¿Cuándo debería usar HDInsight Interactive Query?
Como analista de negocios, necesita determinar cuál es el tipo de clúster de HDInsight más apropiado para compilar la solución. Los clústeres de Interactive Query proporcionan una serie de características y opciones de interoperabilidad que los hacen muy beneficiosos para los analistas de negocios familiarizados con SQL. Son excelentes para los usuarios que quieren trabajar con herramientas de inteligencia empresarial y que requieren consultas interactivas rápidas. Ofrecen otras ventajas, como la compatibilidad con diversos formatos de archivo, simultaneidad y transacciones ACID (atomicidad, coherencia, aislamiento, durabilidad). A esto hay que agregar la integración con Apache Ranger para el control granular de nivel de fila y columna sobre los datos.
Nota:
El contenido de este módulo se aplica a los clústeres de Interactive Query creados para HDInsight 4.0, que usa Hive 3.1 y LLAP, también conocido como Hive LLAP.
Tiene un conjunto de datos grande listo para su consulta
Los clústeres de Interactive Query son más adecuados para conjuntos de datos grandes que se pueden consultar tal cual o con transformaciones mínimas. Están diseñados para situaciones en las que va a realizar varias consultas en los datos y necesita respuestas inmediatas. Los clústeres de Interactive Query no están optimizados para realizar cálculos por lotes de larga duración. Interactive Query admite los siguientes formatos de archivo: ORC, Parquet, CSV, Avro, JSON, texto y tsv.
Necesita una funcionalidad similar a SQL
Si necesita realizar consultas interactivas y de latencia inferior a un segundo ad hoc en los macrodatos que tiene en Azure Storage y Azure Data Lake Storage y busca una experiencia similar a SQL, los clústeres de Azure HDInsight Interactive Query son una excelente opción. Como analista de negocios, está muy familiarizado con las tablas de SQL y la creación de consultas con SQL. Apache Hadoop es una herramienta eficaz para realizar análisis de macrodatos. El uso que Apache Hadoop hace del marco de MapReduce y de sus API de Java puede ser un impedimento si tiene muy olvidados sus conocimientos de programación de Java. En este caso, HDInsight Interactive Query es una mejor opción, ya que se basa en Apache Hadoop, pero es más fácil de usar para cualquier usuario con experiencia en SQL. Interactive Query usa tablas de Hive de tipo SQL para procesar datos y un lenguaje de consulta similar a SQL, denominado HiveQL, para consultar los datos. El uso de Hive es menos complejo que el procesamiento de datos mediante MapReduce en Apache Hadoop. Hive hace que sea más rápido y eficaz implementar soluciones en una empresa.
Consultas interactivas rápidas con el almacenamiento en caché inteligente
Los clústeres de Interactive Query usan técnicas de almacenamiento en caché inteligente para organizar los datos en la RAM dinámica, el SSD de nodo del clúster local y los sistemas de almacenamiento remoto, como Azure Blob y Azure Data Lake Storage, para lograr resultados de consulta rápidos e interactivos en macrodatos. Un buen ejemplo de técnica avanzada de almacenamiento en caché es la caché de texto dinámico, que convierte los datos CSV en un formato en memoria optimizado sobre la marcha, por lo que el almacenamiento en caché es dinámico y las consultas determinan qué datos se almacenan en caché. Gracias a esta funcionalidad, no es necesario cargar y transformar primero los datos. Puede cargar los datos en Azure Storage en su formato original y empezar a consultarlos. Además, esto implica que las consultas tienen un mejor rendimiento la segunda vez que se ejecutan. La primera vez que se ejecuta una consulta, se leen los datos de la capa de almacenamiento de datos empresariales en Azure Storage o Azure Data Lake Gen2. Después, los datos se almacenan en la caché compartida en memoria del clúster. La próxima vez que se ejecute la consulta, los datos simplemente se recuperarán de la caché compartida en memoria, lo que supondrá un ahorro de tiempo al no recuperar datos de la capa de almacenamiento remoto.
Ejecución de consultas mediante herramientas populares
Interactive Query facilita el trabajo con macrodatos mediante el uso de herramientas de inteligencia empresarial con las que ya está familiarizado, como Microsoft Power BI y Tableau. En el análisis de macrodatos, a las organizaciones cada vez les preocupa más que los usuarios finales no saquen provecho suficiente de los sistemas de análisis, ya que el proceso suele ser muy complicado y requiere el uso de herramientas desconocidas y difíciles de aprender para ejecutar el análisis. Para solucionar este problema, HDInsight Interactive Query requiere un entrenamiento mínimo o nulo por parte del usuario para obtener información de los datos. Los usuarios pueden escribir consultas de HiveQL similares a SQL en las herramientas que ya usan. Entre estas herramientas se incluyen Visual Studio Code, Power BI, Apache Zeppelin, Visual Studio, la vista de Hive de Ambari, Beeline, Data Analytics Studio y el controlador ODBC de Hive. No se puede realizar consultas en el clúster de Interactive Query mediante la consola de Hive, Templeton, la CLI clásica de Azure o Azure PowerShell.
Necesita coherencia y simultaneidad de las transacciones
Con la introducción de la administración de recursos específica, el adelantamiento y el uso compartido de los datos almacenados en caché entre consultas y usuarios, Interactive Query admite usuarios simultáneos con facilidad. HDInsight admite la creación de varios clústeres en una instancia compartida de Azure Storage. El metastore de Hive ayuda a lograr un alto grado de simultaneidad. Puede escalar la simultaneidad si agrega más nodos de clúster o más clústeres que apunten a los mismos datos y metadatos subyacentes. Interactive Query también admite transacciones de base de datos de tipo ACID (atomicidad, coherencia, aislamiento, durabilidad). Las transacciones ACID garantizan que una transacción, incluso si abarca varias operaciones, esté contenida en una sola unidad. Por lo tanto, si se produce un error en una sola operación de la transacción, se puede revertir toda la operación, lo que mantiene la coherencia y la precisión de los datos.
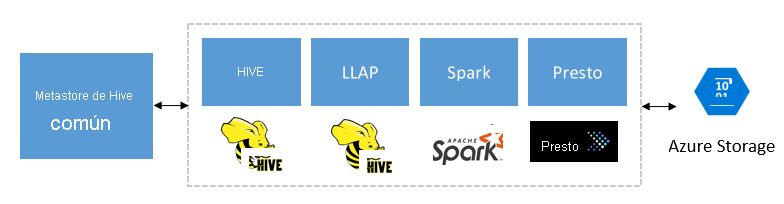
Diseño pensado para complementar Spark, Hive, Presto y otros motores de macrodatos
HDInsight Interactive Query está diseñado para que funcione correctamente con populares motores de macrodatos, como Apache Spark, Hive, Presto, etc. Este tipo de consulta es especialmente útil porque los usuarios pueden elegir cualquiera de estas herramientas para ejecutar los análisis. Con la arquitectura de metadatos y datos compartidos de HDInsight para tablas externas, los usuarios pueden crear varios clústeres con el mismo motor o con otro que apunte a los mismos datos y metadatos subyacentes. Esta funcionalidad es muy eficaz, ya que gracias a ella no se verá limitado a una tecnología para el análisis.