Redes neuronales convolucionales
- 15 minutos
En la unidad anterior hemos aprendido a definir una red neuronal genérica de varias capas. En esta unidad, veremos las redes neuronales convolucionales (CNN), que están diseñadas para computer vision.
Computer Vision es diferente de la clasificación genérica, porque cuando intentamos encontrar un determinado objeto en la imagen, estamos examinando la imagen buscando algunos patrones específicos y sus combinaciones. Por ejemplo, al buscar un gato, primero podemos buscar líneas horizontales, que pueden formar bigotes y, a continuación, cierta combinación de bigotes puede decirnos que es realmente una imagen de un gato. La posición y la presencia de determinados patrones son importantes. Para extraer patrones, usaremos la noción de filtros convolucionales.
Pero en primer lugar, vamos a cargar todas las dependencias y definir las funciones auxiliares que usaremos:
import keras
import tensorflow as tf
import matplotlib.pyplot as plt
import numpy as np
def plot_convolution(data, t, title=''):
t = tf.constant(t, dtype=tf.float32)
t = tf.reshape(t, [*t.shape, 1, 1])
fig, ax = plt.subplots(len(data), 2)
fig.suptitle(title, fontsize=16)
for i in range(len(data)):
d = tf.reshape(tf.constant(data[i], dtype=tf.float32), [1, *data[i].shape, 1])
ax[i][0].imshow(data[i])
ax[i][1].imshow(tf.nn.conv2d(d, t, [1, 1, 1, 1], 'SAME')[0, ..., 0])
def plot_results(hist):
plt.figure(figsize=(12, 4))
plt.subplot(1, 2, 1)
plt.plot(hist.history['accuracy'], label='Training acc')
plt.plot(hist.history['val_accuracy'], label='Validation acc')
plt.legend()
plt.subplot(1, 2, 2)
plt.plot(hist.history['loss'], label='Training loss')
plt.plot(hist.history['val_loss'], label='Validation loss')
plt.legend()
def display_dataset(dataset, labels=None, n=10, classes=None):
fig, ax = plt.subplots(1, n)
for i in range(n):
ax[i].imshow(dataset[i])
ax[i].axis('off')
if labels is not None:
# Handle both scalar labels (e.g. MNIST) and array labels (e.g. CIFAR-10)
lbl = int(labels[i][0]) if np.ndim(labels[i]) > 0 else int(labels[i])
ax[i].set_title(classes[lbl] if classes is not None else str(lbl))
Ahora vamos a cargar el conjunto de datos MNIST:
(x_train, y_train), (x_test, y_test) = keras.datasets.mnist.load_data()
x_train = x_train.astype(np.float32) / 255.0
x_test = x_test.astype(np.float32) / 255.0
Filtros convolucionales
Los filtros convolucionales son ventanas pequeñas que se ejecutan sobre cada píxel de la imagen y calculan el promedio ponderado de los píxeles vecinos. Se definen mediante matrices de coeficientes de peso. Veamos los ejemplos de cómo aplicar dos filtros convolucionales diferentes sobre nuestros dígitos manuscritos MNIST:
plot_convolution(x_train[:5], [[-1., 0., 1.], [-1., 0., 1.], [-1., 0., 1.]], 'Vertical edge filter')
plot_convolution(x_train[:5], [[-1., -1., -1.], [0., 0., 0.], [1., 1., 1.]], 'Horizontal edge filter')
# Expected output: Two sets of images showing original digits alongside the result of applying vertical and horizontal edge filters
El primer filtro se denomina filtro perimetral vertical y se define mediante la siguiente matriz: $$ \left( \begin{matrix} -1 & 0 & 1 \ -1 & 0 & 1 \ -1 & 0 & 1 \ \end{matrix} \right) $$ Cuando este filtro se desliza sobre una región relativamente uniforme de píxeles, la suma ponderada producida por la convolución está cerca de 0, porque las ponderaciones positivas y negativas se cancelan. Cuando encuentra un borde vertical (donde las densidades de píxeles cambian de izquierda a derecha), la convolución genera un valor positivo o negativo grande. Por eso en las imágenes anteriores puede ver bordes verticales resaltados por valores altos y bajos, mientras que los bordes horizontales se suavizan.
Sucede lo contrario cuando aplicamos un filtro de borde horizontal: se amplifican las líneas horizontales y se promedian las verticales.
En computer vision clásica, se aplicaron varios filtros a la imagen para generar características, que luego se usaron en el algoritmo de aprendizaje automático para crear un clasificador. En el aprendizaje profundo, creamos redes que aprenden los mejores filtros convolucionales para resolver el problema de clasificación por sí mismo.
Para ello, presentamos capas convolucionales.
Capas convolucionales
Las capas convolucionales se definen mediante Conv2D la clase . Es necesario especificar lo siguiente:
-
filters: número de filtros que se van a usar. Usaremos 9 filtros diferentes, lo que proporcionará a la red muchas oportunidades para explorar qué filtros funcionan mejor para nuestro escenario. -
kernel_sizees el tamaño de la ventana deslizante. Normalmente se usan filtros 3x3 o 5x5.
La CNN más sencilla contiene solo una capa convolucional. Dado el tamaño de entrada 28x28, después de aplicar nueve filtros 5x5 terminaremos con un tensor de 24x24x9. La dimensión espacial es más pequeña porque el valor predeterminado padding='valid' significa que no se agrega relleno y solo hay 24 posiciones en las que una ventana deslizante de tamaño 5 puede caber en 28 píxeles (28 – 5 + 1 = 24). El uso de padding='same' conservaría las dimensiones espaciales agregando relleno de ceros alrededor de la entrada.
Después de la convolución, aplanamos el tensor de 24×24×9 en un único vector de tamaño 5184, y luego agregamos una capa densa para producir 10 clases. La relu función de activación se aplica después de la capa convolucional para introducir una no linealidad.
model = keras.Sequential([
keras.layers.Input(shape=(28, 28, 1)),
keras.layers.Conv2D(filters=9, kernel_size=(5, 5), activation='relu'),
keras.layers.Flatten(),
keras.layers.Dense(10)
])
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
model.summary()
# Expected output: Model summary showing a Conv2D layer, Flatten, and Dense(10) with ~52k parameters
Puede ver que esta red contiene alrededor de 52 000 parámetros entrenables (234 en la capa convolucional + 51 850 en la capa densa), en comparación con alrededor de 80 000 en redes multicapa totalmente conectadas. Las redes convolucionales generalizan mejor, lo que nos permite lograr buenos resultados en conjuntos de datos más pequeños.
Nota:
En la mayoría de los casos prácticos, queremos aplicar capas convolucionales a imágenes de color. Por lo tanto, Conv2D la capa espera que la entrada sea de la forma $H\times W\times C$, donde $H$ y $W$ son alto y ancho de la imagen, y $C$ es el número de canales de color. Para las imágenes de escala de grises, necesitamos la misma forma con $C=1$.
Es necesario volver a dar forma a los datos antes de iniciar el entrenamiento:
x_train_c = np.expand_dims(x_train, 3)
x_test_c = np.expand_dims(x_test, 3)
hist = model.fit(x_train_c, y_train, validation_data=(x_test_c, y_test), epochs=3)
# Expected output: Training for 3 epochs showing loss and accuracy for training and validation sets
plot_results(hist)
# Expected output: Plots showing training and validation accuracy and loss over 3 epochs
Como puede ver, podemos lograr una mayor precisión con menos épocas en comparación con las redes totalmente conectadas de la unidad anterior. Sin embargo, el propio entrenamiento requiere más recursos y puede ser más lento en equipos que no son de GPU.
Visualización de capas convolucionales
También podemos visualizar los pesos de nuestras capas convolucionales entrenadas para intentar tener más sentido de lo que sucede:
fig, ax = plt.subplots(1, 9)
l = model.layers[0].weights[0]
for i in range(9):
ax[i].imshow(l[..., 0, i])
ax[i].axis('off')
# Expected output: 9 small images showing the learned 5x5 convolutional filter weights
Puede ver que algunos de esos filtros parecen poder reconocer algunos trazos oblicuos, mientras que otros parecen aleatorios.
CNN de varias capas y capas de agrupación
En primer lugar, las capas convolucionales buscan patrones primitivos, como líneas horizontales o verticales. Podemos aplicar capas convolucionales adicionales sobre ellas para buscar patrones de nivel superior, como formas primitivas. A continuación, más capas convolucionales pueden combinar esas formas en algunas partes de la imagen, hasta el objeto final que estamos intentando clasificar.
Al hacerlo, también podemos aplicar un truco: reducir el tamaño espacial de la imagen. Una vez que hemos detectado que hay un trazo horizontal dentro de la ventana deslizante de 3x3, no es tan importante en qué píxel exacto ocurrió. Por lo tanto, podemos "escalar" el tamaño de la imagen, lo cual se realiza mediante una de las capas de agrupación:
- La agrupación media toma una ventana deslizante (por ejemplo, 2 x 2 píxeles) y calcula un promedio de valores dentro de la ventana
- La agrupación máxima reemplaza la ventana por el valor máximo. La idea detrás de la agrupación máxima es detectar una presencia de un determinado patrón dentro de la ventana deslizante.
Por lo tanto, en una CNN típica habría varias capas convolucionales, con capas de agrupación entre ellas para disminuir las dimensiones de la imagen. También aumentaríamos el número de filtros, ya que a medida que los patrones se vuelven más avanzados, hay combinaciones más posibles interesantes que necesitamos buscar.
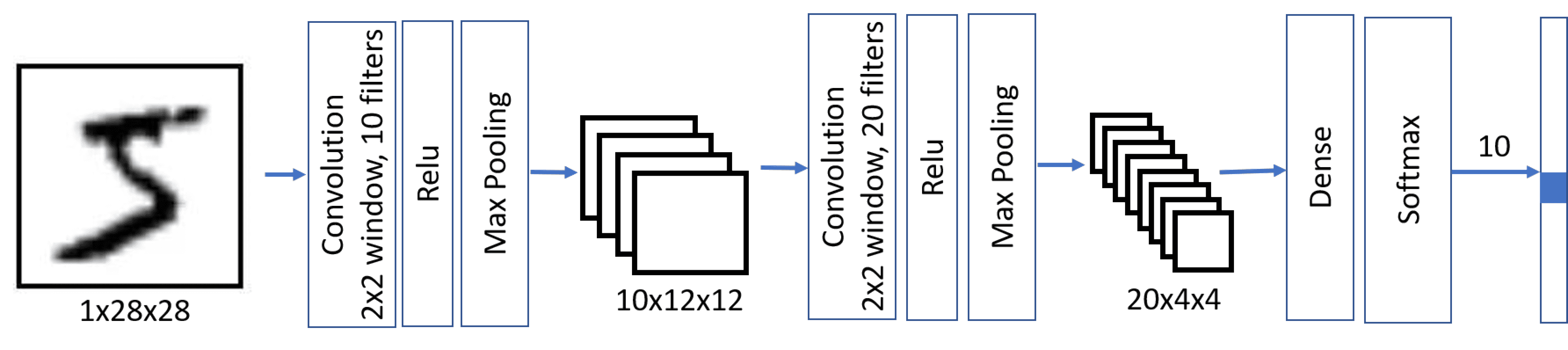
Esta arquitectura también se denomina arquitectura piramidal debido a la disminución de las dimensiones espaciales y al aumento de las dimensiones de características y filtros.
model = keras.Sequential([
keras.layers.Input(shape=(28, 28, 1)),
keras.layers.Conv2D(filters=10, kernel_size=(5, 5), activation='relu'),
keras.layers.MaxPooling2D(),
keras.layers.Conv2D(filters=20, kernel_size=(5, 5), activation='relu'),
keras.layers.MaxPooling2D(),
keras.layers.Flatten(),
keras.layers.Dense(10)
])
model.compile(loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
model.summary()
# Expected output: Model summary showing Conv2D, MaxPooling, Conv2D, MaxPooling, Flatten, Dense with ~8.5k parameters
Observe que el número de parámetros entrenables (~8.5K) es considerablemente menor que en los casos anteriores. Esto sucede porque las capas convolucionales en general tienen pocos parámetros y la dimensionalidad de la imagen antes de aplicar la capa densa final se reduce.
hist = model.fit(x_train_c, y_train, validation_data=(x_test_c, y_test), epochs=3)
# Expected output: Training for 3 epochs showing loss and accuracy for training and validation sets
plot_results(hist)
# Expected output: Plots showing training and validation accuracy and loss over 3 epochs
Observe que podemos lograr una mayor precisión con más de una capa y necesita un número menor de épocas. Esto significa que una arquitectura de red más sofisticada necesita menos datos para averiguar lo que está ocurriendo y para extraer patrones genéricos de nuestras imágenes. Sin embargo, cada época implica más cálculo debido a las operaciones convolucionales adicionales, por lo que el entrenamiento es más rápido con una GPU.
Jugando con imágenes reales del conjunto de datos CIFAR-10
Aunque nuestro problema de reconocimiento de dígitos manuscritos puede parecer un problema de juguete, ahora estamos listos para hacer algo más serio. Vamos a explorar un conjunto de datos más avanzado de imágenes de diferentes objetos, denominado CIFAR-10. Contiene 60 000 imágenes de 32 x 32, divididas en 10 clases.
Nota:
A partir de este punto, se vuelve a cargar x_train, y_train, x_testy y_test con el conjunto de datos CIFAR-10, reemplazando los datos MNIST usados anteriormente en esta unidad. Las variables x_train_c y x_test_c expandidas ya no son necesarias.
(x_train, y_train), (x_test, y_test) = keras.datasets.cifar10.load_data()
x_train = x_train.astype(np.float32) / 255.0
x_test = x_test.astype(np.float32) / 255.0
classes = ('plane', 'car', 'bird', 'cat',
'deer', 'dog', 'frog', 'horse', 'ship', 'truck')
display_dataset(x_train, y_train, classes=classes)
# Expected output: A row of 10 CIFAR-10 images with their class labels
Una arquitectura clásica de CNN es LeNet, propuesta por Yann LeCun originalmente para el reconocimiento de dígitos manuscritos. Vamos a adaptarlo para CIFAR-10. Sigue los mismos principios que hemos descrito anteriormente, la diferencia principal es 3 canales de color de entrada en lugar de 1.
model = keras.Sequential([
keras.layers.Input(shape=(32, 32, 3)),
keras.layers.Conv2D(filters=6, kernel_size=5, strides=1, activation='relu'),
keras.layers.MaxPooling2D(pool_size=2, strides=2),
keras.layers.Conv2D(filters=16, kernel_size=5, strides=1, activation='relu'),
keras.layers.MaxPooling2D(pool_size=2, strides=2),
keras.layers.Flatten(),
keras.layers.Dense(120, activation='relu'),
keras.layers.Dense(84, activation='relu'),
keras.layers.Dense(10)
])
model.summary()
# Expected output: Model summary showing the LeNet architecture with Conv2D, MaxPooling, Dense layers
El entrenamiento adecuado de esta red lleva una cantidad significativa de tiempo y debe realizarse en un sistema habilitado con GPU.
model.compile(optimizer='adam', loss=keras.losses.SparseCategoricalCrossentropy(from_logits=True), metrics=['accuracy'])
hist = model.fit(x_train, y_train, validation_data=(x_test, y_test), epochs=10)
# Expected output: Training for 10 epochs showing loss and accuracy for training and validation sets
plot_results(hist)
# Expected output: Plots showing training and validation accuracy and loss over 10 epochs
La precisión que hemos podido lograr con solo unas pocas épocas de entrenamiento es aceptable. Recuerde que nuestro problema es significativamente más difícil que la clasificación de dígitos MNIST. Obtener más de 60% precisión es un buen logro en un breve tiempo de entrenamiento, aunque los modelos de última generación pueden lograr más de 95% en CIFAR-10 mediante arquitecturas más profundas, aumento de datos y entrenamiento más largo.
Takeaways
En esta unidad, hemos aprendido el concepto principal detrás de las redes neuronales de Computer Vision: redes convolucionales. Las arquitecturas reales que potencian la clasificación de imágenes, la detección de objetos e incluso las redes de generación de imágenes se basan en CNN, solo con más capas y algunos trucos de entrenamiento adicionales.
Comprueba tus conocimientos
Comentarios
¿Le ha resultado útil esta página?
No
¿Necesita ayuda con este tema?
¿Desea intentar usar Ask Learn para aclarar o guiarle a través de este tema?