Microsoft HPC Pack
Para un mayor control de su infraestructura de alto rendimiento, o si administra máquinas virtuales locales y en la nube, considere la posibilidad de usar Microsoft HPC Pack.
En la empresa de ingeniería, quiere migrar una infraestructura de alto rendimiento desde los centros de datos locales a Azure. Como estos sistemas son críticos para la empresa, quiere llevarlo a cabo de manera gradual. Debe procurar que, durante la migración, la demanda se pueda atender rápidamente y que las máquinas virtuales se puedan administrar de forma flexible, cuando haya máquinas virtuales locales y en la nube.
Aquí obtendrá información sobre cómo HPC Pack puede administrar la infraestructura de HPC.
¿Qué es HPC Pack?
Al investigar las distintas opciones disponibles para la organización de ingeniería, ha examinado Azure Batch y las instancias de HPC de Azure. Pero, ¿y si lo que busca es tener control total sobre la administración y programación de los clústeres de las máquinas virtuales? ¿Qué ocurre si ha realizado una inversión significativa en la infraestructura local del centro de datos? HPC Pack ofrece una serie de instaladores para Windows que permiten configurar un plano de administración y control propio, así como implementaciones de nodos locales y en la nube tremendamente flexibles. Al contrario que Batch, que se basa eminentemente en la nube, HPC Pack proporciona flexibilidad de implementación en el entorno local y en la nube. Usa un híbrido de ambas tecnologías para expandir hacia la nube cuando las reservas locales no son suficientes.

HPC Pack es una versión de administración por lotes y programación de capas de control, que te garantiza un control y responsabilidad totales. La implementación de HPC Pack requiere Windows Server 2012 o posterior.
Planeación de HPC Pack
Normalmente, la instalación de HPC Pack se debe preparar revisando detenidamente todos los requisitos. Se necesita un servidor SQL Server y un controlador de Active Directory. También hay que planificar una topología. ¿Cuántos nodos principales y de control debe haber? ¿Cuántos nodos de trabajo? ¿Es necesario expandir hacia Azure? Si así es, aprovisione previamente los nodos de Azure como parte del clúster. El tamaño de los equipos principales que forman el plano de control (el nodo principal y los de control, servidor SQL Server y controlador de dominio de Active Directory) depende del tamaño de clúster previsto.
Al instalar HPC Pack, se muestra un programador de trabajos que admite trabajos de HPC y paralelos. El programador se muestra en la interfaz de paso de mensajes de Microsoft. HPC Pack se integra plenamente en Windows, por lo que se puede usar Visual Studio para la depuración en paralelo. Todos los eventos de aplicación, red y sistema operativo de los nodos de proceso del clúster se pueden ver en una única vista del depurador.
HPC Pack ofrece también un programador de trabajos avanzado. Las implementaciones se pueden realizar con total rapidez, incluso en nodos no dedicados exclusivamente a HPC Pack, en nodos basados en Linux y en nodos de Azure. Esto significa que puede usar la capacidad de reserva existente en el centro de datos. HPC Pack constituye una forma ideal de aprovechar las inversiones de infraestructura existentes y de mantener un control más discreto sobre cómo se divide el trabajo de lo que Batch permite.
Uso de una mezcla de tecnologías
Las opciones que se describen en este módulo no son mutuamente excluyentes. Se pueden usar máquinas virtuales de la serie H, que se han analizado en la última unidad, como posibles nodos de Azure en una configuración de HPC. Aunque se ha centrado en casos de uso híbridos para resaltar las diferencias con Batch, HPC Pack es flexible. Permite tanto las implementaciones exclusivamente locales como las que se basan de forma exclusiva en la nube. Esta flexibilidad es útil cuando se quiere un control más granular que el que ofrece Batch.
Implementación y administración de sistemas HPC
Orquestación de sistemas HPC
Uno de los conceptos clave de la informática en la nube es Orquestación. Hace referencia a la comprobación de la implementación, ejecución y supervisión de todos los componentes de una aplicación en el clúster.
Además, un orquestador puede realizar otras tareas como la recuperación (administración de errores), el escalado y el registro. Los orquestadores como los conocidos Kubernetes o Mesos pueden acceder directamente a los recursos del clúster en la nube mediante la virtualización.
Implementación de sistemas HPC
Las implementaciones de HPC en Azure pueden variar según sus necesidades y presupuestos específicos de la carga de trabajo. Hay algunos componentes estándar en cualquier implementación, entre los que se incluyen:
- Azure Resource Manager: permite la implementación de aplicaciones en clústeres mediante plantillas o archivos de script.
- Nodo principal de HPC: permite programar trabajos y cargas de trabajo en nodos de trabajo. Se trata de una máquina virtual (VM) que se usa para administrar clústeres de HPC.
- Virtual Network: permite crear una red aislada de clústeres y almacenamiento a través de conexiones seguras con ExpressRoute o VPN IPsec. Puede integrar servidores DNS establecidos y direcciones IP en la red y controlar de forma granular el tráfico entre subredes.
- Conjuntos de escalado de máquinas virtuales: habilita el aprovisionamiento de máquinas virtuales de clústeres e incluye características para el escalado automático, las implementaciones de varias zonas y el equilibrio de carga. Puede usar conjuntos de escalado para ejecutar varias bases de datos, como MongoDB, Cassandra y Hadoop.
- Almacenamiento: habilita el montaje de clústeres de almacenamiento persistente en forma de almacenamiento de blobs, discos, archivos, híbridos o lago de datos.
Administración de implementaciones de Azure HPC
Azure ofrece algunos servicios nativos para ayudarle a administrar las implementaciones de HPC. Estas herramientas proporcionan flexibilidad para la administración y pueden ayudarle a programar cargas de trabajo en Azure y en recursos híbridos.
- Microsoft HPC Pack: conjunto de utilidades que le permiten configurar y administrar clústeres de máquinas virtuales, supervisar operaciones y programar cargas de trabajo. HPC Pack incluye características que le ayudarán a migrar cargas de trabajo locales o a seguir funcionando con una implementación híbrida. La utilidad no aprovisiona ni administra máquinas virtuales ni infraestructura de red automáticamente.
- Azure CycleCloud: interfaz para el programador que prefiera. Puede usar Azure CycleCloud con una variedad de opciones nativas y de terceros, como HPC Pack, Grid Engine, Slurm y Symphony. CycleCloud permite administrar y organizar cargas de trabajo, definir controles de acceso con Active Directory y personalizar directivas de clúster.
- Azure Batch: herramienta administrada que puede usar para escalar automáticamente las implementaciones y establecer directivas para la programación de trabajos. El servicio Azure Batch controla el aprovisionamiento, la asignación, los entornos de ejecución y la supervisión de las cargas de trabajo. Para usarlo, solo tiene que cargar las cargas de trabajo y configurar el grupo de máquinas virtuales.
Las cargas de trabajo de Azure HPC ofrecen aprendizaje automático, visualización y representación, lo que fortalece las aplicaciones del sector de los semiconductores. Permite la integración sin problemas y resistentes en la nube de cargas de trabajo de petróleo y gas, así como la secuenciación genómica basada en la nube y el diseño de semiconductores.
Procedimientos recomendados para implementaciones de Azure HPC
Los procedimientos recomendados siguientes pueden ayudarle a obtener el rendimiento esperado y el valor.
Distribuir implementaciones entre Cloud Services: distribuir implementaciones de gran tamaño entre servicios en la nube puede ayudarle a evitar limitaciones creadas mediante la sobrecarga o la confianza en un único servicio. Al dividir la implementación en segmentos más pequeños, puede hacer lo siguiente:
- Detener instancias inactivas después de la finalización del trabajo sin interrumpir otros procesos
- Iniciar y detener de manera flexible los clústeres de nodos
- Encontrar más fácilmente los nodos disponibles en los clústeres
- Uso de varios centros de datos para garantizar la recuperación ante desastres
Use varias cuentas de Azure Storage para implementaciones de nodos: de forma similar a la propagación de implementaciones entre servicios, se recomienda asociar varias cuentas de almacenamiento a cada implementación. Puede proporcionar un mejor rendimiento para implementaciones de gran tamaño, aplicaciones restringidas por operaciones de entrada y salida y aplicaciones personalizadas. Al configurar las cuentas de almacenamiento, debe tener una cuenta para el aprovisionamiento de nodos y otra para mover datos de trabajos o tareas para garantizar la coherencia y baja latencia.
Aumente las instancias de nodo proxy para que coincidan con el tamaño de implementación: los nodos proxy permiten la comunicación entre los nodos principales que está trabajando en el entorno local y los nodos de trabajo de Azure. Estos nodos se adjuntan automáticamente al implementar trabajos en Azure. Si está ejecutando trabajos grandes que cumplen o superan los recursos proporcionados por los nodos proxy, considere la posibilidad de aumentar el número que ha ejecutado. Hacerlo es especialmente importante a medida que la implementación aumenta.
Conéctese al nodo principal con las utilidades de cliente de HPC:
Las utilidades de cliente de HPC Pack son el método preferido para conectarse al nodo principal, especialmente si está ejecutando trabajos grandes. Puede instalar estas utilidades en las estaciones de trabajo de los usuarios y acceder de forma remota al nodo principal según sea necesario en lugar de usar Servicios de Escritorio remoto (RDS). Estas utilidades son especialmente útiles si muchos usuarios se conectan a la vez.
Programación de tareas
Otro servicio de informática de alto rendimiento (HPC) que se ofrece es la programación de tareas. Puede usar el programador en la aplicación para distribuir el trabajo, lo que permite la ejecución de trabajos por lotes de forma eficaz. Los principales objetivos del programador se pueden clasificar de forma general como:
- Minimizar el tiempo entre el envío del trabajo y la finalización de este. Ningún trabajo debe permanecer en la cola durante largos períodos de tiempo.
- Optimizar el uso de CPU. Especialmente, reduciendo el tiempo de inactividad de CPU.
- Maximizar el rendimiento del trabajo, es decir, el escalado de trabajos por unidad de tiempo.
Acerca de la programación de tareas
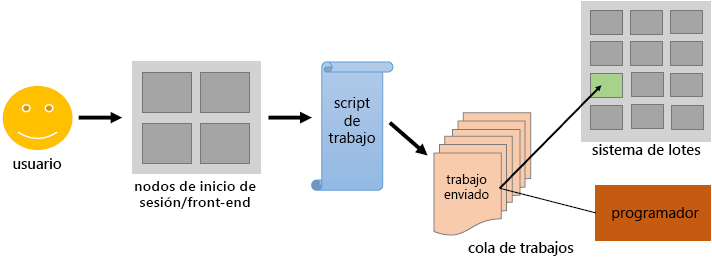
Los usuarios envían trabajos por lotes no interactivos al programador. El programador almacena los trabajos por lotes, evalúa sus requisitos y prioridades de recursos y distribuye los trabajos a los nodos de proceso adecuados. Constituyen la mayor parte de los clústeres de HPC (aproximadamente el 98 %) como la más consumida.
A diferencia de los nodos de inicio de sesión y su uso interactivo, los nodos de proceso no son accesibles directamente a través de ssh. El programador del nodo de inicio de sesión actúa como una interfaz entre el nodo de proceso y el usuario. El usuario debe especificar la aplicación dentro de un script de trabajo en función de los recursos de tiempo y memoria.
El script de trabajo enviado mediante el programador agrega el trabajo a una cola de trabajos. En función de los recursos disponibles que necesite el trabajo, el programador decide cuándo el trabajo deja la cola y en qué (parte de los) nodos back-end se ejecuta.
El usuario debe asegurarse de que los recursos solicitados están dentro de los límites del sistema. Por ejemplo:
- El programador elimina el trabajo una vez que la hora asignada está activa, incluso si el trabajo exige más tiempo.
- El trabajo se bloquea en la cola para siempre si el trabajo requiere más memoria de la que hay disponible en el sistema.
Ilustración
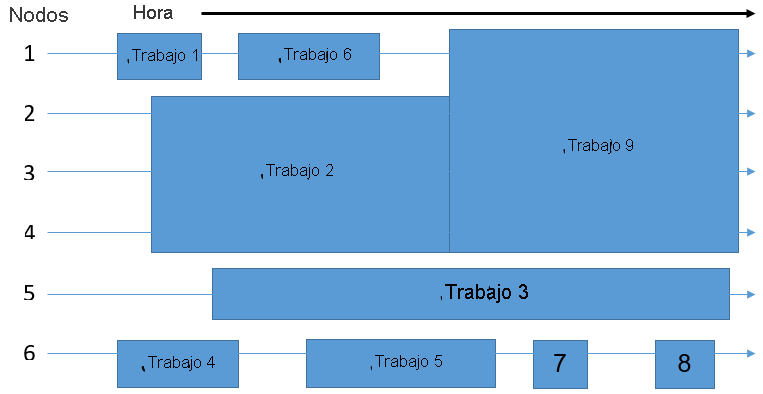
Suponiendo que el sistema por lotes que usa consta de seis nodos, el programador usa TI para colocar los nueve trabajos en la cola en los nodos disponibles. El objetivo es eliminar los recursos desperdiciados que se muestran en el diagrama siguiente como las áreas libres que muestran nodos sin ninguna ejecución de trabajo en ellos.
Por lo tanto, es posible que los trabajos no se distribuyan entre los nodos en el mismo orden en el que entraron por primera vez en la cola. El espacio que ocupa un trabajo viene determinado por el tiempo y el número de nodos necesarios para ejecutarlo. El programador desempeña un rol rotacional multidimensional para rellenar uniformemente los nodos del clúster, equilibrando los requisitos de recursos de todos los trabajos con los recursos disponibles en el clúster.
Algoritmos de programación
Hay dos estrategias básicas que los programadores pueden usar para determinar qué trabajo ejecutar a continuación. Los programadores modernos no se adhieren estrictamente a uno de estos algoritmos, sino que emplean una combinación de los dos. Además, hay muchos más aspectos que un programador debe tener en cuenta, por ejemplo, la carga actual del sistema.
Los trabajos por orden de llegada se ejecutan exactamente en el mismo orden en el que primero entran en la cola. La ventaja es que cada trabajo se ejecuta de forma definitiva. No obstante, un pequeño conjunto de trabajos podría esperar un tiempo inadecuado en comparación con su tiempo real de ejecución.
Trabajo más corto primero En función de la ejecución, la hora declarada en el script de trabajo, el programador calcula el tiempo de ejecución del trabajo. Los trabajos se clasifican en el orden ascendente del tiempo de ejecución. Aunque los trabajos cortos se iniciarán después de un breve tiempo de espera, es posible que nunca se inicien trabajos de larga duración (o al menos trabajos declarados como tales).
Reposición: el programador mantiene el concepto de por orden de llegada sin impedir que se ejecuten trabajos de larga duración. El programador ejecuta el trabajo solo cuando se puede ejecutar el primer trabajo de la cola. En caso contrario, el programador pasa por el resto de la cola para comprobar si se puede ejecutar otro trabajo sin extender el tiempo de espera del primer trabajo en cola. Si encuentra este trabajo, el programador ejecuta ese trabajo. Normalmente, los trabajos pequeños encuentran tiempos de cola cortos.
Administración de flujos de trabajo
Canalización de tareas y automatización
Las operaciones repetidas, como el uso de herramientas y las ejecuciones de secuencia de tareas de proceso de software, se pueden organizar en una canalización. La automatización puede hacer que el uso general de software y herramientas sea más eficaz. Crea eficiencias haciendo que la propia tarea sea más rápida y reduzca la carga sobre el trabajador del conocimiento para su administración.
La automatización puede reducir la tasa de errores de un proceso eliminando la varianza en la forma en que se realiza. Y la canalización y automatización de una tarea pueden abrir la puerta para seguir procesando innovaciones como la paralelización y la implementación en la nube.
Herramientas para la administración de flujos de trabajo
Use Azure Batch
Use Azure Batch para ejecutar aplicaciones de informática de alto rendimiento (HPC) en paralelo y a gran escala, de manera eficaz en Azure. Azure Batch permite crear y administrar un conjunto de nodos de proceso (máquinas virtuales), instalar las aplicaciones que desea ejecutar y programar trabajos para que se ejecuten en los nodos. No hay ningún software de programador de clústeres o trabajos que instalar, administrar o escalar. En su lugar, use API y herramientas de Batch, scripts de línea de comandos o Azure Portal para configurar, administrar y supervisar los trabajos.
Para obtener información completa sobre Azure Batch, que incluya funcionalidades y cómo funciona, consulte Azure Batch.
Use Azure CycleCloud
Azure CycleCloud es una herramienta fácil de manejar para orquestar y administrar entornos de informática de alto rendimiento (HPC) en Azure. Con CycleCloud, los usuarios pueden aprovisionar infraestructura para sistemas de HPC, implementar programadores de HPC y escalar automáticamente la infraestructura para ejecutar trabajos de forma eficaz a cualquier escala. A través de CycleCloud, los usuarios pueden crear diferentes tipos de sistemas de archivos y montarlos en los nodos del clúster de proceso para admitir cargas de trabajo de HPC.
Para más información sobre Azure CycleCloud, consulte Azure CycleCloud.