamaño y rendimiento coincidentes. El volumen de datos de origen se conoce como principal, mientras que el volumen de destino se conoce como secundario.
Los servidores que hospedan estos volúmenes forman una asociación de replicación. Esta asociación puede incluir varios volúmenes de datos, pero todos ellos usan el mismo volumen de registro. Cada servidor, junto con todos sus volúmenes que forman parte de una asociación de replicación, constituye un grupo de replicación.
Importante
Nunca debe usar volúmenes de registro para otras cargas de trabajo.
Características de Réplica de almacenamiento
Las principales características de Réplica de almacenamiento incluyen:
- Replicación a nivel de bloque. Con la replicación a nivel de bloque, no existe la posibilidad de que se bloquee el archivo.
- Simplicidad. Puede confiar en Windows Admin Center para guiarle en el proceso de creación de una asociación de replicación entre dos servidores. Para implementar un clúster extendido, puede usar un asistente basado en Administrador de clústeres de conmutación por error.
- Compatibilidad con servidores físicos y máquinas virtuales. Todas las funcionalidades de Réplica de almacenamiento están disponibles tanto para las implementaciones basadas en invitado virtuales como para las basadas en host. Esto significa que los invitados pueden replicar sus volúmenes de datos incluso si se ejecutan en plataformas de virtualización que no son de Windows o en nubes públicas.
- Uso de Bloque de mensajes del servidor (SMB) 3.x. Réplica de almacenamiento se basa en SMB 3.x, que se incorporó en Windows Server 2012 y luego mejoró considerablemente en versiones posteriores de Windows Server. Todas las características avanzadas de SMB, como SMB multicanal y SMB directo, están disponibles para Réplica de almacenamiento.
- Seguridad. Réplica de almacenamiento presenta una amplia gama de mecanismos de seguridad, como la firma de paquetes, el cifrado de datos completo AES-128-GCM, la compatibilidad con la aceleración de cifrado de terceros y la integridad de la autenticación previa de ataques de tipo "Man in the Middle". Réplica de almacenamiento se basa en Kerberos AES256 para toda la autenticación entre nodos.
- Sincronización inicial de alto rendimiento. Réplica de almacenamiento admite la sincronización inicial inicializada, que implica copiar un subconjunto de datos desde un volumen de origen al destino a través de una copia de seguridad o un medio extraíble. De este modo, la replicación inicial solo consta de la diferencia entre los dos volúmenes, lo que reduce la duración de la sincronización inicial y limita el uso de ancho de banda.
- Grupos de coherencia. La ordenación de escritura garantiza que las escrituras de aplicaciones como SQL Server tengan lugar en la misma secuencia en el origen que en los volúmenes replicados.
- Administración delegada. Puede delegar los permisos para administrar la replicación sin necesidad de conceder privilegios a nivel de administrador en los nodos replicados.
- Las restricciones de red. En los casos en los que hay varias rutas de red entre volúmenes replicados, puede configurar el tráfico de Réplica de almacenamiento para usar adaptadores de red designados. Esto minimiza el impacto potencial del tráfico de replicación en las cargas de trabajo de producción.
- Aprovisionamiento fino. Tiene la opción de implementar el aprovisionamiento fino en Espacios de almacenamiento directo, lo que minimiza los tiempos de replicación inicial.
Replicación sincrónica y asincrónica
Réplica de almacenamiento admite dos tipos de replicación:
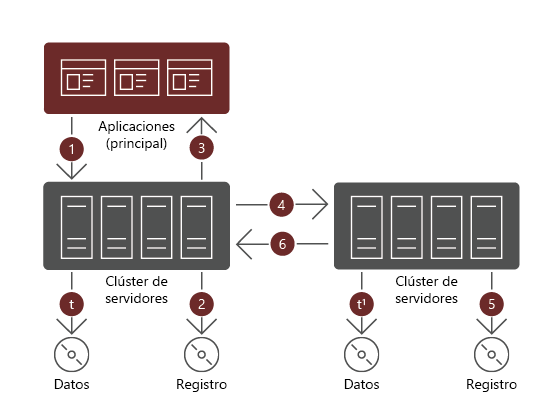
- La replicación sincrónica replica volúmenes entre sitios que están relativamente cerca entre sí. La replicación es coherente frente a bloqueos, lo que garantiza una nula pérdida de datos a nivel del sistema de archivos durante una conmutación por error.
- La replicación asincrónica permite la replicación en distancias más largas en los casos en los que la latencia de ida y vuelta de red supera los 5 milisegundos (ms), sin embargo, se pueden producir pérdidas de datos. El alcance de la pérdida de datos depende del retraso de la replicación entre los volúmenes de origen y de destino.
Cuando se usa la replicación sincrónica, una escritura de datos se debe completar correctamente en ambos volúmenes. Si esto no es así, la carga de trabajo que inicia la escritura debe reintentar la misma operación. Con la replicación sincrónica, los datos en ambos volúmenes son idénticos.
Sugerencia
Use la replicación sincrónica cuando sea imprescindible evitar la pérdida de datos.
La replicación sincrónica requiere una baja latencia de red para minimizar el tiempo de espera de la confirmación de la escritura remota. Este requisito limita la distancia entre los servidores o clústeres que hospedan cada volumen.
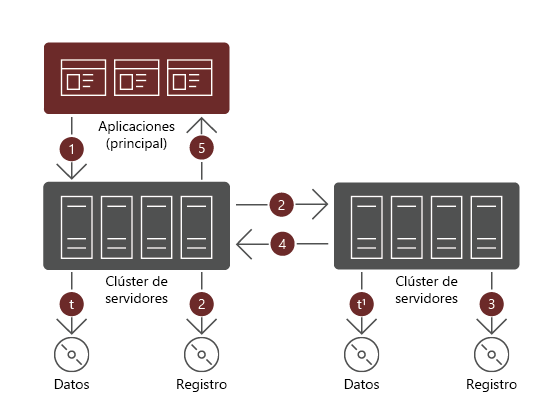
Cuando se usa la replicación asincrónica, después de que una escritura de datos se completa correctamente en el volumen principal, la carga de trabajo que inicia la escritura recibe una confirmación y puede continuar con otra operación de E/S. Las escrituras de datos correspondientes tienen lugar después en el volumen secundario, sin afectar al volumen principal.