Optimización del rendimiento de una solución de Búsqueda de Azure AI
El rendimiento de las soluciones de búsqueda puede verse afectado por el tamaño y la complejidad de los índices. Debe saber cómo escribir consultas eficaces para buscarlas y elegir el nivel de servicio adecuado.
Aquí explorará todas estas dimensiones y verá los pasos que puede seguir para mejorar el rendimiento de la solución de búsqueda.
Medición del rendimiento actual de la búsqueda
Si no conoce el nivel de rendimiento del servicio de búsqueda, no podrá optimizarlo. Cree una prueba comparativa de rendimiento de línea base para poder validar las mejoras que realice, aunque también puede comprobar si hay alguna degradación en el rendimiento a lo largo del tiempo.
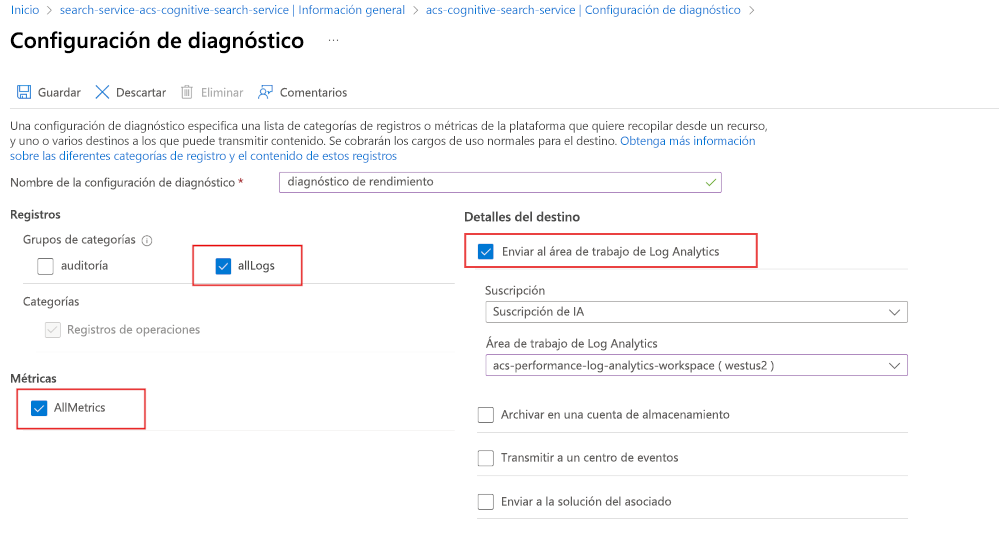
Para empezar, habilite el registro de diagnóstico mediante Log Analytics:
- En el Portal de Azure, seleccione Configuración de diagnóstico.
- Seleccione + Agregar configuración de diagnóstico.

- Asigne un nombre a la configuración de diagnóstico.
- Seleccione allLogs y AllMetrics.
- Seleccione Enviar al área de trabajo de Log Analytics.
- Elija o cree el área de trabajo de Log Analytics.
Es importante capturar esta información de diagnóstico en el nivel de servicio de búsqueda, ya que hay varios puntos en los que los usuarios finales o las aplicaciones pueden ver problemas de rendimiento.

Si puede demostrar que el servicio de búsqueda funciona bien, puede descartarlo como causa posible de los problemas de rendimiento.
Comprobación de que el servicio de búsqueda está o no limitado
Las búsquedas y los índices de Búsqueda de Azure AI se pueden limitar. Si las búsquedas de los usuarios o las aplicaciones están limitadas, se captura en Log Analytics con una respuesta HTTP 503. Si los índices se están limitando, se mostrarán como respuestas HTTP 207.
Esta consulta que puede ejecutar en los registros del servicio de búsqueda muestra si el servicio de búsqueda se está limitando.

En el Portal de Azure, en Supervisión, seleccione Registros. En la pestaña Nueva consulta 1, se usaría esta consulta:
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
Se ejecutaría el comando para ver un gráfico de barras de las respuestas HTTP de los servicios de búsqueda. En el ejemplo anterior puede ver que ha habido varias respuestas 503.
Comprobación del rendimiento de las consultas individuales
La mejor manera de probar el rendimiento de las consultas individuales es con una herramienta cliente como Postman. Puede usar cualquier herramienta que le muestre los encabezados en la respuesta a una consulta. Búsqueda de Azure AI siempre devolverá un valor "tiempo transcurrido" igual al tiempo que ha tardado el servicio en completar la consulta.

Si desea saber cuánto tiempo tardaría en enviar la consulta y, a continuación, recibir la respuesta del cliente, reste el tiempo transcurrido al recorrido de ida y vuelta total. En el ejemplo anterior, eso sería de 125 ms - 21 ms, lo que resulta en 104 ms.
Optimización del tamaño y el esquema del índice
El rendimiento de las consultas de búsqueda está directamente relacionado con el tamaño y la complejidad de los índices. Cuanto más pequeños y optimizados sean los índices, más rápido responderá Búsqueda de Azure AI a las consultas. Le ofrecemos algunas sugerencias que pueden ayudar si tiene problemas de rendimiento en consultas individuales.
Si no presta atención, los índices pueden crecer con el tiempo. Debe revisar si todos los documentos del índice siguen siendo relevantes y si sigue siendo necesario poder buscarlos.
Si no puede quitar ningún documento, ¿puede reducir la complejidad del esquema? ¿Todavía necesita que se puedan buscar los mismos campos? ¿Todavía necesita todos los conjuntos de aptitudes con los que inició el índice?

Considere la posibilidad de revisar todos los atributos que ha habilitado en cada campo. Por ejemplo, agregar compatibilidad con filtros, facetas y ordenación puede cuadruplicar el almacenamiento necesario para admitir el índice.
Nota
Tener demasiados atributos en un campo limita sus funcionalidades. Por ejemplo, sólo puede almacenar 16 KB en un campo al que se pueden aplicar facetas y filtros y que se pueda buscar. Mientras que un campo que se puede buscar puede contener hasta 16 MB de texto.
Si el índice se ha optimizado, pero el rendimiento todavía no es el que debe ser, puede optar por escalar o escalar horizontalmente el servicio de búsqueda.
Mejora del rendimiento de las consultas
Si sabe cómo funciona el servicio de búsqueda, puede ajustar las consultas para mejorar drásticamente el rendimiento. Use esta lista de comprobación para escribir mejores consultas:
- Especifique sólo los campos que necesita buscar mediante el parámetro searchFields, ya que cuantos más campos hay, más procesamiento adicional se requiere.
- Devuelva el número más pequeño de campos que debe representar en la página de resultados de búsqueda; devolver más datos dura más tiempo.
- Intente evitar términos de búsqueda parciales, como la búsqueda de prefijos o expresiones regulares. Estos tipos de búsquedas son más costosos a nivel computacional.
- Evite usar valores de omisión elevados. Esto obliga al motor de búsqueda a recuperar y clasificar volúmenes más grandes de datos.
- Limite el uso de campos a los que se pueden aplicar filtros y facetas a datos de cardinalidad baja.
- En los criterios de filtro, use funciones de búsqueda en lugar de valores individuales. Por ejemplo, puede llamar a
search.in(userid, '123,143,563,121',',')en vez de a$filter=userid eq 123 or userid eq 143 or userid eq 563 or userid eq 121.
Si ha aplicado todo lo anterior y sigue habiendo consultas individuales que no se realizan, puede escalar horizontalmente el índice. En función del nivel de servicio que haya usado para crear la solución de búsqueda, puede agregar hasta 12 particiones. Las particiones son el almacenamiento físico donde reside el índice. De forma predeterminada, todos los índices de búsqueda nuevos se crean con una sola partición. Si agrega más particiones, el índice se almacena en ellas. Por ejemplo, si el índice es de 200 GB y tiene cuatro particiones, cada partición contiene 50 GB del índice.
Agregar particiones adicionales puede ayudar con el rendimiento, ya que el motor de búsqueda se puede ejecutar en paralelo en cada partición. Las mejoras se ven en las consultas que devuelven un gran número de documentos y en las consultas que usan facetas que proporcionan recuentos en un gran número de documentos. Este es un factor del coste computacional de puntuar la relevancia de los documentos.
Uso del mejor nivel de servicio para sus necesidades de búsqueda
Ha visto que puede escalar horizontalmente los niveles de servicio agregando más particiones. Puede escalar horizontalmente con réplicas si necesita escalar debido a un aumento de la carga. También puede escalar verticalmente el servicio de búsqueda mediante un nivel superior.

Los dos índices de búsqueda anteriores tienen un tamaño de 200 GB. El nivel S1 usa ocho particiones y el nivel S2 solo tiene dos. Ambos tienen dos réplicas, y ambos cuestan aproximadamente lo mismo. La elección del mejor nivel para la solución de búsqueda requiere que sepa el tamaño total aproximado del almacenamiento que va a necesitar. El índice más grande admitido actualmente es 12 particiones en el nivel L2, que ofrece un total de 24 TB.
| Nivel | Tipo | Almacenamiento | Réplicas | Particiones |
|---|---|---|---|---|
| F | Gratuito | 50 MB | 1 | 1 |
| B | Básico | 2 GB | 3 | 1 |
| S1 | Estándar | 25 GB por partición | 12 | 12 |
| S2 | Estándar | 100 GB por partición | 12 | 12 |
| S3 | Estándar | 200 GB por partición | 12 | 12 |
| S3HD | Alta densidad | 200 GB por partición | 12 | 3 |
| L1 | Optimizada para almacenamiento | 1 TB por partición | 12 | 12 |
| L2 | Optimizada para almacenamiento | 2 TB por partición | 12 | 12 |
¿Cuál de los dos niveles anteriores en el ejemplo anterior cree que funciona mejor? Ha visto que el escalado horizontal proporciona ventajas de rendimiento debido al paralelismo. Sin embargo, los niveles superiores también incluyen almacenamiento premium, recursos de procesamiento más eficaces y memoria adicional. La elección de la segunda opción proporciona una infraestructura más eficaz y permite un crecimiento futuro del índice. Desafortunadamente, el nivel que mejor funciona depende del tamaño y la complejidad del índice y de las consultas que escriba para buscarlo. Así que cualquiera de los dos podría ser el mejor.
Planear el crecimiento futuro en el uso de la solución de búsqueda significa que debe considerar las unidades de búsqueda. Una unidad de búsqueda (SU) es el producto de réplicas y particiones. Esto significa que el nivel S1 anterior usa 16 SU y el nivel S2, solo 4 SU. Los costos son similares a los niveles superiores que cobran más por SU.
Piense en la necesidad de escalar la solución de búsqueda debido al aumento de la carga. Agregar otra réplica a ambos niveles aumenta el nivel S1 a 24 SU, pero el nivel S2 solo aumenta a 6 SU.