¿Qué es la formación de equipos rojos de IA?
“Red teaming“ es un término del sector de la seguridad de la información que se usa para describir el proceso de prueba de las vulnerabilidades en la seguridad mediante ataques adversarios sistemáticos. El “red teaming“ se realiza para proteger la seguridad de los sistemas de una organización. El “red teaming“ no tiene que ver con los ataques no autorizados de terceros malintencionados.
La introducción de modelos de lenguaje de gran tamaño (LLM) en ecosistemas de aplicaciones requiere que los “red teams“ incluyan técnicas adversarias en los procedimientos de sondeo, realización de pruebas y ataque a los sistemas de inteligencia artificial. El uso adversario, e incluso benigno, de las aplicaciones habilitadas para la inteligencia artificial puede generar salidas potencialmente perjudiciales. Por ejemplo, que el bot de chat de las redes sociales de una empresa se corrompa para generar discursos de odio o glorificar la violencia. El uso adversario también puede provocar que las aplicaciones de inteligencia artificial emitan datos privados, elaboren ataques y provoquen otros efectos negativos posteriores sobre la seguridad.
En el siguiente diagrama se ofrece información general de la ampliación del ámbito que se ha producido con el “red teaming“ desde la introducción del LLM en los ecosistemas de aplicaciones.
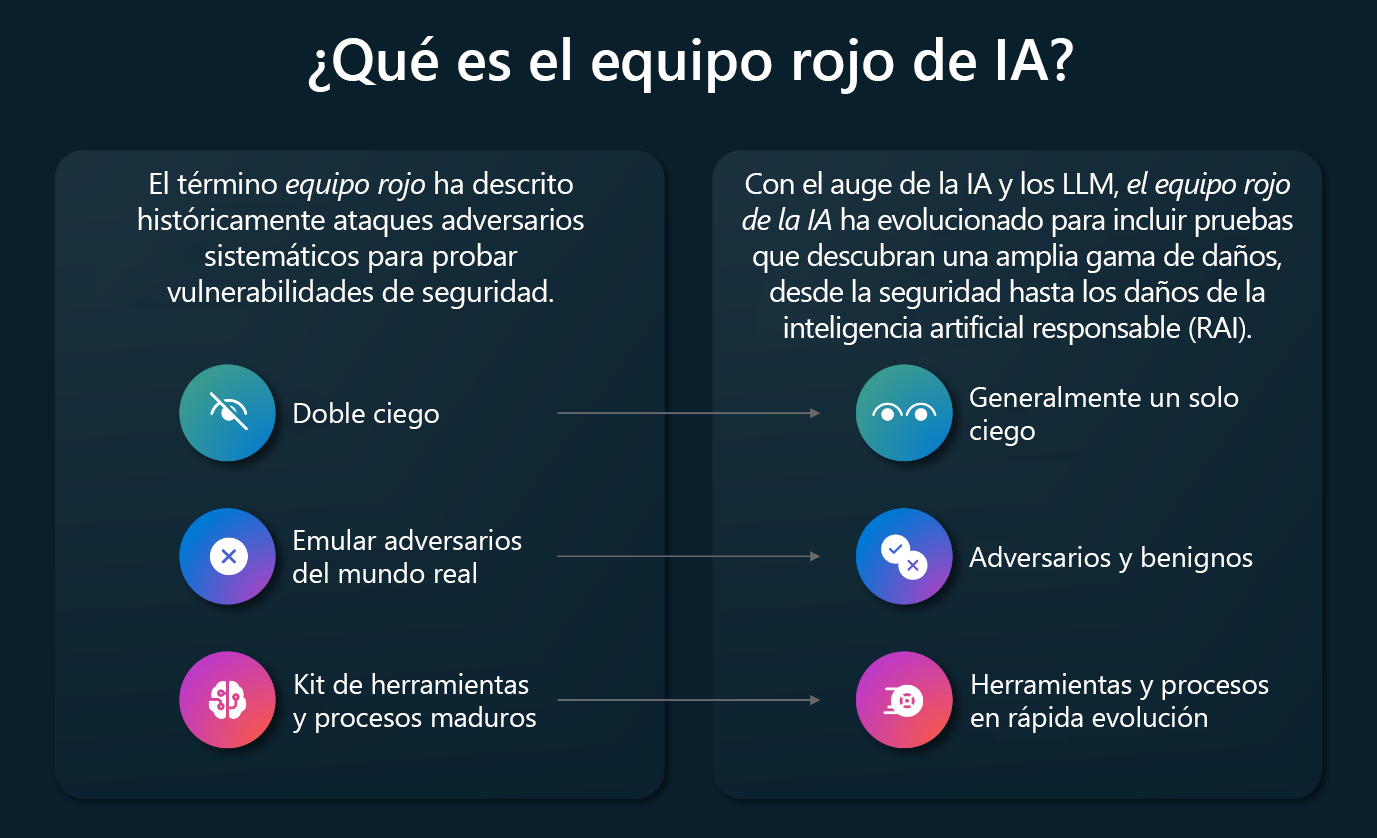
El “red teaming“ de la inteligencia artificial se produce a dos niveles: a nivel del LLM base, como los ataques de “red team“ contra un LLM, como GPT-4 o Phi-3, o a nivel de aplicación, cuando una aplicación habilitada para la inteligencia artificial utiliza un LLM como parte de su infraestructura de back-end. Adoptar este enfoque de dos capas genera los siguientes resultados:
- El uso del proceso “red teaming“ en el modelo ayuda a identificar en una fase temprana del proceso cómo pueden utilizarse mal los modelos, a ampliar las capacidades del modelo y a conocer sus limitaciones. Esta información puede incorporarse al proceso de desarrollo del modelo y mejorar las futuras versiones del mismo.
- A nivel de aplicación, el “red teaming“ adopta un enfoque que abarca todo el sistema, del que el LLM básico es una parte. Por ejemplo, cuando Microsoft ejecutó el proceso “red teaming“ de la inteligencia artificial en Bing Chat, hubo que sondear el LLM de GTP-4, ya que lo utilizaba toda la experiencia de búsqueda de Bing. Adoptar un enfoque que abarque todo el sistema ayuda a identificar errores más allá de los mecanismos de seguridad a nivel de modelo, ya que incluye los desencadenadores de seguridad específicos de la aplicación en general.
Microsoft tiene varios “red teams“ de IA que ejecutan estas pruebas adversarias en modelos de lenguaje de gran tamaño, aplicaciones habilitados para IA y servicios usados por Microsoft. Los equipos han obtenido la siguiente información:
- El “red teaming“ de la inteligencia artificial es más expansivo que el tradicional
- El “red teaming“ de la inteligencia artificial se centra en los errores de personas malintencionadas y benignas
- Los sistemas de IA generativa de “red teaming“ requieren varios intentos de la misma prueba
- Los sistemas de inteligencia artificial evolucionan constantemente
- La mitigación de los errores de la inteligencia artificial requiere una defensa en profundidad
El “red teaming“ de la inteligencia artificial es más expansivo que el tradicional
En la actualidad, el “red teaming“ de la inteligencia artificial es un término paraguas para sondear tanto la seguridad como los resultados de la IA responsable (seguridad). El “red teaming“ de la inteligencia artificial intersecta con los objetivos tradicionales del “red teaming“, pero incluye a los LLM como vector de ataque. El “red teaming“ de la inteligencia artificial comprueba las defensas comparándolas con las nuevas clases de vulnerabilidades de seguridad, entre las que se incluyen la inyección de mensajes y la contaminación del modelo. El “red teaming“ de la inteligencia artificial también incluye el sondeo de aquellos resultados que puedan dañar la reputación de la organización, como problemas de equidad y el contenido nocivo. La realización del “red teaming“ de la inteligencia artificial antes de que se libere al público cualquier carga de trabajo habilitada para LLM o IA ayuda a las organizaciones a identificar los problemas y a clasificar las inversiones en defensa.
El “red teaming“ de la inteligencia artificial se centra en los errores de personas malintencionadas y benignas
A diferencia del “red teaming“ de seguridad tradicional, que se centra principalmente en los adversarios malintencionados, el “red teaming“ de la inteligencia artificial tiene en cuenta un conjunto más amplio de personas y errores. El “red team“ de la inteligencia artificial de Microsoft ha aprendido muchas cosas al realizar pruebas adversarias en una nueva instancia de Bing habilitada para la inteligencia artificial. Al probar el nuevo Bing, el “red teaming“ de la inteligencia artificial no sólo se centró en la forma en que un adversario malintencionado puede subvertir el sistema de IA mediante técnicas y vulnerabilidades centradas en la seguridad, sino también en la forma en que el sistema puede generar contenido problemático y dañino cuando los usuarios normales interactúan con el sistema. Esto es importante porque, como Bing es un producto insignia de Microsoft, el hecho de que genere contenido problemático supondría un daño para la reputación de Microsoft.
Los sistemas de inteligencia artificial generativa de formación de “red teaming“ requieren varios intentos de la misma prueba
En un compromiso de “red teaming“ tradicional, el uso de una herramienta o técnica en dos momentos distintos y con la misma entrada generaría siempre el mismo resultado. Esto se denomina salida determinista. Los sistemas de IA generativa son probabilísticos, lo que significa que ejecutar la misma entrada dos veces puede generar salidas diferentes. La naturaleza probabilística de la IA generativa permite una rango más amplio de salida creativa. Esto dificulta el “red teaming“, ya que el uso de la misma indicación de prueba puede conducir al éxito en un intento y al fracaso en otro. Un método para abordar esto es realizar varias iteraciones de “red teaming“ en la misma operación. Para lograrlo, Microsoft invirtió en automatización que ayuda a escalar las operaciones. Microsoft también desarrolló una estrategia de medición sistémica que cuantifica la extensión del riesgo.
Los sistemas de inteligencia artificial evolucionan constantemente
A medida que aparecen nuevos modelos, las aplicaciones de inteligencia artificial que los utilizan se actualizan con regularidad. Por ejemplo, los desarrolladores pueden actualizar un LLM o un metaprompt de una aplicación habilitada para IA (también conocido como mensaje del sistema). Los metaprompts proporcionan las instrucciones subyacentes al modelo de lenguaje subyacente. El cambio del metaprompt provoca cambios en la forma en de responder del modelo, lo que hace que los ejercicio del “red team“ tengan que volver a realizarse. Dado que las respuestas de los LLM son más probabilísticas que deterministas, los resultados de los cambios no pueden predecirse y sólo pueden comprenderse realmente mediante pruebas. Los “red teams“ de IA deben realizar una medida y pruebas sistemáticas automatizadas y supervisar los sistemas habilitados para IA a lo largo del tiempo.
La mitigación de los errores de la inteligencia artificial requiere una defensa en profundidad
El “red teaming“ de la inteligencia artificial requiere un enfoque de defensa en profundidad. La defensa en profundidad requiere la aplicación de varios controles de seguridad, cada uno de los cuales mitiga una estrategia adversaria diferente. Con las aplicaciones habilitadas para IA que pueden implicar el uso de clasificadores para marcar contenido potencialmente dañino para el uso de metaprompt. Mediante la implementación de clasificadores, es posible guiar el comportamiento o las aplicaciones habilitadas para IA y limitar el desfase conversacional en escenarios interactivos.