Uso de Microsoft Defender XDR en un centro de operaciones de seguridad (SOC)
En el gráfico siguiente, se proporciona información general sobre cómo se integran Microsoft Defender XDR y Microsoft Sentinel en un centro de operaciones de seguridad (SOC) moderno.

Modelo de operaciones de seguridad: funciones y herramientas
Si bien la asignación de responsabilidades a equipos y personas individuales varía en función del tamaño de la organización y otros factores, las operaciones de seguridad constan de varias funciones distintas. Cada función o equipo tiene un área de enfoque principal y también debe colaborar estrechamente con otras funciones y equipos externos para que sean eficaces. En este diagrama, se muestra todo el modelo con equipos completos. En organizaciones más pequeñas, estas funciones se combinan a menudo en un solo rol o equipo, en operaciones de TI (para roles técnicos) o como una función temporal por parte de los líderes o delegados (para la administración de incidentes).
Nota
Nos referimos principalmente a los analistas por el nombre del equipo, no por los números de nivel, ya que cada uno de estos equipos tiene aptitudes especializadas únicas y no son una clasificación literal o jerárquica de valor.
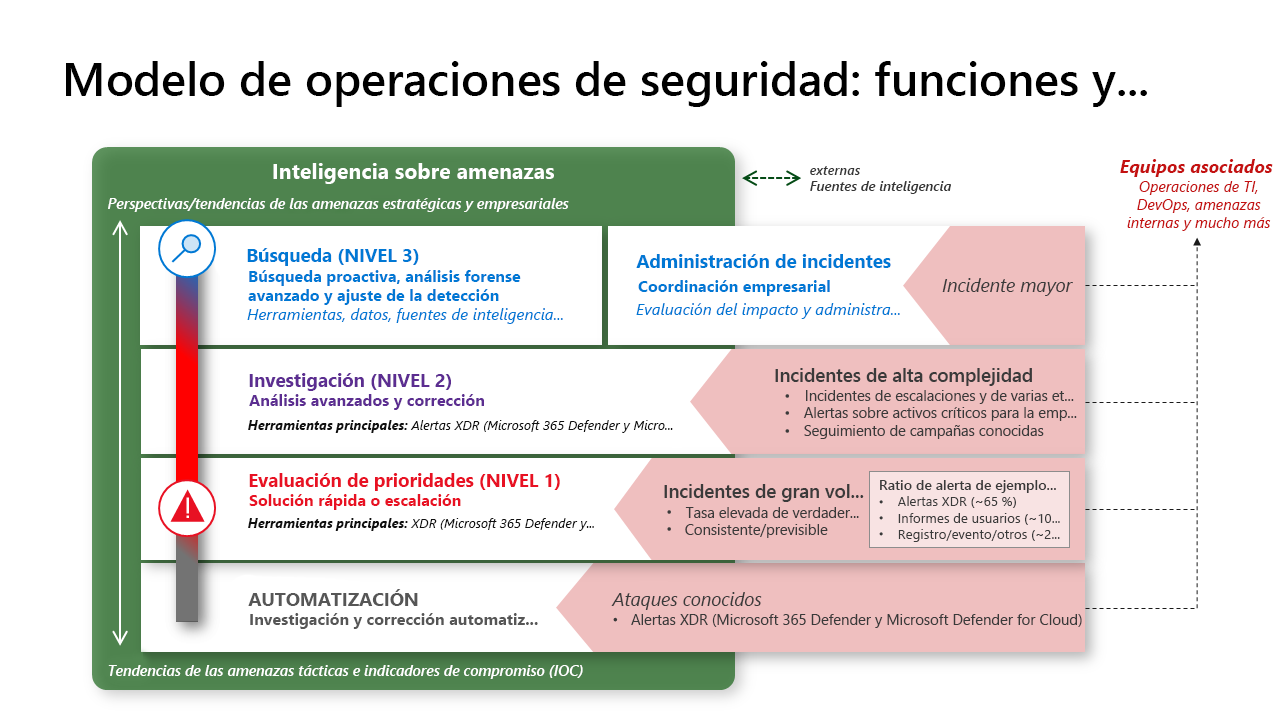
Evaluación de prioridades y automatización
Empezaremos con el control de alertas reactivas, el que comienza con:
Automatización: resolución de tipos de incidentes conocidos casi en tiempo real con automatización. Se trata de ataques bien definidos que la organización ha visto muchas veces.
Evaluación de prioridades (también conocido como "nivel 1"): los analistas de la evaluación de prioridades se centran en corregir rápidamente un gran volumen de tipos de incidentes conocidos que todavía requieren juicio humano (rápido). Por lo general, están a cargo de aprobar los flujos de trabajo de corrección automatizados y la identificación de cualquier aspecto anómalo o interesante que justifique escalar o consultar a equipos de investigación (nivel 2).
Aprendizajes clave para la evaluación de prioridades y la automatización:
- 90 % de verdaderos positivos: recomendamos establecer un estándar de calidad del 90 % de verdaderos positivos para cualquier fuente de alertas que requiera la respuesta de un analista, para que así no sea necesario que los analistas tengan que responder a un gran volumen de alarmas falsas.
- Tasa de alertas: según la experiencia de Microsoft a partir del Centro de operaciones de ciberdefensa, las alertas XDR generan la mayoría de las alertas de alta calidad, mientras que el resto de las alertas provienen de problemas informados por los usuarios, alertas basadas en consultas de registro clásicas y otros orígenes.
- La automatización es un factor clave para los equipos de evaluación de prioridades, ya que ayuda a capacitar a estos analistas y a reducir la carga del trabajo manual (por ejemplo, proporcionar una investigación automatizada y, luego, solicitar una revisión humana antes de aprobar la secuencia de corrección que se creó automáticamente para este incidente).
- Integración de herramientas: una de las tecnologías de ahorro de tiempo más eficaces que mejoró el tiempo de corrección en el CDOC de Microsoft fue la integración de las herramientas XDR en Microsoft Defender XDR a fin de que los analistas tuvieran una única consola para punto de conexión, correo electrónico, identidad, etc. Esta integración permite a los analistas detectar y eliminar rápidamente los correos electrónicos de suplantación de identidad (phishing) del atacante, el malware y las cuentas en peligro antes de que puedan hacer daños significativos.
- Enfoque: estos equipos no pueden mantener su alta velocidad de resolución para todos los tipos de tecnologías y escenarios, por lo que mantienen un enfoque limitado en ciertas áreas o escenarios técnicos. A menudo, esto se refiere a la productividad del usuario, como el correo electrónico, las alertas de AV de punto de conexión (en comparación con EDR que pasa por investigaciones) y la primera respuesta de los informes de usuario.
Investigación y administración de incidentes (nivel 2)
Este equipo actúa como punto de escalación de problemas de Evaluación de prioridades (nivel 1) y supervisa directamente las alertas que indican un atacante más sofisticado. Alertas específicas que desencadenan alertas de comportamiento, alertas de casos especiales relacionadas con recursos críticos para la empresa y supervisión de campañas de ataque en curso. De manera proactiva, este equipo también revisa periódicamente la cola de alertas del equipo de evaluación de prioridades y, en su tiempo libre, puede realizar búsqueda con herramientas XDR.
Este equipo brinda una investigación más profunda sobre un volumen menor de ataques más complejos, a menudo ataques en varias fases llevados a cabo por atacantes humanos. Este equipo pone a prueba tipos de alertas nuevos o desconocidos para documentar procesos del equipo de evaluación de prioridades y la automatización, a menudo incluidas las alertas que genera Microsoft Defender for Cloud en bases de datos SQL, contenedores y Kubernetes, máquinas virtuales y aplicaciones que se hospedan en la nube, entre otros.
Administración de incidentes: este equipo se encarga de los aspectos no técnicos de la administración de incidentes, incluida la coordinación con otros equipos, como el equipo de comunicaciones, el legal, el de liderazgo y otras partes interesadas de la empresa.
Búsqueda y administración de incidentes (nivel 3)
Se trata de un equipo multidisciplinario centrado en identificar a los atacantes que puedan haber burlado las detecciones reactivas y controlar los eventos importantes que afectan al negocio.
- Búsqueda: de manera proactiva, este equipo realiza búsquedas de amenazas no detectadas, ayuda con escalaciones y el análisis forense avanzado en investigaciones reactivas y mejora las alertas y la automatización. Estos equipos operan más en un modelo basado en hipótesis que en un modelo de alerta reactivo y también donde los equipos rojo o púrpura se conectan con las operaciones de seguridad.
Cómo se conjuga todo
Para darle una idea de cómo funciona todo esto, veamos el ciclo de vida de un incidente común.
- El analista de evaluación de prioridades (nivel 1) reclama una alerta de malware proveniente de la cola y la investiga (por ejemplo, con la consola de Microsoft Defender XDR).
- Si bien la mayoría de los casos del nivel de evaluación de prioridades se corrigen y cierran rápidamente, en esta oportunidad el analista observa que el malware puede requerir una corrección más comprometida o avanzada (por ejemplo, aislamiento y limpieza del dispositivo). La evaluación de prioridades escala el caso al analista de Investigación (nivel 2), que lidera la investigación. El equipo de evaluación de prioridades puede seguir participando y obteniendo más información (el equipo de investigación puede usar Microsoft Sentinel u otro SIEM para un contexto más amplio)
- La investigación comprueba las conclusiones de la investigación (o profundiza aún más) y pasa a la corrección a fin de cerrar el caso.
- Posteriormente, en la Búsqueda (nivel 3), se puede observar este caso mientras se revisan los incidentes cerrados para examinar si existen semejanzas o anomalías en las que vale la pena profundizar:
- Las detecciones pueden ser aptas para la corrección automática
- Varios incidentes similares que pueden tener una causa principal común
- Otras posibles mejoras de proceso, herramienta o alerta En un caso, el nivel 3 revisó el caso y encontró que el usuario había sido víctima de una estafa tecnológica. En ese momento, esta detección se marcó como una alerta de prioridad potencialmente más alta porque los estafadores habían logrado obtener acceso de nivel de administrador en el punto de conexión. Una exposición de riesgo mayor.
Información sobre amenazas
Los equipos de inteligencia sobre amenazas proporcionan contexto e información para admitir todas las demás funciones (con una plataforma de inteligencia sobre amenazas [TIP] en las organizaciones más grandes). Esto podría incluir diversas facetas, entre ellas:
- Investigación técnica reactiva para incidentes activos
- Investigación técnica proactiva sobre grupos de atacantes, tendencias de ataque, ataques de alto perfil y técnicas emergentes, entre otros.
- Análisis estratégico, investigación y otras conclusiones para fundamentar los procesos y prioridades empresariales y técnicos.
- Y mucho más