Consultas interactivas de HDInsight
Las consultas interactivas suelen implementarse en un escenario de ruta de acceso inactiva, donde tiene los datos en formato tabular y quiere formular preguntas rápidamente y recibir una respuesta interactiva mediante la sintaxis SQL. En el diagrama siguiente, se muestra la arquitectura de la solución para todas las soluciones de rutas de acceso activas e inactivas de HDInsight y se indica cómo se administran las consultas interactivas a través de Hive LLAP en la capa de servicio. Los datos se pueden ingerir mediante Hive, las consultas interactivas se procesan mediante Hive LLAP, y la salida puede proporcionarse a aplicaciones de bajada, como Power BI.
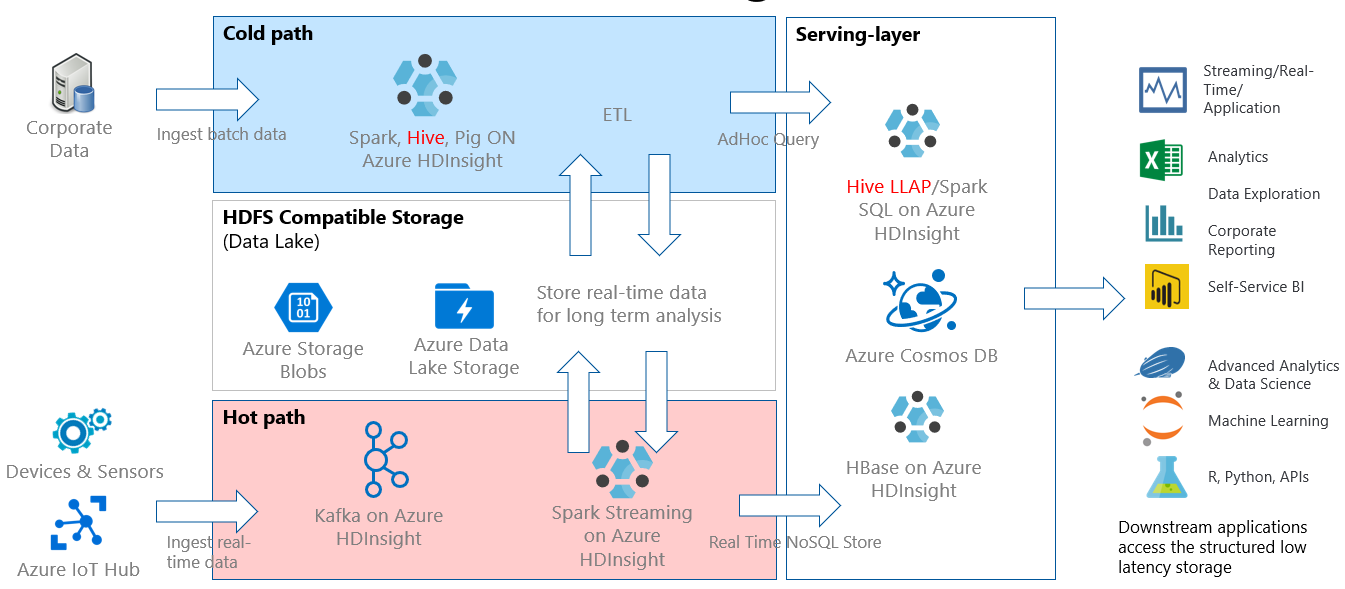
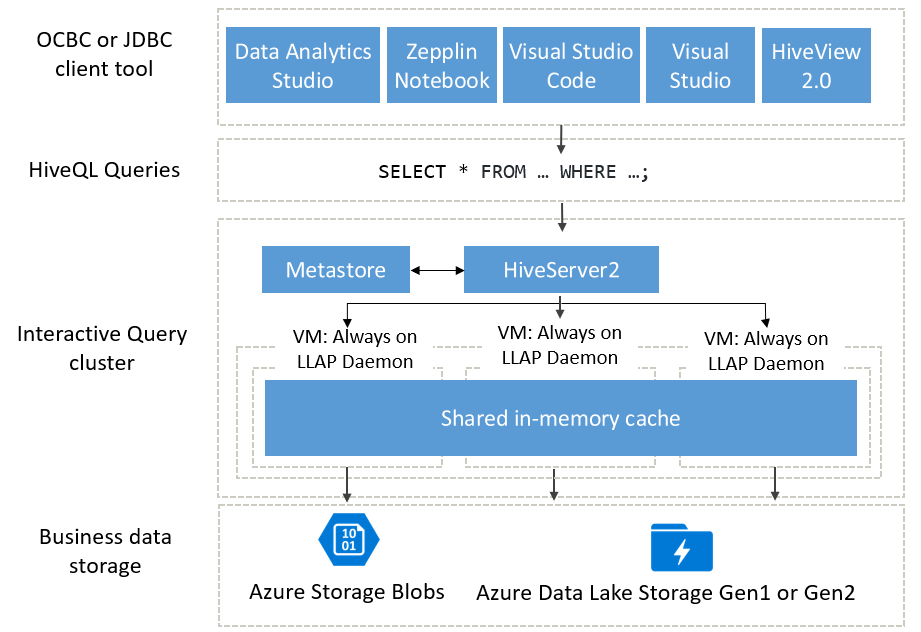
Arquitectura de Interactive Query
Veamos en detalle la arquitectura de Interactive Query.
Los usuarios de Interactive Query pueden elegir entre varios clientes de ODBC o JDBC para ejecutar consultas en sus datos empresariales, como Data Analytics Studio, cuadernos de Zeppelin Notebook y Visual Studio Code. Una vez que un cliente envía una consulta de HiveQL, esta llega a HiveServer, que es responsable de la planeación de la consulta, la optimización y el recorte de seguridad. Hive funciona mediante la división de las tareas de análisis entre los nodos distribuidos del clúster. Las consultas se dividen en subtareas y se envían a los nodos que procesan cada una de las subtareas. Estas se dividen aún más y cada una de ellas lee los datos de la capa de almacenamiento de datos empresariales subyacente. La arquitectura está optimizada porque usa demonios de LLAP "siempre activos", que evitan los tiempos de inicio, así como la caché compartida en memoria, que almacena los datos que se han recuperado del almacenamiento y comparte los datos en todos los nodos.
Las unidades de estado sólido (SSD) empleadas por los clústeres de Interactive Query combinan la RAM y las SSD en un grupo gigante de memoria utilizado por la memoria caché. Con esta combinación de recursos, un perfil de servidor típico puede almacenar en caché cuatro veces más datos, lo que permite procesar conjuntos de datos más grandes y admitir más usuarios. La caché de Interactive Query conoce los cambios de datos subyacentes en el almacén remoto (Azure Storage), de modo que, si los datos subyacentes cambian y el usuario emite una consulta, los datos actualizados se cargarán en la memoria sin necesidad de que el usuario realice ningún paso adicional.