Integración e implementación continuas
La integración continua es el procedimiento de probar cada cambio realizado en el código base automáticamente y tan pronto como sea posible. La entrega continua sigue las pruebas realizadas durante la integración continua y envía los cambios a un sistema de ensayo o producción.
En Azure Data Factory, la integración y la entrega continuas (CI/CD) implican el traslado de canalizaciones de Data Factory de un entorno (desarrollo, prueba o producción) a otro. Azure Data Factory usa las plantillas de Azure Resource Manager para almacenar la configuración de las distintas entidades de Azure Data Factory (canalizaciones, conjuntos de datos, flujos de datos, etc.). Se sugieren dos métodos para promover una factoría de datos a otro entorno:
- Implementación automatizada mediante la integración de Data Factory con Azure Pipelines.
- Carga manual de una plantilla de Resource Manager mediante la integración de la experiencia de usuario de Data Factory con Azure Resource Manager.
Ciclo de vida de la integración y entrega continuas
Aquí se muestra una descripción general de ejemplo del ciclo de vida de CI/CD en una factoría de datos de Azure configurada con Git de Azure Repos.
Se crea una factoría de datos de desarrollo y se configura con GIT de Azure Repos. Todos los desarrolladores deben tener permiso para crear recursos de Data Factory como canalizaciones y conjuntos de usuarios.
Un desarrollador crea una rama de características para realizar un cambio. Depuran sus ejecuciones de canalización con los cambios más recientes.
Cuando un desarrollador está satisfecho con los cambios, crea una solicitud de incorporación de cambios desde su rama de características a la rama maestra o rama de colaboración para que otros equipos del mismo nivel revisen sus cambios.
Después de que la solicitud de incorporación de cambios se haya aprobado y los cambios se hayan combinado en la rama maestra, los cambios se publican en la fábrica de desarrollo.
Cuando el equipo está listo para implementar los cambios en una fábrica UAT (pruebas de aceptación de usuario), se dirige a su versión de Azure Pipelines e implementa la versión deseada de la fábrica de desarrollo en UAT. Esta implementación tiene lugar como parte de una tarea de Azure Pipelines y usa los parámetros de plantilla de Resource Manager para aplicar la configuración adecuada.
Una vez comprobados los cambios en la fábrica de pruebas, realice la implementación en la fábrica de producción mediante la siguiente tarea de versión de canalizaciones.
Nota
Solo la fábrica de desarrollo está asociada a un repositorio de Git. Las fábricas de pruebas y producción no deben tener un repositorio de Git asociado y solo deben actualizarse a través de una canalización de Azure DevOps o de una plantilla de Resource Manager.
En la imagen siguiente se resaltan los distintos pasos de este ciclo de vida.
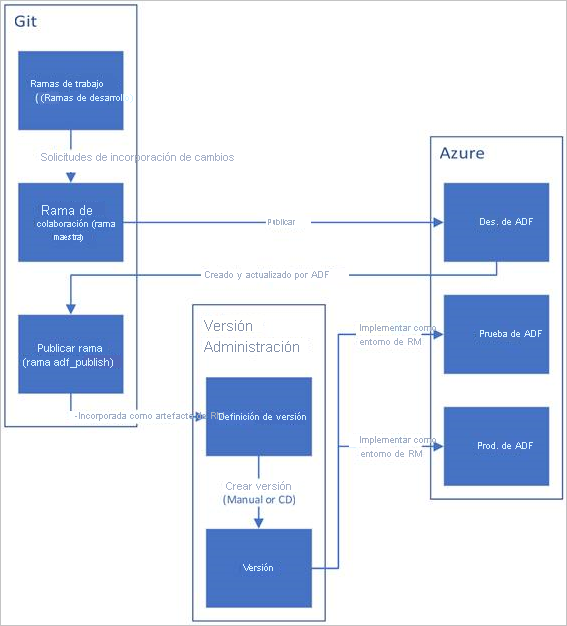
Automatización de la integración continua mediante versiones de Azure Pipelines
A continuación se ofrece una guía para configurar una versión de Azure Pipelines, que automatiza la implementación de una factoría de datos en varios entornos.
Requisitos
Una suscripción a Azure vinculada a Visual Studio Team Foundation Server o Azure Repos que use el punto de conexión de servicio de Azure Resource Manager.
Una factoría de datos configurada con la integración de GIT de Azure Repos.
Un almacén de claves de Azure que contenga los secretos para cada entorno.
Configuración de una versión de Azure Pipelines
En Azure DevOps, abra el proyecto configurado con la factoría de datos.
En el lado izquierdo de la página, seleccione Canalizaciones y después Versiones.
Seleccione Nueva canalización o, si tiene canalizaciones existentes, seleccione Nueva y, luego Nueva canalización de versión.
Seleccione la plantilla Fase vacía.
En el cuadro Nombre de la fase, escriba el nombre del entorno.
Seleccione Agregar artefacto y después el mismo repositorio de Git configurado con la factoría de datos de desarrollo. Seleccione la rama de publicación del repositorio en Rama predeterminada. De forma predeterminada, esta rama de publicación es
adf_publish. En Versión predeterminada, seleccione Más reciente de la rama predeterminada.
Añada una tarea de implementación de Azure Resource Manager:
a. En la vista de fase, seleccione Ver tareas de la fase.
b. Cree una nueva tarea. Busque Implementación de una plantilla de Resource Manager y, después, seleccione Agregar.
c. En la tarea de implementación, seleccione la suscripción, el grupo de recursos y la ubicación de la factoría de datos de destino. Proporcione las credenciales si es necesario.
d. En la lista Acción, seleccione Create or update resource group (Crear o actualizar grupo de recursos).
e. Seleccione el botón de puntos suspensivos ( ... ) situado junto al cuadro Plantilla. Busque la plantilla de Azure Resource Manager que se ha generado en la rama de publicación del repositorio de Git configurado. Busque el archivo
ARMTemplateForFactory.jsonen la carpeta<FactoryName>de la rama adf_publish.f. Seleccione … junto al cuadro Parámetros de plantilla para elegir el archivo de parámetros. Busque el archivo
ARMTemplateParametersForFactory.jsonen la carpeta<FactoryName>de la rama adf_publish.g. Seleccione … junto al cuadro Reemplazar parámetros de plantilla y escriba los valores de los parámetros deseados de la factoría de datos de destino. En el caso de las credenciales que proceden de Azure Key Vault, escriba el nombre del secreto entre comillas dobles. Por ejemplo, si el nombre del secreto es cred1, escriba "$(cred1)" para este valor.
h. Seleccione Incremental para el Modo de implementación.
Advertencia
En el modo de implementación completa, se eliminarán aquellos recursos que existan en el grupo de recursos, pero no estén especificados en la nueva plantilla de Resource Manager.

Guarde la canalización de versión.
Para desencadenar una versión, seleccione Crear versión. En Azure DevOps, esto se puede automatizar.



Importante
En escenarios de CI/CD, el tipo de entorno de ejecución de integración (IR) en otros entornos debe ser el mismo. Por ejemplo, si tiene un IR autohospedado en el entorno de desarrollo, el mismo IR también debe ser de tipo autohospedado en otros entornos, como los de prueba y producción. Del mismo modo, si va a compartir los entornos de ejecución de integración entre varias fases, tendrá que configurarlos como autohospedados vinculados en todos los entornos: desarrollo, prueba y producción.
Obtención de secretos de Azure Key Vault
Si tiene secretos para pasar en una plantilla de Azure Resource Manager, se recomienda usar Azure Key Vault con la versión de Azure Pipelines.
Hay dos formas de administrar los secretos:
Agregue los secretos al archivo de parámetros.
Cree una copia del archivo de parámetros que se ha cargado en la rama de publicación. Establezca los valores de los parámetros que quiera obtener del almacén de claves con este formato:
{ "parameters": { "azureSqlReportingDbPassword": { "reference": { "keyVault": { "id": "/subscriptions/<subId>/resourceGroups/<resourcegroupId> /providers/Microsoft.KeyVault/vaults/<vault-name> " }, "secretName": " < secret - name > " } } } }Al utilizar este método, el secreto se extrae automáticamente del almacén de claves.
El archivo de parámetros también debe estar en la rama de publicación.
Agregue una tarea de Azure Key Vault antes de la tarea de implementación de Azure Resource Manager que se ha descrito en la sección anterior:
En la pestaña Tareas, cree una tarea. Busque Azure Key Vault y agréguelo.
En la tarea de Key Vault, seleccione la suscripción en la que haya creado el almacén de claves. Proporcione credenciales si es necesario y, después, seleccione el almacén de claves.


Concesión de permisos al agente de Azure Pipelines
Es posible que se produzca un error de acceso denegado en la tarea Azure Key Vault si no se han establecido los permisos correctos. Descargue los registros de la versión y busque el archivo .ps1 que contiene el comando para conceder permisos al agente de Azure Pipelines. Puede ejecutar el comando directamente. O bien, puede copiar el identificador de entidad de seguridad del archivo y añadir la directiva de acceso manualmente en Azure Portal. Get y List son los permisos mínimos necesarios.
Actualización de desencadenadores activos
Puede producirse un error en la implementación si intenta actualizar desencadenadores activos. Para actualizar desencadenadores activos, debe detenerlos manualmente e iniciarlos después de la implementación. Puede hacerlo mediante una tarea de Azure PowerShell:
En la pestaña Tareas de la versión, agregue una tarea Azure PowerShell. Elija la versión de la tarea 4.*.
Seleccione la suscripción en la que se encuentra la factoría.
Seleccione Ruta de acceso del archivo de script como tipo de script. Esto requiere guardar el script de PowerShell en el repositorio. El siguiente script de PowerShell sirve para detener desencadenadores:
$triggersADF = Get-AzDataFactoryV2Trigger -DataFactoryName $DataFactoryName -ResourceGroupName $ResourceGroupName $triggersADF | ForEach-Object { Stop-AzDataFactoryV2Trigger -ResourceGroupName $ResourceGroupName -DataFactoryName $DataFactoryName -Name $_.name -Force }
Puede completar pasos similares (con la función Start-AzDataFactoryV2Trigger) para reiniciar los desencadenadores después de la implementación.
Nota:
Estos pasos ya están incluidos en los scripts anteriores y posteriores a la implementación que proporciona el equipo de Azure Data Factory.
Promoción manual de una plantilla de Resource Manager para cada entorno
Si no puede usar Azure DevOps u otra herramienta de administración de versiones, puede promover manualmente una factoría de datos mediante una plantilla de ARM.
En la lista Plantilla de ARM, seleccione Export ARM Template (Exportar plantilla de ARM) para exportar la plantilla de Resource Manager de la factoría de datos en el entorno de desarrollo.

En las factorías de datos de prueba y de producción, seleccione Import ARM Template (Importar plantilla de ARM). Esta acción abrirá Azure Portal, donde puede importar la plantilla exportada. Seleccione Cree su propia plantilla en el editor para abrir el editor de plantillas de Resource Manager.
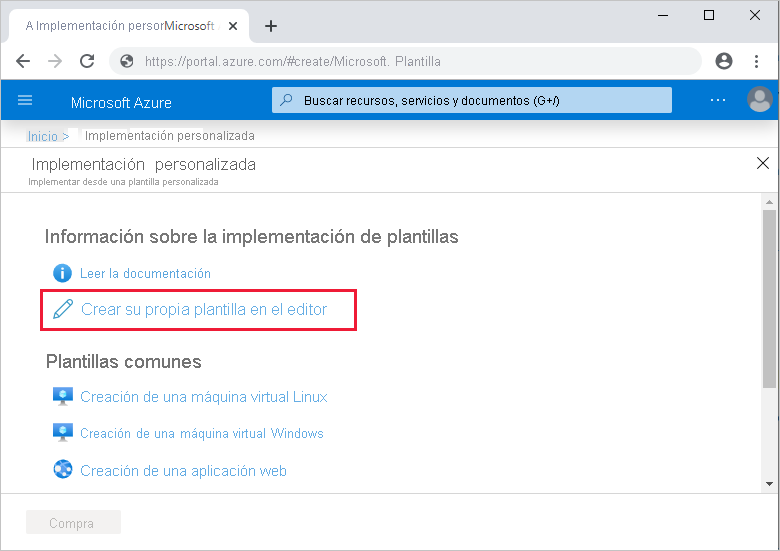
Seleccione Cargar archivo y después la plantilla de Resource Manager generada. Este es el archivo arm_template.json que se encuentra en el archivo ZIP exportado en el paso 1.
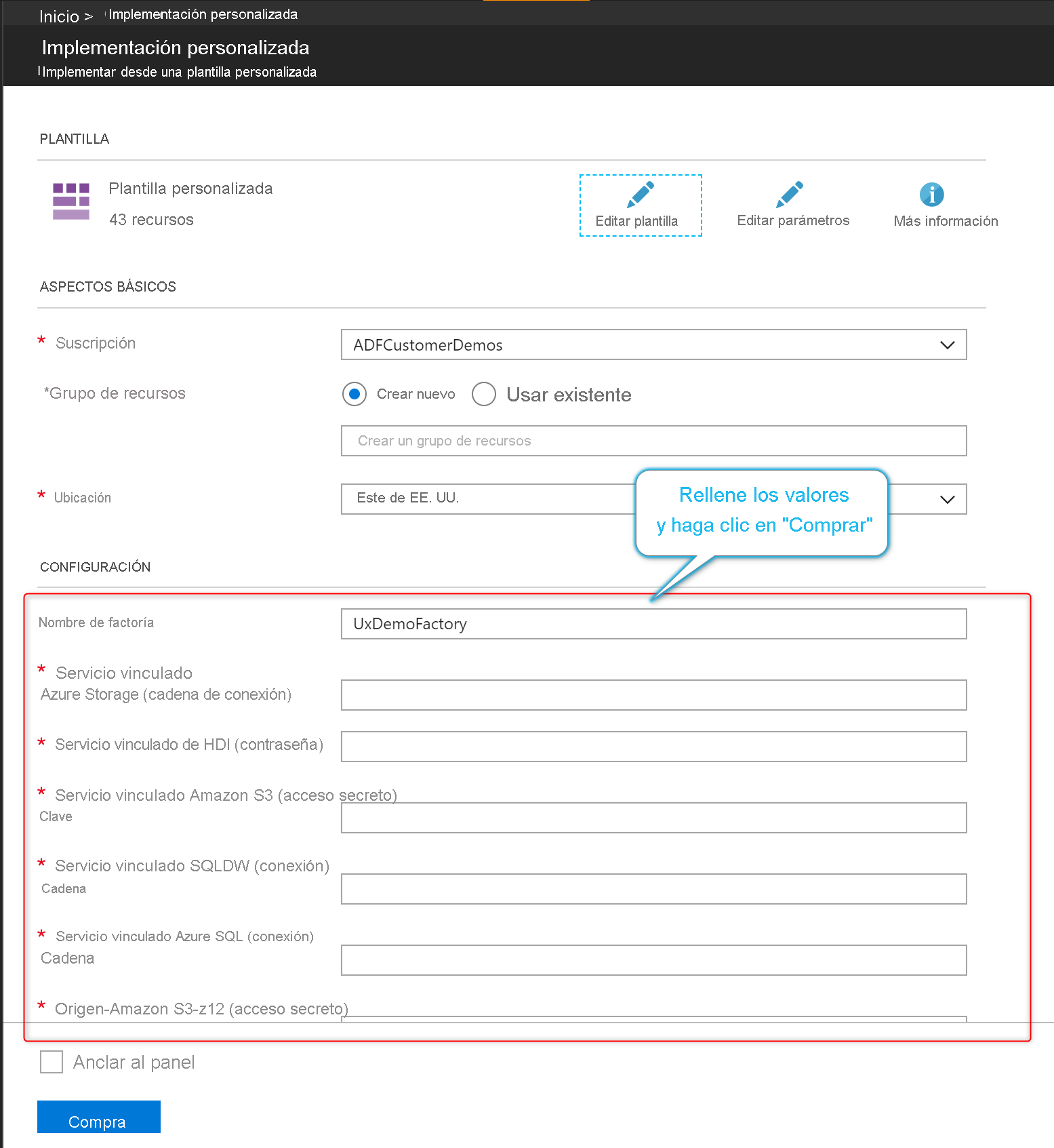
En la sección de configuración, escriba los valores de configuración, como las credenciales del servicio vinculado. Cuando haya terminado, seleccione Comprar para implementar la plantilla de Resource Manager.
Personalización de los parámetros de plantillas de Azure Resource Manager
Si la fábrica de desarrollo tiene un repositorio de Git asociado, puede invalidar los parámetros de plantilla de Resource Manager predeterminados de la plantilla de Resource Manager que se genera mediante la publicación o exportación de la plantilla. Es posible que desee reemplazar la plantilla de parametrización predeterminada en estos escenarios:
- Se usa CI/CD automatizada y se quieren cambiar algunas propiedades durante la implementación de Resource Manager, pero las propiedades no están parametrizadas de forma predeterminada.
- La fábrica es tan grande que la plantilla de Resource Manager predeterminada no es válida porque contiene más parámetros que el número máximo permitido (256).
Para invalidar la plantilla de parametrización predeterminada, vaya al centro de administración y seleccione Plantilla de parametrización en la sección de control de código fuente. Seleccione Editar plantilla para abrir el editor de código de la plantilla de parametrización.
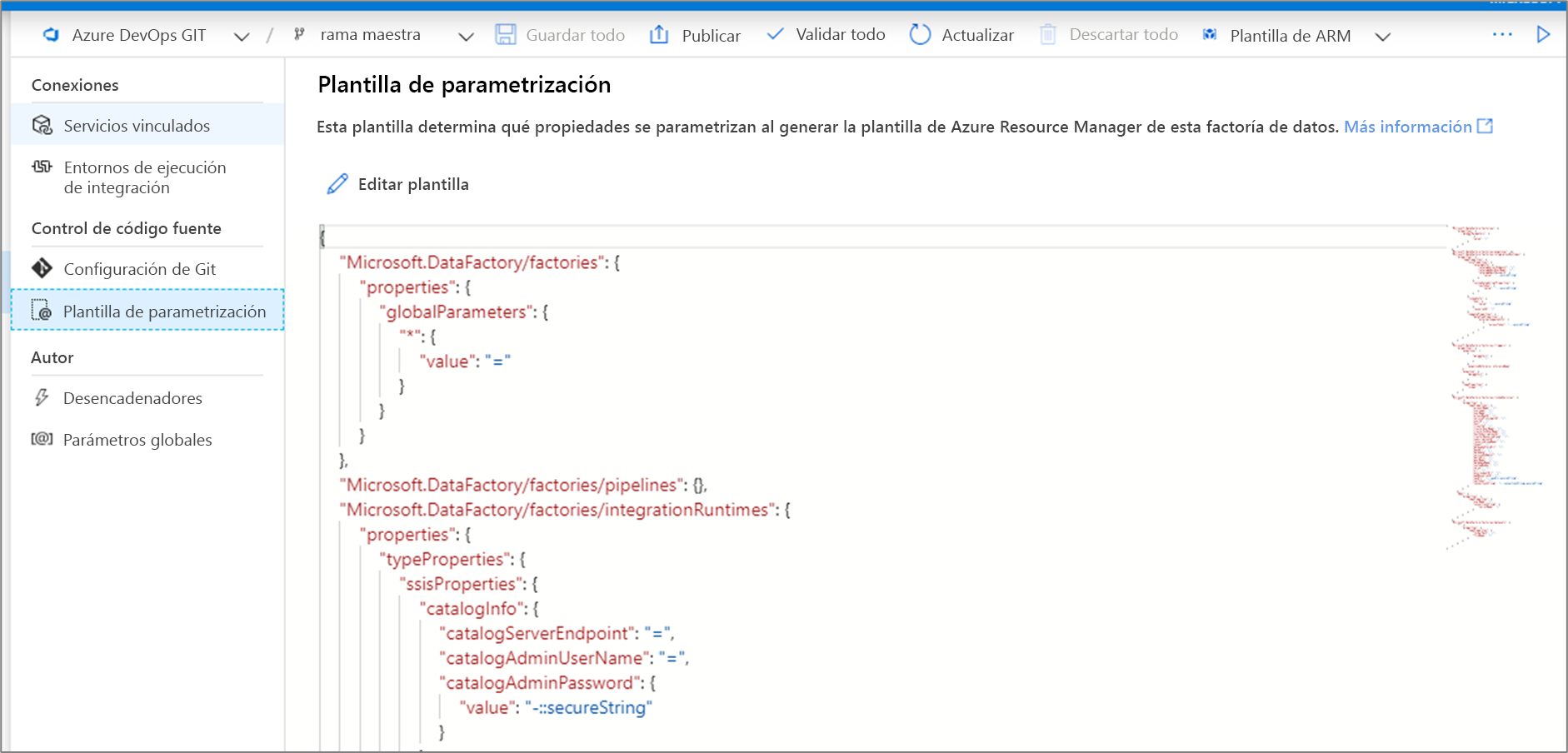
Al crear una plantilla de parametrización personalizada se crea un archivo denominado arm-template-parameters-definition.json en la carpeta raíz de la rama de Git. Debe usar ese nombre de archivo exacto.
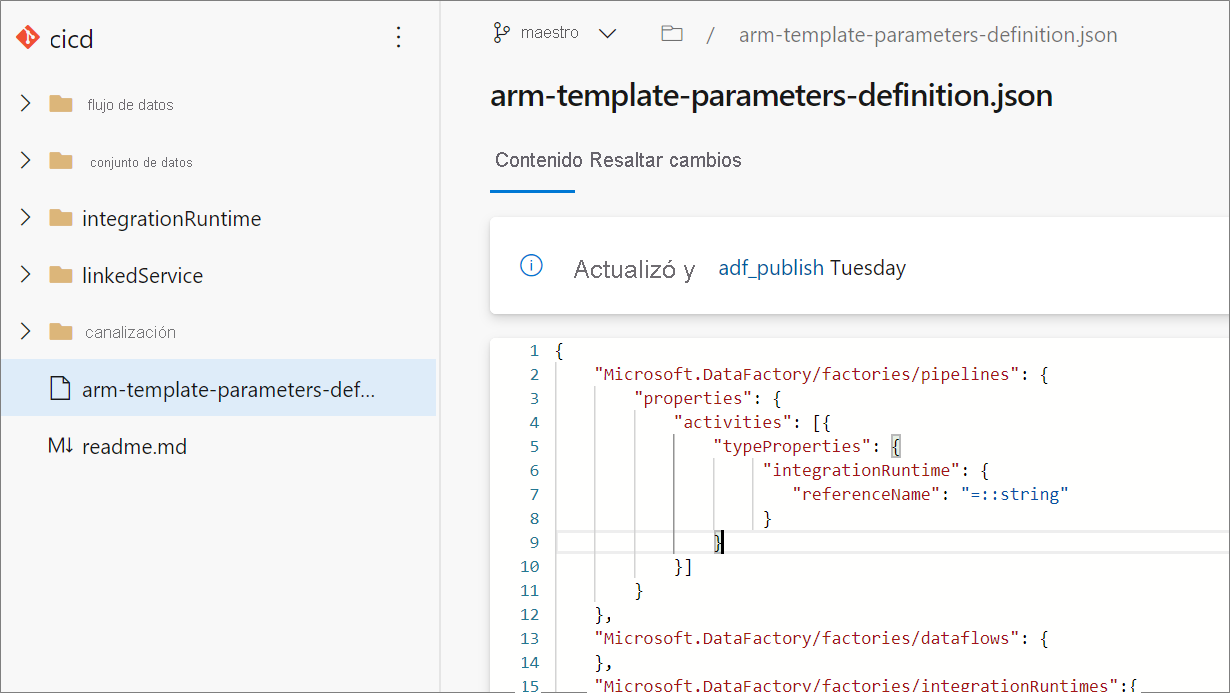
Al realizar la publicación desde la rama de colaboración, Data Factory leerá este archivo y usará su configuración para generar las propiedades que se parametrizarán. Si no se encuentra ningún archivo, se usa la plantilla predeterminada.
Al exportar una plantilla de Resource Manager, Data Factory lee este archivo desde la rama en la que se está trabajando en ese momento, no la rama de colaboración. Puede crear o editar el archivo desde una rama privada, donde pueda probar los cambios si selecciona Export ARM Template (Exportar plantilla de ARM) en la interfaz de usuario. Después, puede combinar el archivo en la rama de colaboración.
Nota
Una plantilla de parametrización personalizada no cambia el límite de 256 parámetros de plantilla de Resource Manager. Le permite elegir y reducir el número de propiedades parametrizadas.
Sintaxis de los parámetros personalizados
A continuación se indican algunas de las instrucciones que se deben seguir para crear el archivo de parámetros personalizados, arm-template-parameters-definition.json. El archivo consta de una sección para cada tipo de entidad: desencadenador, canalización, servicio vinculado, conjunto de datos, entorno de ejecución de integración i flujo de datos.
- Escriba la ruta de acceso de la propiedad en el tipo de entidad correspondiente.
- El establecimiento de un nombre de propiedad en
*indica que quiere parametrizar todas las propiedades que incluye (solo hasta el primer nivel, no de forma recursiva). También puede proporcionar excepciones a esta configuración. - El establecimiento del valor de una propiedad como una cadena indica que quiere parametrizar la propiedad. Use el formato
<action>:<name>:<stype>.<action>puede ser uno de estos caracteres:=significa que el valor actual se debe conservar como el predeterminado para el parámetro.-significa que no se debe conservar el valor predeterminado para el parámetro.|es un caso especial para los secretos de Azure Key Vault para cadenas de conexión o claves.
<name>es el nombre del parámetro. Si está en blanco, toma el nombre de la propiedad. Si el valor empieza por un carácter-, el nombre está abreviado. Por ejemplo,AzureStorage1_properties_typeProperties_connectionStringse abreviará aAzureStorage1_connectionString.<stype>es el tipo del parámetro. Si<stype>está en blanco, el tipo predeterminado esstring. Los valores admitidos son:string,bool,number,objectysecurestring.
- Al especificar una matriz en el archivo de definición indica que la propiedad coincidente en la plantilla es una matriz. Data Factory recorre en iteración todos los objetos de la matriz mediante la definición especificada en el objeto del entorno de ejecución de integración de la matriz. El segundo objeto, una cadena, se convierte en el nombre de la propiedad, que se utiliza como el nombre del parámetro para cada iteración.
- Una definición no puede ser específica de una instancia de recurso. Cualquier definición se aplica a todos los recursos de ese tipo.
- De forma predeterminada, todas las cadenas seguras, como los secretos de Key Vault, las cadenas de conexión, las claves y los tokens, están parametrizadas.
Plantillas vinculadas
Si ha configurado CI/CD para las factorías de datos, es posible que supere los límites de plantilla de Azure Resource Manager a medida que la fábrica aumente de tamaño. Por ejemplo, un límite es el número máximo de recursos de una plantilla de Resource Manager. Para acomodar factorías más grandes mientras se genera la plantilla completa de Resource Manager para una factoría, ahora Data Factory genera plantillas de Resource Manager vinculadas. Con esta característica, la carga de la factoría completa se divide en varios archivos, para que no esté restringido por los límites.
Si ha configurado Git, se generan las plantillas vinculadas y se guardan junto con las plantillas completas de Resource Manager en la rama adf_publish, en una carpeta nueva denominada "linkedTemplates". Normalmente, las plantillas vinculadas de Resource Manager tienen una plantilla principal y un conjunto de plantillas secundarias vinculadas a la principal. La plantilla principal se denomina ArmTemplate_master.json y las plantillas secundarias se denominan con el patrón ArmTemplate_0.json, ArmTemplate_1.json, etc.
Para usar plantillas vinculadas en lugar de la plantilla de Resource Manager completa, actualice la tarea de CI/CD para que apunte a ArmTemplate_master.json en lugar de ArmTemplateForFactory.json (la plantilla de Resource Manager completa). Resource Manager también necesita que cargue las plantillas vinculadas en una cuenta de almacenamiento para que Azure pueda acceder a ellas durante la implementación.
Entorno de producción de revisión
Si implementa una factoría en producción y se da cuenta de que hay un error que se debe corregir de inmediato, pero no puede implementar la rama de colaboración actual, es posible que deba implementar una revisión. Este enfoque se conoce como ingeniería de corrección rápida o QFE.
En Azure DevOps, vaya a la versión que se ha implementado en producción. Busque la última confirmación que se ha implementado.
En el mensaje de confirmación, obtenga el identificador de confirmación de la rama de colaboración.
Cree una rama de revisión a partir de esa confirmación.
Vaya a la experiencia de la interfaz de usuario de Azure Data Factory y cambie a la rama de revisión.
Mediante la experiencia de la interfaz de usuario de Azure Data Factory, corrija el error. Guarde los cambios.
Una vez comprobada la corrección, seleccione Export ARM Template (Exportar plantilla de ARM) para obtener la plantilla de Resource Manager de revisión.
Inserte manualmente esta compilación en la rama de publicación.
Si ha configurado la canalización de versión para que se desencadene automáticamente en función de las inserciones en el repositorio de adf_publish, se iniciará una versión nueva de forma automática. De lo contrario, ponga en cola manualmente una versión.
Implemente la versión de revisión en las factorías de prueba y producción. Esta versión contiene la carga de producción anterior más la revisión realizada en el paso 5.
Agregue los cambios de la revisión a la rama de desarrollo para que las versiones posteriores no incluyan el mismo error.
Prácticas recomendadas para la integración y entrega continuas
Si usa la integración de Git con la factoría de datos y tiene una canalización de CI/CD que mueve los cambios desde el entorno de desarrollo al de prueba y, luego, al de producción, los procedimientos recomendados son los siguientes:
Integración de Git. Configure solo la factoría de datos de desarrollo con la integración de Git. Los cambios en los entornos de prueba y producción se implementan a través de CI/CD y no se necesita la integración Git.
Script anterior y posterior a la implementación. Antes del paso de implementación de Resource Manager en CI/CD, debe completar ciertas tareas, como detener y reiniciar los desencadenadores y realizar la limpieza. Se recomienda usar scripts de PowerShell antes y después de la tarea de implementación. El equipo de Data Factory ha proporcionado un script listo para su uso, y se encuentra en la página de la documentación de CI/CD de Azure Data Factory.
Entornos de ejecución de integración y uso compartido. Los entornos de ejecución de integración no cambian a menudo y son similares en todas las fases de CI/CD. Por tanto, Data Factory espera que el usuario tenga el mismo nombre y tipo de entorno de ejecución de integración en todas las etapas de CI/CD. Si quiere compartir entornos de ejecución de integración en todas las fases, considere la posibilidad de usar una factoría ternaria solo para contener los entornos de ejecución de integración compartidos. Puede usar esta factoría compartida en todos los entornos como un tipo de entorno de ejecución de integración vinculado.
Implementación de un punto de conexión privado administrado. Si ya existe un punto de conexión privado en una fábrica y se intenta implementar una plantilla de Resource Manager que contiene un punto de conexión privado con el mismo nombre pero con propiedades modificadas, se produce un error en la implementación. Es decir, se puede implementar correctamente un punto de conexión privado siempre que tenga las mismas propiedades que el que ya existe en la fábrica. Si alguna propiedad difiere entre entornos, se puede invalidar si se parametriza esa propiedad y se proporciona el valor respectivo durante la implementación.
Key Vault. Cuando se usan servicios vinculados cuya información de conexión se almacena en Azure Key Vault, se recomienda mantener almacenes de claves independientes para entornos diferentes. También puede configurar niveles de permisos independientes para cada almacén de claves. Por ejemplo, es posible que no quiera que los miembros del equipo tengan permisos para ver los secretos de producción. Si sigue este enfoque, se recomienda mantener los mismos nombres de secreto en todas las fases. Si mantiene los mismos nombres de secreto, no es necesario parametrizar cada cadena de conexión en los entornos de CI/CD, porque lo único que cambia es el nombre del almacén de claves, que es un parámetro independiente.
Nomenclatura de los recursos. Debido a las restricciones de las plantillas de ARM, pueden surgir problemas en la implementación si los recursos contienen espacios en el nombre. Para los recursos, el equipo de Azure Data Factory recomienda usar los caracteres "_" o "-" en lugar de espacios. Por ejemplo, "Canalización_1" sería un nombre preferible en lugar de "Pipeline 1".