Azure Batch
- 10 minutos
La informática de alto rendimiento (HPC) es la práctica de usar una potencia informática significativa que proporciona un alto rendimiento en comparación con lo que puede obtener al usar su portátil o estación de trabajo. Resuelve problemas grandes que necesitan ejecutarse en varios núcleos simultáneamente.
Esto se hace dividiendo un problema en unidades computables más pequeñas y distribuyendo esas unidades en un sistema distribuido. Se comunica continuamente entre ellos para llegar a la solución final más rápido que ejecutar el mismo cálculo en menos núcleos.
Hay varias opciones de procesamiento por lotes y HPC disponibles en Azure. Si habla con un experto de Azure, le aconsejará centrarse en tres opciones: Azure Batch, Azure CycleCloud y Microsoft HPC Pack. Las siguientes unidades de este módulo se centran en cada opción. Es importante tener en cuenta que estas opciones no son mutuamente excluyentes. Se basan entre sí y se pueden considerar como herramientas diferentes en un cuadro de herramientas.
Aquí obtendrá información sobre la informática de alto rendimiento en general y obtendrá información sobre Azure HPC.
¿Qué es HPC en Azure?
Hay muchos sectores diferentes que requieren recursos informáticos eficaces para tareas especializadas. Por ejemplo:
- En ciencias genéticas, secuenciación genética.
- En exploración de petróleo y gas, simulaciones de depósitos.
- En finanzas, modelado de mercado.
- En ingeniería, modelado de sistemas físicos.
- En meteorología, el modelado meteorológico.
Estas tareas requieren procesadores que puedan llevar a cabo instrucciones rápidamente. Las aplicaciones de HPC en Azure se pueden escalar a miles de núcleos de proceso, ampliar el proceso grande local o ejecutarse como una solución nativa en la nube del 100 %. Esta solución de HPC, incluidos el nodo principal, los nodos de proceso y los nodos de almacenamiento, se ejecuta en Azure sin infraestructura de hardware que se mantenga. Esta solución se basa en los servicios administrados por Azure: Virtual Machine Scale Sets, Virtual Network y Cuentas de almacenamiento.
Estos servicios se ejecutan en un entorno de alta disponibilidad, revisado y compatible, lo que le permite centrarse en la solución, en lugar de en el entorno en que se ejecutan. Un sistema de Azure HPC también tiene la ventaja de que puede agregar recursos dinámicamente a medida que son necesarios y quitarlos cuando cae la demanda.
¿Qué es la computación en paralelo en sistemas distribuidos?
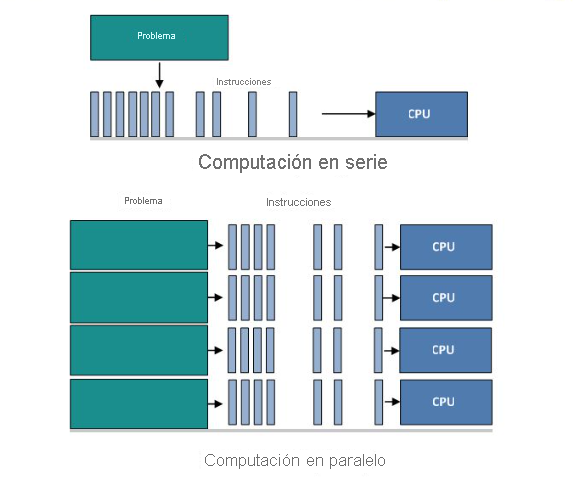
Parallel Computing es el uso simultáneo de varios recursos de proceso para resolver un problema computacional:
- Un problema se divide en partes discretas que se pueden resolver simultáneamente.
- Cada parte se desglosa aún más en una serie de instrucciones.
- Las instrucciones de cada elemento se ejecutan simultáneamente en diferentes procesadores.
- Se emplea un mecanismo general de control y coordinación.
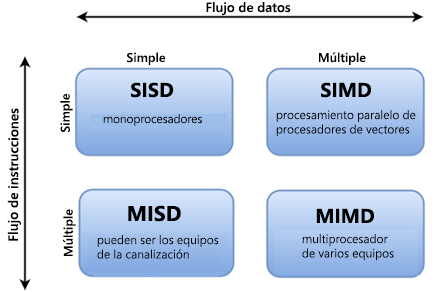
Diferentes fases del paralelismo
Hay diferentes maneras de clasificar equipos paralelos y la taxonomía de Flynn es una de las formas más comunes de hacerlo. Distingue las arquitecturas de equipos de varios procesadores según cómo se pueden clasificar a lo largo de las dos dimensiones independientes del flujo de instrucciones y el flujo de datos. Cada una de estas dimensiones solo puede tener uno de los dos estados posibles: Single o Multiple.
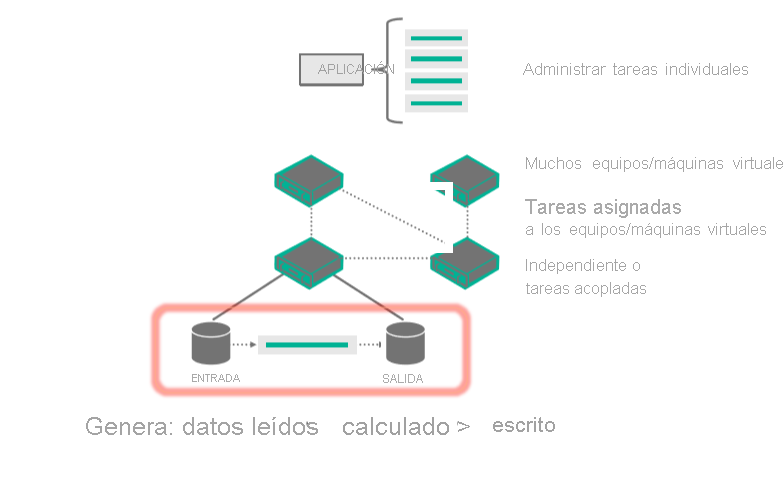
En este diagrama se muestra una aplicación cliente o un servicio hospedado que interactúa con Batch para cargar entradas, crear trabajos, supervisar tareas y descargar la salida.
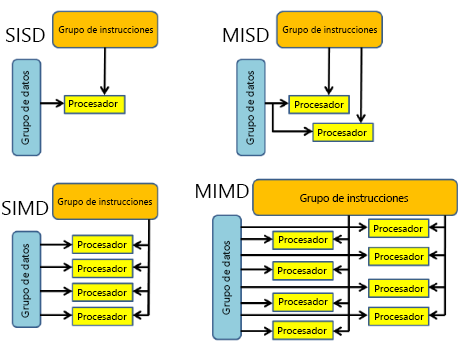
Podemos echar un vistazo a las cuatro clasificaciones diferentes con más detalle.
| SISD | SIMD | MISD | MIMD |
|---|---|---|---|
| - Ordenador en serie (no paralelo) - Instrucción única: solo la CPU actúa en una secuencia de instrucciones durante un ciclo de reloj. - Datos únicos: solo se usa un flujo de datos como entrada durante cualquier ciclo de reloj. - Tipo más antiguo de equipo. Ejemplos: 1. Sistemas centrales de primera generación 2. Minicomputers, Estaciones de trabajo 3. Pc de núcleo de procesador único |
- Equipo paralelo - Instrucción única: todas las unidades de procesamiento ejecutan la misma instrucción en cualquier ciclo de reloj determinado. - Varios datos: cada unidad de procesamiento puede funcionar en un elemento de datos diferente. - Más adecuado para problemas especializados caracterizados por un alto grado de regularidad, como el procesamiento de gráficos/imágenes. - La mayoría de los equipos modernos, con unidades de procesador de gráficos (GPU) emplean instrucciones SIMD y unidades de ejecución. Ejemplos: 1. Matrices de procesador: Thinking Machines CM-2, MasPar MP-1 & MP-2, ILLIAC IV 2. Canalizaciones vectoriales: IBM 9000, Cray X-MP, Y-MP & C90, Fujitsu VP, NEC SX-2, Hitachi S820, ETA10 |
- Equipo paralelo - Varias instrucciones: cada unidad de procesamiento funciona en los datos de forma independiente a través de secuencias de instrucciones independientes. - Datos únicos: un único flujo de datos se introduce en varias unidades de procesamiento. - Pocos (si es que hay alguno) ejemplos reales de esta clase de ordenador paralelo han existido alguna vez. Ejemplos: 1. Varios filtros de frecuencia que funcionan en una sola secuencia de señal 2. Varios algoritmos de criptografía que intentan descifrar un único mensaje codificado |
- Equipo paralelo - Varias instrucciones: cada procesador puede estar ejecutando un flujo de instrucción diferente. - Varios datos: cada procesador puede estar trabajando con un flujo de datos diferente. - Actualmente, el tipo más común de equipo paralelo - la mayoría de los superequipos modernos se dividen en esta categoría. Ejemplos: 1. Superequipos más actuales 2. Clústeres de equipos paralelos en red y "cuadrículas" 3. Equipos SMP con varios procesadores 4. Pc con varios núcleos |
Diferentes tipos de trabajos de HPC: Paralelo masivo frente a estrechamente acoplado
Los trabajos paralelos tienen problemas computacionales divididos en tareas pequeñas, sencillas e independientes. Las tareas se pueden ejecutar al mismo tiempo, a menudo con poca o ninguna comunicación entre ellas.
Entre los casos de uso comunes para trabajos paralelos se incluyen simulaciones de riesgo, modelado molecular, búsqueda contextual y simulaciones de logística.
Los trabajos estrechamente acoplados tienen una gran carga de trabajo compartida que se divide en tareas más pequeñas que se comunican continuamente. Los distintos nodos del clúster se comunican entre sí a medida que realizan su procesamiento.
Entre los casos de uso comunes para trabajos estrechamente acoplados se incluyen:
- Dinámica de fluidos computacionales.
- Modelado de previsión meteorológica.
- Simulaciones de material.
- Emulación de colisión de automóviles.
- Simulaciones geoespaciales.
- Administración del tráfico.
¿Qué es la interfaz de paso de mensajes (MPI)
MPI es un sistema que pretende proporcionar un estándar portátil y eficaz para el paso de mensajes. Es de alto rendimiento, portátil, escalable y se desarrolló para trabajar en redes de diferentes equipos paralelos.
MPI ha ayudado en redes y computación paralela a escala industrial y global. También ha ayudado a mejorar el trabajo de aplicaciones informáticas paralelas a gran escala.
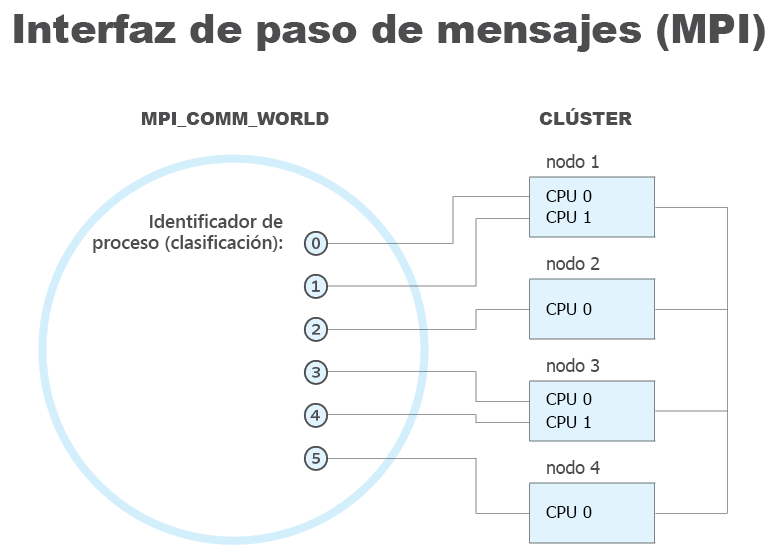
Entre las ventajas de Microsoft MPI se incluyen:
- Facilidad de portabilidad del código existente que usa MPICH.
- Seguridad basada en Active Directory Domain Services.
- Alto rendimiento en el sistema operativo Windows.
- Compatibilidad binaria entre diferentes tipos de opciones de interconectividad.