Seguimiento de incidentes
- 7 minutos
Los incidentes tienen un ciclo de vida. Para responder de forma más eficaz, debe ser capaz de realizar un seguimiento de la evolución del propio incidente y la evolución de la respuesta a él, desde el principio de ese ciclo de vida.
Evaluación de lo que sabe
Una buena manera de evaluar el procedimiento de seguimiento de incidentes mediante un incidente específico es formular una serie de preguntas:
- ¿Cuándo se enteró por primera vez del problema? Si su objetivo es reducir el tiempo necesario para recuperarse de incidentes, debe empezar a capturar información desde el momento en que se entere de los problemas.
- ¿Cómo se enteró del problema? ¿El sistema de supervisión le alertó sobre el incidente? ¿Te enteraste por primera vez de esto a través de tus clientes que se quejaban, ya sea directamente o en las redes sociales?
- Si te acabas de enterar del problema, ¿eres el primero en saberlo? Si es así, ¿quién necesita notificar? Si no es así, ¿quién es consciente del problema?
- Si otros son conscientes, ¿qué se está haciendo al respecto? ¿Todo el mundo supone que alguien más lo está investigando o que alguien ha empezado a tomar medidas para abordarlo?
- ¿Qué malo es? Es posible que no tengamos ninguna noción de gravedad o impacto, y no hay lugar para que sepamos lo malo que realmente es el problema y quién se ve afectado.
Estas pueden ser preguntas difíciles de responder si no se realiza el seguimiento de nada.
Estandarizar dónde se realizará el seguimiento de la información de incidentes
Hay muchos lugares posibles para mantener y compartir su lista de incidentes (activos o de otro modo) y toda la información actual sobre esos incidentes. Pueden ser tan simples como un área de archivos compartida con documentos de Word y tan complejas como software y servicios de seguimiento de incidentes altamente especializados. Entre estos dos extremos se encuentran los sistemas de vales y de seguimiento del trabajo, que se pueden poner en marcha para esta tarea. El sistema que elija es realmente menos importante que cómo usarlo. Independientemente del sistema que use, todos los usuarios que puedan tener cualquier conexión en absoluto a incidentes (ingenieros, soporte al cliente, administración, relaciones públicas, legales, etc.) deben saber dónde buscar el sistema, cómo generar un incidente y cómo acceder a los datos cuando corresponda. Una manera segura de fracasar en el seguimiento de incidentes es hacer que las personas a las que el sistema va a ayudar no sepan cómo llegar al sistema ("¿cuál era la dirección URL de nuestro sistema?") cuando necesiten utilizarlo.
En este módulo, usaremos la funcionalidad de elemento de trabajo de Azure DevOps para nuestro sistema de seguimiento de ejemplo.
Creación de un puente de conversación
Para responder a algunas de las preguntas de la sección evaluar lo que sabe anterior y comenzar el proceso de respuesta a incidentes, necesita un medio para comunicarse con otros sobre el incidente. Idealmente, esto será un medio electrónico de "colaboración en equipo" para la conversación, aunque los puentes telefónicos también funcionan. Las teleconferencias y los puentes telefónicos son menos preferibles porque es más difícil revisar de forma retroactiva la comunicación sobre los incidentes (de ahí la función de "escriba" mencionada anteriormente).
Sea cual sea el medio que elija, debe asegurarse de crear un canal único que esté estrictamente limitado a la discusión sobre este incidente y nada más. Es importante mantener la discusión irrelevante fuera de este canal, ya que debe poder tomar los datos y analizarlos más adelante en la revisión posterior al incidente.
En este módulo, usaremos Microsoft Teams como método de comunicación ante incidentes.
Automatización del inicio del seguimiento de incidentes
Por lo tanto, revisemos las piezas que hemos reunido hasta ahora. Disponemos de:
- Una lista de turnos de las personas de guardia (y una rotación definida para ellas).
- Rol que podemos asignar a las personas que trabajan en un incidente.
- Lugar específico en el que vamos a declarar el incidente y realizar un seguimiento de él.
- Canal único para las personas que trabajan en ese incidente para comunicarse sobre él.
Puede y debe automatizar la creación y administración de todas estas cosas en la medida más completa posible. Cuando surge un problema urgente, no es necesario recordar todos los pasos necesarios para generar un incidente, traer a las personas adecuadas y realizar un seguimiento de él. Lo que realmente le interesa es dar el visto bueno para que se ponga en marcha de inmediato el trabajo que solucione el problema.
Uso de Logic Apps para la automatización sin código
Una manera de automatizar la respuesta inicial es usar Logic Apps, que puede simplificar el trabajo de programación, automatización y orquestación de tareas, procesos empresariales y flujos de trabajo.
Logic Apps es un servicio en la nube de Azure para crear soluciones de integración. Usa conectores para crear flujos de trabajo automatizados. Los desencadenadores inician la aplicación lógica cuando se produce un evento específico o cuando los datos cumplen los criterios especificados. Las acciones son las operaciones que se realizan en el flujo de trabajo de la aplicación lógica.
En nuestro ejemplo, usaremos los siguientes conectores de aplicación lógica para el seguimiento de incidentes:
- Azure Boards (una parte de Azure DevOps), que puede usar para crear y realizar un seguimiento de problemas o incidentes.
- Azure Storage, donde puede almacenar y recuperar información sobre quién está a la llamada para que pueda asignar las personas adecuadas para responder al incidente. En nuestro ejemplo, usaremos Azure Table Storage porque ofrece un almacén "clave-valor" muy sencillo que facilita el almacenamiento de una lista de ingenieros y su estado de llamada.
- Microsoft Teams, que puede usar para crear un canal de incidentes nuevo y único para realizar un seguimiento de las conversaciones de los equipos de ingeniería en tiempo real a medida que se comunican sobre incidentes específicos. Esto le permite conservar las interacciones en relación con la escala de tiempo de los eventos más adelante al realizar una revisión posterior al incidente.
Ahora vamos a vincularlo todo con una aplicación lógica. En primer lugar, eche un vistazo a la aplicación completa como se muestra en el Diseñador de logic Apps y, a continuación, le guiaremos paso a paso.
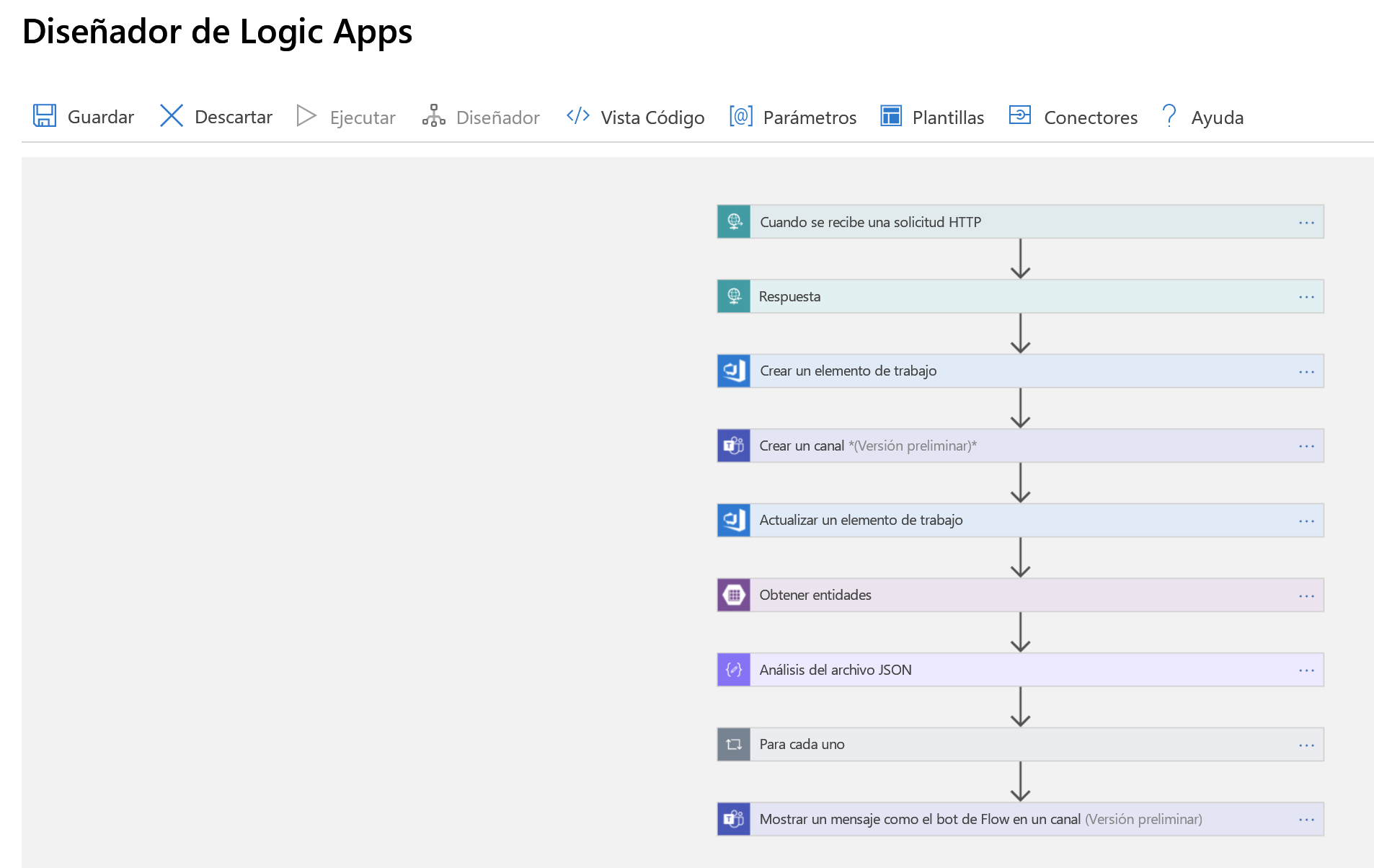
El primer paso es controlar un desencadenador, esa solicitud HTTP que mencionamos. Se realiza una solicitud HTTP POST a nuestra aplicación lógica que contiene una carga JSON con información sobre el incidente que queremos declarar. Analizamos esa carga y devolvemos una confirmación que recibimos:
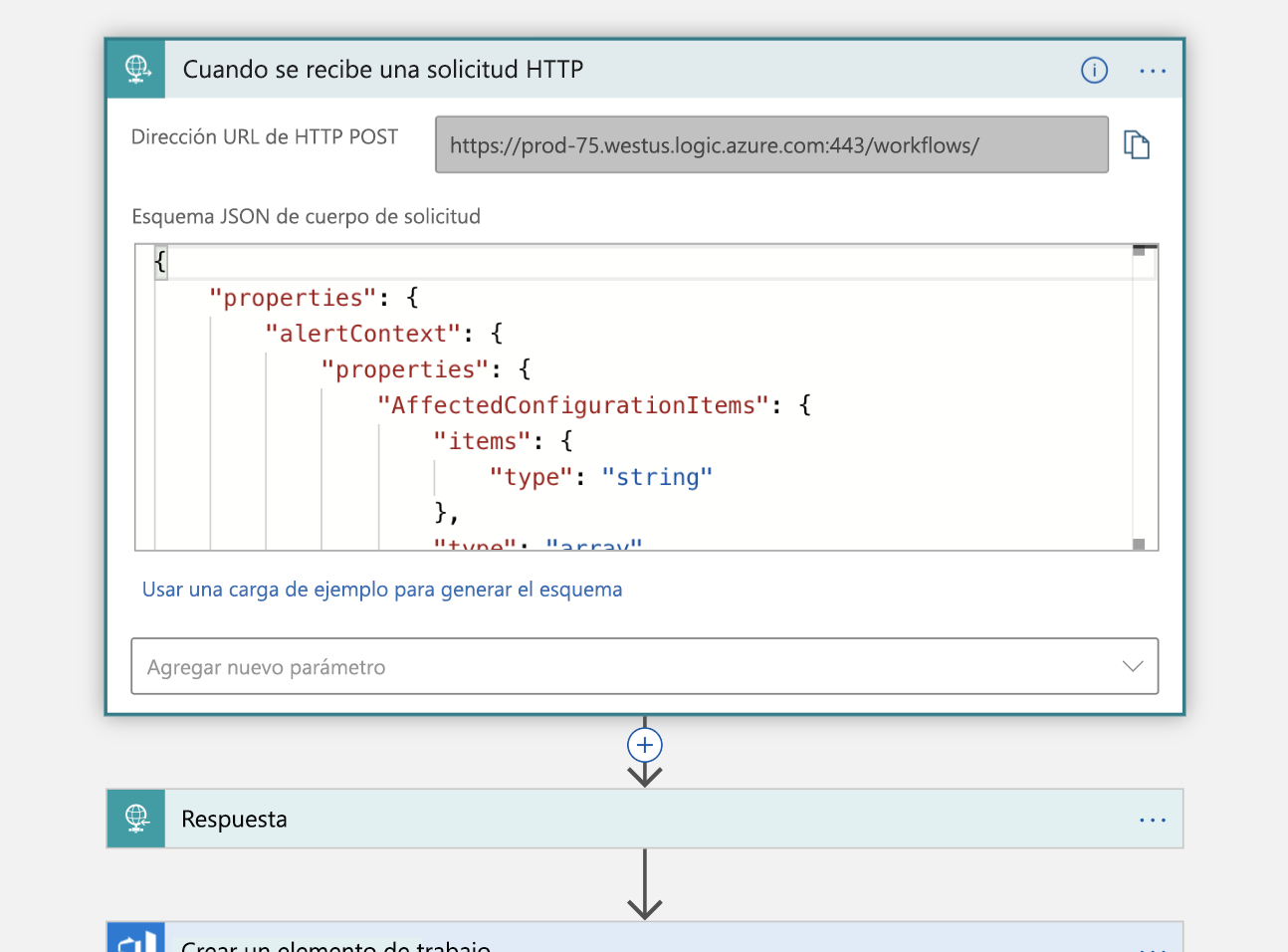
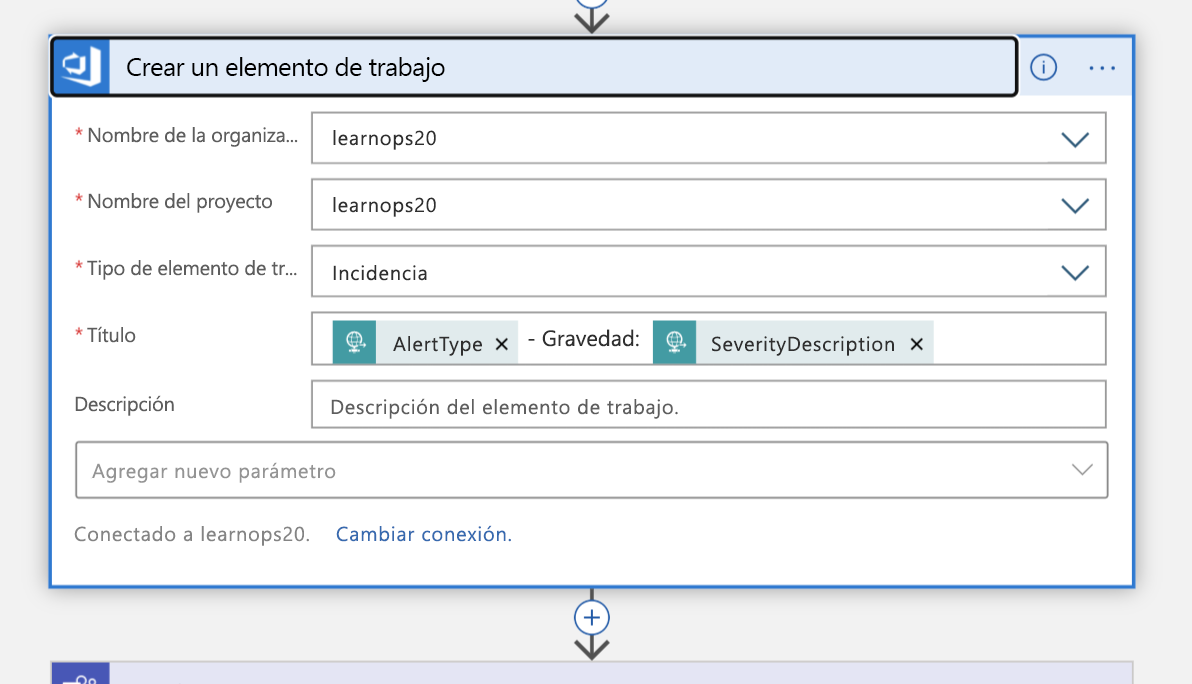
Con esta información, creamos un nuevo elemento de trabajo en nuestra organización de Azure DevOps que representa este incidente.
A continuación, creará un nuevo canal de Teams para el incidente:
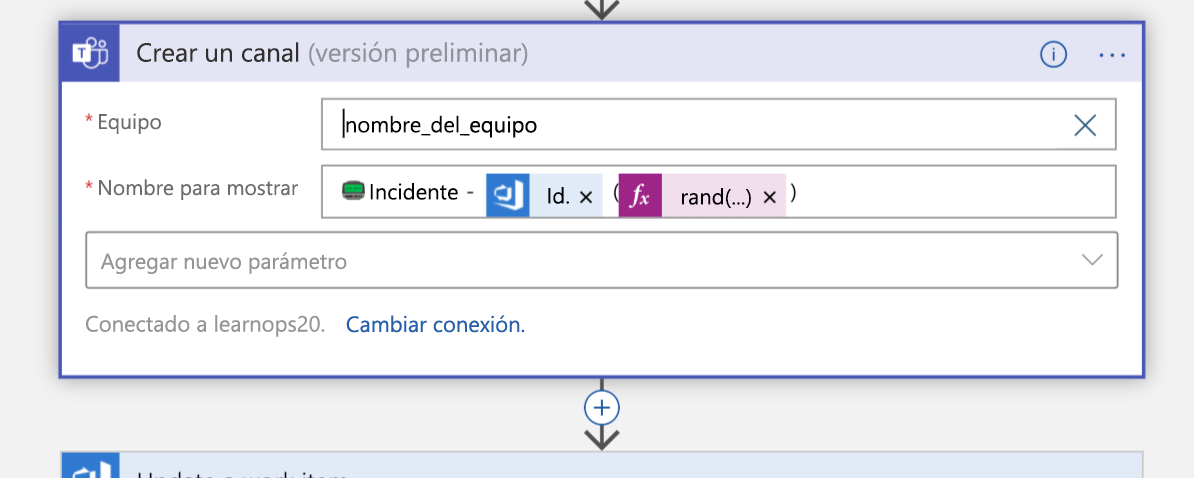
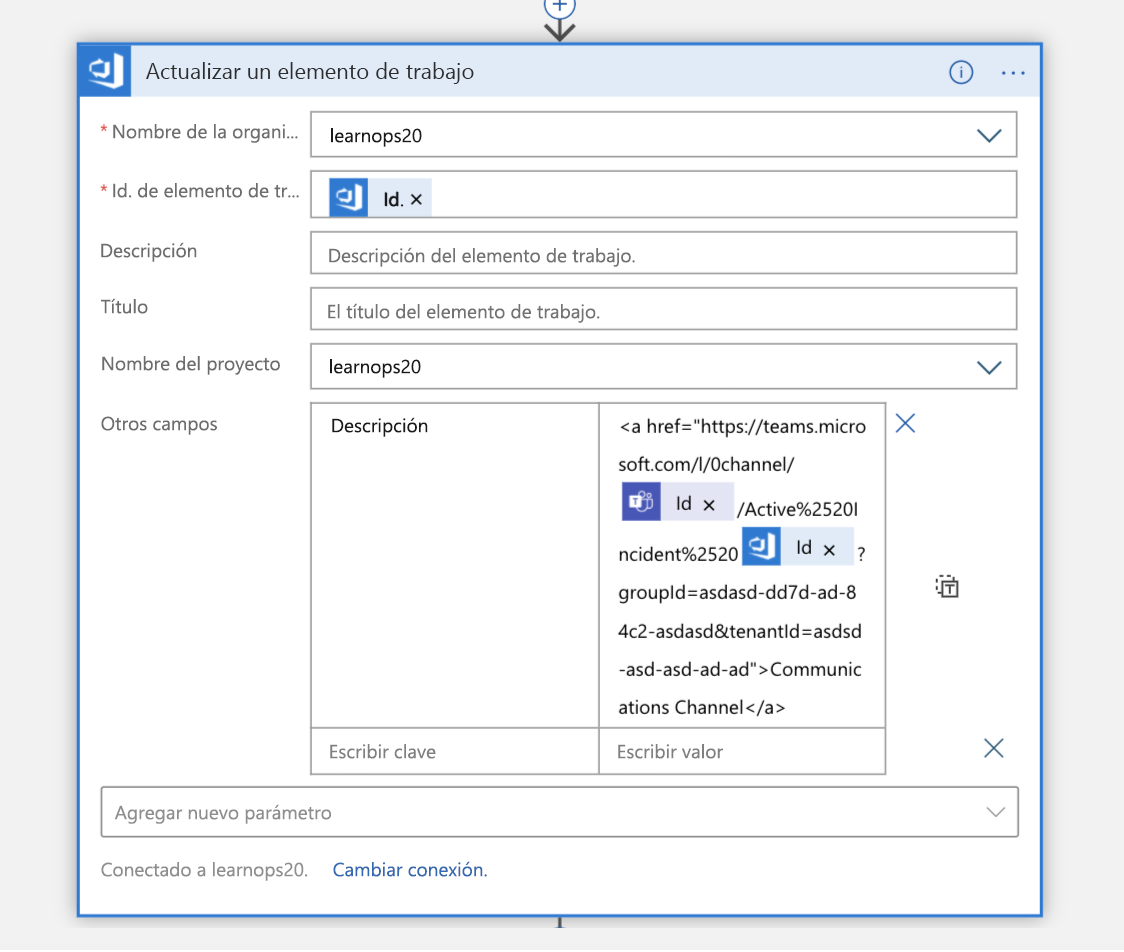
Una vez creado el canal, el elemento de trabajo que creamos hace un momento se actualiza con un vínculo al nuevo canal. Esto mantiene toda la información en el mismo lugar (el elemento de trabajo) y permite a las personas que lo miran más adelante saber dónde ir si quieren unirse a ese canal.
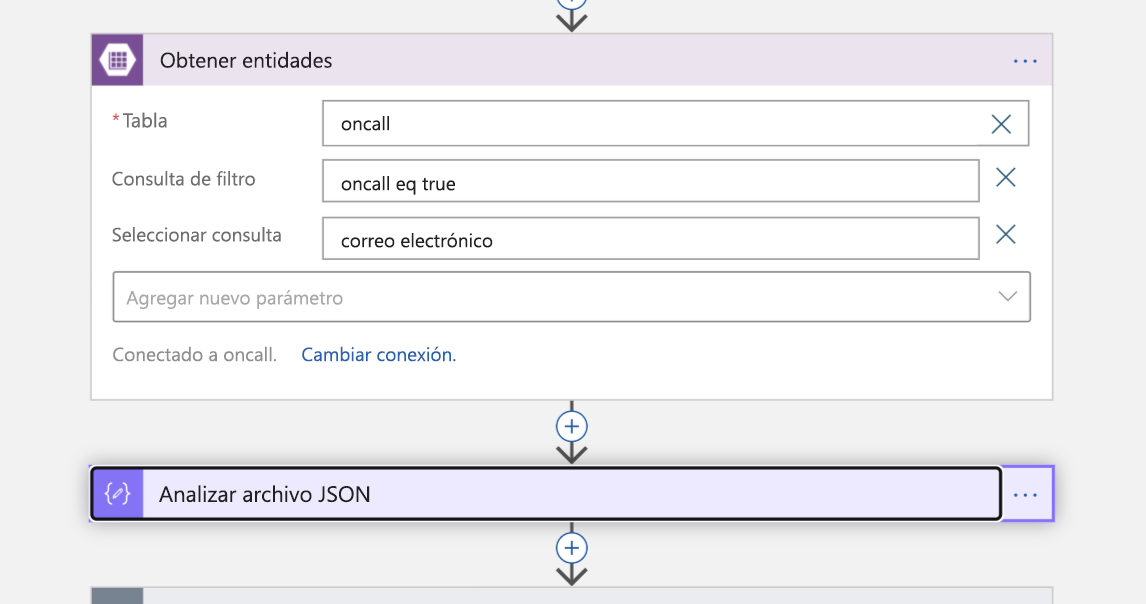
Ahora es el momento de que entre en escena la persona que está de guardia. Realizamos una búsqueda en Azure Table Storage para la dirección de correo electrónico del ingeniero que aparece como llamada. Esto devuelve una respuesta JSON, que luego analizamos.
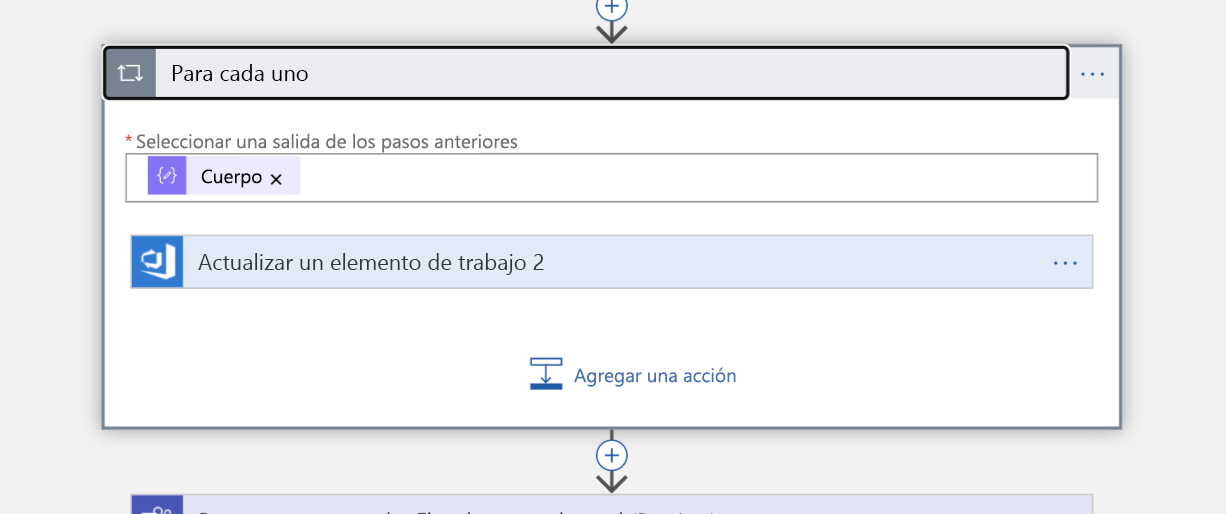
Dado que la consulta devolverá una lista, es necesario recorrer en iteración cada elemento de esa lista como paso siguiente. Asignamos el elemento de trabajo a cada persona (ahora son "propietarios" del incidente).
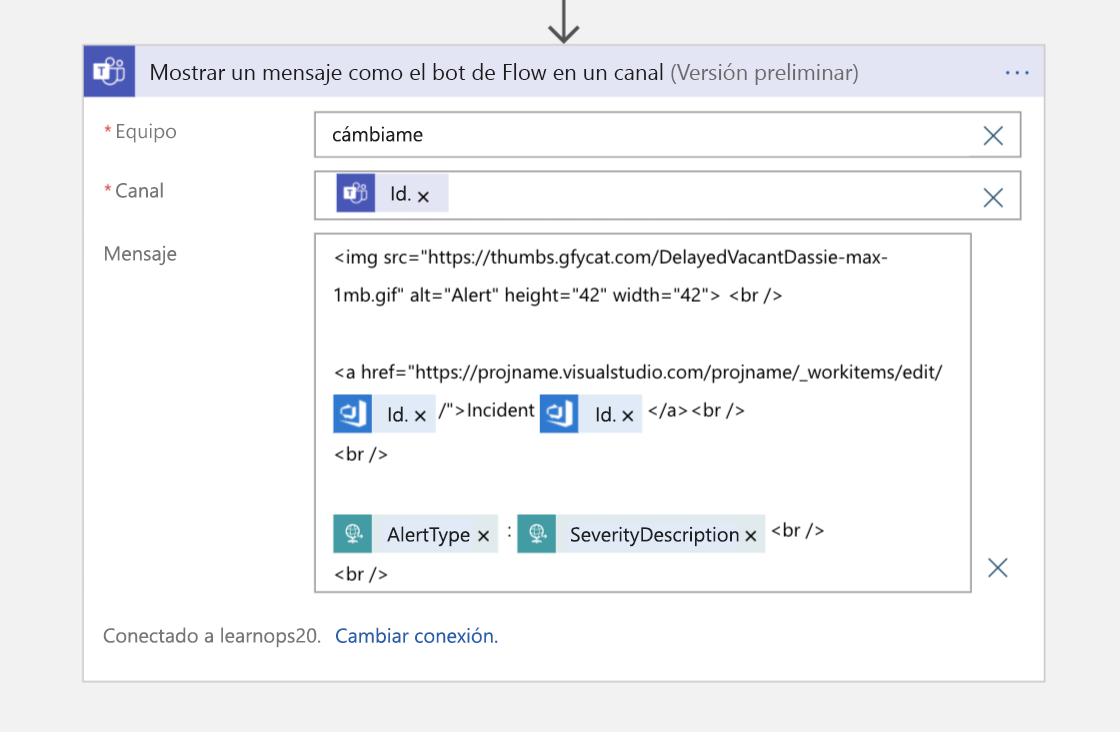
A continuación, como paso final, enviaremos un mensaje al canal de Teams con un enlace al elemento de trabajo para aquellas personas que se incorporen al canal y quieran saber dónde se almacena la información autorizada de ese incidente.
Este es solo un ejemplo de cómo podemos automatizar la configuración de los mecanismos para el seguimiento y la comunicación de incidentes. En la unidad siguiente, profundizaremos un poco más en aspectos de la comunicación en torno a un incidente.